吴裕雄--天生自然python学习笔记:Python MongoDB
MongoDB 是目前最流行的 NoSQL 数据库之一,使用的数据类型 BSON(类似 JSON)。
PyMongo
Python 要连接 MongoDB 需要 MongoDB 驱动,这里我们使用 PyMongo 驱动来连接。 pip 安装
pip 是一个通用的 Python 包管理工具,提供了对 Python 包的查找、下载、安装、卸载的功能。 安装 pymongo: $ python3 -m pip3 install pymongo
也可以指定安装的版本: $ python3 -m pip3 install pymongo==3.5.1
更新 pymongo 命令: $ python3 -m pip3 install --upgrade pymongo
easy_install 安装
旧版的 Python 可以使用 easy_install 来安装,easy_install 也是 Python 包管理工具。 $ python -m easy_install pymongo
更新 pymongo 命令: $ python -m easy_install -U pymongo
测试 PyMongo
接下来我们可以创建一个测试文件 demo_test_mongodb.py,代码如下: demo_test_mongodb.py 文件代码:
#!/usr/bin/python3 import pymongo
执行以上代码文件,如果没有出现错误,表示安装成功。
创建数据库
创建一个数据库
创建数据库需要使用 MongoClient 对象,并且指定连接的 URL 地址和要创建的数据库名。 如下实例中,我们创建的数据库 runoobdb : 实例
#!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
注意: 在 MongoDB 中,数据库只有在内容插入后才会创建! 就是说,数据库创建后要创建集合(数据表)并插入一个文档(记录),数据库才会真正创建。
判断数据库是否已存在
我们可以读取 MongoDB 中的所有数据库,并判断指定的数据库是否存在: 实例
#!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient('mongodb://localhost:27017/') dblist = myclient.list_database_names()
# dblist = myclient.database_names()
if "runoobdb" in dblist:
print("数据库已存在!")
注意:database_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_database_names()。
创建集合
MongoDB 中的集合类似 SQL 的表。 创建一个集合
MongoDB 使用数据库对象来创建集合,实例如下: 实例
#!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"] mycol = mydb["sites"]
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
判断集合是否已存在
我们可以读取 MongoDB 数据库中的所有集合,并判断指定的集合是否存在: 实例
#!/usr/bin/python3 import pymongo myclient = pymongo.MongoClient('mongodb://localhost:27017/') mydb = myclient['runoobdb'] collist = mydb. list_collection_names()
# collist = mydb.collection_names()
if "sites" in collist: # 判断 sites 集合是否存在
print("集合已存在!")
注意:collection_names 在最新版本的 Python 中已废弃,Python3.7+ 之后的版本改为了 list_collection_names()。
增、删、改、查等操作
Python Mongodb 插入文档
MongoDB 中的一个文档类似 SQL 表中的一条记录。
插入集合
集合中插入文档使用 insert_one() 方法,该方法的第一参数是字典 name => value 对。 以下实例向 sites 集合中插入文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] mydict = { "name": "RUNOOB", "alexa": "", "url": "https://www.runoob.com" } x = mycol.insert_one(mydict)
print(x)
print(x)
执行输出结果为: <pymongo.results.InsertOneResult object at 0x10a34b288>
返回 _id 字段
insert_one() 方法返回 InsertOneResult 对象,该对象包含 inserted_id 属性,它是插入文档的 id 值。
import pymongo myclient = pymongo.MongoClient('mongodb://localhost:27017/')
mydb = myclient['runoobdb']
mycol = mydb["sites"] mydict = { "name": "Google", "alexa": "", "url": "https://www.google.com" } x = mycol.insert_one(mydict) print(x.inserted_id)
执行输出结果为: 5b2369cac315325f3698a1cf
如果我们在插入文档时没有指定 _id,MongoDB 会为每个文档添加一个唯一的 id。
插入多个文档
集合中插入多个文档使用 insert_many() 方法,该方法的第一参数是字典列表。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] mylist = [
{ "name": "Taobao", "alexa": "", "url": "https://www.taobao.com" },
{ "name": "QQ", "alexa": "", "url": "https://www.qq.com" },
{ "name": "Facebook", "alexa": "", "url": "https://www.facebook.com" },
{ "name": "知乎", "alexa": "", "url": "https://www.zhihu.com" },
{ "name": "Github", "alexa": "", "url": "https://www.github.com" }
] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)
输出结果类似如下: [ObjectId('5b236aa9c315325f5236bbb6'), ObjectId('5b236aa9c315325f5236bbb7'), ObjectId('5b236aa9c315325f5236bbb8'), ObjectId('5b236aa9c315325f5236bbb9'), ObjectId('5b236aa9c315325f5236bbba')]
insert_many() 方法返回 InsertManyResult 对象,该对象包含 inserted_ids 属性,该属性保存着所有插入文档的 id 值。 执行完以上查找,我们可以在命令终端,查看数据是否已插入:

插入指定 _id 的多个文档
我们也可以自己指定 id,插入,以下实例我们在 site2 集合中插入数据,_id 为我们指定的:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["site2"] mylist = [
{ "_id": 1, "name": "RUNOOB", "cn_name": "菜鸟教程"},
{ "_id": 2, "name": "Google", "address": "Google 搜索"},
{ "_id": 3, "name": "Facebook", "address": "脸书"},
{ "_id": 4, "name": "Taobao", "address": "淘宝"},
{ "_id": 5, "name": "Zhihu", "address": "知乎"}
] x = mycol.insert_many(mylist) # 输出插入的所有文档对应的 _id 值
print(x.inserted_ids)
输出结果为: [1, 2, 3, 4, 5]

Python Mongodb 查询文档
MongoDB 中使用了 find 和 find_one 方法来查询集合中的数据,它类似于 SQL 中的 SELECT 语句。 本文使用的测试数据如下:

查询一条数据
我们可以使用 find_one() 方法来查询集合中的一条数据。 查询 sites 文档中的第一条数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] x = mycol.find_one() print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
查询集合中所有数据
find() 方法可以查询集合中的所有数据,类似 SQL 中的 SELECT * 操作。 以下实例查找 sites 集合中的所有数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] for x in mycol.find():
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'alexa': '', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'alexa': '', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb7'), 'name': 'QQ', 'alexa': '', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb8'), 'name': 'Facebook', 'alexa': '', 'url': 'https://www.facebook.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb9'), 'name': '知乎', 'alexa': '', 'url': 'https://www.zhihu.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbba'), 'name': 'Github', 'alexa': '', 'url': 'https://www.github.com'}
查询指定字段的数据
我们可以使用 find() 方法来查询指定字段的数据,将要返回的字段对应值设置为 1。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] for x in mycol.find({},{ "_id": 0, "name": 1, "alexa": 1 }):
print(x)
输出结果为: {'name': 'RUNOOB', 'alexa': ''}
{'name': 'Google', 'alexa': ''}
{'name': 'Taobao', 'alexa': ''}
{'name': 'QQ', 'alexa': ''}
{'name': 'Facebook', 'alexa': ''}
{'name': '知乎', 'alexa': ''}
{'name': 'Github', 'alexa': ''}
除了 _id 你不能在一个对象中同时指定 0 和 1,如果你设置了一个字段为 0,则其他都为 1,反之亦然。
以下实例除了 alexa 字段外,其他都返回:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] for x in mycol.find({},{ "alexa": 0 }):
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb7'), 'name': 'QQ', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb8'), 'name': 'Facebook', 'url': 'https://www.facebook.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb9'), 'name': '知乎', 'url': 'https://www.zhihu.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbba'), 'name': 'Github', 'url': 'https://www.github.com'}
以下代码同时指定了 0 和 1 则会报错:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] for x in mycol.find({},{ "name": 1, "alexa": 0 }):
print(x)
错误内容大概如下: ...
pymongo.errors.OperationFailure: Projection cannot have a mix of inclusion and exclusion.
...
