python爬虫(九) requests库之post请求
1、方法:
response=requests.post("https://www.baidu.com/s",data=data)
2、拉勾网职位信息获取
因为拉勾网设置了反爬虫机制,在拉勾网中,一些页面的信息获取方法是post,所以就用到了post方法

在拉勾网中,我们搜索与python相关的职业,如果我们爬取这一页的信息,是没有职业的信息的,因为职业的信息在另外的jsp页面上,所以我们需要在这个界面上爬取到职业的信息,选择一个城市+学生身份
同样,在页面右击,选择查看元素,找到网络,刷新,选择跟职位相关的
然后右侧的网址为url:
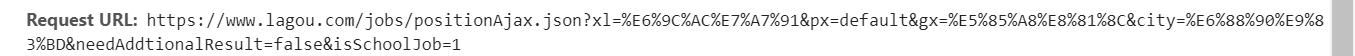
这个页面上面的网址为urls:

可以看到他的获取方法是post,所以我们要获取职位的信息,需要post函数
这时我们需要用到data参数
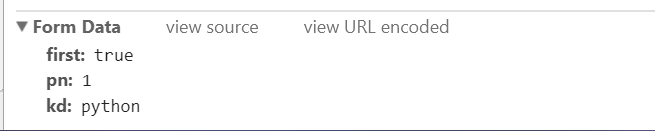
以及请求头:


代码如下:
import requests url='https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1'
data ={
'first':"true",
'pn':1,
'kd':"python"
}
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
'Referer':"https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1",
'Accept':'application/json, text/javascript, */*; q=0.01'
}
urls='https://www.lagou.com/jobs/list_python/p-city_252?px=default&gx=%E5%85%A8%E8%81%8C&gj=&xl=%E6%9C%AC%E7%A7%91&isSchoolJob=1#filterBox'
s = requests.Session()
s.get(urls, headers=headers, timeout=3)
cookie = s.cookies
response = s.post('https://www.lagou.com/jobs/positionAjax.json?xl=%E6%9C%AC%E7%A7%91&px=default&gx=%E5%85%A8%E8%81%8C&city=%E6%88%90%E9%83%BD&needAddtionalResult=false&isSchoolJob=1',data=data,headers=headers, cookies=cookie,timeout=5) print(response.text)
with open('py.html', 'w') as file:
file.write(response.text)
中间出现错误:您操作太频繁,请稍后再访问,解决方法参考网址:http://www.freesion.com/article/140098505/
python爬虫(九) requests库之post请求的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
- python爬虫(1)requests库
在pycharm中安装requests库的一种方法 首先找到设置 搜索然后安装,蓝色代表已经安装 requests库中的get请求 与HTTP协议相对应,requests库也有七种请求方式. 获取ur ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之Requests库的基本使用
import requests response = requests.get('http://www.baidu.com/') print(type(response)) print(respons ...
- Python爬虫系列-Requests库详解
Requests基于urllib,比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 实例引入 import requests response = requests.get( ...
- python 爬虫 基于requests模块的get请求
需求:爬取搜狗首页的页面数据 import requests # 1.指定url url = 'https://www.sogou.com/' # 2.发起get请求:get方法会返回请求成功的响应对 ...
随机推荐
- MySQL删除语句比较,清空表数据,重置自增长索引
drop truncate delete 程度从强到弱 1.drop table tbdrop将表格直接删除,没有办法找回 2.truncate (table) tbtruncate 删除表中的所有数 ...
- web项目获取路径
Java获取路径的各种方法: (1).request.getRealPath("/"); //不推荐使用获取工程的根路径 (2).request.getRealPath(requ ...
- .net core 通过代码创建数据库表
0.结构: 1.API using System; using System.Collections.Generic; using System.IO; using System.Linq; usin ...
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立) 我们提到, ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
- 新手学习arm的建议
本文来自:chen4013874的博客 如果您是ARM初学者或者以前是51单片机应用开发工程师,想快速进入32位ARM嵌入式开发领域,建议您阅读本文档.本文档是我们结合多年ARM开发经验,针对初学者对 ...
- C语言程序设计(二)
目录: 1.算法基本概念 2.认识循环语句 3.算法的表示法 4.求素数 5.求闰年 6.判断一个数是否为回文数 算法基本概念: (一)一个程序主要包含的2方面信息: 1.对数据的描述,在程序中要 ...
- codeforces-Three Friends
Three Friends Three friends are going to meet each other. Initially, the first friend stays at the ...
- mysql DATE_FORMAT 函数使用
使用DATE_FORMAT 查询数据库中时间类型显示 SELECT a.name ,a.uuid ,p.assess_price as assessPrice ,p.assess_date as as ...
- 深入剖析Windows专业版安装Docker引擎和Windows家庭版Docker引擎安装的区别
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 公司使用的电脑是Windows专业版,所以配置本机的Docker时会方便许多,后续由于需 ...