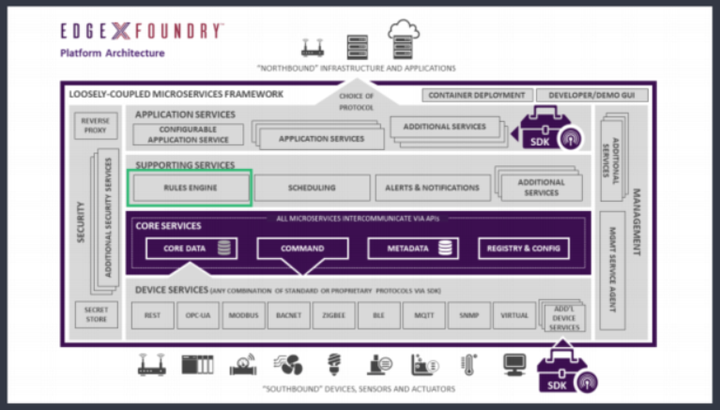
KubeEdge和Kuiper“双剑合并”,轻松解决边缘流式数据处理
摘要:KubeEdge 是一个开源的边缘计算平台,它在Kubernetes原生的容器编排和调度能力之上,扩展实现了 云边协同、计算下沉、海量边缘设备管理、边缘自治等能力。KubeEdge还将通过插件的形式支持5G MEC、AI云边协同等场景,目前在很多领域都已落地应用。
在边缘的流失处理产品Kuiper
Kuiper是从2019年初开始做的,在2019年10月份,发布了第一个版本,一直持续迭代到现在,它的整个架构是一个比较经典的流式处理架构。
产品设计目标:在云端运行的流式处理,像Spark与Flink可以运行在边缘端
Kuiper架构图

整体架构可分为3部分,左侧为sources,代表数据来源的位置,数据来源可能是KubeEdge里面有个边缘端的MQTT macOS broker,也可能是文件、窗口、数据库;
右侧为Sinks,代表数据处理完成后所要存储的位置,也就是目标系统,目标可以是MQTT,可以将其存到文件、数据库里面,也可以调用HTTP service;
中间部分分成了这几层,最上层为数据业务逻辑处理,这个层面提供了SQL statement、Rule Parser,SQL processors进行处理后并将其转化成SQL plan;下面层为Streaming runtime和SQL runtime, 运行最终执行出来的 plan;最底层为storage,用来存储有些消息流出。
Kuiper使用场景
流式处理:实现在边缘端的实时流式处理
规则引擎:灵活定义规则引擎,实现告警和消息转发
数据格式与协议转换:实现边缘与云端不同类型的数据格式与异构协议之间灵活转换,实现IT&OT融合
KubeEdge与Kuiper集成
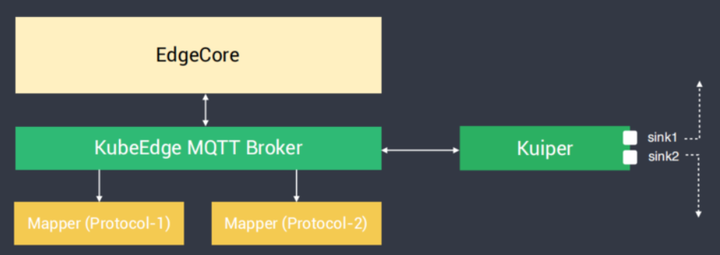
部分架构图
Kuiper是装在 KubeEdge MQTT Broker后面,整个都运行在边缘端,底下为不同的Mapper,也就是接入各种各样不同的协议。边缘MQTT Broker用来交换消息。
数据处理的类型:
