理解BERT:一个突破性NLP框架的综合指南
概述
- Google的BERT改变了自然语言处理(NLP)的格局
- 了解BERT是什么,它如何工作以及产生的影响等
- 我们还将在Python中实现BERT,为你提供动手学习的经验
BERT简介
想象一下——你正在从事一个非常酷的数据科学项目,并且应用了最新的最先进的库来获得一个好的结果!几天后,一个新的最先进的框架出现了,它有可能进一步改进你的模型。
这不是一个假想的场景——这是在自然语言处理(NLP)领域工作的真正现实!过去的两年的突破是令人兴奋的。
谷歌的BERT就是这样一个NLP框架。我敢说它可能是近代最有影响力的一个(我们很快就会知道为什么)。

毫不夸张地说,BERT极大地改变了NLP的格局。想象一下,使用一个在大型未标记数据集上训练的单一模型,然后在11个单独的NLP任务上获得SOTA结果。所有这些任务都需要fine-tuning。BERT是我们设计NLP模型的一个结构性转变。
BERT启发了许多最近的NLP架构、训练方法和语言模型,如谷歌的TransformerXL、OpenAI的GPT-2、XLNet、ERNIE2.0、RoBERTa等。
我的目标是给你一个全面的指导,不仅BERT,还有它带来的影响以及如何影响未来的NLP研究。
目录
- 什么是BERT?
- 从Word2Vec到BERT:NLP的学习语言表示的探索
- BERT如何工作?
- 使用BERT进行文本分类(Python代码)
- 超越BERT:NLP的最新技术
什么是BERT?
你可能大概听说过BERT,你看到过它是多么不可思议,它是如何潜在地改变了NLP的前景。但是BERT到底是什么呢?
BERT背后的研究团队是这样描述NLP框架的:
"BERT代表Transformers的双向编码器。它被设计为通过对左右的上下文的联合来预训练未标记文本得到深层的双向表示。因此,只需一个额外的输出层,就可以对预训练的BERT模型进行微调,从而为各种NLP任务创建SOTA结果。"
作为一开始,这听起来太复杂了。但是它确实总结了BERT的出色表现,因此让我们对其进行细分。
首先,很容易理解BERT是Transformers的双向编码器表示。这里的每个词都有其含义,我们将在本文中逐一讨论。这一行的关键是,BERT是基于Transformer架构的。
其次,BERT是在大量未标记文本的预训练,包括整个Wikipedia(有25亿个词!)和图书语料库(有8亿个单词)。
这个预训练步骤是BERT成功背后的一半。这是因为当我们在大型文本语料库上训练模型时,我们的模型开始获得对语言工作原理的更深入和深入的了解。这种知识几乎可用于所有NLP任务。
第三,BERT是"深度双向"模型。双向意味着BERT在训练阶段从目标词的左右两侧上下文来学习信息。
模型的双向性对于真正理解语言的意义很重要。让我们看一个例子来说明这一点。在此示例中,有两个句子,并且两个句子都包含单词"bank":

如果我们仅通过选择左侧或右侧上下文来预测"bank"一词的意义,那么在两个给定示例中至少有一个会出错。
解决此问题的一种方法是在进行预测之前考虑左右上下文。这正是BERT所做的!我们将在本文的后面看到如何实现这一目标。
最后,BERT最令人印象深刻的方面。我们可以通过仅添加几个其他输出层来微调它,以创建用于各种NLP任务的最新模型。
从Word2Vec到BERT:NLP的学习语言表示的探索
"自然语言处理中的最大挑战之一是训练数据的短缺。由于NLP是一个具有许多不同任务的多元化领域,因此大多数特定于任务的数据集仅包含数千或数十万个人标记的训练示例。" – Google AI
Word2Vec和GloVe
通过在大型未标记文本数据上进行预训练模型来学习语言表示的要求始于诸如Word2Vec和GloVe之类的词嵌入。这些嵌入改变了我们执行NLP任务的方式。现在,我们有了嵌入,可以捕获单词之间的上下文关系。

这些嵌入被用来训练下游NLP任务的模型,并做出更好的预测。这可以通过利用来自嵌入本身的附加信息,甚至使用较少的特定于任务的数据来完成。
这些嵌入的一个限制是使用非常浅的语言模型。这意味着他们能够获取的信息的数量是有限的,这促使他们使用更深入、更复杂的语言模型(LSTMs和GRUs层)。
另一个关键的限制是,这些模型没有考虑单词的上下文。让我们以上面的“bank”为例。同一个单词在不同的上下文中有不同的意思。然而,像Word2Vec这样的嵌入将在这两个上下文中为“bank”提供相同的词嵌入。
