(数据科学学习手札87)利用adjustText解决matplotlib文字标签遮挡问题
本文示例代码、数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在进行数据可视化时我们常常需要在可视化作品上进行一些文字标注,譬如对散点图我们可以将每个散点对应的属性信息标注在每个散点旁边,但随着散点量的增多,或图像上的某个区域聚集了较多的散点时,叠加上的文字标注会挤在一起相互叠置,出现如图1所示的情况:
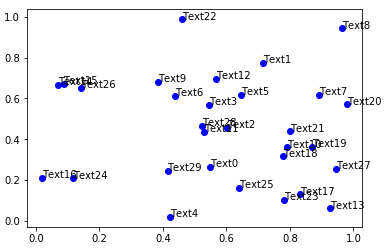 图1
图1
出现这种情况非常影响数据可视化作品的呈现效果,而我们下面要介绍的adjustText是一个辅助matplotlib所绘制的图像自动调整文字位置以缓解遮挡现象的库,其灵感来源于R中非常著名的辅助ggplot2解决文字遮挡问题的ggrepel:
 图2
图2
它通过算法迭代,在一轮轮的迭代过程中逐渐消除文字遮挡现象:
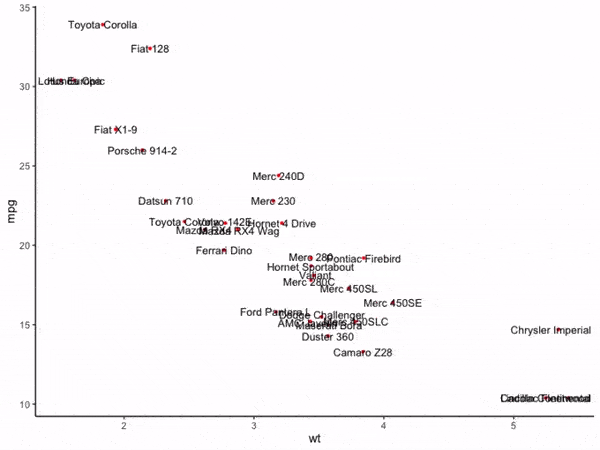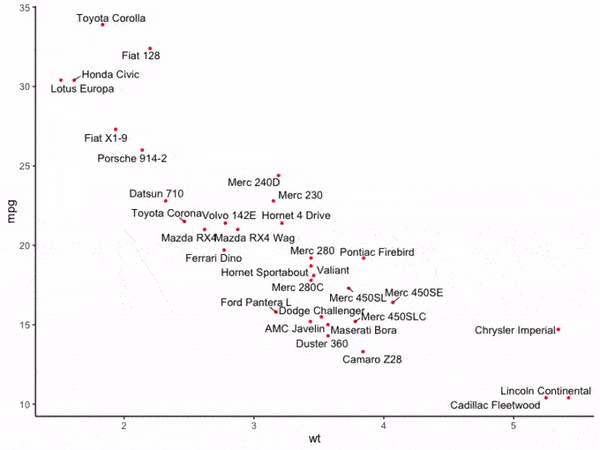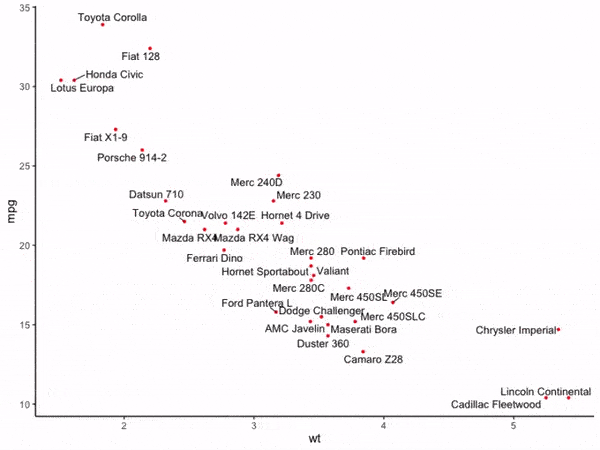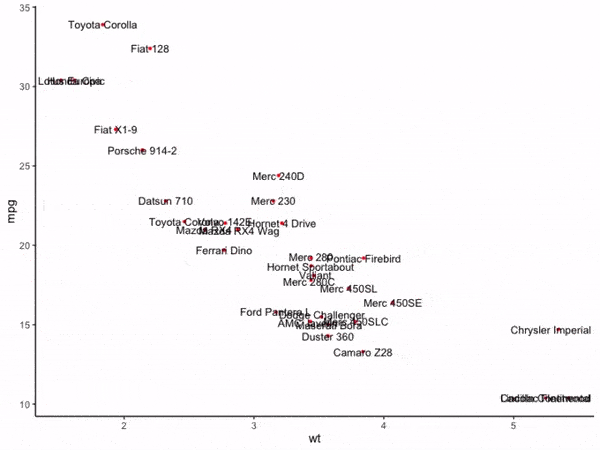 图3
图3
下面我们就来学习如何使用adjustText解决matplotlib图像文字遮挡问题。
2 使用adjustText解决文字遮挡问题
2.1 从一个简单的例子出发
使用pip install adjustText或conda install -c conda-forge adjusttext 来安装adjustText。安装成功之后,首先生成随机示例数据以方便之后的演示:
import matplotlib.pyplot as plt
from adjustText import adjust_text
import numpy as np
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
seed = np.random.RandomState(42) # 固定随机数水平
x, y = seed.uniform(0, 1, [2, 100]) # 产生固定的均匀分布随机数
