数据分析应该掌握的知识及SQL技能
一、概念及常识
1、数据分析必备的统计学知识
- 描述统计学
1.平均值、中位数、众数
2.方差、标准差
3.统计分布:正态分布、指数分布、二项分布、卡方分布 - 推论统计学
1.假设检验
2.置信区间
3.显着性测试 - 实验设计
1.A/B测试
2.实验条件控制
3.双盲测试
4.幂律分布
2、数据分析的常用工具
- SQL:数据科学家的必备技能
- ECXCEL:容易上手,所见即所得,无需编程即可对数据进行运算和作图。
- R:专门为数据科学而设计的语言,在数据科学领域比PYTHON略微受欢迎些。
- Python:简单易学,功能强大且丰富,是大学教授中最受欢迎的编程语言。
- Spark:专为大规模数据处理而设计的基于内存计算的引擎。
- Tableau:帮人们查看并处理数据,可进行快速分析、可视化并分享结果
3、从事数据科学需要掌握的技能
要从事数据科学,我们需要从数据知识、计算机知识、专业知识这三个维度考虑
- 具有分析思维
- 基本的大学数学知识,包括微积分和线性代数。
- 统计学知识,包括描述统计学和推导统计学
- 编程基础,如 Python 、R语言、SQL语句
- 算法知识,如回归、分类、聚类算法等。
- 数据可视化,将你的分析结果展示出来。
- 领域专业知识,如商业知识、生物知识等,视具体分析的问题而定。
3.1 数据科学的工作流程
虽然数据分析是一个不断迭代的过程,而且不同的步骤会有些交叉,但是我们依然可以将过程简化为以下七个步骤:
- 明确的问题
- 收集原始数据
- 数据清洗
- 数据探索
- 应用模型进行深度分析
- 传达分析结果
- 是分析过程可再现
在一个数据项目中,我们绝大部分的努力都将花在获取数据和清洗数据上(步骤2-3)以及展示分析结果和过程(6-7)上。
3.2 数据科学中的职业角色
- 数据科学家(data scieneists):有人这样描述数据科学家,他们比统计学家更懂编程,而比工程师更懂统计,
- 数据分析师(data analysts):他们研究数据并提供相应的报告和可视化图表,可以将数据分析师看作数据科学家的低配版,初级数据科学家,一般是从事数据科学工作的第一步,数据分析师不需要具备高深的研究背景来发明新算法,但是他们要熟练掌握现有工具来解决问题。
- 数据工程师( data engineers):他们是软件工程师的一种,为数据科学家们提供软件基础设施服务,建设强壮的数据管道来清洗、转移、聚合多种杂乱无章的数据,并存放道特定的数据库中,他们需要管理数据库系统;写复杂的查询语句来抽取数据,维护多台服务器,懂得hadoop等分布式系统。
二、MySQL必学必会
1、一般查询语句
需要掌握的关键词(包含顺序):
SELECT
FROM
JOIN
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT
SELECT
指定需要先择的列,存在多个时用逗号分隔。如果想要查看全部列,则可以使用*号代替。如果需要对查询结果去重,可以添加DISTINCT关键词。另外可对选定的列使用AS关键词进行重命名。
示例代码:
SELECT name, age, occupation,season_contestant FROM bachelorette;
SELECT * FROM bachelorette;
SELECT DISTINCT season_contestant FROM bachelorette;
SELECT name, age, occupation,season_contestant as sc FROM bachelorette;
WHERE
可以用来对查询的项进行过滤。语法格式为:列名+过滤操作符+具体要求。常用的过滤操作符有:
- 比较操作符:=、>、<、>=、<=、!=和<>,其中!=和<>都表示不等于
- 多项匹配:
in,采用括号将多个需要配匹配的放在一起 - 范围限定:
BETWEEN AND,匹配某一个范围,请注意,在不同的数据库中,BETWEEN 操作符会产生不同的结果!在使用前需要先确定包含规则,所以推荐使用比较操作符替换BETWEEN AND- 在某些数据库中,BETWEEN 选取介于两个值之间但不包括两个测试值的字段。
- 在某些数据库中,BETWEEN 选取介于两个值之间且包括两个测试值的字段。
- 在某些数据库中,BETWEEN 选取介于两个值之间且包括第一个测试值但不包括最后一个测试值的字段。
- 模糊匹配:
LIKE,阈值配合使用的时%代表任意个字符,_代表一个字符。 - 空值判断:
IS NULL。注意,对于字符串为空不能应用控制判断,而使用!=’’ - 语法组合关键词
AND、OR、NOT。优先级可用()进行显式声明(括号内的优先)。
示例代码:
SELECT * from Customers WHERE country = 'USA';
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil';
SELECT * from Products WHERE Price BETWEEN 10 AND 20;
SELECT * from Customers WHERE CustomerName LIKE '%to%';
SELECT * FROM student WHERE dept_name IN ('Comp. Sci.', 'Physics', 'Elec. Eng.');
GROUP BY与聚集函数
GROUP BY允许你对指定的一个或多个列进行分组统计。而分组统计中常会用到聚集函数。常用的聚集函数如下:
- COUNT — 对列进行计数。还可以与DISTINCT一起使用,用来统计不同项目的数量。想对所有列进行统计可以使用
count(1)或count(*),两个表示的含义是一致的。 - AVG — 取列的平均值(部分数据库使用的是AVERAGE关键词)
- MIN — 取列的最小值
- MAX — 取列的最大值
- SUM — 取列的和
示例代码:
SELECT Country, COUNT(CustomerID) FROM Customers GROUP BY Country;
HAVING
和WHERE一样也是一种数据过滤的方法,和WHERE条件不同的是它针对的是使用GROUP BY以后的聚合函数的值。
SELECT Country, COUNT(CustomerID) FROM Customers GROUP BY Country HAVING COUNT(CustomerID) > 3;
ORDER BY
指定要进行排序的以恶个或多个列,与ASC(正序)和DESC(倒序)一起使用。默认为ASC。
示例代码:
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil' ORDER BY CustomerName;
SELECT * from Customers WHERE country = 'USA' OR country = 'Brazil' ORDER BY CustomerName DESC;
JOIN
可以将多在表组合成一张表后进行查询。其中JOIN的常用操作主要有以下几类:
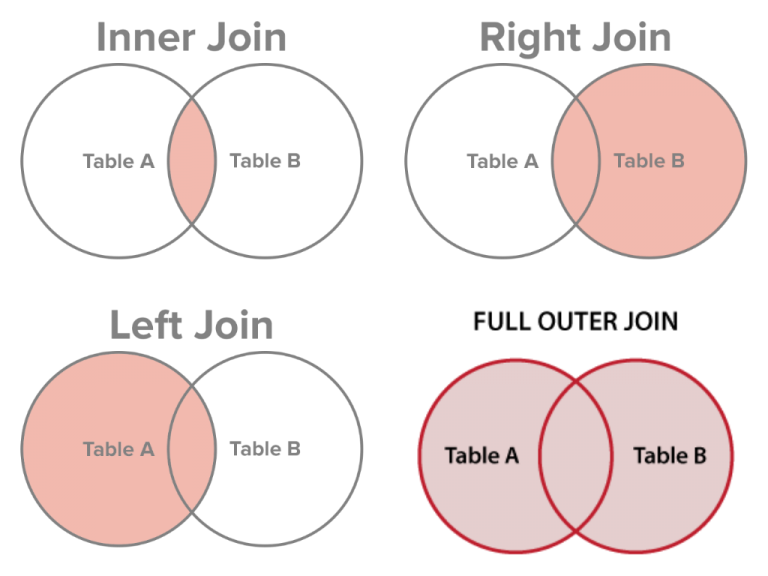
JOIN的时候需要使用ON关键词指定两张表中关联的列。另外可以对表使用AS关键词进行重命名,避免出现两张表相同列名的问题。重命名后取对应列的方法为表名.列名。
示例代码:
SELECT Orders.OrderID, Customers.CustomerName FROM Orders INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
SELECT Customers.CustomerName, Orders.OrderID FROM Customers LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID;
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName FROM Orders RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID;
SELECT Customers.CustomerName, Orders.OrderID FROM Customers FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID;
其他的一些JOIN:
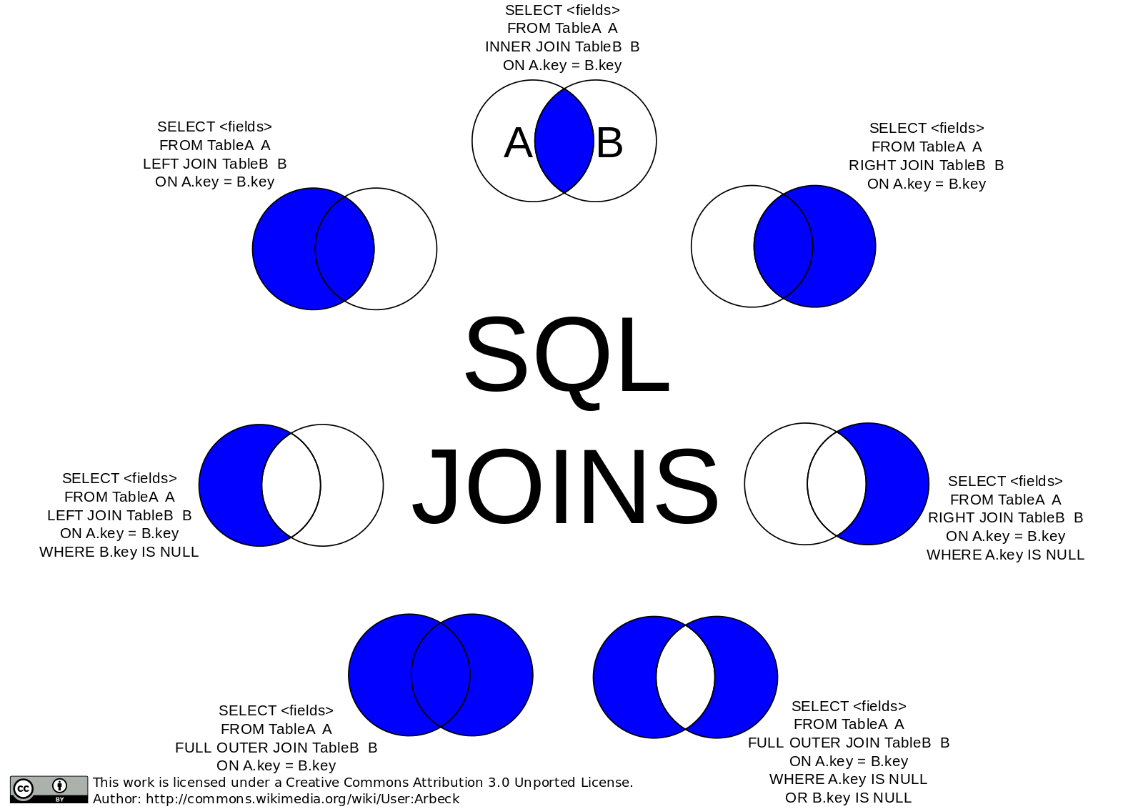
另外还有一种JOIN是Cross Join,代表的是取2张表的笛卡尔积
LIMIT
限制需要返回的数据条目。比如LIMIT 100,则表示只返回100条数据。如果是LIMIT 10,100则表示返回从第10个开始,返回100条记录。
2、子查询
嵌套SELECT语句也叫子查询,一个 SELECT 语句的查询结果能够作为另一个语句的输入值。子查询不但能够出现在WHERE子句中,也能够出现在FROM子句中,作为一个临时表使用,也能够出现在SELECT LIST中,作为一个字段值来返回。
