Python 爬虫-Scrapy框架基本使用
2017-08-01 22:39:50
一、Scrapy爬虫的基本命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行。
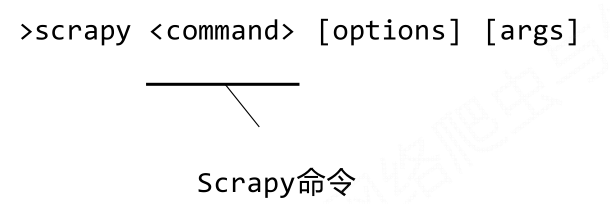
- Scrapy命令行格式
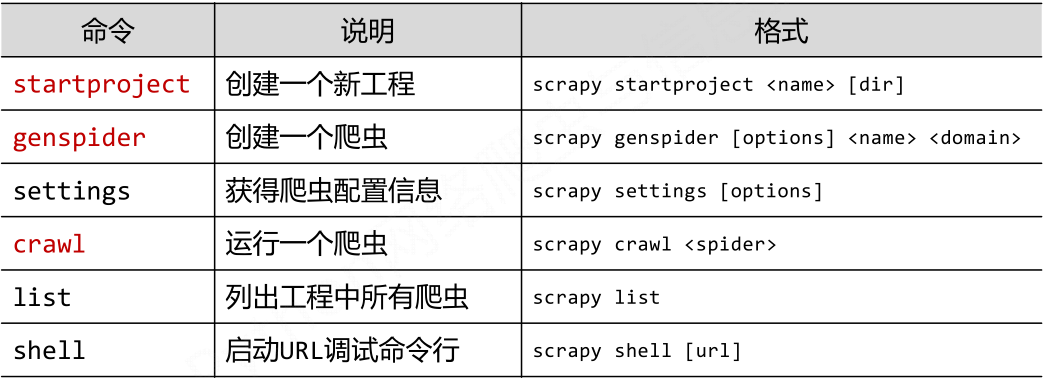
- Scrapy常用命令
- 采用命令行的原因
命令行(不是图形界面)更容易自动化,适合脚本控制本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
二、Scrapy爬虫的一个基本例子
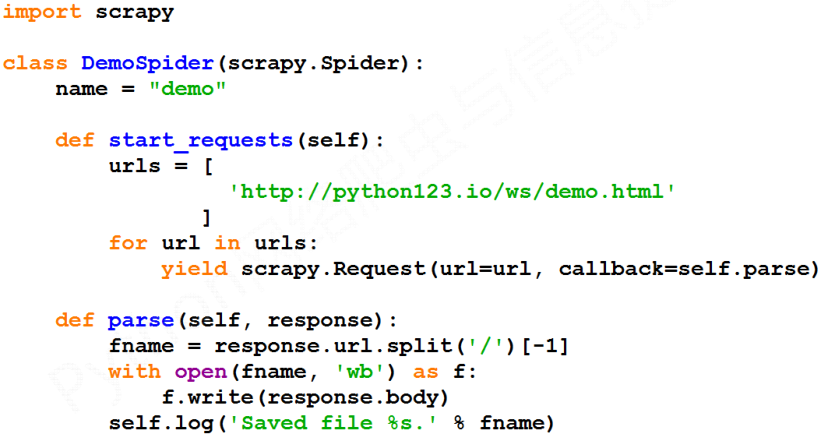
演示HTML页面地址:http://python123.io/ws/demo.html
步骤一:建立一个Scrapy爬虫
选取一个文件夹,例如E:\python,然后执行如下命令。

此时在python文件夹下就会生成一个名为Python123demo的工程,该工程的文件结构为:


步骤二:在工程中产生一个Scrapy爬虫
使用cd进入E:\python\python123demo文件夹,然后执行如下命令。

该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py
该命令仅用于生成demo.py,该文件也可以手工生成
步骤三:配置产生的spider爬虫

demo文件是使用genspider命令产生的一个spider。
- 继承于scrapy.Spider
- name='demo'说明爬虫的名字是demo
- allowed_domains指爬取网站时只能爬取该域名下的网站链接
- star_urls是指爬取的一个或多个起始的爬取url
- parse()用于处理响应并发现新的url爬取请求
配置:(1)初始URL地址 (2)获取页面后的解析方式

步骤四:运行爬虫,获取网页
执行如下代码:

