SQL实战(二)
一、
获取所有员工当前的manager,如果当前的manager是自己的话结果不显示,当前表示to_date='9999-01-01'。
结果第一列给出当前员工的emp_no,第二列给出其manager对应的manager_no。
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL,
`emp_no` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
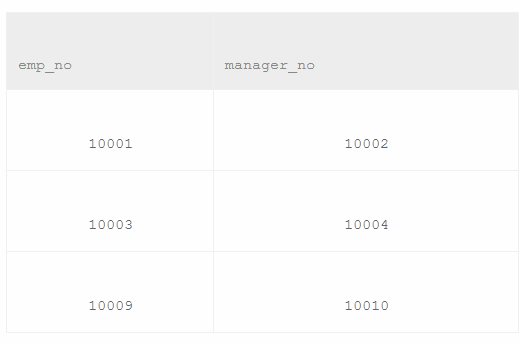
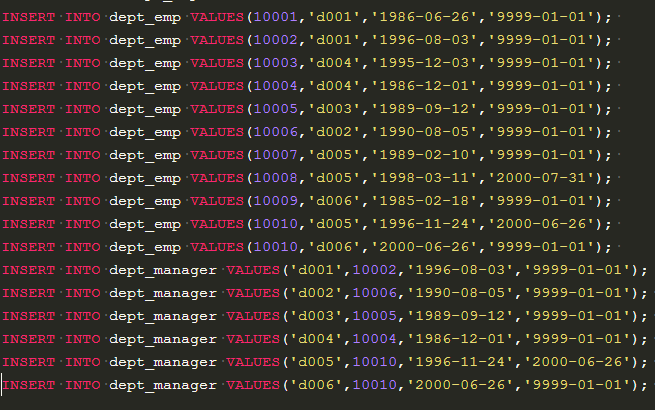
这道题是读取dept_emp 中的 当前员工(9999-01-01)的部门(d001),从dept_manager 中读取该部门的经理(10002)。注意同一个人的话不输出。
1、
select e.emp_no,m.emp_no from dept_emp as e,dept_manager as m
where e.to_date="9999-01-01" and e.dept_no=m.dept_no and e.emp_no!=m.emp_no and m.to_date="9999-01-01"
注意是靠部门联系两个表,然后再判断 具体条件
2、join
select e.emp_no,m.emp_no as manager_no --改名为manager_no
from dept_emp as e join dept_manager as m
on e.to_date="9999-01-01" and e.dept_no=m.dept_no and e.emp_no!=m.emp_no and m.to_date="9999-01-01"
3、left join
select e.emp_no,m.emp_no as manager_no --改名为manager_no
from dept_emp as e left join dept_manager as m
on e.to_date="9999-01-01" and e.dept_no=m.dept_no and e.emp_no!=m.emp_no and m.to_date="9999-01-01"
where manager_no is not NUll
左连接去掉NULL。
二、
获取所有部门中当前员工薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
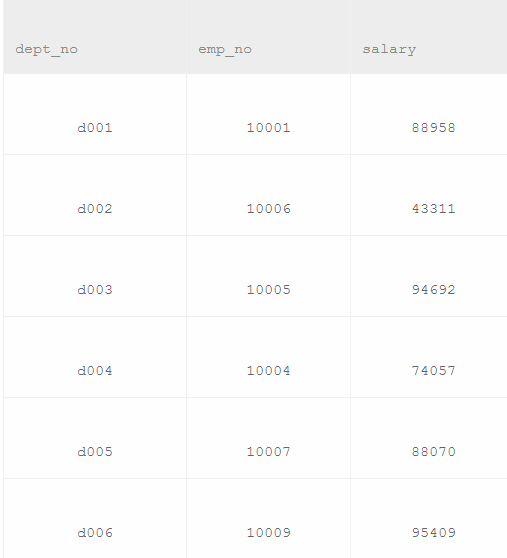
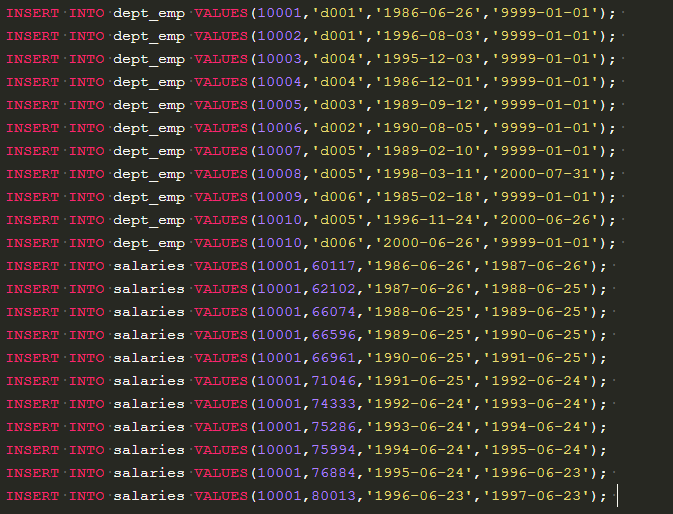
十个人六个部门,有重叠,找最高.
