10w行级别数据的Excel导入优化记录
需求说明
项目中有一个 Excel 导入的需求:缴费记录导入
由实施 / 用户 将别的系统的数据填入我们系统中的 Excel 模板,应用将文件内容读取、校对、转换之后产生欠费数据、票据、票据详情并存储到数据库中。
在我接手之前可能由于之前导入的数据量并不多没有对效率有过高的追求。但是到了 4.0 版本,我预估导入时Excel 行数会是 10w+ 级别,而往数据库插入的数据量是大于 3n 的,也就是说 10w 行的 Excel,则至少向数据库插入 30w 行数据。因此优化原来的导入代码是势在必行的。我逐步分析和优化了导入的代码,使之在百秒内完成(最终性能瓶颈在数据库的处理速度上,测试服务器 4g 内存不仅放了数据库,还放了很多微服务应用。处理能力不太行)。具体的过程如下,每一步都有列出影响性能的问题和解决的办法。
导入 Excel 的需求在系统中还是很常见的,我的优化办法可能不是最优的,欢迎读者在评论区留言交流提供更优的思路
声明:本文首发于博客园,作者:后青春期的Keats;地址:https://www.cnblogs.com/keatsCoder/ 转载请注明,谢谢!
一些细节
数据导入:导入使用的模板由系统提供,格式是 xlsx (支持 65535+行数据) ,用户按照表头在对应列写入相应的数据
数据校验:数据校验有两种:
- 字段长度、字段正则表达式校验等,内存内校验不存在外部数据交互。对性能影响较小
- 数据重复性校验,如票据号是否和系统已存在的票据号重复(需要查询数据库,十分影响性能)
数据插入:测试环境数据库使用 MySQL 5.7,未分库分表,连接池使用 Druid
迭代记录
第一版:POI + 逐行查询校对 + 逐行插入
这个版本是最古老的版本,采用原生 POI,手动将 Excel 中的行映射成 ArrayList 对象,然后存储到 List<ArrayList> ,代码执行的步骤如下:
- 手动读取 Excel 成 List<ArrayList>
- 循环遍历,在循环中进行以下步骤
- 检验字段长度
- 一些查询数据库的校验,比如校验当前行欠费对应的房屋是否在系统中存在,需要查询房屋表
- 写入当前行数据
- 返回执行结果,如果出错 / 校验不合格。则返回提示信息并回滚数据
显而易见的,这样实现一定是赶工赶出来的,后续可能用的少也没有察觉到性能问题,但是它最多适用于个位数/十位数级别的数据。存在以下明显的问题:
- 查询数据库的校验对每一行数据都要查询一次数据库,应用访问数据库来回的网络IO次数被放大了 n 倍,时间也就放大了 n 倍
- 写入数据也是逐行写入的,问题和上面的一样
- 数据读取使用原生 POI,代码十分冗余,可维护性差。
第二版:EasyPOI + 缓存数据库查询操作 + 批量插入
针对第一版分析的三个问题,分别采用以下三个方法优化
缓存数据,以空间换时间
逐行查询数据库校验的时间成本主要在来回的网络IO中,优化方法也很简单。将参加校验的数据全部缓存到 HashMap 中。直接到 HashMap 去命中。
例如:校验行中的房屋是否存在,原本是要用 区域 + 楼宇 + 单元 + 房号 去查询房屋表匹配房屋ID,查到则校验通过,生成的欠单中存储房屋ID,校验不通过则返回错误信息给用户。而房屋信息在导入欠费的时候是不会更新的。并且一个小区的房屋信息也不会很多(5000以内)因此我采用一条SQL,将该小区下所有的房屋以 区域/楼宇/单元/房号 作为 key,以 房屋ID 作为 value,存储到 HashMap 中,后续校验只需要在 HashMap 中命中
自定义 SessionMapper
Mybatis 原生是不支持将查询到的结果直接写人一个 HashMap 中的,需要自定义 SessionMapper
SessionMapper 中指定使用 MapResultHandler 处理 SQL 查询的结果集
@Repository
public class SessionMapper extends SqlSessionDaoSupport {
@Resource
public void setSqlSessionFactory(SqlSessionFactory sqlSessionFactory) {
super.setSqlSessionFactory(sqlSessionFactory);
}
// 区域楼宇单元房号 - 房屋ID
@SuppressWarnings("unchecked")
public Map<String, Long> getHouseMapByAreaId(Long areaId) {
MapResultHandler handler = new MapResultHandler();
this.getSqlSession().select(BaseUnitMapper.class.getName()+".getHouseMapByAreaId", areaId, handler);
