【Kafka】Kafka简单介绍
基本介绍
概述
Kafka官网网站:http://kafka.apache.org/
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个 按照分布式事务日志架构的大规模发布/订阅消息队列,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。(摘自维基百科 https://zh.wikipedia.org/wiki/Kafka)优点
高吞吐、低延迟 —— kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒;
高伸缩性 —— 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中;
持久性、可靠性 —— Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储;
容错性 —— 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作;
高并发 —— 支持数千个客户端同时读写。
(摘自文章 真的,关于 Kafka 入门看这一篇就够了)主要应用场景
以下摘自Kafka官网文档:http://kafka.apachecn.org/uses.html
一、消息传递
Kafka 很好地替代了传统的message broker(消息代理)。 Message brokers 可用于各种场合(如将数据生成器与数据处理解耦,缓冲未处理的消息等)。 与大多数消息系统相比,Kafka拥有更好的吞吐量、内置分区、具有复制和容错的功能,这使它成为一个非常理想的大型消息处理应用。
根据我们的经验,通常消息传递使用较低的吞吐量,但可能要求较低的端到端延迟,Kafka提供强大的持久性来满足这一要求。
在这方面,Kafka 可以与传统的消息传递系统(ActiveMQ 和 RabbitMQ)相媲美。
二、跟踪网站活动
Kafka 的初始用例是将用户活动跟踪管道重建为一组实时发布-订阅源。 这意味着网站活动(浏览网页、搜索或其他的用户操作)将被发布到中心topic,其中每个活动类型有一个topic。 这些订阅源提供一系列用例,包括实时处理、实时监视、对加载到Hadoop或离线数据仓库系统的数据进行离线处理和报告等。
每个用户浏览网页时都生成了许多活动信息,因此活动跟踪的数据量通常非常大
三、度量
Kafka 通常用于监控数据。这涉及到从分布式应用程序中汇总数据,然后生成可操作的集中数据源。
四、日志聚合
许多人使用Kafka来替代日志聚合解决方案。 日志聚合系统通常从服务器收集物理日志文件,并将其置于一个中心系统(可能是文件服务器或HDFS)进行处理。 Kafka 从这些日志文件中提取信息,并将其抽象为一个更加清晰的消息流。 这样可以实现更低的延迟处理且易于支持多个数据源及分布式数据的消耗。 与Scribe或Flume等以日志为中心的系统相比,Kafka具备同样出色的性能、更强的耐用性(因为复制功能)和更低的端到端延迟。
五、流式处理
许多Kafka用户通过管道来处理数据,有多个阶段: 从Kafka topic中消费原始输入数据,然后聚合,修饰或通过其他方式转化为新的topic, 以供进一步消费或处理。 例如,一个推荐新闻文章的处理管道可以从RSS订阅源抓取文章内容并将其发布到“文章”topic; 然后对这个内容进行标准化或者重复的内容, 并将处理完的文章内容发布到新的topic; 最终它会尝试将这些内容推荐给用户。 这种处理管道基于各个topic创建实时数据流图。从0.10.0.0开始,在Apache Kafka中,Kafka Streams 可以用来执行上述的数据处理,它是一个轻量但功能强大的流处理库。除Kafka Streams外,可供替代的开源流处理工具还包括Apache Storm 和Apache Samza.