可以看到d001部门有两个员工,10001和1002,一个表中不能将1001和1002和为一类比较。所以得先用join连接两个表,而不能直接from a,b这种形式。
1、
select d.dept_no,d.emp_no,max(s.salary) from dept_emp as d join salaries as s --连接表 on d.emp_no=s.emp_no --连接条件 where d.to_date="9999-01-01" and s.to_date="9999-01-01" --找到当前部门,薪水 group by d.dept_no --按部门分组,找最大的
2、
select d.dept_no,d.emp_no,s.salary from dept_emp as d join salaries as s --连接表 on d.emp_no=s.emp_no --连接条件 where d.to_date="9999-01-01" and s.to_date="9999-01-01" --找到当前部门,薪水 group by d.dept_no --按部门分组,找最大的 having max(s.salary) --函数放最后
三、
题目描述
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);

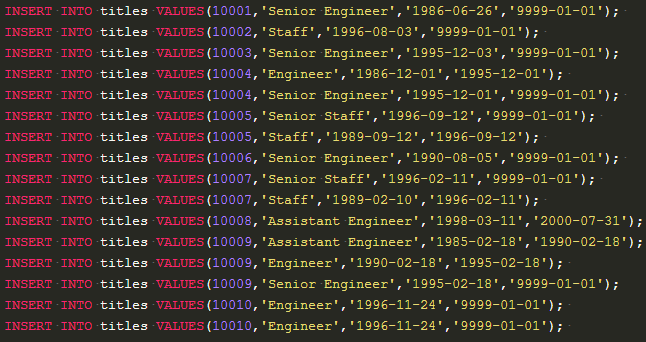
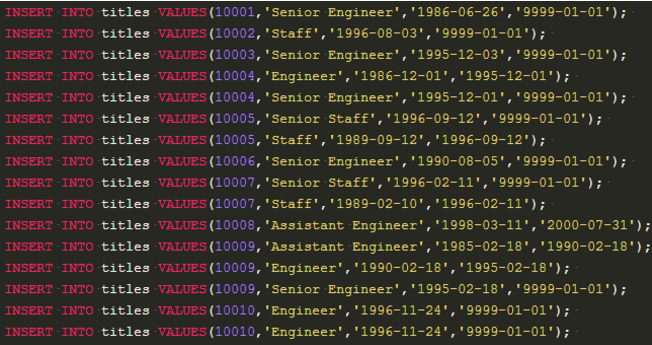
统计职称人数
group by 分组,count 统计个数,having 控制条件
1、
select title,count(title) as t from titles group by title
四、
题目描述
注意对于重复的emp_no进行忽略。
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);


where和having的不同之处在于,where是查找之前的限定,而having是查找之后。

这道题是去这两个重
首先按engineer分组,然后按10010 去重
1、
select title,count(distinct emp_no) as t from titles
group by title
having t>=2
2、
select tt.title,count(1) as t from (select distinct emp_no,title from titles )as tt
group by tt.title
having t>=2
这里注意名称的命名
五、
题目描述
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
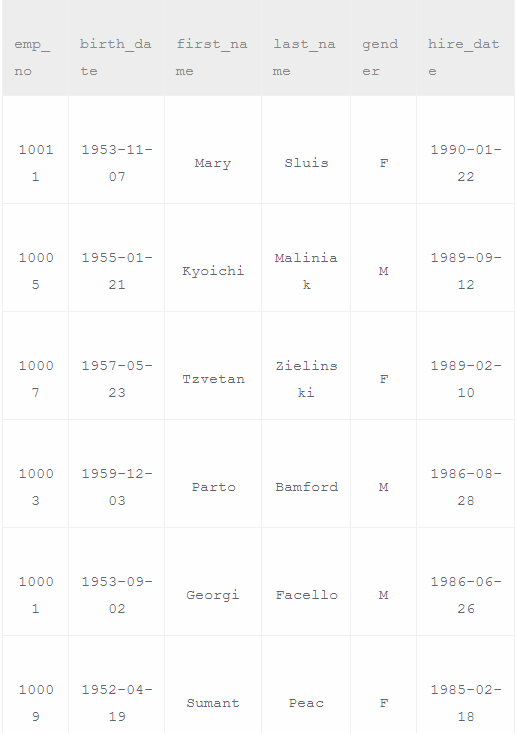
select * from employees as e