Map<String, Long> map = handler.getMappedResults();
return map;
}
}
MapResultHandler 处理程序,将结果集放入 HashMap
public class MapResultHandler implements ResultHandler {
private final Map mappedResults = new HashMap();
@Override
public void handleResult(ResultContext context) {
@SuppressWarnings("rawtypes")
Map map = (Map)context.getResultObject();
mappedResults.put(map.get("key"), map.get("value"));
}
public Map getMappedResults() {
return mappedResults;
}
}
示例 Mapper
@Mapper
@Repository
public interface BaseUnitMapper {
// 收费标准绑定 区域楼宇单元房号 - 房屋ID
Map<String, Long> getHouseMapByAreaId(@Param("areaId") Long areaId);
}
示例 Mapper.xml
<select id="getHouseMapByAreaId" resultMap="mapResultLong">
SELECT
CONCAT( h.bulid_area_name, h.build_name, h.unit_name, h.house_num ) k,
h.house_id v
FROM
base_house h
WHERE
h.area_id = #{areaId}
GROUP BY
h.house_id
</select>
<resultMap id="mapResultLong" type="java.util.HashMap">
<result property="key" column="k" javaType="string" jdbcType="VARCHAR"/>
<result property="value" column="v" javaType="long" jdbcType="INTEGER"/>
</resultMap>
之后在代码中调用 SessionMapper 类对应的方法即可。
使用 values 批量插入
MySQL insert 语句支持使用 values (),(),() 的方式一次插入多行数据,通过 mybatis foreach 结合 java 集合可以实现批量插入,代码写法如下:
<insert id="insertList">
insert into table(colom1, colom2)
values
<foreach collection="list" item="item" index="index" separator=",">
( #{item.colom1}, #{item.colom2})
</foreach>
</insert>
使用 EasyPOI 读写 Excel
EasyPOI 采用基于注解的导入导出,修改注解就可以修改Excel,非常方便,代码维护起来也容易。
第三版:EasyExcel + 缓存数据库查询操作 + 批量插入
第二版采用 EasyPOI 之后,对于几千、几万的 Excel 数据已经可以轻松导入了,不过耗时有点久(5W 数据 10分钟左右写入到数据库)不过由于后来导入的操作基本都是开发在一边看日志一边导入,也就没有进一步优化。但是好景不长,有新小区需要迁入,票据 Excel 有 41w 行,这个时候使用 EasyPOI 在开发环境跑直接就 OOM 了,增大 JVM 内存参数之后,虽然不 OOM 了,但是 CPU 占用 100% 20 分钟仍然未能成功读取全部数据。故在读取大 Excel 时需要再优化速度。莫非要我这个渣渣去深入 POI 优化了吗?别慌,先上 GITHUB 找找别的开源项目。这时阿里 EasyExcel 映入眼帘:
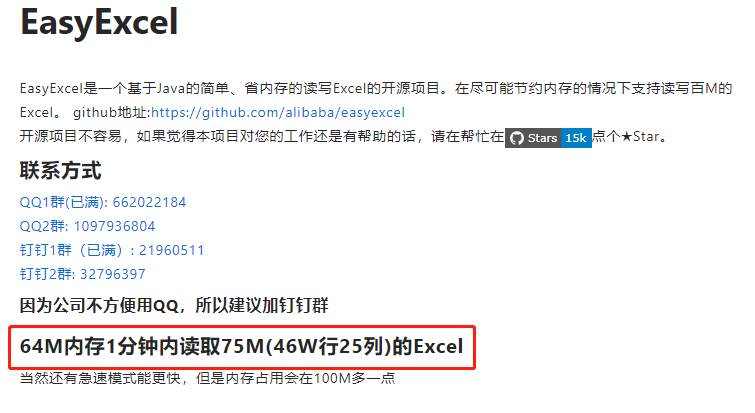
emmm,这不是为我量身定制的吗!赶紧拿来试试。EasyExcel 采用和 EasyPOI 类似的注解方式读写 Excel,因此从 EasyPOI 切换过来很方便,分分钟就搞定了。也确实如阿里大神描述的: 41w行、25列、45.5m 数据读取平均耗时 50s,因此对于大 Excel 建议使用 EasyExcel 读取。
第四版:优化数据插入速度
