获取网站title的脚本
脚本在此
公司的商城需要添加一个脚本,这个脚本就是观察首页页面是否正常,虽然已经配置了zabbix监控网站是否200,但是有一些特殊的情况,比如网页可以打开但是页面是“file not found”,类似这样就需要被运维第一时间监控到然后通知开发。
原本我打算直接爬取整个首页然后与服务器里的index.html对比一下,如果不符合就报警,但是跟前端同事说了这个思路之后,前端说服务器上是没有index.html的,因为这个index.html是结合其他的php拼接的。前端说“只要能检测title正常就OK,一般来说title能获取到就证明系统是OK的,如果titleOK但是html内容获取不到就是前段代码的问题,跟系统无关”。于是我就写了这么一个爬虫脚本来获取网站title,如下:
1 |
#coding=utf-8 |
说一下,如果在from bs4 import BeautifulSoup爆出ImportError: No module named 'bs4'是因为安装的库装错了,应该是pip install beautifulsoup4而不是pip install beautifulsoup。启动脚本效果如下: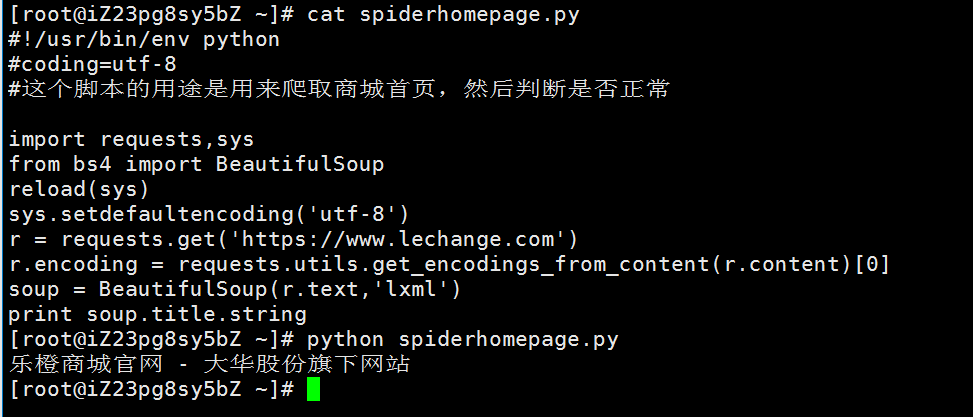
编码问题
上面那个脚本里的soup.title.string的类型是bs4.element.NavigableString,如果不用print那么它的形式是unicode的,如图:
这种现象并不新鲜,比如list在python2里一直都不是正常输出中文的,如图: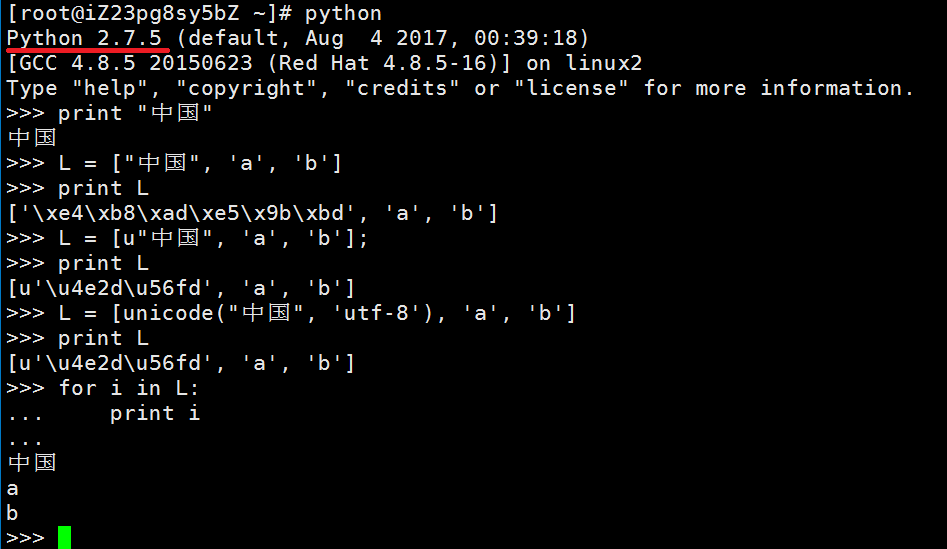
可见只有 大专栏 获取网站title的脚本for in的时候才会正常编码,那么这样的情况怎么办?