where e.emp_no%2==1 and e.last_name!="Mary"
order by hire_date desc
六、
题目描述
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);

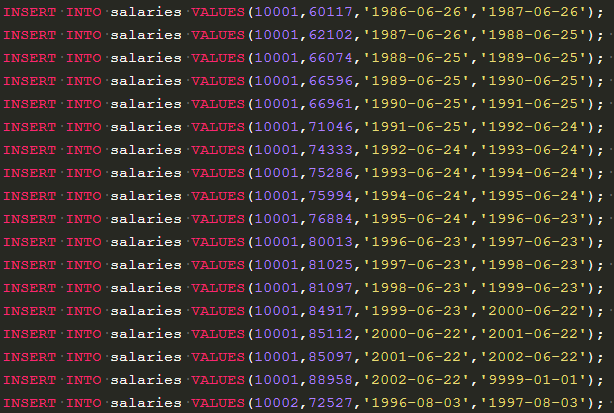
1、
select t.title,avg(s.salary) from titles as t join salaries as s --合并表
on t.emp_no=s.emp_no and t.to_date="9999-01-01" and s.to_date="9999-01-01"--三个条件,人和职位对应起来,对应现在的工资,现在的人
group by t.title --按职位分类
虽然能通过测试,这段程序还是有问题的,如果向上题那样重复记录了,其实计算就是错误的。
七、
题目描述
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
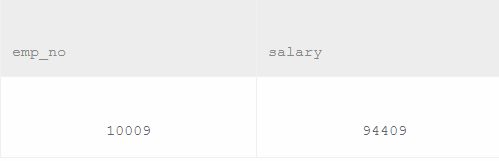
select emp_no,salary from salaries
where to_date="9999-01-01"
order by salary desc
limit 1,1
2、上面这段程序并没有考虑重复的情况
用distinct 去重复
select emp_no,salary from salaries
where to_date="9999-01-01" and salary=(select distinct salary from salaries where to_date="9999-01-01" order by salary desc limit 1,1)
3、比较大小的方式
select emp_no,max(salary) from salaries
where to_date="9999-01-01" and salary <(select max(salary) from salaries)
先读取最大的,然后比较选出次大的
八、
查找当前薪水(to_date='9999-01-01')排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,不准使用order by
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
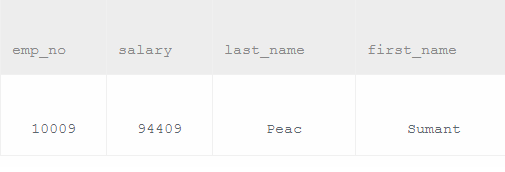
1、不用排序就是用比较的方法
select e.emp_no,max(s.salary),e.last_name,e.first_name from employees as e,salaries as s
