【JUC】如何理解线程池?第四种使用线程的方式
线程池的概念
线程池的主要工作的控制运行的线程的数量,处理过程种将任务放在队列,线程创建后再启动折现任务,如果线程数量超过了最大的数量,则超过部分的线程排队等待,直到其他线程执行完毕后,从队列种取出任务来执行。
处理流程:
1.线程池判断核心线程池的线程是否全部在执行任务?
1.1 不是:创建一个新的工作线程执行任务。
1.2 是:
2. 线程池判断工作队列是否已经满了?
2.1 没有满:将新提交的任务存储在工作队列中。
2.2 满了:
3. 线程池判断线程池的线程是否都在工作?
3.1 是:交由饱和策略来处理这个任务。
3.2 不是:创建一个新的工作线程来执行任务。
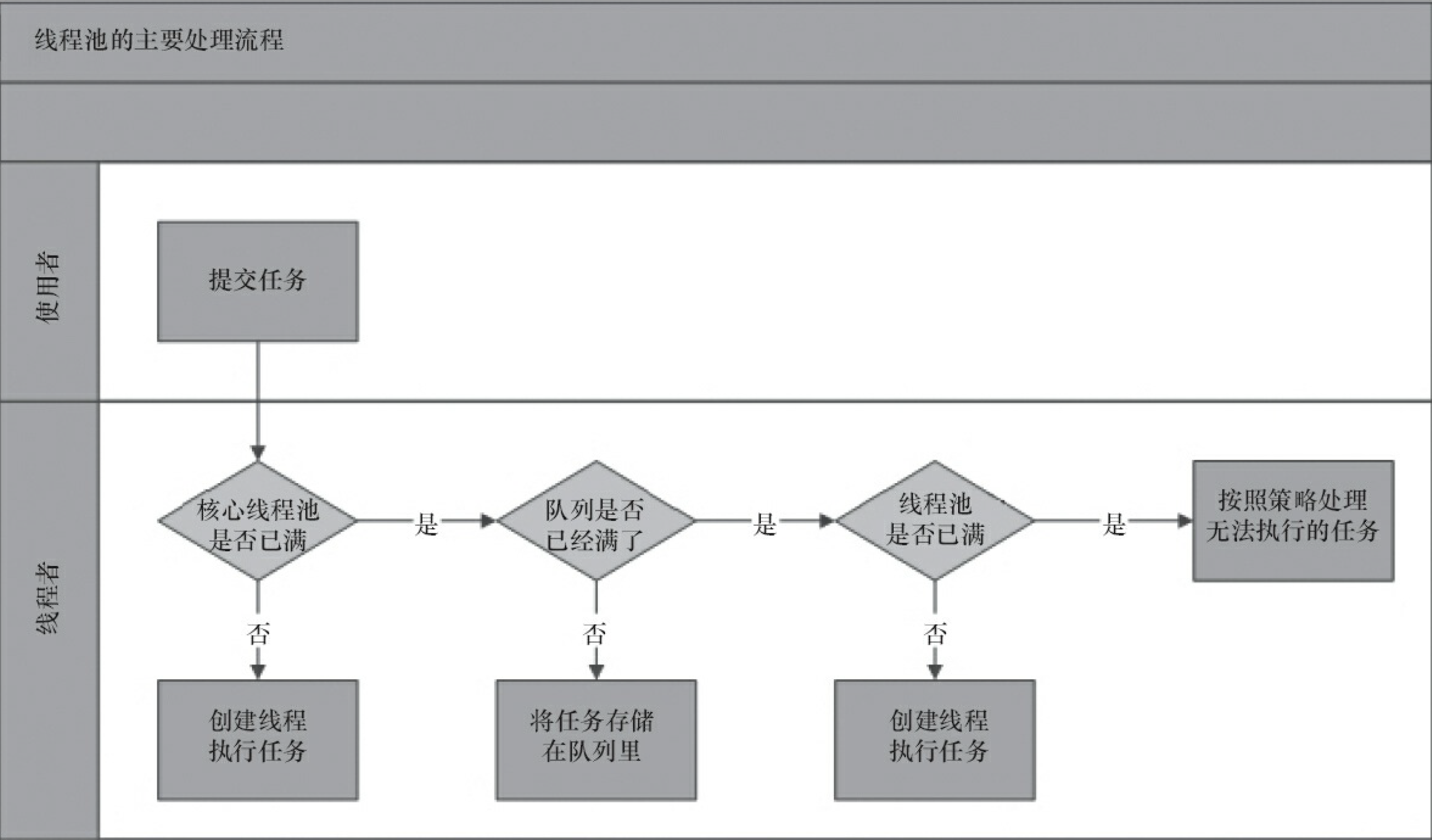
特点:线程复用、控制最大并发数、管理线程。
线程池的优势
1. 降低资源消耗,通过重复利用已经创建的线程,降低了线程创建和销毁产生的消耗。
2. 提高响应速度,任务到达时,任务不需要等待线程创建就能立即执行。
3. 提高线程的可管理性,线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行同一的分配、调优和监控。
线程池的使用
Java线程池是通过Executor框架实现的,该框架中用到了Executor、Executors、ExecutorService和ThreadPoolExecutor类。

具体使用示例:
public static void fixedThreadPool() {
ExecutorService threadPool = Executors.newFixedThreadPool(5);//固定线程
try {
for (int i = 0; i < 10; i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName());
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
threadPool.shutdown();
}
}
输出结果
pool-1-thread-2
pool-1-thread-4
pool-1-thread-2
pool-1-thread-5
pool-1-thread-1
pool-1-thread-3
pool-1-thread-5
pool-1-thread-1
pool-1-thread-2
pool-1-thread-4
线程池的源码及重要参数
Executors.newFixedThreadPool(int)
固定线程数,适用场景:执行长期任务,性能好。
1 public static ExecutorService newFixedThreadPool(int nThreads) {
2 return new ThreadPoolExecutor(nThreads, nThreads,
3 0L, TimeUnit.MILLISECONDS,
4 new LinkedBlockingQueue<Runnable>());
5 }
Executors.newSingleThreadExecutor()
一池一个线程,使用场景:一个任务接一个任务执行的时候。
1 public static ExecutorService newSingleThreadExecutor() {
2 return new FinalizableDelegatedExecutorService
