Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit(p)与自变量之 间存在线性相关的关系,逻辑回归模型定义如下:
- #Sigmoid曲线:
- import matplotlib.pyplot as plt
- import numpy as np
- def Sigmoid(x):
- return 1.0 / (1.0 + np.exp(-x))
- x= np.arange(-10, 10, 0.1)
- h = Sigmoid(x) #Sigmoid函数
- plt.plot(x, h)
- plt.axvline(0.0, color='k') #坐标轴上加一条竖直的线(0位置)
- plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
- plt.axhline(y=0.5, ls='dotted', color='k') #在y=0.5的地方加上黑色虚线
- plt.yticks([0.0, 0.5, 1.0]) #y轴标度
- plt.ylim(-0.1, 1.1) #y轴范围
- plt.show()
二、鸢尾花分类问题的思路分析
(1)选择使用LogisticRegression分类器,由于Iris数据集涉及到3个目标分类问题,而逻辑回归模型是二分类模型,用于二分类问题。因此,可以将其推广为多项逻辑回归模型(multi-nominal logistic regression model),用于多分类。
(2)根据多项逻辑回归模型,编写代码,输入数据集,训练得到相应参数并作出预测。
(3)对预测出的数据的分类结果和原始数据进行可视化展示。
三、多项逻辑回归模型的原理及推导过程
假设类别 Y 的取值集合为 {1,2,...,K},那么多项逻辑回归模型是:

其似然函数为:
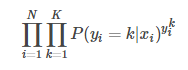
其中,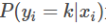 为模型在输入样本
为模型在输入样本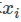 时,将其判为类别k 的概率;
时,将其判为类别k 的概率;
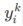 起到指示函数的作用,当K 等于样本
起到指示函数的作用,当K 等于样本 的标签类别时为1,其余均为0。
的标签类别时为1,其余均为0。
对似然函数取对数,然后取负,得到 (简记为:
(简记为: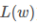 ),最终要训练出的模型参数要使得
),最终要训练出的模型参数要使得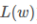 的值取得最小。
的值取得最小。
 的推导过程如下:
的推导过程如下:
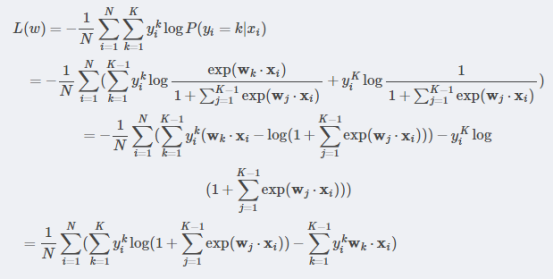
考虑到过拟合的发生,对 加上一个正则项:
加上一个正则项:
则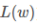 可以写成:
可以写成:

对 关于
关于 求梯度,得到:
求梯度,得到:

在上式中,第一项 可以看成是类别k的后验期望值,第二项
可以看成是类别k的后验期望值,第二项 视为类别k 的先验期望值,第三项是正则化项,用于缓解过拟合。
视为类别k 的先验期望值,第三项是正则化项,用于缓解过拟合。
接下来使用梯度下降法对参数 进行修正更新即可:
进行修正更新即可:

四、实现步骤
4.1 读入数据文件
这里需要注意的是,在datas中取前两列作为特征(为了后期的可视化画图更加直观,故只取前两列特征值向量进行训练)
- attributes=['SepalLength','SepalWidth','PetalLength','PetalWidth'] #鸢尾花的四个属性名
- datas=[]
- labels=[]
- # with open('IRIS_dataset.txt','r') as f:
- # for line in f:
- # linedata=line.split(',')
- # datas.append(linedata[:-1]) #前4列是4个属性的值
- # labels.append(linedata[-1].replace('\n','')) #最后一列是类别
- #读入数据集的数据:
- data_file=open('IRIS_dataset.txt','r')
- for line in data_file.readlines():
- # print(line)
- linedata = line.split(',')
- # datas.append(linedata[:-1]) # 前4列是4个属性的值(误判的样本的个数为:7
- datas.append(linedata[:-3]) # 前2列是2个属性的值(误判的样本的个数为:30
- labels.append(linedata[-1].replace('\n', '')) # 最后一列是类别
- datas=np.array(datas)
- datas=datas.astype(float) #将二维的字符串数组转换成浮点数数组
- labels=np.array(labels)
- kinds=list(set(labels)) #3个类别的名字列表
4.2 编写代码实现LogisticRegression算法