六、采集日志
Event sourcing是一种应用程序设计风格,按时间来记录状态的更改。 Kafka 可以存储非常多的日志数据,为基于 event sourcing 的应用程序提供强有力的支持。
七、提交日志
Kafka 可以从外部为分布式系统提供日志提交功能。 日志有助于记录节点和行为间的数据,采用重新同步机制可以从失败节点恢复数据。 Kafka的日志压缩 功能支持这一用法。 这一点与Apache BookKeeper 项目类似。
Kafka的架构
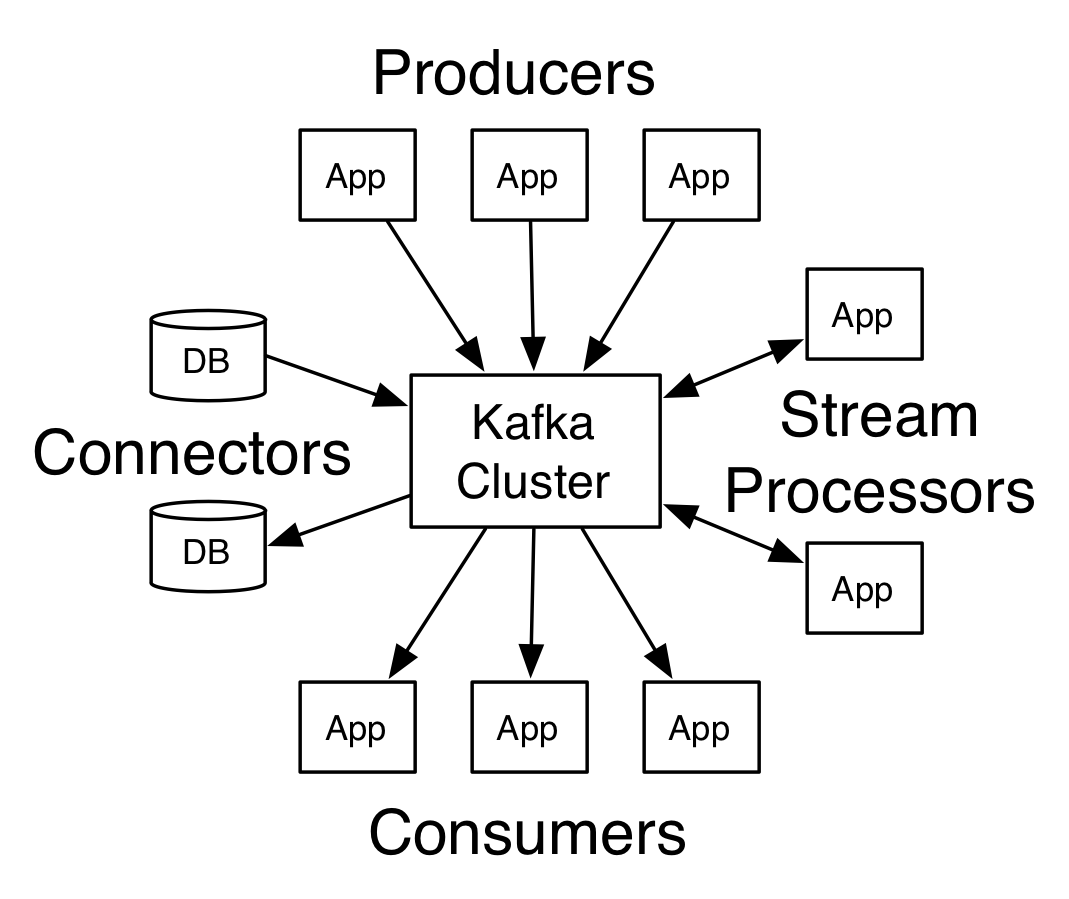
四大核心API
Producer API —— 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic。
Consumer API —— 允许一个应用程序订阅一个或多个 topic ,并且对发布给他们的流式数据进行处理。
Streams API —— 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入输出流中进行有效的转换。
Connector API —— 允许构建并运行可重用的生产者或者消费者,将Kafka topics连接到已存在的应用程序或者数据系统。比如,连接到一个关系型数据库,捕捉表(table)的所有变更内容。架构内部细节
摘自博主@如初⁰的文章Kafka内部实现原理、架构的分析与总结
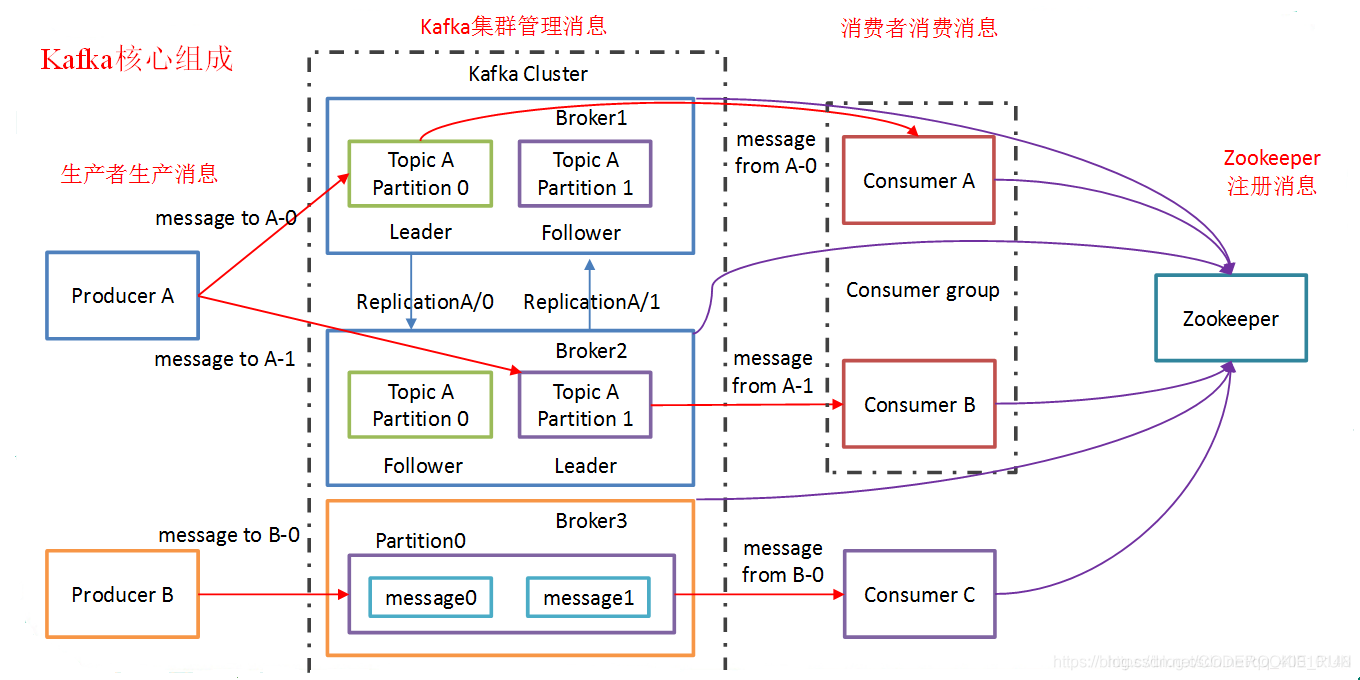
Broker —— 一台kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以容纳多个topic。
Topic —— 就是数据主题,是数据记录发布的地方,可以用来区分业务系统,可以理解为是一个队列。
Partition —— Topic中的数据可以分为一个或者多个Partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Segment —— 一个partition当中存在多个segment文件段,每个segment分为两部分:.log文件和 .index文件,其中 .index文件是索引文件,主要用于快速查询;.log文件当中是数据的偏移量位置
Producer —— 消息生产者,主要负责将消息发布到Kafka的Broker中
Consumer —— 消息消费者,主要负责从Kafka的Broker中读取消息
Consumer Group —— 每一个Consumer属于一个特定的Consumer Group(可以为每个Consumer指定 groupName)
【Kafka】Kafka简单介绍的更多相关文章
- kafka 主要内容介绍
1. kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and ...
- _00017 Kafka的体系结构介绍以及Kafka入门案例(0基础案例+Java API的使用)
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 博文标题:_000 ...
- kafka SASL认证介绍及自定义SASL PLAIN认证功能
目录 kafka 2.x用户认证方式小结 SASL/PLAIN实例(配置及客户端) broker配置 客户端配置 自定义SASL/PLAIN认证(二次开发) kafka2新的callback接口介绍 ...