3 (new ThreadPoolExecutor(1, 1,
4 0L, TimeUnit.MILLISECONDS,
5 new LinkedBlockingQueue<Runnable>()));
6 }
Executors.newCachedThreadPool()
N个线程,带缓存,适用场景:执行很多短期异步的小程序或者负载较轻的服务器。
1 public static ExecutorService newCachedThreadPool() {
2 return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
3 60L, TimeUnit.SECONDS,
4 new SynchronousQueue<Runnable>());
5 }
ThreadPoolExecutor
ThreadPoolExecutor的执行示意图:
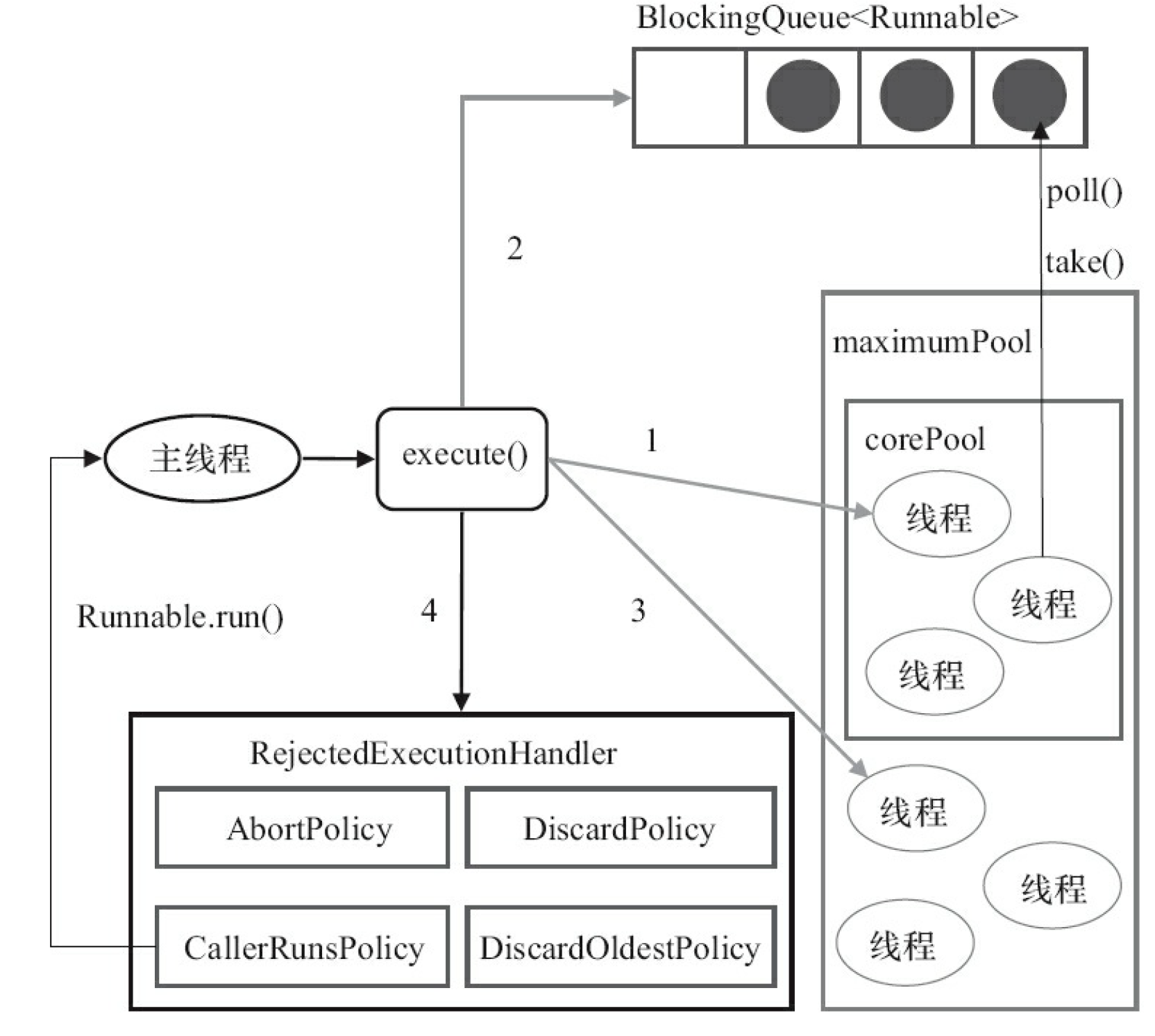
1. corePoolSize:线程池中的常驻核心线程数
2. maximumPoolSize:线程池能够容纳同时执行的最大线程数,必须大于等于1【扩容的上限】。如果工作队列满了,core也满了的时候,线程池会扩容,直到达到maximumPoolSize(新来的任务会直接抢占扩容线程,不进入工作队列,工作队列中的任务继续等待)。
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(
2, //corePoolSize
5, //maximumPoolSize
100L, //keepAliveTime
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());//N个线程带缓存
try {
for (int i = 1; i <= 6; i++) {
final int tmp = i;
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"线程"+",执行任务"+tmp);
try {
TimeUnit.SECONDS.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
threadPool.shutdown();
}
}
输出结果:
pool-1-thread-2线程,执行任务2
pool-1-thread-3线程,执行任务6
pool-1-thread-1线程,执行任务1
pool-1-thread-3线程,执行任务3
pool-1-thread-2线程,执行任务4
pool-1-thread-1线程,执行任务5
当线程池中有2个核心线程时,线程1和2正在执行任务1和2,任务3、4、5在工作队列中等候,此时工作队列满了,core也满了的时候,且core< maximumPoolSize,任务6的出现引起线程池的扩容,任务6在3、4、5执行任务前进行了抢占。所以从输出结果可以看出新来的任务会直接抢占新扩容的线程。
3. keepAliveTime:多余的空闲线程的存活时间。当前线程数超过corePoolSize的时候,空闲时间达到keepAliveTime时,多余的空闲线程会被销毁直到剩下corePoolSize的数量的线程。
4. unit:keepAliveTime的单位
5. workQueue:(阻塞队列)工作队列,任务等待区,被提交但是没有被执行的任务。
6. threadFactory:线程工厂,用于创建线程,一般用默认即可。