这是导致模型不准确的一个因素。
ELMO和ULMFiT

ELMo是NLP社区对一词多义问题的回应——相同的词在不同的语境中有不同的含义。从训练浅层前馈网络(Word2vec),逐步过渡到使用复杂的双向LSTM体系结构的层来训练词嵌入。这意味着同一个单词可以根据它所在的上下文有多个ELMO嵌入。
那是我们开始看到预训练作为NLP的训练机制的优势。

ULMFiT则更进一步。这个框架可以训练语言模型,这些模型可以进行微调,从而在各种文档分类任务中,即使使用更少的数据(少于100个示例)也可以提供出色的结果。可以肯定地说,ULMFiT破解了NLP中迁移学习的密码。
这就是我们在NLP中建立迁移学习黄金法则的时候:
NLP中的迁移学习 =预训练和微调
ULMFIT之后的大多数NLP的突破调整了上述等式的组成部分,并获得了最先进的基准。
OpenAI的GPT
OpenAI的GPT扩展了ULMFiT和ELMo引入的预训练和微调方法。GPT本质上用基于转换的体系结构取代了基于lstm的语言建模体系结构。
GPT模型可以微调到文档分类之外的多个NLP任务,如常识推理、语义相似性和阅读理解。
GPT还强调了Transformer框架的重要性,它具有更简单的体系结构,并且比基于lstm的模型训练得更快。它还能够通过使用注意力机制来学习数据中的复杂模式。
OpenAI的GPT通过实现多个最先进的技术,验证了Transformer架构的健壮性和有用性。
这就是Transformer如何启发了BERT以及接下来在NLP领域的所有突破。
现在,还有一些其他的重要突破和研究成果我们还没有提到,比如半监督序列学习。这是因为它们稍微超出了本文的范围,但是你可以阅读相关的论文来了解更多信息。
BERT
因此,解决NLP任务的新方法变成了一个2步过程:
- 在大型无标签文本语料库(无监督或半监督)上训练语言模型
- 将这个大型模型微调到特定的NLP任务,以利用这个大型知识库训练模型(监督)
在这样的背景下,让我们来理解BERT是如何从这里开始建立一个模型,这个模型将在很长一段时间内成为NLP中优秀的基准。
BERT如何工作?
让我们仔细看一下BERT,了解为什么它是一种有效的语言建模方法。我们已经知道BERT可以做什么,但是它是如何做到的?我们将在本节中回答这个相关问题。
1. BERT的体系结构
BERT架构建立在Transformer之上。我们目前有两个可用的版本:
BERT Base:12层transformer,12个attention heads和1.1亿个参数BERT Large:24层transformer,16个attention heads和3.4亿个参数

出于比较的目的,BERT基础架构具有与OpenAI的GPT相同的模型大小。所有这些Transformer层都是只使用Transformer的编码器。
现在我们已经了解了BERT的总体架构,接下来让我们看看在进入模型构建阶段之前需要哪些文本处理步骤。
2.文本预处理

BERT背后的开发人员已经添加了一组特定规则来表示模型的输入文本。其中许多是创造性的设计选择,目的是使模型更好。
对于初学者,每个输入的嵌入是3个嵌入的组合:
- 位置嵌入(Position Embeddings):BERT学习并使用位置嵌入来表达句子中单词的位置。这些是为了克服Transformer的限制而添加的,Transformer与RNN不同,它不能捕获“序列”或“顺序”信息
- 段嵌入(Segment Embeddings):BERT还可以将句子对作为任务的输入(可用于问答)。这就是为什么它学习第一和第二句话的独特嵌入,以帮助模型区分它们。在上面的例子中,所有标记为EA的标记都属于句子A(对于EB也是一样)
- 目标词嵌入(Token Embeddings):这些是从WordPiece词汇表中对特定词汇学习到的嵌入
对于给定的目标词,其输入表示是通过对相应的目标词、段和位置的嵌入进行求和来构造的。
这样一个综合的嵌入方案包含了很多对模型有用的信息。
这些预处理步骤的组合使BERT如此多才多艺。这意味着,不需要对模型的体系结构进行任何重大更改,我们就可以轻松地对它进行多种NLP任务的训练。
3.预训练任务
BERT已接受两项NLP任务的预训练:
- 屏蔽语言建模
- 下一句预测
让我们更详细地了解这两个任务!