最简单的方法,改用python3。不过上面那个脚本是可以直接把中文放到soup.title.string进行判断的。
安装python 3.6.4
首先要先安装相关依赖包yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make,其中readline-devel这个很重要,他是管方向键的,如果python运行的时候方向键不好使,那么就要yum install readline-devel安装,安装完毕后重新configure和make。
然后过程如下:
1 |
yum -y install epel-release #运行这个命令添加epel扩展源 |
更改yum配置,因为其要用到python2才能执行,否则会导致yum不能正常使用,需要分别修改/usr/bin/yum和/usr/libexec/urlgrabber-ext-down这两个文件,把他们的#! /usr/bin/python修改为#! /usr/bin/python2。
然后还要给python3的pip3做一个软连接: ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3。
注意!如果你用了python3那么上面那个脚本就会有很大的变动。
参考资料
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/tutorial.html
获取网站title的脚本的更多相关文章
- php获取网站根目录
php获取网站根目录方法一:<?phpdefine("WWWROOT",str_ireplace(str_replace("/","\\&quo ...
- php用正则表达式获取网站的标题内容
已知网站的网址,用php获取网站的内容. 编写正则表达式. 用preg_match_all函数获取标题内容. $url='http://www.m-ivi.com'; $content=file_ge ...
- 使用curl获取网站的http的状态码
发布:thebaby 来源:net [大 中 小] 本文分享一例shell脚本,一个使用curl命令获取网站的httpd状态码的例子,有需要的朋友参考下.本文转自:http://www.j ...
- Python 网站后台扫描脚本
Python 网站后台扫描脚本 #!/usr/bin/python #coding=utf-8 import sys import urllib import time url = "ht ...
- PHP中如何获取网站根目录物理路径
在php程序开发中经常需要获取当前网站的目录,我们可以通过常量定义获取站点根目录物理路径,方便在程序中使用. 下面介绍几种常用的获取网站根目录的方法. php获取网站根目录方法一: <?php ...
- PHP获取网站图标(favicon.ico)文件
有的网站源码中加入了这几行代码: <link rel="shortcut icon" href="/favicon.ico" type="ima ...
- 曲线救国:IIS7集成模式下如何获取网站的URL
如果我们在Global中的Application_Start事件中访问HttpContext.Current.Request对象,如: protected void Application_Start ...
- Web前端性能优化教程05:网站样式和脚本
本文是Web前端性能优化系列文章中的第五篇,主要讲述内容:网站样式和脚本代码的放置位置.使用外部javascript和css.完整教程可查看:Web前端性能优化 一.将样式表放在顶部 可视性回馈的重要 ...
- 使用PHP获取网站Favicon的方法
使用PHP获取网站Favicon的方法 Jan022014 作者:Jerry Bendy 发布:2014-01-02 23:18 分类:PHP 阅读:4,357 views 20条评论 ...
随机推荐
- python-day4爬虫基础之正则表达式
正则表达式:(字符串匹配) 使用单个字符串来描述匹配一系列符合某个句法规则的字符串 是对字符串操作的一种逻辑公式 应用场景:处理文本和数据 正则表达式过程:依次拿出表达式和文本中的字符比较,如果每一个 ...
- 当年写的C代码
#ifndef KMIN_H_ #define KMIN_H_ /******************************************************************* ...
- psi 函数计算
scipy.special.psi odps中不支持 scipy.special.psi,需要改写 基于 chebyshev_polynomial https://people.sc.fsu.edu/ ...
- 吴裕雄--天生自然TensorFlow高层封装:Keras-TensorFlow API
# 1. 模型定义. import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist_ ...
- 日期控件 My97DatePicker WdatePicker 日期格式
WdatePicker()只显示日期 WdatePicker({dateFmt:'yyyy-MM-dd HH:mm:ss'})显示日期和时间 WdatePicker({dateFmt:'yyyy-MM ...
- tesseract系列(1) -- tesseract用vs编译成库
1.下载teseract 下载地址github: https://github.com/tesseract-ocr/tesseract/releases/ 2.编译源码 源码的编译有两种方式 ...
- eclipse web 项目配置 运行
- appium自动化的工作原理(1)
用appium开发移动端自动化测试脚本这么长时间,还没有认证的了解下它的原理是什么,到底是如何实现的呢? 1.先看一个Appium加载的过程图解(来自:了解appium自动化的工作原理--https: ...
- Office VBA开发经典-中级进阶卷 配套资源下载
本书源代码请到如下页面寻找: https://www.cnblogs.com/ryueifu-VBA/p/8982192.html
- 三角插值的 Fourier 系数推导
给定 $k$ 个互不相同的复数 $x_0,\cdots,x_{k-1}$,以及 $k$ 个复数$y_0,\cdots,y_{k-1}$.我们知道存在唯一的复系数 $k-1$ 次多项式$$\mathca ...