texts = [f'文字{i}' for i in range(x.__len__())]
接着我们先不使用adjustText调整图像,直接绘制出原始的散点+文字标签:
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(x, y, c='SeaGreen', s=10) # 绘制散点
# 绘制所有点对应的文字标签
for x_, y_, text in zip(x, y, texts):
plt.text(x_, y_, text, fontsize=12)
# 美观起见隐藏顶部与右侧边框线
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
fig.savefig('图4.png', dpi=300, bbox_inches='tight', pad_inches=0) # 保存图像
 图4
图4
可以看到,在通常的情况下,散点聚集的区域内文字标签非常容易重叠在一起,接下来我们使用adjustText的基础功能来消除文字重叠现象:
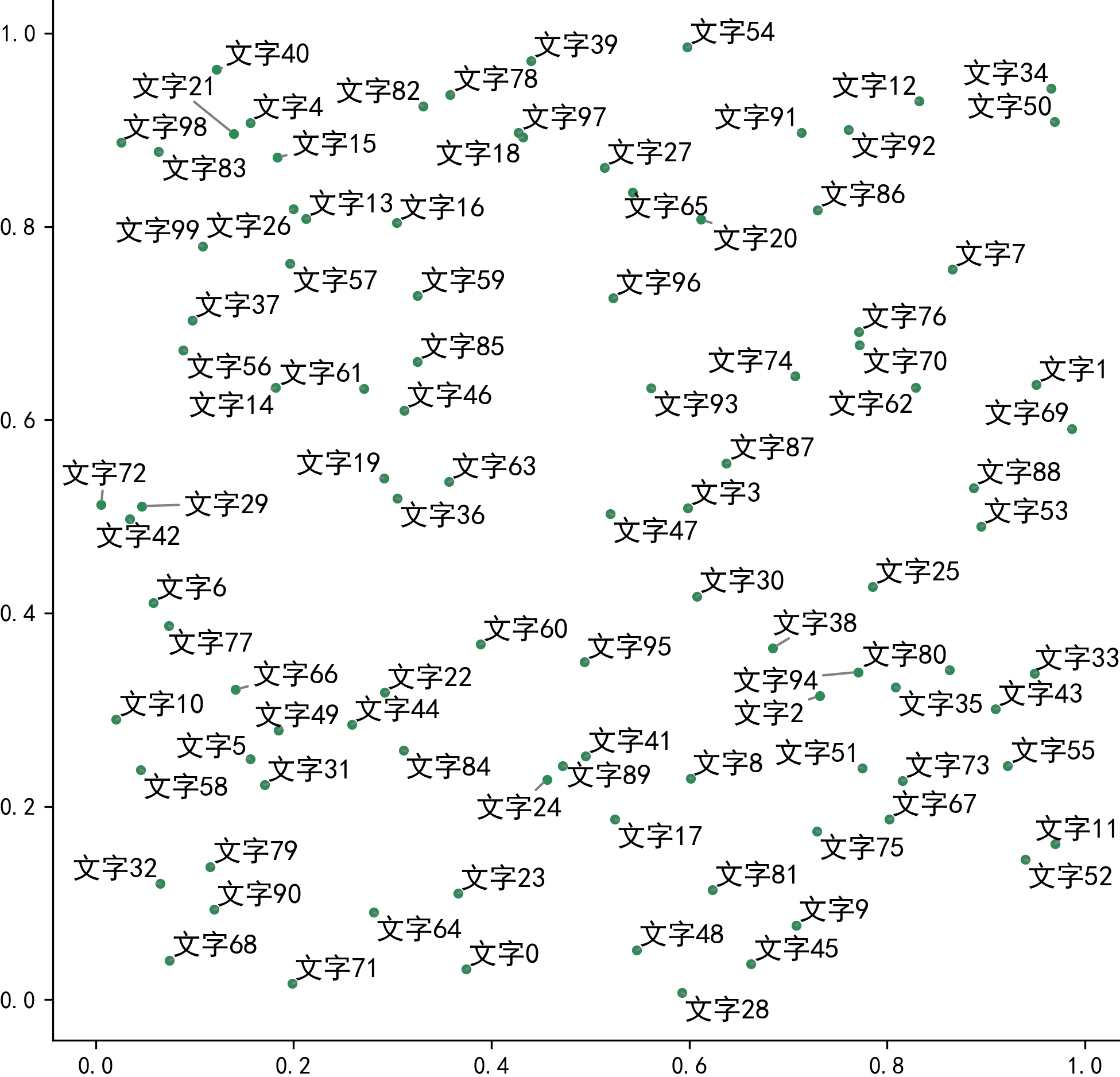 图5
图5
这时可以看到与图4相比,图5中的所有文字都没有出现彼此重叠现象,adjustText帮助我们自动微调了文字的摆放位置,并且距离原始散点偏移较大的文字还贴心的加上了连接线,至此,我们就初探了adjustText的强大功能,接下来我们来学习adjustText的更多功能。
2.2 adjust_text的用法
adjustText中的核心功能都通过调用函数adjust_text来实现,其核心参数如下:
texts:List型,每个元素都是表示单个文字标签对应的
matplotlib.text.Text对象ax:绘制文字标签的目标axe对象,默认为最近一次的axe对象
lim:int型,控制迭代调整文本标签位置的次数,默认为500次
precision:float型,用于决定迭代停止的精度,默认为0.01,即所有标签相互遮挡部分的长和宽占所有标签自身长宽之和的比例,
addjust_text会在精度达到precision和迭代次数超过lim这两个条件中至少有一个满足时停止迭代only_move:字典型,用于指定文本标签与不同对象发生遮挡时的位移策略,键有