- # LogisticRegression算法,训练数据,传入参数为数据集(包括特征数据及标签数据),结果返回训练得到的参数 W
- def LogRegressionAlgorithm(datas,labels):
- kinds = list(set(labels)) # 3个类别的名字列表
- means=datas.mean(axis=0) #各个属性的均值
- stds=datas.std(axis=0) #各个属性的标准差
- N,M= datas.shape[0],datas.shape[1]+1 #N是样本数,M是参数向量的维
- K=3 #k=3是类别数
- data=np.ones((N,M))
- data[:,1:]=(datas-means)/stds #对原始数据进行标准差归一化
- W=np.zeros((K-1,M)) #存储参数矩阵
- priorEs=np.array([1.0/N*np.sum(data[labels==kinds[i]],axis=0) for i in range(K-1)]) #各个属性的先验期望值
- liklist=[]
- for it in range(1000):
- lik=0 #当前的对数似然函数值
- for k in range(K-1): #似然函数值的第一部分
- lik -= np.sum(np.dot(W[k],data[labels==kinds[k]].transpose()))
- lik +=1.0/N *np.sum(np.log(np.sum(np.exp(np.dot(W,data.transpose())),axis=0)+1)) #似然函数的第二部分
- liklist.append(lik)
- wx=np.exp(np.dot(W,data.transpose()))
- probs=np.divide(wx,1+np.sum(wx,axis=0).transpose()) # K-1 *N的矩阵
- posteriorEs=1.0/N*np.dot(probs,data) #各个属性的后验期望值
- gradients=posteriorEs - priorEs +1.0/100 *W #梯度,最后一项是高斯项,防止过拟合
- W -= gradients #对参数进行修正
- print("输出W为:",W)
- return W
4.3 编写predict_fun()预测函数
根据训练得到的参数W和数据集,进行预测。输入参数为数据集和由LogisticRegression算法得到的参数W,返回值为预测的值。
- #根据训练得到的参数W和数据集,进行预测。输入参数为数据集和由LogisticRegression算法得到的参数W,返回值为预测的值
- def predict_fun(datas,W):
- N, M = datas.shape[0], datas.shape[1] + 1 # N是样本数,M是参数向量的维
- K = 3 # k=3是类别数
- data = np.ones((N, M))
- means = datas.mean(axis=0) # 各个属性的均值
- stds = datas.std(axis=0) # 各个属性的标准差
- data[:, 1:] = (datas - means) / stds # 对原始数据进行标准差归一化
- # probM每行三个元素,分别表示data中对应样本被判给三个类别的概率
- probM = np.ones((N, K))
- print("data.shape:", data.shape)
- print("datas.shape:", datas.shape)
- print("W.shape:", W.shape)
- print("probM.shape:", probM.shape)
- probM[:, :-1] = np.exp(np.dot(data, W.transpose()))
- probM /= np.array([np.sum(probM, axis=1)]).transpose() # 得到概率
- predict = np.argmax(probM, axis=1).astype(int) # 取最大概率对应的类别
- print("输出predict为:", predict)
- return predict
4.4 绘制图像
(1)确定坐标轴范围,x,y轴分别表示两个特征
- # 1.确定坐标轴范围,x,y轴分别表示两个特征
- x1_min, x1_max = datas[:, 0].min(), datas[:, 0].max() # 第0列的范围
- x2_min, x2_max = datas[:, 1].min(), datas[:, 1].max() # 第1列的范围
- x1, x2 = np.mgrid[x1_min:x1_max:150j, x2_min:x2_max:150j] # 生成网格采样点,横轴为属性x1,纵轴为属性x2
- grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
- #.flat 函数将两个矩阵都变成两个一维数组,调用stack函数组合成一个二维数组
- print("grid_test = \n", grid_test)
- grid_hat = predict_fun(grid_test,W) # 预测分类值
- grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