demo爬虫被执行,捕获页面存储在demo.html
还有一种等价的表达方式:
三、Scrapy爬虫的基本使用
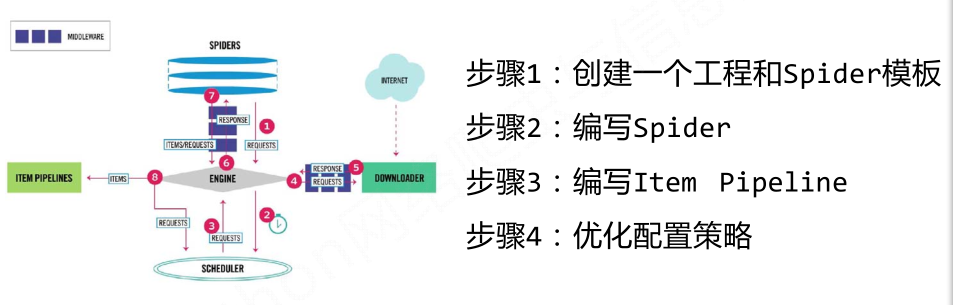
这四个步骤会涉及到三个类:Request类、Response类、Item类;
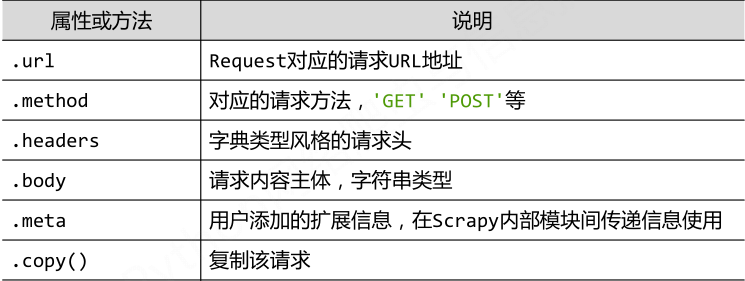
- Request类
class scrapy.http.Request():Request对象表示一个HTTP请求,由Spider生成,由Downloader执行。
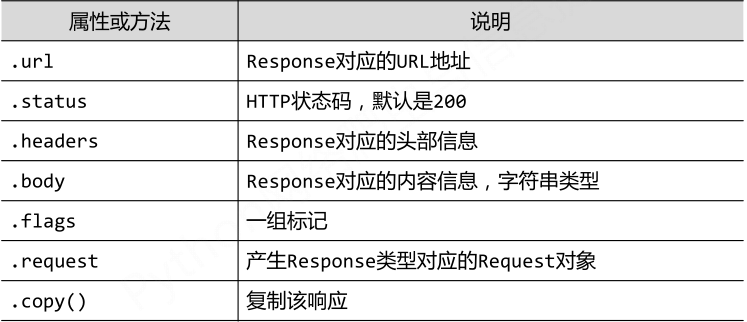
- Response类
class scrapy.http.Response():Response对象表示一个HTTP响应;由Downloader生成,由Spider处理。
- Item类
class scrapy.item.Item():Item对象表示一个从HTML页面中提取的信息内容;由Spider生成,由Item Pipeline处理;Item类似字典类型,可以按照字典类型操作。
Python 爬虫-Scrapy框架基本使用的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫-Scrapy框架的工作原理
Scrapy框架工作原理 Scrapy框架架构图 Scrapy框架主要由六大组件组成,分别为: 调度器(Scheduler),下载器(Downler),爬虫(Spiders),中间件(Middwa ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
随机推荐
- TensorFlow中的变量命名以及命名空间.
What: 在Tensorflow中, 为了区别不同的变量(例如TensorBoard显示中), 会需要命名空间对不同的变量进行命名. 其中常用的两个函数为: tf.variable_scope, t ...
- svn忽略目录,svn忽略app目录add toignore list,避免每次更新很多app的内容下来导出到本地很麻烦
svn忽略目录,svn忽略app目录add toignore list,避免每次更新很多app的内容下来导出到本地很麻烦 ------------------------------ 本人微信公众帐号 ...
- Hive学习之路 (五)DbVisualizer配置连接hive
一.安装DbVisualizer 下载地址http://www.dbvis.com/ 也可以从网上下载破解版程序,此处使用的版本是DbVisualizer 9.1.1 具体的安装步骤可以百度,或是修改 ...
- SNMP学习笔记之SNMP报文协议详解
0x00 简介 简单网络管理协议(SNMP)是TCP/IP协议簇的一个应用层协议.在1988年被制定,并被Internet体系结构委员会(IAB)采纳作为一个短期的网络管理解决方案:由于SNMP的简单 ...
- P2486 [SDOI2011]染色
P2486 [SDOI2011]染色 树链剖分 用区间修改线段树维护 对于颜色段的计算:sum[o]=sum[lc]+sum[rc] 因为可能重复计算,即左子树的右端点和右子树的左端点可能颜色相同 多 ...
- 20145330 《网络对抗》 Eternalblue(MS17-010)漏洞复现与S2-045漏洞的利用及修复
20145330 <网络对抗> Eternalblue(MS17-010)漏洞利用工具实现Win 7系统入侵与S2-045漏洞的利用及修复 加分项目: PC平台逆向破解:注入shellco ...
- noip 2013 提高组 Day2 部分题解
积木大赛: 之前没有仔细地想,然后就直接暴力一点(骗点分),去扫每一高度,连到一起的个数,于是2组超时 先把暴力程序贴上来(可以当对拍机) #include<iostream> #incl ...
- 常用模块之 time,datetime,random,os,sys
time与datetime模块 先认识几个python中关于时间的名词: 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运行“ty ...
- 苹果电脑macbook 安装 Burp Suite pro_v1.7.37破解版
1.先去官网下载最新版本 Burp Suite Community Edition v1.7.36安装完成 https://portswigger.net/burp/communitydownload ...
- 获取转UTF8的字符串
/// <summary> /// 获取转UTF8的字符串 /// </summary> /// <param name="strWord">& ...