ShardingJDBC使用不当引发的线上事故
本文讲述一个由 ShardingJDBC 使用不当引起的悲惨故事。
一. 问题重现
有一天运营反馈我们部分订单状态和第三方订单状态无法同步。
根据现象找到了不能同步订单状态是因为 order 表的 thirdOrderId 为空导致的,但是这个字段为啥为空,排查过程比较波折。
过滤掉复杂的业务逻辑,当时的代码可以简化为这样:
Order order;
// 业务在特定情况会生成新的订单
if (特定条件) {
order = buildOrders();
orderService.saveBatch(Lists.newArrayList(order));
}
// 省略复杂的业务逻辑
// ...
// 调用第三方下单
ThirdOrder thirdOrder = callThirdPlaceOrder()
// 设置order表 thirdOrderId 字段
order.setThirdOrderId(thirdOrder.getOrderId());
// 设置 order_item 表 thirdOrderId 字段
orderItems.foreach(e -> e.setThirdOrderId(thirdOrder.getOrderId()));
// 更新 order 表
orderService.updateById(order);
// 更新 order_item 表
orderItemService.updateBatchById(itemUpdateList);
我们发现这类有问题的订单,order 表 thirdOrderId 为空,但是 order_item 表 thirdOrderId 更新成功了,使我们直接排除了这里母单更新“失败”的问题,因为两张表的更新操作在一个事务里面,子单更新成功了说明这里的代码逻辑应该没有问题。
就是这里的错觉,让我们走了很多弯路。我们排查了所有可能存在并发更新、先读后写、数据覆盖的地方,结合业务日志,翻遍了业务代码仍然无法确认问题具体在哪里。最后只能在可能出现问题的地方补充了日志,同时我们也在此处更新 order 表的地方加上了日志,最后发现在执行 orderService.saveBatch 后 order 的 id 为空,导致 order 的更新并没有成功。
说实话找到问题的那一刻有点颠覆我的认知,在我的印象中,MyBatisPlus批量插入的方法是可以返回ID,经过实验,在当前项目环境中,save()方法会返回主键ID,但是saveBatch()方法不会。这种颠覆认知的新
二. 源码分析
2.1 JDBC如何获取批量插入数据的ID
要想摸清楚批量插入后为什么没有获取到主键ID,我们得先了解一下JDBC如何批量插入数据,以及在批量插入操作后,获取数据库的主键值。
// 创建一个 PreparedStatement 对象,并指定获取自动生成的主键
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO order_info (column1, column2) VALUES (?, ?)", Statement.RETURN_GENERATED_KEYS);
// 执行批量插入操作
pstmt.setString(1, "value1"); // 设置参数值
pstmt.setString(2, "value2"); // 设置参数值
pstmt.addBatch(); // 添加批量操作
// ... 添加更多批量操作
// 执行批量操作
pstmt.executeBatch();
// 获取生成的主键
ResultSet generatedKeys = pstmt.getGeneratedKeys();
while (generatedKeys.next()) {
int primaryKey = generatedKeys.getInt(1); // 假设主键为整数类型,如果是其他类型,请根据实际情况调整
System.out.println("Generated Primary Key: " + primaryKey);
}
// 关闭相关资源
generatedKeys.close();
pstmt.close();
conn.close();
在执行批量插入操作后,我们可以通过 Statement.getGeneratedKeys() 方法获取数据库主键值。
2.2 MyBatis 批量插入原理
MyBatis-Plus 是对 MyBatis 的一种增强,底层还是依赖于MyBatis SqlSession API对数据库进行的操作,而SqlSession执行批量插入大概分为如下几步:
try (SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH)) {
YourMapper mapper = sqlSession.getMapper(YourMapper.class);
List<YourEntity> entities = new ArrayList<>();
// 添加要插入的实体对象到列表中
for (YourEntity entity : entities) {
// 调用插入方法,但此时还未真正执行
mapper.insert(entity);
}
// 批量执行SQL
sqlSession.flushStatements();
sqlSession.commit(); // 提交事务
} catch (Exception e) {
sqlSession.rollback(); // 发生异常时回滚事务
}
2.3 Myabtis-Plus + ShardingJDBC 批量插入数据为什么无法获取ID
MyBatis-Plus 执行批量插入操作本质上和MyBatis是一致的,Myabtis-Plus saveBtach方法:
/**
* 插入(批量)
*
* @param entityList 实体对象集合
*/
@Transactional(rollbackFor = Exception.class)
default boolean saveBatch(Collection<T> entityList) {
return saveBatch(entityList, DEFAULT_BATCH_SIZE);
}
/**
* 批量插入
*
* @param entityList ignore
* @param batchSize ignore
* @return ignore
*/
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
进入executeBatch:
/**
* 执行批量操作
*
* @param entityClass 实体类
* @param log 日志对象
* @param list 数据集合
* @param batchSize 批次大小
* @param consumer consumer
* @param <E> T
* @return 操作结果
* @since 3.4.0
*/
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {
int size = list.size();
int i = 1;
for (E element : list) {
// 执行 sqlSession 的 insert 方法
consumer.accept(sqlSession, element);
if ((i % batchSize == 0) || i == size) {
// 每达到 batchSize 就执行SQL
sqlSession.flushStatements();
}
i++;
}
});
}