'points'、'text'和'objects',对应的值可选'xy'、'x'、'y',分别代表竖直和水平方向均调整、只调整水平方向以及只调整竖直方向arrowprops:字典型,用于设置偏移后的文字标签与原始位置之间的连线样式,下文会作具体演示
save_steps:bool型,用于决定是否保存记录迭代过程中各轮的帧图像,默认为False
save_prefix:str型,当save_steps设置为True时,用于指定中间帧保存的路径,默认为'',即当前工作路径
下面我们来演示一下这些参数的使用效果,首先我们来看看only_move参数的效果,在图6的基础上,我们设置only_move={'text': 'x'},即当文字出现遮挡时,只在水平方向上进行偏移,这里将save_steps设置为True以直观地查看偏移过程:
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(x, y, c='SeaGreen', s=10) # 绘制散点
# 使用adjustText修正文字重叠现象
new_texts = [plt.text(x_, y_, text, fontsize=12) for x_, y_, text in zip(x, y, texts)]
adjust_text(new_texts,
only_move={'text': 'x'},
arrowprops=dict(arrowstyle='-', color='grey'),
save_steps=True)
# 美观起见隐藏顶部与右侧边框线
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
 图6
图6
可以看到在整个迭代微调的过程中,每个标签只在水平方向发生位移,你可以根据自己作图的实际需要灵活调整这里的平移策略。接下来我们来看看`arrowprops`对可视化结果的影响,在之前的例子里我们设置了`arrowprops={arrowstyle='-', color='grey'}`,其中`arrowstyle`用于设定连线的线型,`color`不用多说,接下来我们添加参数`lw`用于控制线的宽度,并对线型与颜色进行修改:
fig, ax = plt.subplots(figsize=(8, 8))
ax.scatter(x, y, c='SeaGreen', s=10) # 绘制散点