在第二版插入的时候,我使用了 values 批量插入代替逐行插入。每 30000 行拼接一个长 SQL、顺序插入。整个导入方法这块耗时最多,非常拉跨。后来我将每次拼接的行数减少到 10000、5000、3000、1000、500 发现执行最快的是 1000。结合网上一些对 innodb_buffer_pool_size 描述我猜是因为过长的 SQL 在写操作的时候由于超过内存阈值,发生了磁盘交换。限制了速度,另外测试服务器的数据库性能也不怎么样,过多的插入他也处理不过来。所以最终采用每次 1000 条插入。
每次 1000 条插入后,为了榨干数据库的 CPU,那么网络IO的等待时间就需要利用起来,这个需要多线程来解决,而最简单的多线程可以使用 并行流 来实现,接着我将代码用并行流来测试了一下:
10w行的 excel、42w 欠单、42w记录详情、2w记录、16 线程并行插入数据库、每次 1000 行。插入时间 72s,导入总时间 95 s。

并行插入工具类
并行插入的代码我封装了一个函数式编程的工具类,也提供给大家
/**
* 功能:利用并行流快速插入数据
*
* @author Keats
* @date 2020/7/1 9:25
*/
public class InsertConsumer {
/**
* 每个长 SQL 插入的行数,可以根据数据库性能调整
*/
private final static int SIZE = 1000;
/**
* 如果需要调整并发数目,修改下面方法的第二个参数即可
*/
static {
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "4");
}
/**
* 插入方法
*
* @param list 插入数据集合
* @param consumer 消费型方法,直接使用 mapper::method 方法引用的方式
* @param <T> 插入的数据类型
*/
public static <T> void insertData(List<T> list, Consumer<List<T>> consumer) {
if (list == null || list.size() < 1) {
return;
}
List<List<T>> streamList = new ArrayList<>();
for (int i = 0; i < list.size(); i += SIZE) {
int j = Math.min((i + SIZE), list.size());
List<T> subList = list.subList(i, j);
streamList.add(subList);
}
// 并行流使用的并发数是 CPU 核心数,不能局部更改。全局更改影响较大,斟酌
streamList.parallelStream().forEach(consumer);
}
}
这里多数使用到很多 Java8 的API,不了解的朋友可以翻看我之前关于 Java 的博客。方法使用起来很简单
InsertConsumer.insertData(feeList, arrearageMapper::insertList);
其他影响性能的内容
日志
避免在 for 循环中打印过多的 info 日志
在优化的过程中,我还发现了一个特别影响性能的东西:info 日志,还是使用 41w行、25列、45.5m 数据,在 开始-数据读取完毕 之间每 1000 行打印一条 info 日志,缓存校验数据-校验完毕 之间每行打印 3+ 条 info 日志,日志框架使用 Slf4j 。打印并持久化到磁盘。下面是打印日志和不打印日志效率的差别
打印日志

不打印日志

我以为是我选错 Excel 文件了,又重新选了一次,结果依旧

缓存校验数据-校验完毕 不打印日志耗时仅仅是打印日志耗时的 1/10 !
总结
提升Excel导入速度的方法:
- 使用更快的 Excel 读取框架(推荐使用阿里 EasyExcel)
- 对于需要与数据库交互的校验、按照业务逻辑适当的使用缓存。用空间换时间
- 使用 values(),(),() 拼接长 SQL 一次插入多行数据
- 使用多线程插入数据,利用掉网络IO等待时间(推荐使用并行流,简单易用)
- 避免在循环中打印无用的日志
如果你觉得阅读后有收获,不妨点个推荐吧
10w行级别数据的Excel导入优化记录的更多相关文章
- Hive修改行级别数据
我们知道Hive0.14版本之前是不支持行级别的插入,更新,删除的,0.14版本之后可以通过修改相关配置得以支持,但是在不修改默认配置的情况下是不是完全没有办法呢?不是的,这里有个比较简单的方法,前提 ...
- 销售合同金额数据从Excel导入
一.业务需求 1.新增了销售合同金额的字段,但是老数据没有这个字段:所以销售合同金额从销售合同附件的各品种金额之和. 2.制作好excel字段模板,将此模板发送给销售业务部门来统计并完成excel表格 ...