在 executeBatch 中 MyBatis-Plus 会循环调用 SqlSession.insert 缓存插入语句,每 batchSize 提交一次SQL。
进入 DefaultSqlSession.flushStatements():
@Override
public List<BatchResult> flushStatements() {
try {
return executor.flushStatements();
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error flushing statements. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
委托 BaseExecutor.flushStatements() 执行:
@Override
public List<BatchResult> flushStatements() throws SQLException {
return flushStatements(false);
}
public List<BatchResult> flushStatements(boolean isRollBack) throws SQLException {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
return doFlushStatements(isRollBack);
}
最终 doFlushStatements() 方法由各个子类去实现,BaseExecutor 有 BatchExecutor,ReuseExecutor,SimpleExecutor,ClosedExecutor,MybatisBatchExecutor,MybatisReuseExecutor,MybatisSimpleExecutor这几种实现。
Mybatis 开头的是 Mybatis-Plus 提供的实现,分别对应 MyBatis 的 simple、reuse、batch执行器类别。不管哪个执行器,里面都会有一个 StatementHandler 接口来负责具体执行SQL。
而在 MyBatis-Plus 批量插入的场景中,是由 MybatisBatchExecutor#doFlushStatements 执行的:
@Override
public List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
try {
List<BatchResult> results = new ArrayList<>();
if (isRollback) {
return Collections.emptyList();
}
for (int i = 0, n = statementList.size(); i < n; i++) {
Statement stmt = statementList.get(i);
applyTransactionTimeout(stmt);
BatchResult batchResult = batchResultList.get(i);
try {
// 1. 此处调用JDBC PreparedStatement API,批量执行SQL
batchResult.setUpdateCounts(stmt.executeBatch());
MappedStatement ms = batchResult.getMappedStatement();
List<Object> parameterObjects = batchResult.getParameterObjects();
KeyGenerator keyGenerator = ms.getKeyGenerator();
if (Jdbc3KeyGenerator.class.equals(keyGenerator.getClass())) {
Jdbc3KeyGenerator jdbc3KeyGenerator = (Jdbc3KeyGenerator) keyGenerator;
// 2. 使用 jdbc3KeyGenerator 获取批量执行的所生成的 ID
jdbc3KeyGenerator.processBatch(ms, stmt, parameterObjects);
} else if (!NoKeyGenerator.class.equals(keyGenerator.getClass())) { //issue #141
for (Object parameter : parameterObjects) {
keyGenerator.processAfter(this, ms, stmt, parameter);
}
}
// Close statement to close cursor #1109
closeStatement(stmt);
} catch (BatchUpdateException e) {
StringBuilder message = new StringBuilder();
message.append(batchResult.getMappedStatement().getId())
.append(" (batch index #")
.append(i + 1)
.append(")")
.append(" failed.");
if (i > 0) {
message.append(" ")
.append(i)
.append(" prior sub executor(s) completed successfully, but will be rolled back.");
}
throw new BatchExecutorException(message.toString(), e, results, batchResult);
}
results.add(batchResult);
}
return results;
} finally {
for (Statement stmt : statementList) {
closeStatement(stmt);
}
currentSql = null;
statementList.clear();
batchResultList.clear();
}
}
在 1 处,执行批量插入语句后,然后在2处调用 Jdbc3KeyGenerator.jdbc3KeyGenerator 获取ID:
// org.apache.ibatis.executor.keygen.Jdbc3KeyGenerator#processBatch
public void processBatch(MappedStatement ms, Statement stmt, Object parameter) {
final String[] keyProperties = ms.getKeyProperties();
if (keyProperties == null || keyProperties.length == 0) {
return;
}
// 本质上,还是调用JDBC Statement.getGeneratedKeys() 方法获取ID(参考文中2.1示例)
try (ResultSet rs = stmt.getGeneratedKeys()) {
final ResultSetMetaData rsmd = rs.getMetaData();
final Configuration configuration = ms.getConfiguration();
if (rsmd.getColumnCount() < keyProperties.length) {
// Error?