# 使用adjustText修正文字重叠现象
new_texts = [plt.text(x_, y_, text, fontsize=12) for x_, y_, text in zip(x, y, texts)]
adjust_text(new_texts,
arrowprops=dict(arrowstyle='->',
color='red',
lw=1))
# 美观起见隐藏顶部与右侧边框线
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
fig.savefig('图7.png', dpi=300, bbox_inches='tight', pad_inches=0) # 保存图像
这时连线随着我们自定义的设置改变到相应的样式:
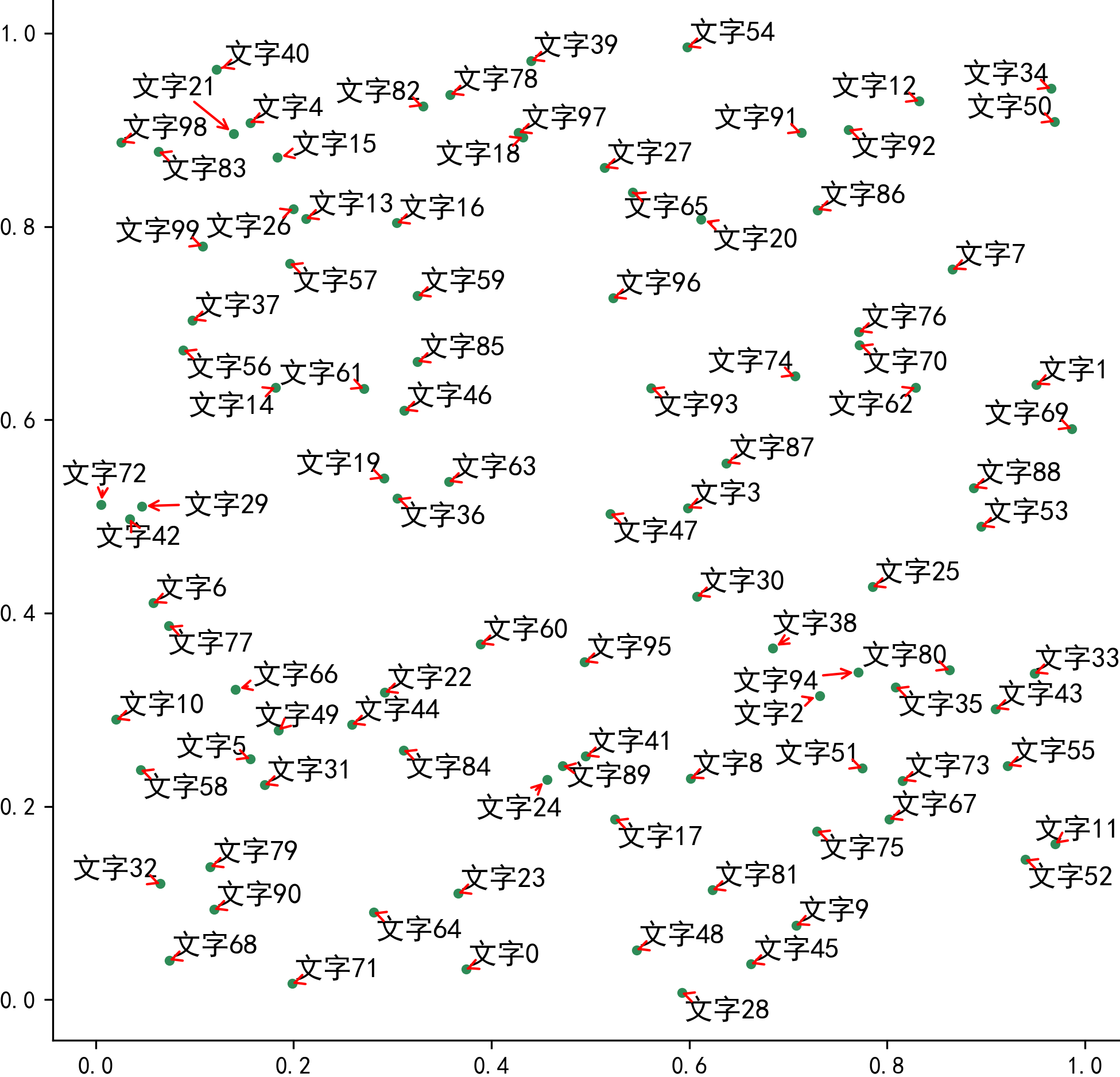 图7
图7
有关adjustText的更多参数设置信息和示例可以去官方文档(https://adjusttext.readthedocs.io/en/latest/ )查看。
以上就是本文的全部内容,如有疑问欢迎在评论区与我们讨论。
(数据科学学习手札87)利用adjustText解决matplotlib文字标签遮挡问题的更多相关文章
- (数据科学学习手札100)搞定matplotlib中的字体设置
本文示例文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 matplotlib作为数据可视化的利器,被广泛 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
随机推荐
- [Asp.Net Core] Blazor Server Side 扩展用途 - 配合CEF来制作带浏览器核心的客户端软件 (二) 可运行版本
前言 大概3个星期之前立项, 要做一个 CEF+Blazor+WinForms 三合一到同一个进程的客户端模板. 这个东西在五一的时候做出了原型, 然后慢慢修正, 在5天之前就上传到github了. ...
- etcd分布式锁及事务
前言 分布式锁是控制分布式系统之间同步访问共享资源的一种方式.在分布式系统中,常常需要协调他们的动作.如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互 ...