从设备模型文件定义中获取类型定义
将数据转换为Kuiper的数据类型
创建流时,可使用schema-less流定义
支持的数据类型有int、string、bool、float
KubeEdge模型文件和配置
下图为部分配置文件,包括设备的名称、属性、name、data type、Description等。

部分配置文件
保存设备模型文件
在ect/mqtt_source.yaml中配置模型文件信息
- KubeEdgeVersion:目前未使用,为适配将来不同的版本模型文件预留
- KubeEdgeModelFile:模型文件路径
通过config-map下发配置,保存到相关目录下
Kuiper使用过程
1)定义流:类似余数据库中表格的定义
DATASOURCE=”$hw/events/device/+/twin/update”为KubeEdge里定义好的topic

2)定义并提交规则
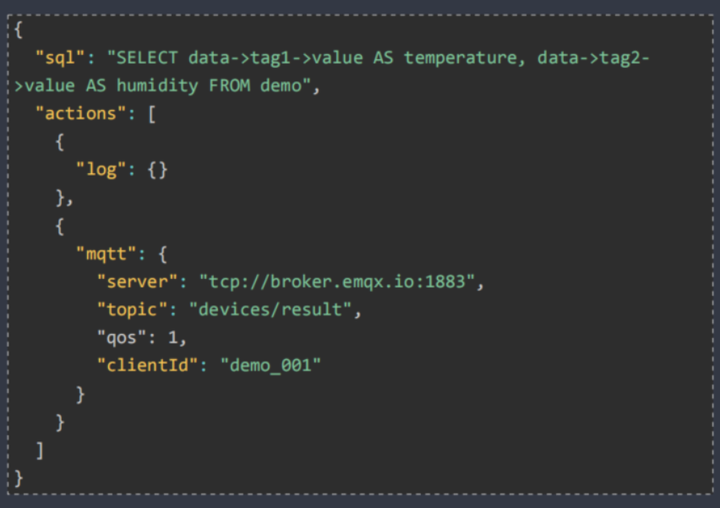
用SQL实现业务逻辑,并将运行结果发送到指定目标
支持的SQL
SELECT/FROM/WHERE/ORDER
JOIN/GROUP/HAVING
4类时间窗口+1个计数窗口
60+SQL函数
3)运行
KubeEdge中部署Kuiper规则
1)运用Kuiper-Kubernetes-tool
2)该程序为一个工具类,单独运行在容器中,执行通过config-map下发的命令配置文件
配置文件中用于指定kuiper服务所在的地址和端口等信息
命令文件所在的目录
3)通过config-map下发命令执行文件,该工具定期自动扫描文件,然后执行命令
Kuiper manager-云边协同管理控制台
另外一种方式是通过管理控制台来管理很多Kuiper节点,因为Kuiper可以运行在很多节点上。
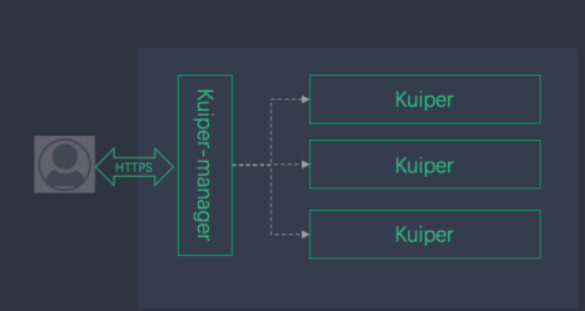
比如Kuiper可以运行在车联网的盒子里面,车联网有很多车,可以通过Kuiper-manager把所有的实例都接入进来,统一对其进行规则更新。
第一步是安装插件,我们提供了一些插件的知识,比如要接入不同的源,如果我们这边的源不支持,则可以自己写个插件,将插件进行安装,安装上去之后我们提供安卓插件界面,就可以使用了。
