入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建:
学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了。然后又去搭建Hive,又遇到了很多坑,就这样一直解决问题,加上网上搜索和个人排查检查日志。搜索百度,百度不行搜索Bing,看了csdn,看strackflow,最后终于功夫不负有心人,成功把MySql和Hive跑起来了。这里我将还原最初状态,并把遇到的坑一并记录下,同时防止后人采坑。
搭建环境:
Centos7,MySql14.14,Hive2.3.6
搭建MySql:
搭建步骤我参考的菜鸟教程: https://www.runoob.com/mysql/mysql-install.html
参考上述步骤搭建遇到的坑:
坑1:安装完后,给root用户设置密码后,使用账户和密码登陆报了ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)错误,解决方案点击。
搭建Hive:
搭建步骤我参考的: https://www.cnblogs.com/dxxblog/p/8193967.html
参考上述步骤遇到的坑:启动hive抛出Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D异常,解决方案点击。
操作Hive:
先说下环境的坑:
坑1:当我在Hive中执行查询操作没问题,但是当删除表结构的时候会抛出如下异常 :
执行drop table tableName;
Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:For direct MetaStore DB connections, we don't support retries at the client level.)
这句话的意思是不支持此操作,并不是SQL写错了。 这个问题的原因是之前我们在hive的lib中添加的mysql-connection-java.jar(使用JDBC操作MySql的包)版本不对,我之前用的mysql-connection-java-5.1.18.jar,后来改为了mysql-connection-java-5.1.47.jar就好了。
如果您的也不对,请及时替换,包连接
案例1(在Hive中创建内部表):
在Linux系统找个位置创建visits.txt和visits.hive文件:
在visits.txt文件里面加入如下内容,中间是以\t 分割的
一明 北京市朝阳区
毒逆天 江苏省苏州市
海面贝贝 上海市闵行区
在visits.hive加入创建数据库命令
create table people_visits
(
user_name string,
phone string,
address string
)
row format delimited
fields terminated by '\t';
在hive里面创建people_visits表
hive -f visits.hive
然后在hive中使用show tables; 就能看到这个表了。 但是数据是空的。接下来使用命令将visits.txt文件数据提交到hdfs再查询就能看到数据了。
hadoop fs -put visits.txt /user/hive/warehouse/people_visits

使用web浏览也可以看到上传的文件:

案例2:(在hive中创建外部表)
在Linux本地找个文件夹创建externalHive.txt文件
cd /data/
touch externalHive.txt
编辑文件加入以下内容
vim externalHive.txt
西红柿
桃子
注意:(上面字符使用tab键分割)
在hdfs里面新建一个hivetest文件夹
hadoop fs -mkdir /user/root/hivetest
将文件上传到hdfs
hadoop fs -put externalHive.txt /user
进入Hive创建一个价格外部表
hive
create external table priceVisits
(
name string,
price int
)
row format delimited
fields terminated by '\t'
location '/user/root/hivetest'; --指定表所在路径
将数据上传到priceVisits表里面
hive
load data inpath '/user/externalHive.txt' into table priceVisits;
PS:(上面的命令执行完后,user目录下的externalHive.txt就会移动到创建table时指定的目录下面)
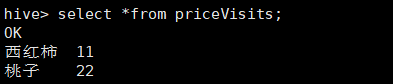
查询priceVisits表就可以看到数据了
select *from priceVisits;
删除priceVisits表:
drop table priceVisits;
可以看到表删除了,但是数据还没删除,这就是外部表的作用


