Django ORM性能优化之count和len方法的选择(非常详细推荐干货)
接下来我将从源码层面分情况和应用分析我们在计算queryset数据集时是用orm的count函数计算长度还是用len函数计算数据集长度。
首先,我们知道ORM查询queryset数据集是惰性查询的,只有使用到数据集时,ORM才会真正去执行查询语句,然后ORM会把查询到的数据集缓存到内存中,下次我们使用数据集时是从缓存中取值的。这就是ORM的惰性查询机制和缓存机制,还不清楚可以找相应的博客了解其概念,首先理解这两点我们便能更好地理解接下来的场景及应用。
1.、场景一:queryset数据集已经使用然后缓存的情况下,我们使用queryset对象.count()方法时其底层源码是用的len()方法计算数量,所以在有缓存时用len()和count()是一样的;
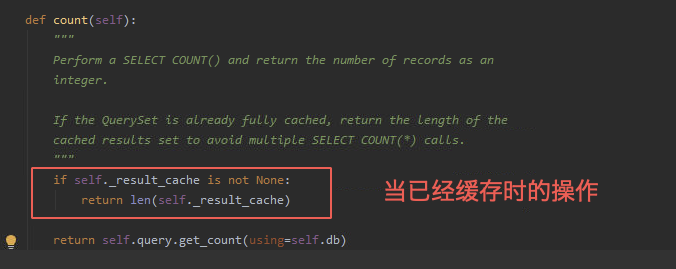
2、场景二:如果我们只想获得queryset对象的长度而不使用queryset对象的其他操作的情况下,count函数底层用了数据库的聚合函数查询计算结果,
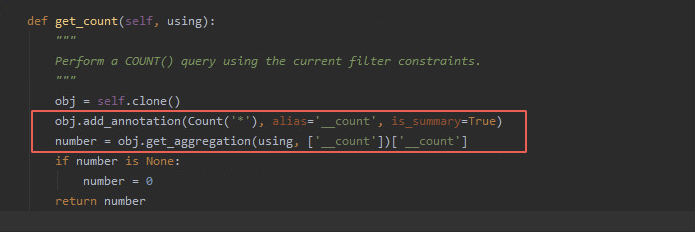
然后取其结果时间复杂度是O(1),而len方法底层实现是是需要获取整个queryset数据集时间复杂度为O(n),并且空间复杂度也为O(n),

这种场景下使用count函数更好;
3、场景三:在初始我们写了ORM查询语句,然后接下来我们既要计算查询后结果集的长度,又要对结果集做其他操作(如获取每个queryset对象的属性等),(这里暂时不考虑分页时limit减小查询范围的情况)。
接下来我们分析len方法和count方法他们分别会做什么事情,首先如果是len操作的话会先触发orm的查询操作得到queryset结果集然后缓存,然后后续对结果集的操作直接从缓存中取对应的queryset对象,然后是count函数操作因为之前我们讲过ORM的惰性查询机制,在我们执行count函数的时其实这时查询操作还未真正的运行,也就是此时还没有queryset结果集的缓存,所以此时我们执行count方法会执行一次聚合函数查询,然后后续我们使用到queryset集合时就会触发数据库查询得到queryset结果集然后缓存。
所以在场景三的情况下,使用len()方法计算结果集的长度时会比count方法会更有优势,因为此时少了一次对数据的聚合查询操作。
4、场景四:如果是在先执行了数据库查询结果集并使用到了queryset结果有了缓存的情况下,参考场景一此时用len方法或者count方法的效果是一样的。
5、场景五:这也是最复杂也比较难判断的情况,首先步骤一:我们写了数据库查询操作(此时还未使用到这个查询的结果集),然后步骤二这里我们可能使用len方法或者count方法来计算结果集的长度,接下来步骤三我们使用分页组件对结果集进行分页处理,再步骤四使用我们分页后的结果集。
这种场景的话对于步骤二我们是使用len方法还是count方法来计算结果集的长度时就需要我们考虑以下几个因素了,
1)如果此时我们使用的是len方法的话我们会缓存整个queryset结果集,并相当于遍历了整个结果集时间复杂度为O(n),空间复杂度为O(n),步骤三的分页操作对于我们后端的时间或者空间来说都没什么太大帮助了
2)如果此时我们使用的是count()方法来计算长度的话,我们会多一次数据库查询操作,但是步骤三的分页操作相当于查询结果集时sql语句然后limit 10(数字取决于我们分页的size),这样我们的时间复杂度和空间复杂度都可以降到O(1)
个人倾向的话可能在此种情况我会使用count方法,通过多一次数据库查询操作来降低时间和空间的复杂度还是挺划算的。
Django ORM性能优化之count和len方法的选择(非常详细推荐干货)的更多相关文章
- Django ORM性能优化 和 图片验证码
一,ORM性能相关 1. 关联外键, 只拿一次数据 all_users = models.User.objects.all().values('name', 'age', 'role__name') ...