where e.emp_no=s.emp_no and s.to_date="9999-01-01" and s.salary <(select max(salary) from salaries where to_date="9999-01-01")
九、
查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL,
PRIMARY KEY (`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
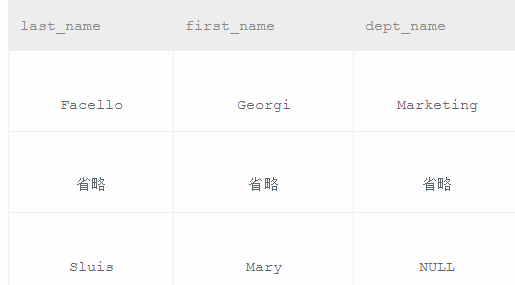
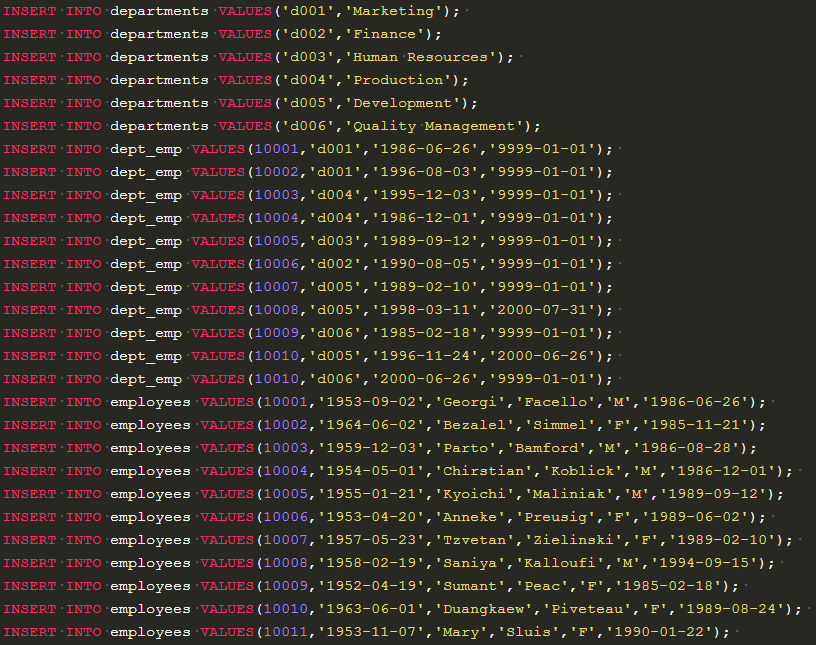
输出结果如下才对
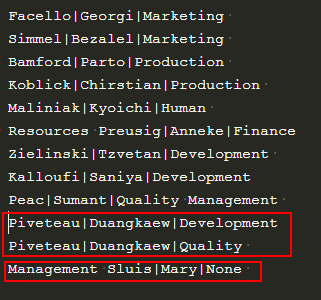
没有部门的显示none,10010编号的显示了两次
三个表,6个部门,11个人对应于部门,每个人情况表
首先employees和dept_emp左连接形成一个表,然后再左连接departments 形成新的表.考察left join的双层嵌套
select e.last_name,e.first_name,de.dept_name --所有获取的内容放在前面 from (employees as e left join dept_emp as dp on e.emp_no=dp.emp_no) --第一层left join,形成新的表 left join departments as de on de.dept_no=dp.dept_no --第二层left join
十、
查找员工编号emp_now为10001其自入职以来的薪水salary涨幅值growth
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));


1、默认递增排列的
select max(s.salary)-min(s.salary) as growth from salaries as s
where s.emp_no="10001"
注意growth的生成,只能select ...as...的形式
2、排序,找出第一个和最后一个
select (
(select salary from salaries where emp_no="10001" order by from_date desc limit 0,1)
-
(select salary from salaries where emp_no="10001" order by from_date limit 0,1)
)
as growth
SQL实战(二)的更多相关文章
- coreseek实战(二):windows下mysql数据源部分配置说明
coreseek实战(二):windows下mysql数据源部分配置说明 关于coreseek在windows使用mysql数据源的配置,以及中文分词的详细说明,请参考官方文档: mysql数据源配置 ...