接下来为创建流定义
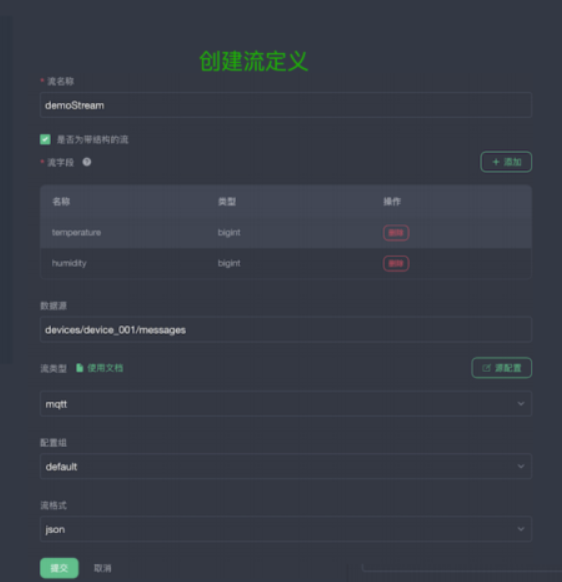
下图为数据存储的位置,下图所示为将数据保存到文件系统,进行路径的指定。
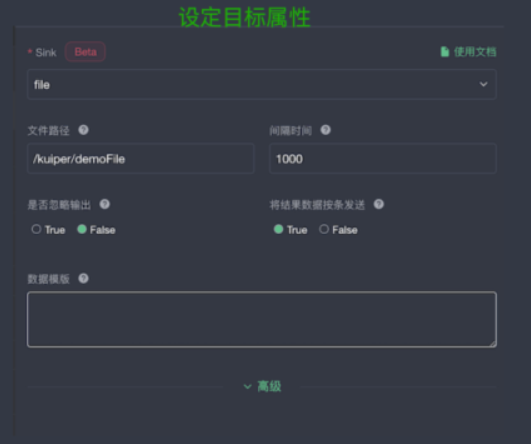
下图为可视化的编辑界面,可以进行规则的编写。
应用案例:国家工业互联网大数据中心
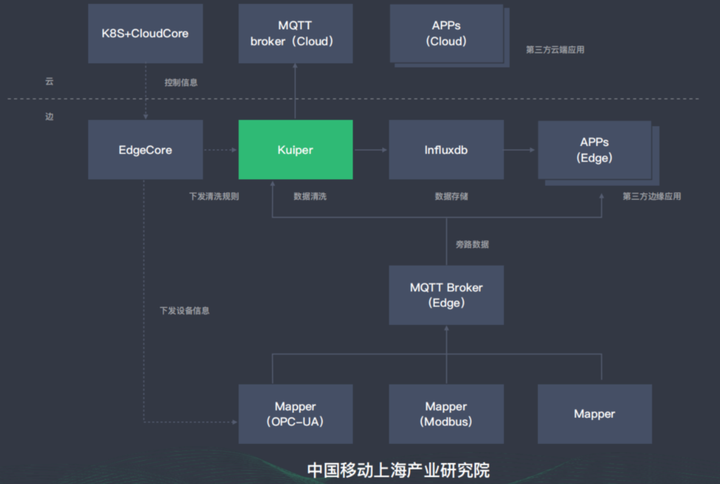
该案例是一个非常典型的使用场景。K8s+CloudCore部署在云端,将规则通过管理通道下放到Kuiper,Kuiper的位置是放在MQTT broker,会将数据定义,实现数据的清洗。目前通道有两条,第一条是将处理完的消息发往Cloud MQTT broker,第二条通道比如本地要做数据持久化,可将其存到Influxdb这个持续数据库,我们在边缘发生的一些第三方应用可以直接去调Influxdb里面的数据,做一些展示可视化等。底层是通过Mapper把不同的数据给接上来。
Kuiper里规则引擎的使用场景
LF EdgeX Foundry内置规则引擎,于2020年4月Geneva版本中已经正式发布。
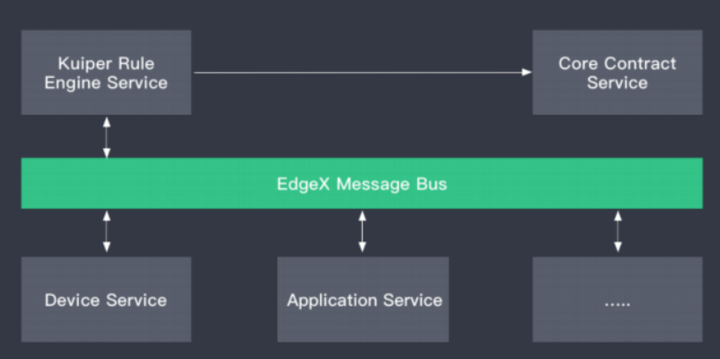
应用案例:异构系统对接数据格式转换
实现与ERP、MES等IT系统数据交换,我们提供了一个非常灵活的扩展能力,包括异构数据通过扩展插件采集后,可以利用SQL内置函数或者扩展函数进行快速、灵活处理;第二点是拿到数据处理结果后,通过sink的数据模板可以对分析结果进行转换,灵活适配各类目标系统所需的数据格式和协议,比如同样一条温度大于30度的规则,如果要去发送控制设备的指令,并且要发到微信上。这两个不同的目标系统,它所需要的接口和数据是不一样的,但对于这个规则是一样的,那么可以在 data里面,根据同一条规则触发两个不同的操作,你可以指定不同的 topic,数据即可发送,不需再进行复杂的编程;第三点是利用SAP NetWeaver RFC SDK,实现从SAP中读取数据,处理并转换后发送到别的异构系统。