- #grid_hat本来是一唯的,调用reshape()函数修改形状,将其grid_hat转换为两个特征(长度和宽度)
- print("grid_hat = \n", grid_hat)
- print("grid_hat.shape: = \n", grid_hat.shape) # (150, 150)
(2)指定默认字体
- # 2.指定默认字体
- mpl.rcParams['font.sans-serif'] = [u'SimHei']
- mpl.rcParams['axes.unicode_minus'] = False
(3)绘制图像
- # 3.绘制图像
- cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
- cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
- alpha = 0.5
- plt.pcolormesh(x1, x2, grid_hat, cmap=plt.cm.Paired) # 预测值的显示
- # 调用pcolormesh()函数将x1、x2两个网格矩阵和对应的预测结果grid_hat绘制在图片上
- # 可以发现输出为三个颜色区块,分布表示分类的三类区域。cmap=plt.cm.Paired/cmap=cm_light表示绘图样式选择Paired主题
- # plt.scatter(datas[:, 0], datas[:, 1], c=labels, edgecolors='k', s=50, cmap=cm_dark) # 样本
- plt.plot(datas[:, 0], datas[:, 1], 'o', alpha=alpha, color='blue', markeredgecolor='k')
- ##绘制散点图
- plt.scatter(datas[:, 0], datas[:, 1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
- plt.xlabel(u'花萼长度', fontsize=13) #X轴标签
- plt.ylabel(u'花萼宽度', fontsize=13) #Y轴标签
- plt.xlim(x1_min, x1_max) # x 轴范围
- plt.ylim(x2_min, x2_max) # y 轴范围
- plt.title(u'鸢尾花LogisticRegression二特征分类', fontsize=15)
- # plt.legend(loc=2) # 左上角绘制图标
- # plt.grid()
- plt.show()
五、 实验结果
(1)运行程序输出的参数:
使用二个特征:
|
输出W为: [[-0.41462351 1.26263398 0.26536423] [-1.07260354 -2.44478672 1.96448439]] 输出predict为: [1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 0 0 0 2 0 2 0 2 0 2 2 2 2 2 2 0 2 2 2 2 2 2 2 2 0 0 0 0 2 2 2 2 2 2 2 0 0 2 2 2 2 2 2 2 2 2 2 0 2 2 0 2 0 0 0 0 2 0 0 0 0 0 0 2 2 0 0 0 0 2 0 2 0 0 0 0 2 2 0 0 0 0 0 0 2 0 0 0 2 0 0 0 2 0 0 0 2 0 0 2] 误判的样本的个数为:28 |
使用四个特征:
|
输出W为: [[-0.09363942 -1.41359443 1.17376524 -2.3116611 -2.20018596] [ 1.44071982 -0.05960463 -0.31391519 -0.87589944 -1.83255315]] 输出predict为: [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] 误判的样本的个数为:8 |
(2)数据可视化结果如下:
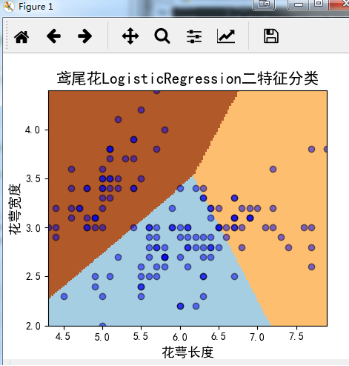
六、结果分析与比较
由以上实验结果可以看出,使用了二特征的误判的样本个数为28(样本总数为150),而使用了四个特征的训练结果,误判的样本个数为8,在一定程度上可以解释使用的特征数过少的话,会导致欠拟合的情况发生。
为了后期的可视化画图更加直观,故只取前两列特征值向量进行训练。结果展示如上图所示。
完整实现代码详见:【GitHub 】
【Reference】
2、https://blog.csdn.net/BTUJACK/article/details/79761461
3、https://blog.csdn.net/eastmount/article/details/77920470
Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器的更多相关文章
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- 基于SVM的鸢尾花数据集分类实现[使用Matlab]
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set.iris包含150个样本,对应数据集的每行数据.每行数据包含每个样本的四个特征和样本的类别信息 ...
