使用HtmlAgilityPack和ScrapySharp抓取网页数据遇到的几个问题解决方法——格式编码问题
需要用到对应市区县街道居委会的区域编码,于是找到统计局的网页,对这些数据进行抓取,用到了HtmlAgilityPack和ScrapySharp,由于也是第一次从网页抓取数据,所以对于HtmlAgilityPack和ScrapySharp的使用也是不熟悉,期间遇到了很多问题,在这里对其做下总结
对于HtmlAgilityPack和ScrapySharp的使用,在网上有大量的使用demo,不过看来看去基本都是同一篇,也不知道谁是原作者,这里附上天方的博文,demo就不抄了,附上链接,需要的可以在去看看
TianFang-使用ScrapySharp快速从网页中采集数据
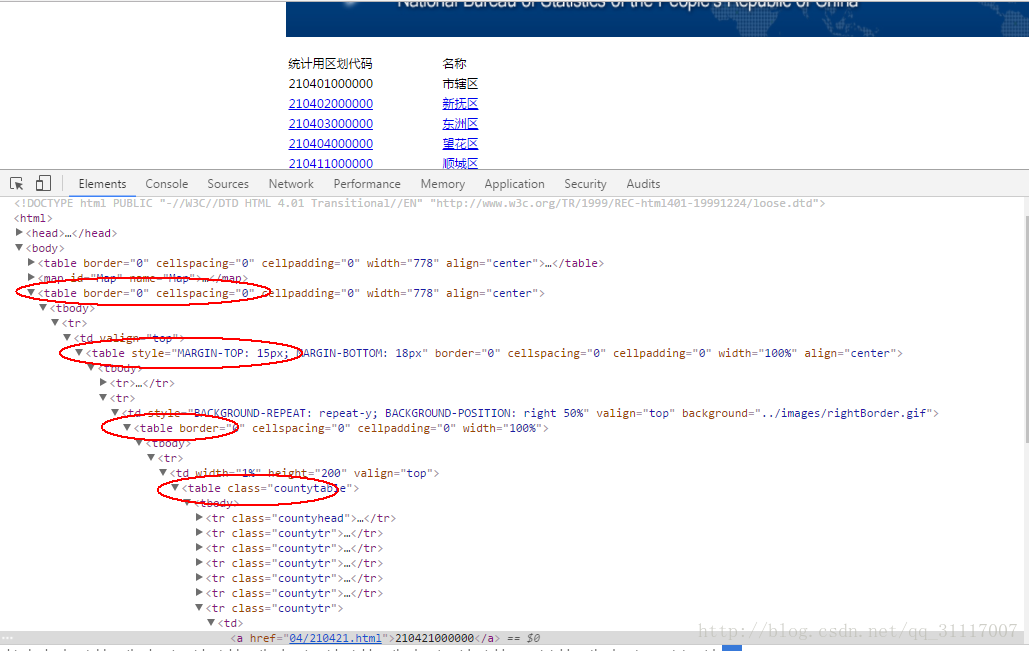
这里的CSS选择器的用法很简单,跟我们写CSS对HTML元素做定位是一样的。由于统计局的网页内容如下图
一个table套一个table,连套四个,而我们抓取数据又不仅仅是抓取一个页面的内容,所以这里只能找统一的规律,最后直接用了简单粗暴的方法var divs = html.CssSelect("table table table table tr");//直接获取到最底层的table的tr
在取到对应的值后,又遇到个问题,抓取的数据无论是读出到控制应用台还是保存到文本中,读取到的中文都是问号,最终发觉是格式编码的问题,demo上的网页用的格式编码是utf-8,而ScrapySharp抓取的默认格式编码应该也是utf-8所以不会出现问题,而统计局这的编码格式是gbk2312,因为请求抓取数据没有使用正确的编码格式,所以导致抓取到的数据变成乱码。
正如前面所说,百度一搜基本都是天方的那一篇博文,根本没有一个提出类似问题的解决方案,而且ScrapySharp的使用文档也找不到,最后在一篇擦边的文章中找到了解决方法代码如下
var browser1 = new ScrapingBrowser { Encoding = Encoding.GetEncoding("gb2312") };//在定义抓取实体时,对其进行设置,之前一直在对抓取之后的内容进行编码转换,结果都没有任何作用,真正的转换是要在抓取之前对请求进行设置至此网页内容的抓取基本是成功的了,于是开启程序开始让它抓取数据
但是在程序运行过程中遇到一个问题就是有时网络出现不稳定或者过于频繁访问该网站,导致报502错误,程序就会报异常,我的解决方法是用try catch去抓取网页内容,如果异常了这给内容赋空字符串,让它继续跑下去,这样就没有问题了,不过这个不算是一个好的解决方法,奈何目前能力有限,就只能这么用着先了
使用HtmlAgilityPack和ScrapySharp抓取网页数据遇到的几个问题解决方法——格式编码问题的更多相关文章
- 使用HtmlAgilityPack批量抓取网页数据
原文:使用HtmlAgilityPack批量抓取网页数据 相关软件点击下载登录的处理.因为有些网页数据需要登陆后才能提取.这里要使用ieHTTPHeaders来提取登录时的提交信息.抓取网页 Htm ...