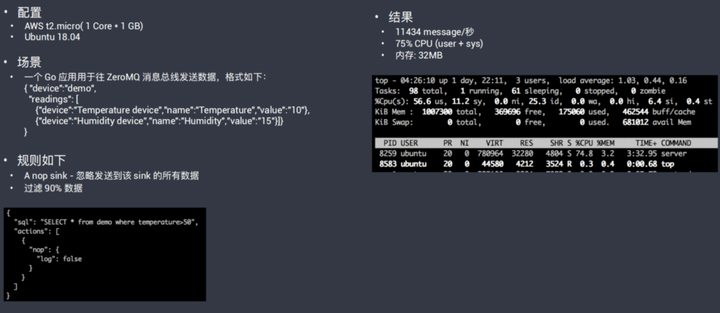
性能数据
Kuiper 支持并发运行数千条规则
8000规则*0.1消息/秒/规则,共计的TPS为800条/秒
规则定义
源:MQTT
SQL:select temperature from source where temperature>20(90%数据被过滤)
目标:日志
配置
AWS:2core*4GB
Ubuntu
资源使用
Memory:89%~72%;0.4MB/rule
GPU:25%
AWS t2.micro 配置10k+/s消息吞吐
KubeEdge和Kuiper“双剑合并”,轻松解决边缘流式数据处理的更多相关文章
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 转载:30多条mysql数据库优化方法,千万级数据库记录查询轻松解决
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- The New Stack:KubeEdge将Kubernetes的能力延伸至边缘
3月29日,权威技术分析网站The New Stack在Edge/IoT专栏发表了关于边缘计算项目KubeEdge的最新调研报告.原文观点如下: https://github.com/kubeedge ...
- 轻松解决oracle11g 空表不能exp导出的问题
轻松解决oracle11g 空表不能exp导出的问题 [引用 2012-9-22 18:06:36] 字号:大 中 小 oracle11g的新特性,数据条数是0时不分配segment,所以就不 ...
- Git分支合并冲突解决(续)
接Git分支合并冲突解决,在使用rebase合并冲突情况下,如果不小心,执行完add后执行了commit,此时本地仓库HEAD处于游离态(即HEAD指向未知的分支),如何解决? 解决方法 (1)此时, ...
- 转:git合并冲突解决方法
git合并冲突解决方法 1.git merge冲突了,根据提示找到冲突的文件,解决冲突 如果文件有冲突,那么会有类似的标记 2.修改完之后,执行git add 冲突文件名 3.git commit注意 ...