- SpringSecurity权限管理系统实战—二、日志、接口文档等实现
系列目录 SpringSecurity权限管理系统实战-一.项目简介和开发环境准备 SpringSecurity权限管理系统实战-二.日志.接口文档等实现 SpringSecurity权限管理系统实战 ...
- 牛客网数据库SQL实战解析(51-61题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(31-40题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(21-30题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(11-20题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- 牛客网数据库SQL实战解析(1-10题)
牛客网SQL刷题地址: https://www.nowcoder.com/ta/sql?page=0 牛客网数据库SQL实战解析(01-10题): https://blog.csdn.net/u010 ...
- MySQL:怒刷牛客网“sql实战”
MySQL:怒刷牛客网"sql实战" 在对MySQL有一定了解后,抽空刷了一下 牛客网上的 数据库SQL 实战,在此做一点小小的记录 SQL1 查找最晚入职员工的所有信息 sele ...
- 【NFS项目实战二】NFS共享数据的时时同步推送备份
[NFS项目实战二]NFS共享数据的时时同步推送备份 标签(空格分隔): Linux服务搭建-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品, ...
- chrome调试工具高级不完整使用指南(实战二)
3.3 给页面添加测试脚本 在现实的工作中,我们往往会遇到一些问题在线上就会触发然后本地就触发不了的问题.或者是,要给某个元素写一个测试脚本.这个时候如果是浏览器有提供一个添加脚本的功能的话,那么我们 ...
随机推荐
- 仿segmentfault-table横向滚动
问题描述 自己的博客在用移动端访问时,如果table的列数足够多会显示不全,如下图红圈所示 正常情况如图 解决过程 使用chrome发现segmentfault的解决方法是在table上套一个tabl ...
- 学习gensim
首先要将字符串分割成词语列表.比如”hurry up”要分割成[“hurry”,”up”]. 对于中文来讲,分词就是一个很关键的问题,不过可以去找一些分词库来实现.我一般用的是jieba. 而对于英文 ...
- Simulink仿真入门到精通(十三) Simulink创建自定义库
当用户自定义了一系列模块之后,可以自定义模块库将同类自定义模块显示到Simulink Browser中,作为库模块方便地拖曳到新建模型中. 建立这样的自定义库需要3个条件: 建立library的mdl ...
- CrawlSpiders简介
转:https://www.cnblogs.com/ellisonzhang/p/11124516.html#4295547 一.CrawlSpiders类简介 通过下面的命令可以快速创建 Crawl ...
- C++ 动态链接库 dll的加载
//首先生成一个my.dll项目,在cpp中添加如下代码 //导出函数 _declspec(dllexport) int test(int a, int b) { return a + b; } // ...
- python安装包的3的方式
1.pip pip install 包名 2.压缩包(针对pip安装不上) 1.下载源码解压(压缩包有setup.py) 2.python setup.py install 3.****.whl文件 ...
- 将xml处理为json对象数组
function xmlStr2js(xmlStr) { var tagNames = xmlStr.match(/<\w+>/g) tagNames = deWeightTagNames ...
- java常用日期类总结
java 常用的日期类有三个Date.SimpleDateFormat.Calendar
- 后端程序员必备:书写高质量SQL的30条建议
前言 本文将结合实例demo,阐述30条有关于优化SQL的建议,多数是实际开发中总结出来的,希望对大家有帮助. 1.查询SQL尽量不要使用select *,而是select具体字段. 反例子: sel ...
- C++类复习及新的认识 6.1.1+6.1.2内容(适合看过一遍书的新手)
作者水平有限,文字表述大多摘抄课本,源码部分由课本加自己改编而成,所有代码均在vs2019中编译通过 定义类操作 class Tdate { public: void Set(int m, int d ...