- ML学习笔记之XGBoost实现对鸢尾花数据集分类预测
import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import tra ...
- BP神经网络算法程序实现鸢尾花(iris)数据集分类
作者有话说 最近学习了一下BP神经网络,写篇随笔记录一下得到的一些结果和代码,该随笔会比较简略,对一些简单的细节不加以说明. 目录 BP算法简要推导 应用实例 PYTHON代码 BP算法简要推导 该部 ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- 实验一 使用sklearn的决策树实现iris鸢尾花数据集的分类
使用sklearn的决策树实现iris鸢尾花数据集的分类 要求: 建立分类模型,至少包含4个剪枝参数:max_depth.min_samples_leaf .min_samples_split.max ...
- python 鸢尾花数据集报表展示
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltsns.set_style('white',{'font. ...
随机推荐
- MyBatis动态SQL foreach标签实现批量插入
需求:查出给定id的记录: <select id="getEmpsByConditionForeach" resultType="com.test.beans.Em ...
- Mono Touch Table应用
, UIApplication.SharedApplication.StatusBarFrame.Height , UIScreen.MainScree ...
- 浅谈 Adaboost 算法
http://blog.csdn.net/haidao2009/article/details/7514787 菜鸟最近开始学习machine learning.发现adaboost 挺有趣,就把自己 ...
- 单元测试中用@Autowired 报null (空指针异常)
原因是因为,单元测试不依赖于容器,所以自动注入也就存在问题 (单元测试中加@Autowired注解亲自测过是不行,不知道这样理解的是否正确)
- Google Java Style 中文版
Google Java Style 中文版 基于官方文档2013.12.19最后一次改动. 翻译人:Weir Zhang (zh.weir) 旁白:水平有限,很多地方只是意译.不准确的地方 ...
- CentOS7安装 Apache HTTP 服务器
CentOS7安装 Apache HTTP 服务器 时间:2015-05-02 00:45来源:linux.cn 作者:linux.cn 举报 点击:11457次 不管你因为什么原因使用服务器,大部分 ...
- mysql 表分区 查看表分区 修改表分区
原文地址:http://blog.csdn.net/feihong247/article/details/7885199 一. mysql分区简介 数据库分区 数据库分区是一种物理数据库设 ...
- Unity3d 屏幕截图。并保存。iOS
- ( void ) imageSaved: ( UIImage *) image didFinishSavingWithError:( NSError *)error contextInfo: ( ...
- iOS开发点滴 - 如何通过Segue写代码传递数据从一个ViewController到另一个ViewController(Swift代码)
1. 拖线 按住Control键,用鼠标从源控制器的某个控件开始,拖动到目的控制器 2. 选择弹出类型并设置Segue Identifier 在弹出的对话框中,选择“Selection Segue-& ...
- SHELL函数处理
SHELL函数调用分为两种: 第一种方式,有点像C语言调用函数的风格,直接把函数的执行结果复制给变量!不过,这个赋值过程和C语言的函数赋值是不一样的! C语言中,函数调用,是将函数的返回值返回给被调函 ...