7. handler:拒绝策略。当队列满了并且工作线程大于线程池的最大线程数的时候触发拒绝策略。
5个参数的构造函数
1 public ThreadPoolExecutor(int corePoolSize,
2 int maximumPoolSize,
3 long keepAliveTime,
4 TimeUnit unit,
5 BlockingQueue<Runnable> workQueue) {
6 this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
7 Executors.defaultThreadFactory(), defaultHandler);
8 }
7个参数的构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
线程池的底层工作原理及源码
ThreadPoolExecutor执行execute方法分下面4种情况。
1)如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
2)如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
3)如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执行这一步骤需要获取全局锁)。
4)如果创建新线程将使当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//如果线程数小于核心线程数,创建线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程数大于等于核心线程数或线程创建失败,当前任务加入工作队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果线程数不处于运行中或人物失效无法放入队列,
//且当前线程数量小于最大允许的线程数,则创建一个线程执行任务
else if (!addWorker(command, false))
reject(command);
}
工作线程:线程池创建线程时,会将线程封装成工作线程Worker,Worker在执行完任务后,还会循环获取工作队列里的任务来执行。我们可以从Worker类的run()方法里看到。
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {//循环获取工作队列里的任务执行
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
线程池的拒绝策略(RejectedExecutionHandler)
当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。
1. AbortPolicy:直接抛出异常。RejectedExecutionException
2. CallerRunsPolicy:只用调用者所在线程来运行任务。不抛弃任务,也不抛出异常,将任务回退到调用者。
例如:任务数 > maximumPoolSize+Queue.capacity=8的时候拒绝任务9和10,任务回退给调用者,示例中的调用者就是main线程。
pool-1-thread-1线程,执行任务1
main线程,执行任务9
pool-1-thread-3线程,执行任务6
pool-1-thread-2线程,执行任务2
