机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)
在学习LDA之前,有必要将其自然语言处理领域的LDA区别开来,在自然语言处理领域, LDA是隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),是一种处理文档的主题模型。本文只讨论线性判别分析,因此后面所有的LDA均指线性判别分析。
线性判别分析 LDA: linear discriminant analysis
一、LDA思想:类间小,类间大 (‘高内聚,松耦合’)
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的,这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”,如下图所示。 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。

可能还是有点抽象,先看看最简单的情况。
假设有两类数据,分别为红色和蓝色,如下图所示,这些数据特征是二维的,希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
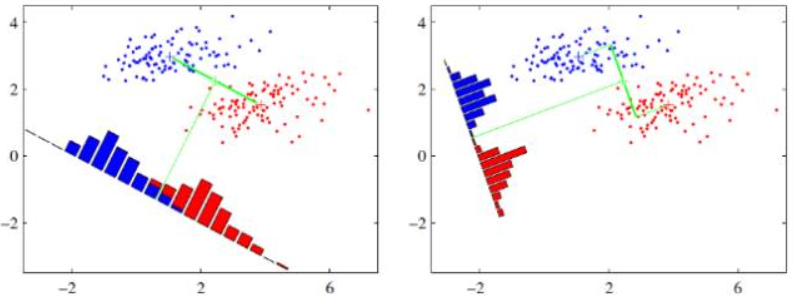
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
二、LDA原理与流程



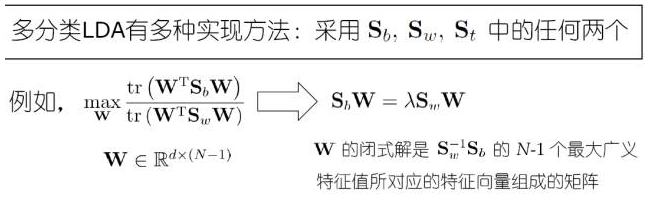
三、LDA分类

四、LDA降维

五、LDA与PCA的相同点和不同点
LDA用于降维,和PCA有很多相同,也有很多不同的地方
相同点
- 1)两者均可以对数据进行降维。
- 2)两者在降维时均使用了矩阵特征分解的思想。
- 3)两者都假设数据符合高斯分布。
不同点
- 1)LDA是有监督的降维方法,而PCA是无监督的降维方法
- 2)LDA降维最多降到类别数k-1的维数,而PCA没有这个限制。
- 3)LDA除了可以用于降维,还可以用于分类。
- 4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。


四、LDA的优缺点
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在进行图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
优点
- 1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
- 2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
缺点
- 1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
- 2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
- 3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
- 4)LDA可能过度拟合数据。
参考文献:
机器学习理论基础学习3.2--- Linear classification 线性分类之线性判别分析(LDA)的更多相关文章
- 机器学习理论基础学习12---MCMC
作为一种随机采样方法,马尔科夫链蒙特卡罗(Markov Chain Monte Carlo,以下简称MCMC)在机器学习,深度学习以及自然语言处理等领域都有广泛的应用,是很多复杂算法求解的基础.比如分 ...
- 机器学习理论基础学习3.1--- Linear classification 线性分类之感知机PLA(Percetron Learning Algorithm)
一.感知机(Perception) 1.1 原理: 感知机是二分类的线性模型,其输入是实例的特征向量,输出的是事例的类别,分别是+1和-1,属于判别模型. 假设训练数据集是线性可分的,感知机学习的目标 ...
- 机器学习理论基础学习3.3--- Linear classification 线性分类之logistic regression(基于经验风险最小化)
一.逻辑回归是什么? 1.逻辑回归 逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,来达到将数据二分类的目的. logistic回归也称为逻辑回归,与线性回归这样输出 ...
- 机器学习理论基础学习3.5--- Linear classification 线性分类之朴素贝叶斯
一.什么是朴素贝叶斯? (1)思想:朴素贝叶斯假设 条件独立性假设:假设在给定label y的条件下,特征之间是独立的 最简单的概率图模型 解释: (2)重点注意:朴素贝叶斯 拉普拉斯平滑 ...
- 机器学习理论基础学习3.4--- Linear classification 线性分类之Gaussian Discriminant Analysis高斯判别模型
一.什么是高斯判别模型? 二.怎么求解参数?
- 机器学习理论基础学习17---贝叶斯线性回归(Bayesian Linear Regression)
本文顺序 一.回忆线性回归 线性回归用最小二乘法,转换为极大似然估计求解参数W,但这很容易导致过拟合,由此引入了带正则化的最小二乘法(可证明等价于最大后验概率) 二.什么是贝叶斯回归? 基于上面的讨论 ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 机器学习理论基础学习5--- PCA
一.预备知识 减少过拟合的方法有:(1)增加数据 (2)正则化(3)降维 维度灾难:从几何角度看会导致数据的稀疏性 举例1:正方形中有一个内切圆,当维度D趋近于无穷大时,圆内的数据几乎为0,所有的数据 ...
- 机器学习理论基础学习13--- 隐马尔科夫模型 (HMM)
隐含马尔可夫模型并不是俄罗斯数学家马尔可夫发明的,而是美国数学家鲍姆提出的,隐含马尔可夫模型的训练方法(鲍姆-韦尔奇算法)也是以他名字命名的.隐含马尔可夫模型一直被认为是解决大多数自然语言处理问题最为 ...
随机推荐
- css笔记 - 张鑫旭css课程笔记之 vertical-align 篇
支持负值的属性: margin letter-spacing word-spacing vertical-align 元素vertical-align垂直对齐的位置与前后元素都没有关系元素vertic ...
- Linux命令 swap:内存交换空间
swap 内存交换空间的概念 swap使用上的限制
- java(1) 编程基础
1.classpath 环境变量 * 当java虚拟机需要运行一个类时,会在classpath 环境变量中所定义的路径下寻找所需的class文件 2.java 的基本语法 * java 语言是严格区分 ...
- hdu 4746Mophues[莫比乌斯反演]
Mophues Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 327670/327670 K (Java/Others) Total ...
- github命令行下载项目源码
一.git clone [URL] 下载指定ur的源码 $ git clone https://github.com/jquery/jquery 二.指定参数, -b是分支, --depth 1 最新 ...
- stdarg.h头文件源代码分析
谈到C语言中可变参数函数的实现(参见C语言中可变参数函数实现原理),有一个头文件不得不谈,那就是stdarg.h 本文从minix源码中的stdarg.h头文件入手进行分析: #ifndef _STD ...
- Spring Cloud Eureka 服务消费者
参考<spring cloud 微服务实战> 现在已经构建了服务注册中心和服务提供中心,下面就来构建服务消费者: 服务消费者主要完成:发现服务和消费服务.其中服务的发现主要由Eureka的 ...
- vue---阻止默认表单提交的三种方法
vue在做表单提交的时候,需要用到一些自定义的验证规则,这个时候就需要阻止表单默认的提交方式. 方法一:直接阻止 <form id="form" @submit=" ...
- js模拟点击打开超链接
js模拟点击打开超链接,页面上有一些锚文本,如果用 JS 批量在新窗口打开. jquery示例: <div class="link"> <a href=" ...
- pandas生成时间列表(某段连续时间或者固定间隔时间段)
python生成一个日期列表 首先导入pandas import pandas as pd def get_date_list(begin_date,end_date): date_list = [x ...