- 利用PL/SQL Developer工具导出数据到excel,导入excel数据到表
使用PL/SQL Developer工具. 导出: 1.执行select 语句查询出需要导出的数据. 2.在数据列表中右键,选择save results.保存为.csv文件,然后已excel方式打开就 ...
- 关于Java导出100万行数据到Excel的优化方案
1>场景 项目中需要从数据库中导出100万行数据,以excel形式下载并且只要一张sheet(打开这么大文件有多慢另说,呵呵). ps:xlsx最大容纳1048576行 ,csv最大容纳1048 ...
- 批量数据的Excel导入
public void importIndexHistoryByCsv(String fileName) { logger.info("开始获取Csv文件导入到数据库,csv文件名为:&qu ...
- SQL server 导入数据 (excel导入到SQL server数据库)
打开数据库SQL server ,右键数据库,任务,导入数据 点击下一步 选择数据源类型 选择路径,点击下一步 选择将要生成的类型 选择登陆方式 选中,点击下一步 点击编辑映射可以修改将要生成的表,点 ...
- 拷贝txt文本中的某行的数据到excel中
package com.hope.day01;import java.io.*;import java.util.ArrayList;public class HelloWorld { publ ...
- JAVA使用POI如何导出百万级别数据(转)
https://blog.csdn.net/happyljw/article/details/52809244 用过POI的人都知道,在POI以前的版本中并不支持大数据量的处理,如果数据量过多还会 ...
- JAVA使用POI如何导出百万级别数据
用过POI的人都知道,在POI以前的版本中并不支持大数据量的处理,如果数据量过多还会常报OOM错误,这时候调整JVM的配置参数也不是一个好对策(注:jdk在32位系统中支持的内存不能超过2个G,而在6 ...
随机推荐
- Java实现 蓝桥杯 算法训练 字串统计
算法训练 字串统计 时间限制:1.0s 内存限制:512.0MB 问题描述 给定一个长度为n的字符串S,还有一个数字L,统计长度大于等于L的出现次数最多的子串(不同的出现可以相交),如果有多个,输出最 ...
- Java实现 蓝桥杯VIP 算法训练 删除多余括号
算法训练 删除多余括号 时间限制:1.0s 内存限制:512.0MB 问题描述 从键盘输入一个含有括号的四则运算表达式,要求去掉可能含有的多余的括号,结果要保持原表达式中变量和运算符的相对位置不变,且 ...
- Java实现 蓝桥杯VIP 算法提高 盾神与砝码称重
算法提高 盾神与砝码称重 时间限制:1.0s 内存限制:256.0MB 提交此题 查看参考代码 问题描述 有一天,他在宿舍里无意中发现了一个天平!这个天平很奇怪,有n个完好的砝码,但是没有游码.盾神为 ...
- java实现土地测量
** 土地测量** 造成高房价的原因有许多,比如土地出让价格.既然地价高,土地的面积必须仔细计算.遗憾的是,有些地块的形状不规则,比如是如图[1.jpg]中所示的五边形. 一般需要把它划分为多个三角形 ...
- Java实现第八届蓝桥杯取数位
取数位 求1个整数的第k位数字有很多种方法. 以下的方法就是一种. 还有一个答案:f(x/10,k--) public class Main { static int len(int x){ // 返 ...
- LeetCode 75,90%的人想不出最佳解的简单题
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题的44篇文章,我们一起来看下LeetCode的75题,颜色排序 Sort Colors. 这题的官方难度是Medi ...
- 时间序列神器之争:prophet VS lstm
一.需求背景 我们福禄网络致力于为广大用户提供智能化充值服务,包括各类通信充值卡(比如移动.联通.电信的话费及流量充值).游戏类充值卡(比如王者荣耀.吃鸡类点券.AppleStore充值.Q币.斗鱼币 ...
- JavaScript选择器和节点操作
感谢:链接(视频讲解很清晰) 下文中讲解用到Chrome中的console调试台,如果不懂最好先看一下:链接 JavaScript选择器 作用:选取html中的标签等内容,最重要的还是为节点的操作(增 ...
- Fibonacci(模板)【矩阵快速幂】
Fibonacci 题目链接(点击) Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 20989 Accepted: 14 ...
- PyQt5 FileDialog的使用例子
加载***.ui文件可以使用: loadUi('main_window.ui', self) self.btnFileChoose.clicked.connect(self.getFolderName ...