1. 屏蔽语言建模(双向性)
双向性
BERT被设计成一个深度双向模型。网络有效地从第一层本身一直到最后一层捕获来自目标词的左右上下文的信息。
传统上,我们要么训练语言模型预测句子中的下一个单词(GPT中使用的从右到左的上下文),要么训练语言模型预测从左到右的上下文。这使得我们的模型容易由于信息丢失而产生错误。

ELMo试图通过在左到右和从右到左的上下文中训练两个LSTM语言模型并对其进行浅级连接来解决此问题。即使它在现有技术上有了很大的改进,但这还不够。
"凭直觉,我们有理由相信,深层双向模型比左向右模型或从左至右和从右至左模型的浅级连接严格更强大。" – BERT
这就是BERT在GPT和ELMo上都大大改进的地方。看下图:

箭头指示从一层到下一层的信息流。顶部的绿色框表示每个输入单词的最终上下文表示。
从上图可以明显看出:BERT是双向的,GPT是单向的(信息仅从左向右流动),而ELMO是浅双向的。
关于屏蔽语言模型
假设我们有一句话——“我喜欢阅读关于分析数据科学的博客”。我们想要训练一个双向的语言模型。与其试图预测序列中的下一个单词,不如构建一个模型,从序列本身预测缺失的单词。
让我们把“分析”替换成“[MASK]”。这是表示被屏蔽的单词。然后,我们将以这样一种方式训练该模型,使它能够预测“分析”这个词语,所以句子变为:“我喜欢阅读关于[MASK]数据科学的博客”
这是掩蔽语言模型的关键所在。BERT的作者还提出了一些注意事项,以进一步改进这项技术:
- 为了防止模型过于关注一个特定的位置或被掩盖的标记,研究人员随机掩盖了15%的单词
- 掩码字并不总是被掩码令牌[掩码]替换,因为[掩码]令牌在调优期间不会出现
- 因此,研究人员采用了以下方法:
- 80%的情况下,单词被替换成带面具的令牌[面具]
- 10%的情况下,这些单词被随机替换
- 有10%的时间单词是保持不变的
2. 下一句预测
掩蔽语言模型(MLMs)学习理解单词之间的关系。此外,BERT还接受了下一个句子预测任务的训练,这些任务需要理解句子之间的关系。
此类任务的一个很好的例子是问题回答系统。
任务很简单。给定两个句子——A和B, B是语料库中A后面的下一个句子,还是一个随机的句子?
由于它是一个二分类任务,因此可以通过将任何语料库分成句子对来轻松生成数据。就像mlm一样,作者在这里也添加了一些注意事项。让我们举个例子:
假设我们有一个包含100,000个句子的文本数据集。因此,将有50,000个训练例子或句子对作为训练数据。
- 对于50%的对来说,第二个句子实际上是第一个句子的下一个句子
- 对于剩下的50%,第二句是语料库中的一个随机句子
- 第一种情况的标签是“IsNext”,而第二种情况的标签是“NotNext”
这就是为什么BERT能够成为一个真正的任务不可知的模型。它结合了掩蔽语言模型(MLM)和下一个句子预测(NSP)的预训练任务。
在Python中实现BERT以进行文本分类
你的头脑一定被BERT所开辟的各种可能性搅得团团转。我们有许多方法可以利用BERT的大量知识来开发我们的NLP应用程序。
最有效的方法之一是根据你自己的任务和特定于任务的数据对其进行微调。然后我们可以使用BERT中的嵌入作为文本文档的嵌入。
在本节中,我们将学习如何在NLP任务中使用BERT的嵌入。我们将在以后的文章中讨论对整个BERT模型进行微调的概念。
为了从BERT中提取嵌入,我们将使用一个非常有用的开源项目:https://github.com/hanxiao/bert-as-service这个开源项目如此有用的原因是它允许我们只需两行代码使用BERT获取每个句子的嵌入。
安装BERT-As-Service
服务以一种简单的方式工作。它创建了一个BERT服务器。每次我们将一个句子列表发送给它时,它将发送所有句子的嵌入。
我们可以通过pip安装服务器和客户机。它们可以单独安装,甚至可以安装在不同的机器上:
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`注意,服务器必须在Python >= 3.5上运行,而TensorFlow >= 1.10。
此外,由于运行BERT是一个GPU密集型任务,我建议在基于云的GPU或其他具有高计算能力的机器上安装BERT服务器。
现在,回到你的终端并下载下面列出的模型。然后,将zip文件解压缩到某个文件夹中,比如/tmp/englishL-12H-768_A-12/。
以下是发布的预训练BERT模型列表:
BERT-Base, Uncased 12-layer, 768-hidden, 12-heads, 110M parametershttps://storage.googleapis.com/bertmodels/20181018/uncasedL-12H-768A-12.zip
BERT-Large, Uncased 24-layer, 1024-hidden, 16-heads, 340M parametershttps://storage.googleapis.com/bertmodels/20181018/uncasedL-24H-1024A-16.zip
BERT-Base, Cased 12-layer, 768-hidden, 12-heads, 110M parametershttps://storage.googleapis.com/bertmodels/20181018/casedL-12H-768A-12.zip
BERT-Large, Cased 24-layer, 1024-hidden, 16-heads, 340M parametershttps://storage.googleapis.com/bertmodels/20181018/casedL-24H-1024A-16.zip
BERT-Base, Multilingual Cased (New) 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametershttps://storage.googleapis.com/bertmodels/20181123/multicasedL-12H-768_A-12.zip
BERT-Base, Multilingual Cased (Old) 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametershttps://storage.googleapis.com/bertmodels/20181103/multilingualL-12H-768A-12.zip
BERT-Base, Chinese Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parametershttps://storage.googleapis.com/bertmodels/20181103/chineseL-12H-768A-12.zip
我们将下载BERT Uncased,然后解压缩zip文件:
wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip && unzip uncased_L-12_H-768_A-12.zip将所有文件提取到一个文件夹中之后,就可以启动BERT服务了:
bert-serving-start -model_dir uncased_L-12_H-768_A-12/ -num_worker=2 -max_seq_len 50现在,你可以从Python代码(使用客户端库)简单地调用BERT-As-Service。让我们直接进入代码!
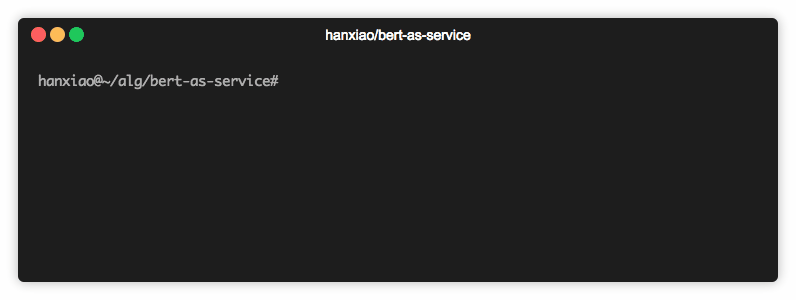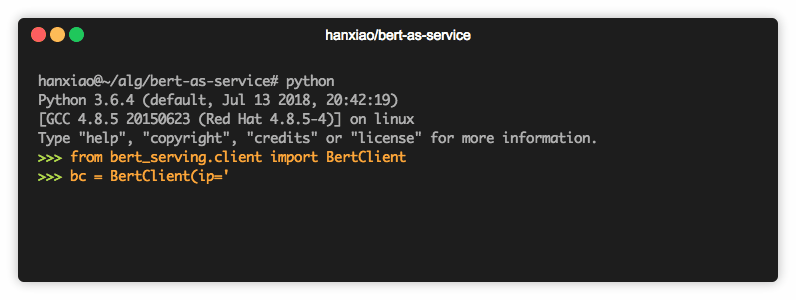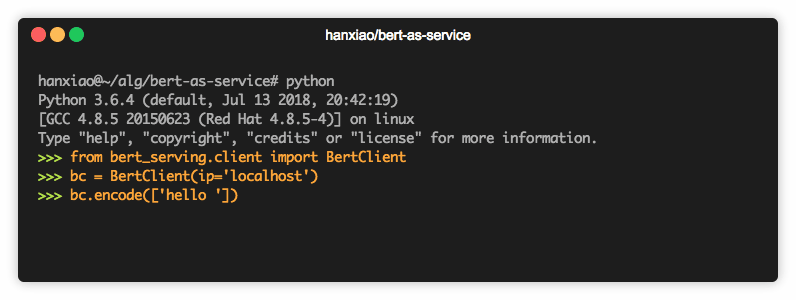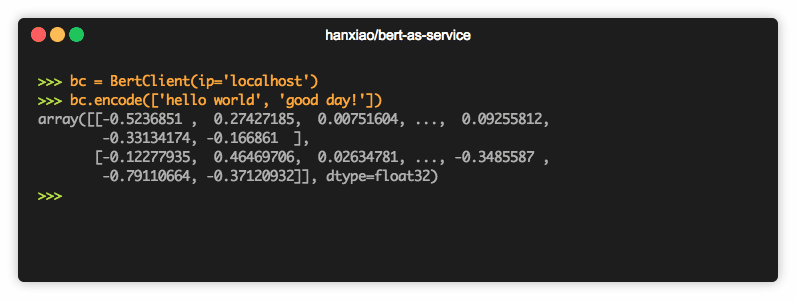