- git使用,多分支合并代码解决冲突,git删除远程分支,删除远程master默认分支方法
git使用,多分支合并代码解决冲突,git删除远程分支,删除远程master默认分支方法提交代码流程:1.先提交代码到自己分支上2.切换到devlop拉取代码合并到当前分支3.合并后有变动的推送到自己 ...
- 轻松解决U盘拷贝文件时提示文件过大问题
现在的高科技时代生活中,u盘的使用已经是许多从事电脑it行业的人每天都必须要用到的用具.可以在一台电脑上使用u盘拷贝文件到另外一台电脑上进行使用,加上它的身材小巧,非常方便我们随身携带到任何地方进行使 ...
- iOS教你轻松打造瀑布流Layout
前言 : 在写这篇文章之前, 先祝贺自己, 属于我的GitHub终于来了. 这也是我的GitHub的第一份代码, 以下文章的代码均可以在Demo clone或下载. 欢迎大家给予意见. 觉得写得不错的 ...
- Insights直播预告 | 多媒体管线服务,助您轻松进入“技术流”创新阵地
[导读] 随着各类音视频移动应用快速发展,短视频.线上直播等娱乐方式逐渐为大众所喜爱.优质的视听效果和交互体验,往往能吸引更多的用户.多媒体管线服务作为一个轻量级的多媒体开发框架,其跨平台.高性能的多 ...
随机推荐
- UVA10702 Travelling Salesman 题解
UVA10702 Travelling Salesman 题解 题面: 有个旅行的商人,他每到一个的新城市,便卖掉所有东西再购买新东西,从而获得利润.从某城市 A 到某城市 B 有固定利润(B 到 ...
- 16.1 Socket 端口扫描技术
端口扫描是一种网络安全测试技术,该技术可用于确定对端主机中开放的服务,从而在渗透中实现信息搜集,其主要原理是通过发送一系列的网络请求来探测特定主机上开放的TCP/IP端口.具体来说,端口扫描程序将从指 ...
- Vue之自定义过滤器
使用Vue.filter('过滤器名称',方法); 1. <!DOCTYPE html> <html lang="en"> <head> < ...
- CF1401B [Ternary Sequence]
Problem 题目简述 两个序列 \(A, B\).这两个序列都是由 \(0,1,2\) 这三个数构成. \(x_1,y_1,z_1\) 和 \(x_2,y_2,z_2\) 分别代表 \(A\) 序 ...
- [ABC321C] 321-like Searcher
Problem 题目简述 给你一个 \(K\),求出 \([1 \sim K]\) 区间内有多少个 321-like Number. 321-like Number 的定义: 每一位上的数字从左到右严 ...
- Java代码审计之目录穿越(任意文件下载/读取)
一.目录穿越漏洞 1.什么是目录穿越 所谓的目录穿越指利用操作系统中的文件系统对目录的表示.在文件系统路径中,".."表示上一级目录,当你使用"../"时,你正 ...
- kubernetes驱逐机制总结
概述 k8s的驱逐机制是指在某些场景下,如node节点notReady.node节点压力较大等,将pod从某个node节点驱逐掉,让pod的上层控制器重新创建出新的pod来重新调度到其他node节点. ...
- 2007年对Youtube小视频的分析文章
Understanding the Characteristics of Internet Short Video Sharing: YouTube as a Case Study 视频的种类 该研究 ...
- 老是听到做PPT要会“内容可视化”,到底啥是内容可视化?
在PPT中,内容可视化是指将文字.数据和概念等抽象信息转化为图像.图表.图表及其他可视化元素来呈现.通过合适的颜色.形状.大小和布局等视觉设计元素来强调信息的关键点和关系, 从而提高观众对信息的理解和 ...
- 关于git 解决分支冲突问题(具体操作,包含截图,教你一步一步解决冲突问题)
当在Git中有多个开发者在同一个分支上工作时,可能会发生分支冲突.分支冲突指的是多个开发者在同一时间修改相同的代码文件,导致Git无法自动合并这些更改. 比如说:我在github上进行了md文件的修改 ...