pool-1-thread-5线程,执行任务8
pool-1-thread-4线程,执行任务7
main线程,执行任务10
pool-1-thread-3线程,执行任务3
pool-1-thread-1线程,执行任务5
pool-1-thread-5线程,执行任务4
3. DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
4. DiscardPolicy:不处理,丢弃掉。
任务队列(runnableTaskQueue)
1. ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。
2. LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
3. SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
在实际开发中选择那种线程池?
三种:单一/固定数/可变,都不能用。为什么不用?
在实际的开发中线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。
因为不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者过度切换的问题。
线程池不允许适用Executors去创建,而是通过ThreadPoolExecutor的方式,可以避免资源耗尽的风险。
Executors中的线程池对象存在的问题:
1. FixedThreadPool和SingleThreadPool:允许请求队列的长度为Integer.MAX_VALUE,可能会堆积大量请求,导致OOM
2. CachedThreadPool和ScheduledThreadPool:允许创建线程数量为Integer.MAX_VALUE,可能会创建大量请求,导致OOM
所以应该选择自定义线程池。
如何配置自定义的线程池参数?
首先查询服务器是几核的?Runtime.getRuntime().availableProcessors();
1. CPU密集型
任务需要大量的运算,而没有阻塞,CPU一直全速运行,CPU密集任务只有在真正的多核CPU上才可能得到加速。(通过多线程)
应该配置尽可能少的线程数量:CPU核数+1个线程的线程池
2. IO密集型
IO密集型任务并不是一直执行任务,则应配置尽可能多的线程,
CPU核数 * 2
CPU核数 / 1 - 阻塞系数(0.8~0.9)
补充:CPU密集 & IO密集
CPU密集型,又称计算密集型任务。它的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。
IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少。
【JUC】如何理解线程池?第四种使用线程的方式的更多相关文章
- Java-五种线程池,四种拒绝策略,三种阻塞队列(转)
Java-五种线程池,四种拒绝策略,三种阻塞队列 三种阻塞队列: BlockingQueue<Runnable> workQueue = null; workQueue = n ...
- java线程池和五种常用线程池的策略使用与解析
java线程池和五种常用线程池策略使用与解析 一.线程池 关于为什么要使用线程池久不赘述了,首先看一下java中作为线程池Executor底层实现类的ThredPoolExecutor的构造函数 pu ...