打开一个新的Jupyter notebook,试着获取以下句子的嵌入信息:“I love data science and analytics vidhya”。
这里,IP地址是你的服务器或云的IP。如果在同一台计算机上使用,则不需要此字段。
返回的嵌入形状为(1,768),因为BERT的架构中一个句子由768个隐藏单元表示。
问题:在Twitter上对不良言论进行分类
让我们拿一个真实世界的数据集来看看BERT有多有效。我们将使用一个数据集,该数据集由一系列推文组成,这些推文被归类为“不良言论”或非“不良言论”。
为了简单起见,如果一条推文带有种族主义或性别歧视的情绪,我们就说它包含不良言论。因此,我们的任务是将种族主义或性别歧视的推文与其他推文进行分类。
数据集链接https://datahack.analyticsvidhya.com/contest/practice-problem-twitter-sentiment-analysis/?utmsource=blog&utmmedium=demystifying-bert-groundbreaking-nlp-framework。
我们将使用BERT从数据集中的每个推特中提取嵌入,然后使用这些嵌入来训练文本分类模型。
以下是该项目的整体结构:

现在让我们看一下代码:
你会熟悉大多数人是如何发推特的。有许多随机的符号和数字(又名聊天语言!)我们的数据集也一样。我们需要在通过BERT之前对它进行预处理:
现在数据集是干净的,它被分割成训练集和验证集:
让我们在训练和验证集中获得所有推特的嵌入:
现在是建模时间!我们来训练分类模型:
检查分类精度:
from sklearn.metrics import accuracy_score
print(accuracy_score(y_val, pred_bert))即使使用如此小的数据集,我们也可以轻松获得大约95%的分类精度,这真的非常棒。
我鼓励你继续尝试BERT对不同问题进行尝试
超越BERT:目前最先进的NLP
BERT激发了人们对NLP领域的极大兴趣,特别是NLP任务中Transformer的应用。这导致了研究实验室和组织的数量激增,他们开始研究预训练、BERT和fine-tuning的不同方面。
许多这样的项目在多个NLP任务上都比BERT做得好。其中最有趣的是RoBERTa,这是Facebook人工智能对BERT和DistilBERT的改进,而DistilBERT是BERT的精简版和快速版。
欢迎关注磐创博客资源汇总站:http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:http://pytorch.panchuang.net/
理解BERT:一个突破性NLP框架的综合指南的更多相关文章
- vue是一个渐进式的框架,我是这么理解的
vue是一个渐进式的框架,我是这么理解的 原文地址 时间:2017-10-26 10:37来源:未知 作者:admin 每个框架都不可避免会有自己的一些特点,从而会对使用者有一定的要求,这些要求就是主 ...
- DirectX11--深入理解Effects11、使用着色器反射机制(Shader Reflection)实现一个复杂Effects框架
前言 如果之前你是跟随本教程系列学习的话,应该能够初步了解Effects11(现FX11)的实现机制,并且可以编写一个简易的特效管理框架,但是随着特效种类的增多,要管理的着色器.资源等也随之变多.如果 ...
- 深入理解BERT Transformer ,不仅仅是注意力机制
来源商业新知网,原标题:深入理解BERT Transformer ,不仅仅是注意力机制 BERT是google最近提出的一个自然语言处理模型,它在许多任务 检测上表现非常好. 如:问答.自然语言推断和 ...