} else {
assignKeys(configuration, rs, rsmd, keyProperties, parameter);
}
} catch (Exception e) {
throw new ExecutorException("Error getting generated key or setting result to parameter object. Cause: " + e, e);
}
}
但是我们项目中如果使用的 ShardingJDBC,那么此时调用的就是 ShardingPreparedStatement.getGeneratedKeys():
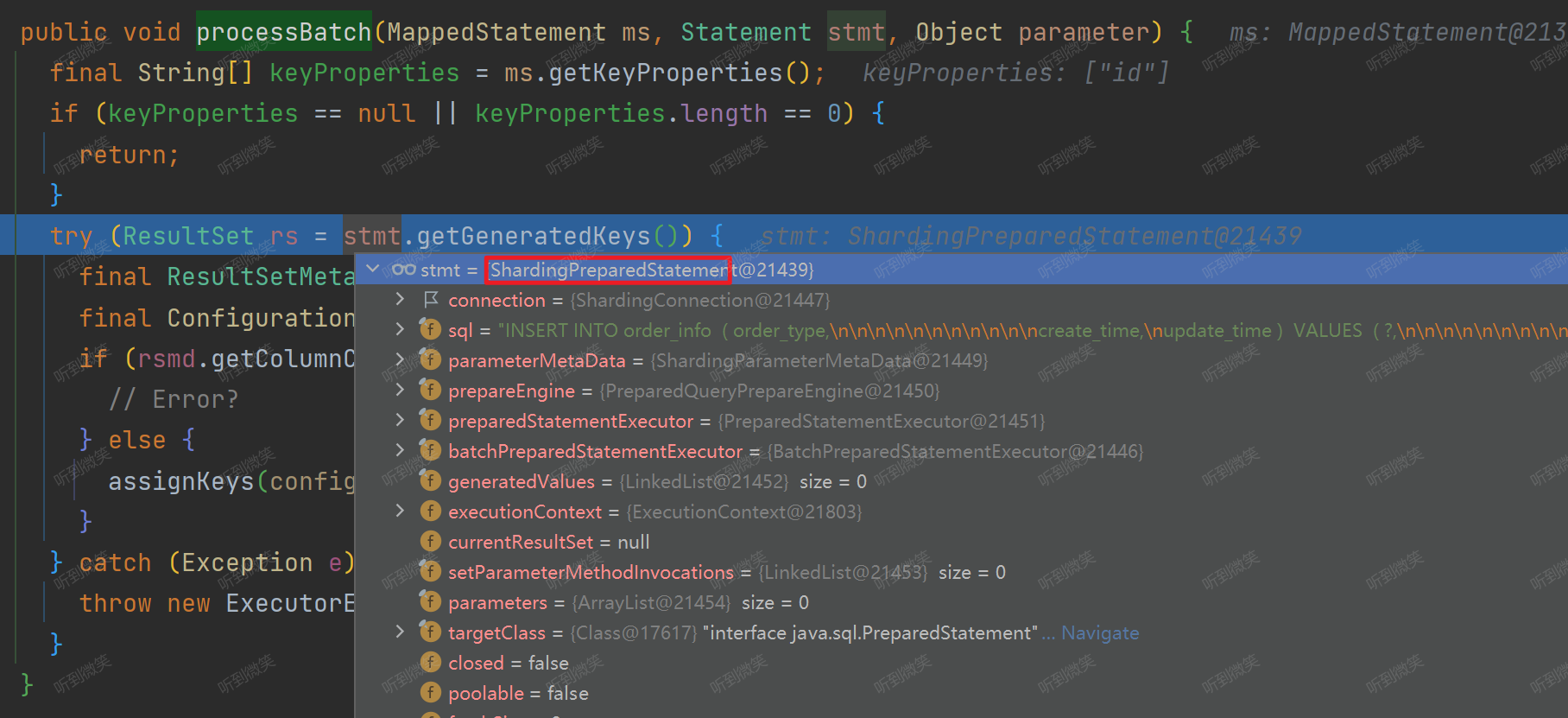
通过 DEBUG,我们发现在我们项目中 ShardingPreparedStatement.getGeneratedKeys() 返回的是null值:
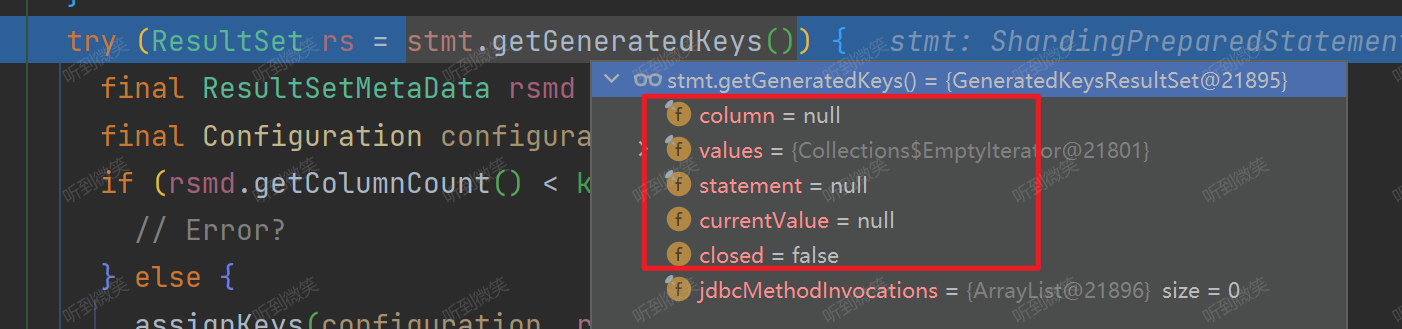
这也就找到了为什么MyBatis-Plus 和 ShardingJDBC 一起使用时获取不到ID值的问题,问题的根节并不在MyBatis这边,而是 ShardingJDBC 实现的 PreparedStatement 获取不到key。
2.4 为什么执行MyBatis-Plus save方法可以获取到主键
当我们调用 MyBatis-Plus save() 方法保存单条数据时,底层实际上还是调用的 ShardingPreparedStatement.getGeneratedKeys() 方法,获取插入后的主键key:
@Override
public ResultSet getGeneratedKeys() throws SQLException {
Optional<GeneratedKeyContext> generatedKey = findGeneratedKey();
if (preparedStatementExecutor.isReturnGeneratedKeys() && generatedKey.isPresent()) {