根据指定条件查询
我们可以在 find() 中设置参数来过滤数据。 以下实例查找 name 字段为 "RUNOOB" 的数据:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": "RUNOOB" } mydoc = mycol.find(myquery) for x in mydoc:
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
高级查询
查询的条件语句中,我们还可以使用修饰符。 以下实例用于读取 name 字段中第一个字母 ASCII 值大于 "H" 的数据,大于的修饰符条件为 {"$gt": "H"} :
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": { "$gt": "H" } } mydoc = mycol.find(myquery) for x in mydoc:
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'alexa': '', 'url': 'https://www.taobao.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb7'), 'name': 'QQ', 'alexa': '', 'url': 'https://www.qq.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb9'), 'name': '知乎', 'alexa': '', 'url': 'https://www.zhihu.com'}
使用正则表达式查询
我们还可以使用正则表达式作为修饰符。 正则表达式修饰符只用于搜索字符串的字段。 以下实例用于读取 name 字段中第一个字母为 "R" 的数据,正则表达式修饰符条件为 {"$regex": "^R"} :
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": { "$regex": "^R" } } mydoc = mycol.find(myquery) for x in mydoc:
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
返回指定条数记录
如果我们要对查询结果设置指定条数的记录可以使用 limit() 方法,该方法只接受一个数字参数。 以下实例返回 3 条文档记录:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myresult = mycol.find().limit(3) # 输出结果
for x in myresult:
print(x)
输出结果为: {'_id': ObjectId('5b23696ac315325f269f28d1'), 'name': 'RUNOOB', 'alexa': '', 'url': 'https://www.runoob.com'}
{'_id': ObjectId('5b2369cac315325f3698a1cf'), 'name': 'Google', 'alexa': '', 'url': 'https://www.google.com'}
{'_id': ObjectId('5b236aa9c315325f5236bbb6'), 'name': 'Taobao', 'alexa': '', 'url': 'https://www.taobao.com'}
Python Mongodb 修改文档
我们可以在 MongoDB 中使用 update_one() 方法修改文档中的记录。该方法第一个参数为查询的条件,第二个参数为要修改的字段。 如果查找到的匹配数据多余一条,则只会修改第一条。
以下实例将 alexa 字段的值 10000 改为 12345:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "alexa": "" }
newvalues = { "$set": { "alexa": "" } } mycol.update_one(myquery, newvalues) # 输出修改后的 "sites" 集合
for x in mycol.find():
print(x)
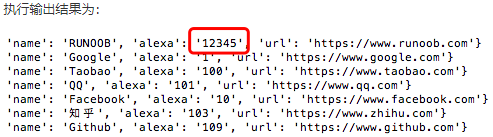
update_one() 方法只能修匹配到的第一条记录,如果要修改所有匹配到的记录,可以使用 update_many()。 以下实例将查找所有以 F 开头的 name 字段,并将匹配到所有记录的 alexa 字段修改为 123:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": { "$regex": "^F" } }
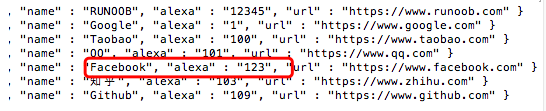
newvalues = { "$set": { "alexa": "" } } x = mycol.update_many(myquery, newvalues) print(x.modified_count, "文档已修改")
输出结果为: 1 文档已修改
查看数据是否已修改:
排序
sort() 方法可以指定升序或降序排序。 sort() 方法第一个参数为要排序的字段,第二个字段指定排序规则,1 为升序,-1 为降序,默认为升序。
对字段 alexa 按升序排序:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] mydoc = mycol.find().sort("alexa")
for x in mydoc:
print(x)
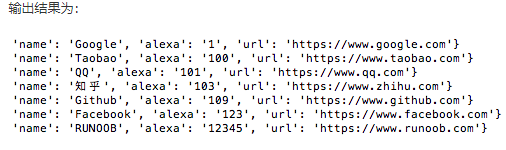
对字段 alexa 按降序排序:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] mydoc = mycol.find().sort("alexa", -1) for x in mydoc:
print(x)
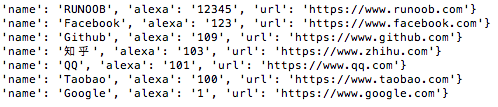
Python Mongodb 删除数据
我们可以使用 delete_one() 方法来删除一个文档,该方法第一个参数为查询对象,指定要删除哪些数据。
以下实例删除 name 字段值为 "Taobao" 的文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": "Taobao" } mycol.delete_one(myquery) # 删除后输出
for x in mycol.find():
print(x)
输出结果为:

删除多个文档
我们可以使用 delete_many() 方法来删除多个文档,该方法第一个参数为查询对象,指定要删除哪些数据。 删除所有 name 字段中以 F 开头的文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] myquery = { "name": {"$regex": "^F"} } x = mycol.delete_many(myquery) print(x.deleted_count, "个文档已删除")
删除集合中的所有文档
delete_many() 方法如果传入的是一个空的查询对象,则会删除集合中的所有文档:
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] x = mycol.delete_many({}) print(x.deleted_count, "个文档已删除")
删除集合
我们可以使用 drop() 方法来删除一个集合。
import pymongo myclient = pymongo.MongoClient("mongodb://localhost:27017/")
mydb = myclient["runoobdb"]
mycol = mydb["sites"] mycol.drop()
如果删除成功 drop() 返回 true,如果删除失败(集合不存在)则返回 false。 我们使用以下命令在终端查看集合是否已删除: > use runoobdb
switched to db runoobdb
> show tables;
吴裕雄--天生自然python学习笔记:Python MongoDB的更多相关文章
- 吴裕雄--天生自然HADOOP学习笔记:hadoop集群实现PageRank算法实验报告
实验课程名称:大数据处理技术 实验项目名称:hadoop集群实现PageRank算法 实验类型:综合性 实验日期:2018年 6 月4日-6月14日 学生姓名 吴裕雄 学号 15210120331 班 ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL UPDATE 更新
如果需要修改或更新 MySQL 中的数据,我们可以使用 SQL UPDATE 命令来操作. 语法 以下是 UPDATE 命令修改 MySQL 数据表数据的通用 SQL 语法: UPDATE table ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL 插入数据
MySQL 表中使用 INSERT INTO SQL语句来插入数据. 可以通过 mysql> 命令提示窗口中向数据表中插入数据,或者通过PHP脚本来插入数据. 以下为向MySQL数据表插入数据通 ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL简介
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用 ...