- kafka工作原理介绍
两张图读懂kafka应用: Kafka 中的术语 broker:中间的kafka cluster,存储消息,是由多个server组成的集群. topic:kafka给消息提供的分类方式.brok ...
- Kafka管理工具介绍【转】
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下. ...
- 第1节 kafka消息队列:2、kafka的架构介绍以及基本组件模型介绍
3.kafka的架构模型 1.producer:消息的生产者,主要是用于生产消息的.主要是接入一些外部的数据源,从外部获取数据,比如说我们可以从flume获取数据,还可以通过ftp传入数据等,还可以通 ...
- MQTT介绍(1)简单介绍
MQTT目录: MQTT简单介绍 window安装MQTT服务器和client java模拟MQTT的发布,订阅 MQTT: MQTT(Message Queuing Telemetry Transp ...
- spring cloud之简单介绍
以下是来自官方的一篇简单介绍: spring Cloud provides tools for developers to quickly build some of the common patte ...
- [Kafka] - Kafka Java Consumer实现(一)
Kafka提供了两种Consumer API,分别是:High Level Consumer API 和 Lower Level Consumer API(Simple Consumer API) H ...
- [Kafka] - Kafka Java Consumer实现(二)
Kafka提供了两种Consumer API,分别是:High Level Consumer API 和 Lower Level Consumer API(Simple Consumer API) H ...
随机推荐
- 用threejs 实现3D物体在浏览器展示
用threejs 实现3D物体在浏览器展示,通过鼠标平移,缩放,键盘箭头按钮左右移动等功能展示. <!DOCTYPE html> <html> <head> < ...
- JSON Extractor(JSON提取器)
JSON提取器 Variable names(名称):提取器的名称Apply to(应用范围):Main sample and sub-samples:应用于主sample及子sampleMain s ...
- 2020不平凡的90天,Python分析三个月微博热搜数据带你回顾
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:刘早起早起 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- stand up meeting 11/25/2015 暨sprint2总结
今天在课堂上进行了小组项目的阶段性总结,这两天小组内也是频繁的开会,具体细节我们已经反复核查,具体不表~ sprint2个人工作总结: 冯晓云:完成了必应词典在线查词api的调用和网络状况的检测:完成 ...
- Servlet 和 Servlet容器
Servlet 很多同学可能跟我一样始终没有搞清楚到底什么是 Servlet,什么是 Servlet 容器.网上看了很多帖子,或许人家说的很清楚,但是自己的那个弯弯就是拐不过来. 想了很久说一下自己的 ...
- Jmeter系列(1)- 环境部署
如果你想从头学习Jmeter,可以看看这个系列的文章哦 https://www.cnblogs.com/poloyy/category/1746599.html 官网下载Jmeter http://j ...
- Thymeleaf+SpringBoot+Mybatis实现的齐贤易游网旅游信息管理系统
项目简介 项目来源于:https://github.com/liuyongfei-1998/root 本系统是基于Thymeleaf+SpringBoot+Mybatis.是非常标准的SSM三大框架( ...
- opencv-4-成像系统与Mat图像颜色空间
opencv-4-成像系统与Mat图像颜色空间 opencvc++qtmat 目标 知道 opencv 处理图像数据的格式 介绍 mat 基础内容 知道 BGR 颜色 显示 颜色转换 BGR 到 灰度 ...
- java中的Volatile关键字使用
文章目录 什么时候使用volatile Happens-Before java中的Volatile关键字使用 在本文中,我们会介绍java中的一个关键字volatile. volatile的中文意思是 ...
- java 之 继承 super关键籽 this关键字 final关键字
继承 语法: 使用 extends 来继承 class子类 extends父类{ 子类属性 子类方法 } 继承的特点: 1.子类会把父类所有的属性和方法继承下来,final修饰的类是不可以被继承 ...