return new GeneratedKeysResultSet(generatedKey.get().getColumnName(), generatedValues.iterator(), this);
}
if (1 == preparedStatementExecutor.getStatements().size()) {
return preparedStatementExecutor.getStatements().iterator().next().getGeneratedKeys();
}
return new GeneratedKeysResultSet();
}
但是在执行单条数据插入时,1 == preparedStatementExecutor.getStatements().size() 是成立的,就会返回底层被真实被代理的MySQL JDBC 的 Statement 获取主键key:
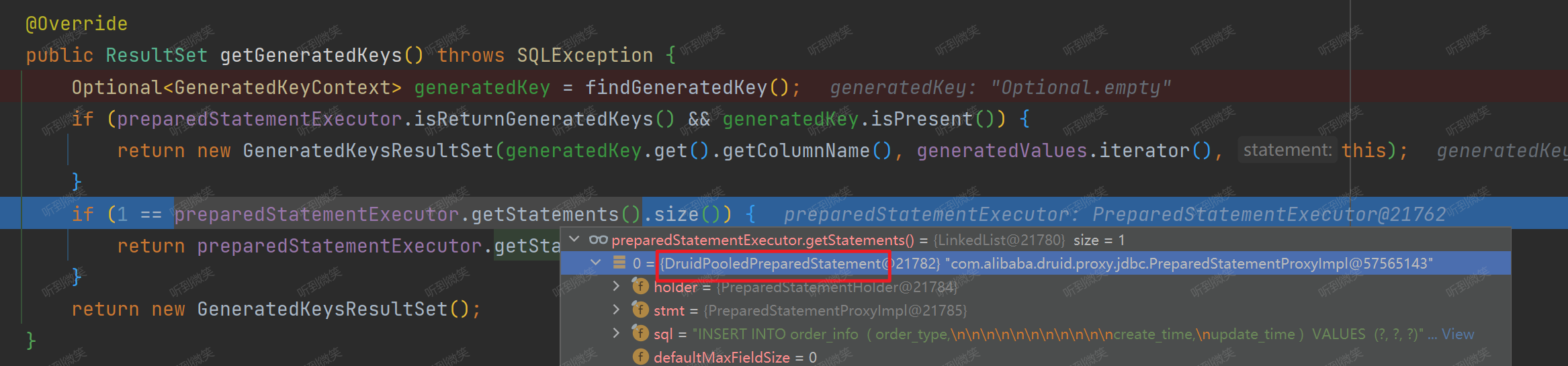
至于 AbstractStatementExecutor.statements 为什么在执行单一语句的时候statements里不为空,但是批量插入的时候,这个list为空,可以参考下面的回答:
AbstractStatementExecutor.statements是ShardingJDBC中的一个重要数据结构,它用于存储待执行的SQL语句及其对应的数据库连接信息。在进行SQL操作时,ShardingJDBC会根据你的分片策略将SQL语句路由到相应的数据库节点,并生成对应的数据结构存储在statements这个列表里。那么,为什么在执行单一SQL语句时,
statements不为空,而在批量插入时,这个列表却为空呢?这主要是因为ShardingJDBC处理这两种情况的方式有所不同。
- 对于单一SQL语句,ShardingJDBC将其路由到正确的数据库节点(可能是多个),然后创建对应的PreparedStatement对象,这些对象被存储在
statements列表中,以便后续执行和获取结果。- 对于批量插入,ShardingJDBC采取了一种“延迟执行”的策略。具体来说,ShardingJDBC首先会解析和拆分批量插入语句,然后将拆分后的单一插入语句暂存起来,而不是立即创建PreparedStatement对象。这就导致了在批量插入过程中,