- 吴裕雄--天生自然 oracle学习笔记:oracle理论学习详解及各种简单操作例子
1. 数据库的发展过程 层次模型 -->网状模型 -->关系模型 -->对象关系模型 2. 关于数据库的概念 DB:数据库(存储信息的仓库) DBMS:数据库管理系统(用于管理数据库 ...
- 吴裕雄--天生自然HADOOP学习笔记:基本环境配置
实验目的 学习安装Java 学习配置环境变量 学习设置免密码登陆的方法 掌握Linux环境下时间同步的配置 实验原理 1.Java的安装 java是大数据的黄金语言,这和java跨平台的特性是密不可分 ...
- 吴裕雄--天生自然HADOOP学习笔记:使用yum安装更新软件
实验目的 了解yum的原理及配置 学习软件的更新与安装 学习源代码编译安装 实验原理 1.编译安装 前面我们讲到了安装软件的方式,因为linux是开放源码的,我们可以直接获得源码,自己编译安装.例如: ...
- 吴裕雄--天生自然HADOOP学习笔记:Shell工具使用
实验目的 学习使用xshell工具连接Linux服务器 在连上的服务器中进入用户目录 熟悉简单的文件操作命令 实验原理 熟悉shell命令是熟悉使用linux环境进行开发的第一步,我们在linux的交 ...
- 吴裕雄--天生自然HTML学习笔记:HTML 布局
网页布局对改善网站的外观非常重要. 请慎重设计您的网页布局. <!DOCTYPE html> <html> <head> <meta charset=&qu ...
- 吴裕雄--天生自然MySQL学习笔记:MySQL 安装
所有平台的 MySQL 下载地址为: MySQL 下载:https://dev.mysql.com/downloads/mysql/ 注意:安装过程我们需要通过开启管理员权限来安装,否则会由于权限不足 ...
随机推荐
- HALCON形状匹配讲解
HALCON形状匹配讲解 https://blog.csdn.net/linnyn/article/details/50663328 https://blog.csdn.net/u014608071/ ...
- mysql 5.6 cmake的安装
# cmake \-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \-DMYSQL_DATADIR=/usr/local/mysql/data \-DSYSCONFDI ...
- vue title悬停
title 设置name="peo" title="" v-on:mouseenter="peoAndCarHover(item.signStatus ...
- 可能对Flutter应用程序开发有用的代码/库/专有技术列表
当我开始使用Flutter实施该应用程序时,我开始担心“如何最好地编写?”以及“如何使其更好地放置?”. 在这种情况下,您将需要参考GitHub上发布的代码和应用程序. 因此,我收集了似乎对Flu ...
- 小程序Java多次请求Session不变
微信小程序每次请求的sessionid是变化的,导致对应后台的session不一致,无法获取之前保存在session中的openid和sessionKey. 为了解决这个问题,需要强制同意每次小程序前 ...
- Java使用Sftp实现对跨服务器上传、下载、打包、写入相关操作
1.Maven引入jar <dependency> <groupId>com.jcraft</groupId> <artifactId>jsch< ...
- Qt QRect与QRectF的区别
一直在与QRect和QRectF打交道.甚至在使用过程中因为QRect而出现了致命的Bug.因为QRect在数据存储表示上有一个很大的“历史遗留问题”! QRect Class 也就是说,对于QR ...
- Teensy-HID攻击
title date tags layut 渗透利器-Teensy(低配版BadUSB) 2018-09-25 kali post 准备工作 一块 Teensy2.0++ 的板子(淘宝一搜就有) Ar ...
- IdentityServer4之Token令牌获取流程分析
1.asp.net core 是基于管道模式IdentityServer会在注册一个管道处理程序 IdentityServerMiddleware 类专门处理登录验证的逻辑,本次主要讲的是access ...
- FastReport 使用入门
FastReport 是微软开发的一款快速报表工具,使用起来非常方便简单 最关键的是快捷. 下面介绍一下 Fastreport在项目中的使用. 下图为其中一个效果图 首先 打开FastReport ...