- 【转】快速理解Kafka分布式消息队列框架
from:http://blog.csdn.net/colorant/article/details/12081909 快速理解Kafka分布式消息队列框架 标签: kafkamessage que ...
- 一个响应式框架——agera
Google在上周开源了一个响应式框架——agera,相信它会慢慢地被广大程序员所熟知.我个人对这样的技术是很感兴趣的,在这之前也研究过RxJava,所以在得知Google开源了这样的框架之后第一时间 ...
- QT带OpenGL与不带的区别,QT5是一个伟大的框架,短时期内根本不会有替代者
你好 , 我Qt的初学者 , 我在官网下载Qt时感觉很迷茫 , 不知道要下载哪个, 麻烦你写他们之间的不同点:Qt 5.2.0 for Windows 32-bit (MinGW 4.8, OpenG ...
- DirectX11 With Windows SDK--13 动手实现一个简易Effects框架、阴影效果绘制
前言 到现在为止,所有的教程项目都没有使用Effects11框架类来管理资源.因为在D3DCompile API (#47)版本中,如果你尝试编译fx_5_0的效果文件,会收到这样的警告: X4717 ...
- Android 从零开始搭建一个主流项目框架—RxJava2.0+Retrofit2.0+OkHttp
我这里的网络请求是用的装饰者模式去写的,什么是装饰者模式呢?在不必改变原类文件和使用继承的情况下,动态地扩展一个对象的功能.它是通过创建一个包装对象,也就是装饰来包裹真实的对象.我的理解就是一个接口, ...
- 基于Netty和SpringBoot实现一个轻量级RPC框架-协议篇
基于Netty和SpringBoot实现一个轻量级RPC框架-协议篇 前提 最近对网络编程方面比较有兴趣,在微服务实践上也用到了相对主流的RPC框架如Spring Cloud Gateway底层也切换 ...
随机推荐
- 牛客网剑指offer第21题——判断出栈序列是否是入栈序列
题目: 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序.假设压入栈的所有数字均不相等.例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈 ...
- Nginx使用和配置
概要: Nginx 简介 Nginx 架构说明 Nginx 基础配置与使用 Nginx 反向代理与负载均衡 Nginx 实现高速缓存 Nginx 性能参数调优 一.Nginx 简介与安装 Nginx ...
- SSRF漏洞的挖掘思路与技巧
什么是SSRF? SSRF(Server-Side Request Forgery:服务器端请求伪造) 是一种由攻击者构造形成由服务端发起请求的一个安全漏洞.一般情况下,SSRF攻击的目标是从外网无法 ...
- 【Django】接收照片,储存文件 前端代码
后端: from rest_framework.views import APIView from car import settings from django.shortcuts import r ...
- 沃土前端系列 - HTML常用标签
html是什么 HTML是Hyper Text Markup Language的缩写,中文的意思是"超文本标记语言",它是制作网页的标准语言.由于网页中不仅包含普通文本,还包含超文 ...
- python学习记录_中断正在执行的代码,执行剪切板中的代码,键盘快捷键,魔术命令,输入和输出变量,记录输入和输出变量_
2018-03-28 00:56:39 中断正在执行的代码 无论是%run执行的脚本还是长时间运行的命令ctrl + cIn [1]: KeyboardInterrupt 执行剪切板中的代码 ctrl ...
- java异常和throw和throws的区别
之前在编程中编译完成后,运行时,会遇见一些常见的错误,如NullPointerException,ArrayIndexOutOfBoundsException等等 在今天重新回顾学习了java异常,总 ...
- 用vue-cli进行npm run dev时候Cannot GET/
在用vue cli进行项目npm run dev 时候,页面Cannot GET/ 主要是把config/index.js里面的dev:{assetsPublicPath:'/'}改成了跟build里 ...
- php不用第三个变量,交换两个数的值
//字符串版本 结合使用substr,strlen两个方法实现 $a="a"; $b="b"; echo '交换前 $a:'.$a.',$b:'.$b.'< ...
- [Python] iupdatable包:日志模块使用介绍
一.说明 日志模块是对 logging 模块的单例封装 特点: 可同时向控制台和文件输出日志,并可选择关闭其中一种方式的输出: 集成colorlog,实现根据日志等级不同,控制台输出日志颜色不同: 灵 ...