statements列表为空。这样做的主要目的是为了提高批量插入的性能,因为创建PreparedStatement对象和管理数据库连接都是需要消耗资源的。
三. 总结
本文由故障现象定位到了具体的问题点是因为 MyBatis-Plus 批量插入没有返回数据库组件,而跟踪源码后我们却发现是因为ShardingJDBC不支持批量插入获取主键值。
ShardingJDBC不支持批量插入后获取主键,主要是因为在批量插入操作中,ShardingJDBC可能需要将数据插入到多个不同的数据库节点,在这种情况下,每个节点都可能有自己的主键生成规则,并且这些节点可能并不知道其他节点的主键值。因此,如果你需要在批量插入后获取自动生成的主键,可能需要通过其他方式实现,例如使用全局唯一ID作为主键。
ShardingJDBC使用不当引发的线上事故的更多相关文章
- 由定时脚本错误以及Elasticsearch配置错误引发的Flink线上事故
近期接手离职同事项目,突然遇到线上事故,Flink无法正常聚合数据生成指标. 以下是详细的排查过程: 问题复现 清晨,运维报告Flink数据分析模块无法正常生成指标数据. 赶紧登陆Flink所在机器, ...
- 一次Java线程池误用(newFixedThreadPool)引发的线上血案和总结
一次Java线程池误用(newFixedThreadPool)引发的线上血案和总结 这是一个十分严重的线上问题 自从最近的某年某月某天起,线上服务开始变得不那么稳定(软病).在高峰期,时常有几台机器的 ...
- 记一次真实的线上事故:一个update引发的惨案!
目录 前言 项目背景介绍 要命的update 结语 前言 从事互联网开发这几年,参与了许多项目的架构分析,数据库设计,改过的bug不计其数,写过的sql数以万计,从未出现重大纰漏,但常在河边走,哪 ...
- RabbitMQ 线上事故!慌的一批,脑袋一片空白。。。
前言 那天我和同事一起吃完晚饭回公司加班,然后就群里就有人@我说xxx商户说收不到推送,一开始觉得没啥.我第一反应是不是极光没注册上,就让客服通知商户,重新登录下试试.这边打开极光推送的后台进行检查. ...