- python django ORM 性能优化 select_related & prefetch_related
q = models.UserInfo.objects.all() select * from userinfo select * from userinfo inner join usertype ...
- Django的性能优化
Django的性能优化 一,利用标准数据库优化技术 传统数据库优化技术博大精深,不同的数据库有不同的优化技巧,但重心还是有规则的.在这里算是题外话,挑两点通用的说说: 索引,给关键的字段添加索引, ...
- Django之缓存+序列化+信号+ORM性能优化+验证码
缓存 由于Django是动态网站,所有每次请求均会去数据进行相应的操作,当程序访问量大时,耗时必然会更加 明显,最简单解决方式是使用:缓存,缓存将一个某个views的返回值保存至内存或者memcach ...
- Django数据库性能优化之 - 使用Python集合操作
前言 最近有个新需求: 人员基础信息(记作人员A),10w 某种类型的人员信息(记作人员B),1000 要求在后台上(Django Admin)分别展示:已录入A的人员B列表.未录入的人员B列表 团队 ...
- laravel 5.1 性能优化对比 - 框架提供的方法
写了一个项目发现性能不如人意. 于是便测试下, 看下性能瓶颈在什么地方. 使用 ab -n 20 http://www.lartest.com/ 软件环境: OS : windows 8.1 CPU: ...
- 移动端 CPU 的深度学习模型推理性能优化——NCHW44 和 Record 原理方法详解
用户实践系列,将收录 MegEngine 用户在框架实践过程中的心得体会文章,希望能够帮助有同样使用场景的小伙伴,更好地了解和使用 MegEngine ~ 作者:王雷 | 旷视科技 研发工程师 背景 ...
- Java 性能优化之 String 篇
原文:http://www.ibm.com/developerworks/cn/java/j-lo-optmizestring/ Java 性能优化之 String 篇 String 方法用于文本分析 ...
- 《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载 指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数 可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Run ...
随机推荐
- 超详细步骤---Linux下的最新Git版本安装
原文地址:https://blog.csdn.net/u010887744/article/details/53957613 [标注大头] 1.查看当前git版本:git --version 查看最新 ...
- 双链表【参照redis链表结构】
参照了Redis里面的双链表结构,可以说是完全复制粘贴,redis的双链表还是写的很通俗易懂的,没有什么花里胡哨的东西,但是redis还有个iter迭代器的结构来遍历链表.我这里就没有实现了,只是实现 ...
- java内存模型(JMM)和happens-before
目录 重排序 Happens-Before 安全发布 初始化安全性 java内存模型(JMM)和happens-before 我们知道java程序是运行在JVM中的,而JVM就是构建在内存上的虚拟机, ...
- Floyd-Warshall算法正确性证明
以下所有讨论,都是基于有向无负权回路的图上的.因为这一性质,任何最短路径都不会含有环,所以也不讨论路径中包含环的情形!并且为避免混淆,将"最短路径"称为权值最小的路径,将路径经过的 ...
- Struts2漏洞利用
Struts漏洞合集 Struts-S2-013漏洞利用 受影响版本 Struts 2.0.0 - Struts 2.3.14.1 漏洞利用 任意命令执行POC: ${(#_memberAccess[ ...
- Vue Router路由守卫妙用:异步获取数据成功后再进行路由跳转并传递数据,失败则不进行跳转
问题引入 试想这样一个业务场景: 在用户输入数据,点击提交按钮后,这时发起了ajax请求,如果请求成功, 则跳转到详情页面并展示详情数据,失败则不跳转到详情页面,只是在当前页面给出错误消息. 难点所在 ...
- Heartbeat+Haproxy实现负载均衡高可用
环境说明: 主机名 角色 IP地址 mylinux1.contoso.com heartbeat+haproxy eth0:192.168.100.121 eth1:172.16.100.121 my ...
- 单源最短路径:Dijkstra算法(堆优化)
前言:趁着对Dijkstra还有点印象,赶快写一篇笔记. 注意:本文章面向已有Dijkstra算法基础的童鞋. 简介 单源最短路径,在我的理解里就是求从一个源点(起点)到其它点的最短路径的长度. 当然 ...
- 5分钟入门pandas
pandas是在数据处理.数据分析以及数据可视化上都有比较多的应用,这篇文章就来介绍一下pandas的入门.劳动节必须得劳动劳动 1. 基础用法 以下代码在jupyter中运行,Python 版本3. ...
- 抓住CoAP协议的“心”
摘要 The Constrained Application Protocol(CoAP)是一种专用的Web传输协议,用于受约束的节点和受约束的(例如,低功率,有损)网络. 节点通常具有带少量ROM和 ...