上面的查询并没有用到MapReduce计算,仅仅使用了简单的本地查询,这是因为我们没有写聚合语句,不需要MapReduce。
DDL操作语句参考: https://www.cnblogs.com/shun7man/p/13172313.html
分桶操作参考:https://www.cnblogs.com/shun7man/p/13172437.html
入门大数据---Hive的搭建的更多相关文章
- 入门大数据---Hive计算引擎Tez简介和使用
一.前言 Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎.至于为什么提高了计算速度,可以参考下图: 用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Re ...
- 入门大数据---Hive是什么?
这篇文章主要介绍Hive的概念. 简介: Hive中文名叫数据仓库管理系统,之前我们操作MapReduce必须通过编写代码或者通过特殊命令来实现,有了Hive我们通过常用的SQL语句就能操作MapRe ...
- 入门大数据---Hive数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载. 1.1 员工表 -- 建表语句 ...
- 入门大数据---Kafka的搭建与应用
前言 上一章介绍了Kafka是什么,这章就讲讲怎么搭建以及如何使用. 快速开始 Step 1:Download the code Download the 2.4.1 release and un-t ...
- 入门大数据---通过Yarn搭建MapReduce和应用实例
上一篇中我们了解了MapReduce和Yarn的基本概念,接下来带领大家搭建下Mapreduce-HA的框架. 结构图如下: 开始搭建: 一.配置环境 注:可以现在一台计算机上进行配置,然后分发给其它 ...
- 入门大数据---Hive常用DDL操作
一.Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SC ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive视图和索引
一.视图 1.1 简介 Hive 中的视图和 RDBMS 中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条 SELECT 语句的结果集.视图是纯粹的逻辑对象,没有关联的存储 (Hive 3.0 ...
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
随机推荐
- echo改变字体颜色
格式: echo -e "\033[字背景颜色;字体颜色m字符串\033[0m" 例如: echo -e "\033[41;36m something here \033 ...
- Alpha冲刺 —— 5.6
这个作业属于哪个课程 软件工程 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 Alpha冲刺 作业正文 正文 github链接 项目地址 其他参考文献 无 一.会议内容 1.展 ...
- PowerPC-object与elf中的符号引用
https://mp.weixin.qq.com/s/6snzjEpDT4uQuCI2Nx9VcQ 一. 符号引用 编译会先把每个源代码文件编译成object目标文件,然后把所有目标文件链接到一起 ...
- MyBatis特性详解
缓存简介 一般我们在系统中使用缓存技术是为了提升数据查询的效率.当我们从数据库中查询到一批数据后将其放入到混存中(简单理解就是一块内存区域),下次再查询相同数据的时候就直接从缓存中获取数据就行了. 这 ...
- 基于 abp vNext 和 .NET Core 开发博客项目 - 博客接口实战篇(二)
系列文章 基于 abp vNext 和 .NET Core 开发博客项目 - 使用 abp cli 搭建项目 基于 abp vNext 和 .NET Core 开发博客项目 - 给项目瘦身,让它跑起来 ...
- Java实现 蓝桥杯 算法训练 Balloons in a Box
试题 算法训练 Balloons in a Box 问题描述 你要写一个程序,使得能够模拟在长方体的盒子里放置球形的气球. 接下来是模拟的方案.假设你已知一个长方体的盒子和一个点集.每一个点代表一个可 ...
- Java实现 LeetCode 242 有效的字母异位词
242. 有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词. 示例 1: 输入: s = "anagram", t = " ...
- Java实现 蓝桥杯VIP 算法提高 贪吃的大嘴
算法提高 贪吃的大嘴 时间限制:1.0s 内存限制:256.0MB 问题描述 有一只特别贪吃的大嘴,她很喜欢吃一种小蛋糕,而每一个小蛋糕有一个美味度,而大嘴是很傲娇的,一定要吃美味度和刚好为m的小蛋糕 ...
- Java实现 蓝桥杯 算法提高最小方差生成树
1 问题描述 给定带权无向图,求出一颗方差最小的生成树. 输入格式 输入多组测试数据.第一行为N,M,依次是点数和边数.接下来M行,每行三个整数U,V,W,代表连接U,V的边,和权值W.保证图连通.n ...
- PAT甲级 Reversible Primes
描述 A reversible prime in any number system is a prime whose "reverse" in that number syste ...