- 【转】一次Java线程池误用(newFixedThreadPool)引发的线上血案和总结
[转]原文链接:https://cloud.tencent.com/developer/article/1497826 这是一个十分严重的线上问题 自从最近的某年某月某天起,线上服务开始变得不那么稳定 ...
- ThreadLocal引起的一次线上事故
> 线上用户存储数据后查看提示无权限 前言 不知道什么时候年轻的我曾一度认为Java没啥难度,没有我实现不了的需求,没有我解不了的bug 直到我遇到至今难忘的一个bug . 线上用户存储数据后查 ...
- 记一次线上事故的JVM内存学习
今天线上的hadoop集群崩溃了,现象是namenode一直在GC,长时间无法正常服务.最后运维大神各种倒腾内存,GC稳定后,服务正常.虽说全程在打酱油,但是也跟着学习不少的东西. 第一个问题:为什么 ...
- 一个SQL注释引发的线上问题
最近开始服务拆分,时间将近半个月.测试阶段也非常顺利,没有什么问题. 但上线之后的第二天,产品就风风火火的来找我们了,一看就是线上有什么问题.我们也不敢说,我们也不敢问,线上的后台商品忽然无法上架了, ...
- MyBatis 版本升级引发的线上问题
MyBatis上线前后的版本:上线前(3.2.3)上线后(3.4.6) 服务上线后,开始陆续出现了一些更新系统交互日志方面的报警,这属于系统的辅助流程,报警如下代码所示.我们发现都是跟 MyBatis ...
- 一次线上事故,让我对MySql的时间戳存char(10)还是int(10)有了全新的认识
美好的周五 周五的早晨,一切都是那么美好. 然鹅,10点多的时候,运营小哥哥突然告诉我后台打不开了,我怀着一颗"有什么大不了的,估计又是(S)(B)不会连wifi"的心情,自信的打 ...
随机推荐
- consul:啥?我被优化没了?AgileConfig+Yarp替代Ocelot+Consul实现服务发现和自动网关配置
现在软件就业环境不景气,各行各业都忙着裁员优化.作为一个小开发,咱也不能光等着别人来优化咱,也得想办法优化下自己.就拿手头上的工作来说吧,我发现我的微服务应用里,既有AgileConfig这个日志组件 ...
- JDK 19新特性 & JDK 多版本安装切换配置
新的JDK 19包含如下7个新的特性: 转自:JDK19中比较重要的新特性-电子发烧友网 JEP 405: Record Patterns(Record模式) JEP 422: Linux/RISC- ...
- 重新点亮linux 命令树————网络管理[十一二]
前言 简单整理一下网络管理. 正文 网络管理需要掌握: 网络状态查看 网络配置 路由命令 网络故障排除 网络服务管理 常用网络配置文件 网络状态的查看: 1.net-tools ---->1.i ...
- 手机配置IPV6
据可靠消息说今年7月份前大部分系统都得支持ipv6,之前也没当回事,突然说要全切,还得验证ipv6的支持情况. 网上找了一堆,发现都过时了,或者行不通,琢磨了一下把华为android的搞定了(流量模式 ...
- 动手实现自己的http服务器【精简版】
1 package v2; 2 3 import java.io.IOException; 4 import java.io.OutputStream; 5 import java.io.PrintS ...
- ES6中数组新增了哪些扩展?
一.扩展运算符的应用 ES6通过扩展元素符...,好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列 console.log(...[1, 2, 3])// 1 2 3console.l ...
- git默认忽略文件名称大小写
0. 现象 当将文件名称test 修改为 Test时,git提交记录检测不到变化 1.原因 Git默认设置忽略文件名大小写是因为不同操作系统对文件名大小写的处理方式不同,为了避免在不同操作系统之间出现 ...
- vscode下的超级慢的解决方法
vscode下的超级慢的解决方法 从网上看到的方法,记录给自己看 vscode官网:https://code.visualstudio.com/Download 复制下载链接 链接如下: https: ...
- 力扣35(java&python)-搜索插入位置(简单)
题目: 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引.如果目标值不存在于数组中,返回它将会被按顺序插入的位置. 请必须使用时间复杂度为 O(log n) 的算法. 示例 1: 输入: ...
- Flink集成Iceberg在同程艺龙的实践
------------恢复内容开始------------ null ------------恢复内容结束------------