- python基本数据类型;字符串及其方法三:
###################判断类型################### ######################################################### ...
- codeforces Gym - 101485 D Debugging (2015-2016 Northwestern European Regional Contest (NWERC 2015))
题目描述: 点击打开链接 这题题意其实很不好理解,你有一个n行的程序,现在程序运行了r时间之后停止了运行,证明此处有一个bug,现在你需要在程序中加printf来调试找到bug所在的位置,你每次加一个 ...
- hdu6153KMP
A Secret Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 256000/256000 K (Java/Others)Total ...
- Java——日期获取和日期格式化
import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Calendar; impor ...
- pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值.
- [COCOS2DX-LUA]0-001.利用ClippingNode实现放大镜功能
用过Iphone的都知道,Iphone在定位光标位置的时候会把内容进行放大,这样我们就能很快的把光标移动到指定的位置.那么在我们的Cocos2dX的游戏中,怎么可以实现这种功能呢.起先我就是想起了Ip ...
- [Python基础]005.语法(4)
语法(4) 类 创建 self 方法 变量 综合例子 继承 类 创建 与其他大部分语言一样,Python也用 class 来创建类. class Person: # Person类 pass # 空语 ...
- 性能测试之Docker监控
微服务.大中台盛行的当下,容器化已经被广泛使用.在性能测试过程中,对容器的监控模型构建也是必不可少的. 我们性能测试监控模型的构建一直是围绕着Prometheus和Grafana来展开的.她们可以快速 ...