- java线程池与五种常用线程池策略使用与解析
背景:面试中会要求对5中线程池作分析.所以要熟知线程池的运行细节,如CachedThreadPool会引发oom吗? java线程池与五种常用线程池策略使用与解析 可选择的阻塞队列BlockingQu ...
- Java线程池的四种创建方式
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程. newFix ...
- juc线程池原理(四): 线程池状态介绍
<Thread之一:线程生命周期及五种状态> <juc线程池原理(四): 线程池状态介绍> 线程有5种状态:新建状态,就绪状态,运行状态,阻塞状态,死亡状态.线程池也有5种状态 ...
- Java多线程系列--“JUC线程池”05之 线程池原理(四)
概要 本章介绍线程池的拒绝策略.内容包括:拒绝策略介绍拒绝策略对比和示例 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3512947.html 拒绝策略 ...
- 四种Java线程池用法解析
本文为大家分析四种Java线程池用法,供大家参考,具体内容如下 http://www.jb51.net/article/81843.htm 1.new Thread的弊端 执行一个异步任务你还只是如下 ...
- 面试题:四种Java线程池用法解析 !=!=未看
1.new Thread的弊端 执行一个异步任务你还只是如下new Thread吗? 1 2 3 4 5 6 7 8 new Thread(new Runnable() { @Override ...
- JUC线程池之 线程池的5种状态:Running, SHUTDOWN, STOP, TIDYING, TERMINATED
线程池有5种状态:Running, SHUTDOWN, STOP, TIDYING, TERMINATED. 线程池状态定义代码如下: private final AtomicInteger ctl ...
随机推荐
- 你这些知识点都不会,你学个锤子SQL数据库!
全套的数据库的知识都在这里,持续更新中ing 快戳我查看,快戳戳,不管是Oracle还是mysql还是sqlsever,SQL语言都是基础. 一.关系 单一的数据结构----关系 现实世界的实体以及实 ...
- 图论--差分约束--POJ 2983--Is the Information Reliable?
Description The galaxy war between the Empire Draco and the Commonwealth of Zibu broke out 3 years a ...
- UDP广播的客户端和服务器端的代码设计
实验环境 linux 注意: 使用UDP广播,是客户端发送广播消息,服务器端接收消息.实际上是客户端探测局域网中可用服务器的一种手段.客户端发送,服务器端接收,千万不能弄混淆!!! 为了避免混淆,本文 ...
- jmeter正则表达式提取多个数据/一组数据时,应该怎么做——debug sampler的使用
背景:今天有个接口需要借助前面接口产生的一组ids数据,来作为入参使用,但是之前都是提取单个接口,所以到底怎么提取接口,遇到了很大的问题,按照多方查取资料都没有成功,最终在一个不相关帖子的最后一句话被 ...
- FarmCraft
题意:mhy住在一棵有n个点的树的1号结点上,每个结点上都有一个妹子.mhy从自己家出发,去给每一个妹子都送一台电脑,每个妹子拿到电脑后就会开始安装zhx牌杀毒软件,第i个妹子安装时间为ci.树上的每 ...
- 分治思想--快速排序解决TopK问题
----前言 最近一直研究算法,上个星期刷leetcode遇到从两个数组中找TopK问题,因此写下此篇,在一个数组中如何利用快速排序解决TopK问题. 先理清一个逻辑解决TopK问题→快速排序→递 ...
- Tarjan缩点割点(模板)
描述:https://www.luogu.com.cn/problem/P3387 给定一个 nn 个点 mm 条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大.你只需要求出这个权 ...
- Qt之xml文件解析
XML文件简介 XML - EXtensible Markup Language,可拓展标记语言 Qt中加载XML模块 .pro 文件中添加 QT += xml Qt的XML访问方式 引用:https ...
- TP5整合的导出Excel中没有图片和包含图片两种方法
之前做了个项目需要导出Excel文件 ,我在网上查了许多资料,最后终于搞定了 ,现在把代码贴到下面 先导入库文件:将文件phpoffice放在根目录的vendor下.获取文件点击:链接:https:/ ...
- HTML简单的伪装与造假
利用浏览器制止台能简单的修改内容,致使其造成伪装. 打开网页控制台后,不要管那些眼花撩乱的代码,我们直接寻找控制台顶部的 Tab 栏 找到 Console 这个 Tab,点击它,把代码 documen ...