第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
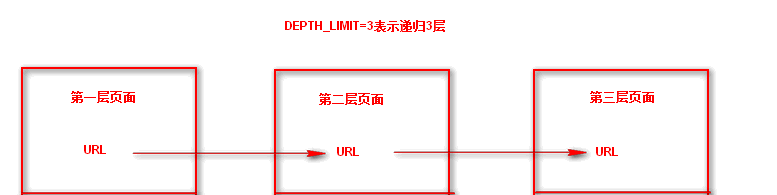
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 记录url可以是缓存,或者数据库,如果保存数据库按照以下方式: id URL加密 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第一百二十六节,JavaScript,XPath操作xml节点
第一百二十六节,JavaScript,XPath操作xml节点 学习要点: 1.IE中的XPath 2.W3C中的XPath 3.XPath跨浏览器兼容 XPath是一种节点查找手段,对比之前使用标准 ...
- 第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承
第三百八十六节,Django+Xadmin打造上线标准的在线教育平台—HTML母版继承 母板-子板-母板继承 母板继承就是访问的页面继承一个母板,将访问页面的内容引入到母板里指定的地方,组合成一个新页 ...
- 第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表、课程评论表、用户收藏表、用户消息表、用户学习表
第三百七十六节,Django+Xadmin打造上线标准的在线教育平台—创建用户操作app,在models.py文件生成5张表,用户咨询表.课程评论表.用户收藏表.用户消息表.用户学习表 创建名称为ap ...
随机推荐
- How lock works?
Eliminating Synchronization-Related Atomic Operations with Biased Locking and Bulk Rebiasing http:// ...
- Spring Bean 的加载顺序
一,单一Bean 装载 1. 实例化; 2. 设置属性值; 3. 如果实现了BeanNameAware接口,调用setBeanName设置Bean的ID或者Name; 4. 如果实现BeanFacto ...
- 微信公众号抢现金红包活动的核心代码分析(asp.net C#)
今年春节微信抢红包,我想各位都还记得.最近很多商家也在使用公众号给粉丝发红包,做营销活动.吸粉活动或者是反馈老用户等. 我们作为第3方开发者,就义不容辞的来给这些商家服务了.首先我们得会使用程序来写抢 ...
- [Windows Azure] Load Testing in Windows Azure
The primary goal of a load test is to simulate many users accessing a web application at the same ti ...
- mysql_secure_installation
安装完mysql-server 会提示可以运行mysql_secure_installation.运行mysql_secure_installation会执行几个设置: a)为root用户设置密码 ...
- Eclipse 使用 SVN 插件后修改用户方法汇总
http://blog.csdn.net/ShaneLooLi/article/details/50994005 ******************************************* ...
- C#数组 添加元素
例1: string[] a = new string[] { "1", "2", "3" }; 给a追加一个 "4" ...
- java多线程17:ThreadLocal源码剖析
ThreadLocal源码剖析 ThreadLocal其实比较简单,因为类里就三个public方法:set(T value).get().remove().先剖析源码清楚地知道ThreadLocal是 ...
- uboot之第一阶段
U-boot的启动一般分为两个阶段,现在我们先将第一阶段. 在此之前,我们先了解一下uboot的目录结构,各个文件夹是什么作用. 如果连各个文件夹是干什么的都不清楚就开始移植剪裁,势必会和我刚拿到开发 ...
- django模型查询
概述 查询集表示从数据库获取的对象的集合 查询集可以有多个过滤器 过滤器就是一个函数,基于所给的参数限制查询集结果 从SQL角度来说,查询集和select语句等价,过滤器就像where条件 查询集 在 ...