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Asp.net 使用正则和网络编程抓取网页数据(有用)
Asp.net 使用正则和网络编程抓取网页数据(有用) Asp.net 使用正则和网络编程抓取网页数据(有用) /// <summary> /// 抓取网页对应内容 /// </su ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
- c#抓取网页数据
写了一个简单的抓取网页数据的小例子,代码如下: //根据Url地址得到网页的html源码 private string GetWebContent(string Url) { string strRe ...
- 使用JAVA抓取网页数据
一.使用 HttpClient 抓取网页数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ...
- 【iOS】正則表達式抓取网页数据制作小词典
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/xn4545945/article/details/37684127 应用程序不一定要自己去提供数据. ...
- 01 UIPath抓取网页数据并导出Excel(非Table表单)
上次转载了一篇<UIPath抓取网页数据并导出Excel>的文章,因为那个导出的是table标签中的数据,所以相对比较简单.现实的网页中,有许多不是通过table标签展示的,那又该如何处理 ...
- 使用HtmlAgilityPack抓取网页数据
XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. 下面列出了最有用的路径表达式: nodename:选取此节点的所有 ...
随机推荐
- 二十三、NFS企业级优化
nfs内核优化:(对于本地文件系统也是有效的) [root@nfsserve ~]# cat /proc/sys/net/core/rmem_default(该文件指定了接收套接字缓冲区大小的缺省值) ...
- 54)PHP,访问修饰符
类外就是你再实例化成对象的时候 用你类里面的变量 继承的类内, 就是子类里面,但是实例化对象时,不能用 本类内, 只在本类的定义时用,子类不能用.
- file_get_contents为何无法采集某些压缩过的网站
有些网站直接用file_get_contents就能采集, 但是有些不行. 于是可以在网址前加入 'compress.zlib://‘ $url = 'compress.zlib://' . 'htt ...
- 在CMD中操作mysql数据库出现中文乱码解决方案
百度了一下..有说将cmd字符编码用chcp命令改为65001(utf8字符编码),可这样之后根本无法输入中文,查询出的中问结果依旧乱码 其实,只要保证cmd客户端和MySQL两者编码一致即可. 但现 ...
- cs231n spring 2017 Python/Numpy基础
本文使根据CS231n的讲义整理而成(http://cs231n.github.io/python-numpy-tutorial/),以下内容基于Python3. 1. 基本数据类型:可以用 prin ...
- python去除列表中重复元素的方法
列表中元素位置的索引用的是L.index 本文实例讲述了Python去除列表中重复元素的方法.分享给大家供大家参考.具体如下: 比较容易记忆的是用内置的set 1 2 3 l1 = ['b','c', ...
- C语言Windows程序设计—— 使用计时器
传统意义上的计时器是指利用特定的原理来测量时间的装置, 在古代, 常用沙漏.点燃一炷香等方式进行粗略的计时, 在现代科技的带动下, 计时水平越来越高, 也越来越精确, 之所以需要进行计时是在很多情况下 ...
- mongoDB连接信息及生成对应的collection生成代码
.net,个人封装MONGODDB的操作. using System; using System.Collections.Generic; using System.Linq; using Syste ...
- git使用的简要介绍
GIT """ 什么是git:版本控制器 - 控制的对象是开发的项目代码 代码开发时间轴:需求1 > 版本库1 > 需求2 > 版本库2 > 版本 ...
- <JZOJ5938>分离计划
emm骚操作 #include<cstdio> #include<iostream> #include<cstring> #include<algorithm ...