- 子查询必须括在圆括号中。
- 子查询的 SELECT 子句中只能有一个列,除非主查询中有多个列,用于与子查询选中的列相比较。
- 子查询不能使用 ORDER BY,不过主查询可以。在子查询中,GROUP BY 可以起到同 ORDER BY 相同的作用。
- 返回多行数据的子查询只能同多值操作符一起使用,比如 IN 操作符。
- SELECT 列表中不能包含任何对 BLOB、ARRAY、CLOB 或者 NCLOB 类型值的引用。
- 子查询不能直接用在集合函数中。
- BETWEEN 操作符不能同子查询一起使用,但是 BETWEEN 操作符可以用在子查询中。
示例代码:
SELECT ename,deptno,sal FROM emp WHERE deptno=(SELECT deptno FROM dept WHERE loc='NEW YORK');
SELECT ename,job,sal,rownum FROM (SELECT ename,job,sal FROM EMP ORDER BY sal);
3、CTE
CTE(Common Table Expressions)相当于生成一张临时表,与临时表不同的是生存周期的不同。不需要显式的创建或删除,也不需要创建表的权限。更准确的说,CTE更像是一个临时的VIEW。可同时定义多个CTE,但只能用一个with,多个CTE中间用逗号”,”分隔。
代码示例:
WITH t1 AS (
SELECT CountryRegionCode
FROM person.CountryRegion
WHERE Name LIKE 'C%'
)
SELECT *
FROM person.CountryRegion;
WITH t1 AS (
SELECT *
FROM table1
WHERE name LIKE 'abc%'
),
t2 AS (
SELECT *
FROM table2
WHERE id > 20
),
t3 AS (
SELECT *
FROM table3
WHERE price < 100
)
SELECT a.*
FROM t1 a LEFT JOIN t2 ON t1.id = t2.id
INNER JOIN t3 ON t1.id = t3.id;
和临时表有个重要的区别,就是生存周期,
CTE也就是common table expressions是sql标准里的语法,CTE与derived table最大的不同之处是:
- 可以自引用,递归使用(recursive cte
- 在语句级别生成独立的临时表. 多次调用只会执行一次
- 一个cte可以引用另外一个cte
- 一个CTE语句其实和CREATE [TEMPORARY] TABLE类似,但
4、UNION 与 UNION ALL
UNION和UNION ALL关键字都是将两个结果集合并为一个,主要区别:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
代码示例:
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2;
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2;
5、CASE WHEN
CASE WHEN是对列的数据进行判断,然后设定新的值,CASE WHEN通常使用在SELECT语句内,但有时也会用在WHERE语句内
示例代码:
SELECT
STUDENT_NAME,
(CASE WHEN score < 60 THEN '不及格'
WHEN score >= 60 AND score < 80 THEN '及格'
WHEN score >= 80 THEN '优秀'
ELSE '异常' END) AS REMARK
FROM
TABLE
6、常用函数
上面讲过聚集函数,这里主要介绍的是除聚集函数以外的其他函数。
常用数值处理函数
- ROUND: 确定数字要保存的位数,遵循四舍五入
- ABS: 取绝对值
- MOD: 取除法余数
- SIGN: 正数返回1,负数返回-1,0 返回0
- SQRT: 开方
- FLOOR/CEIL: 向下取整或向上取整
- POWER: 指数
常用字符串处理函数
- TRIM: 删除字符串前后的空格,另外还有RTRIM和LTRIM,可以指定删除左侧还是右侧空格
- SUBSTR: 取得字符串中指定起始位置和长度的字符串默认是从起始位置到结束的子串。
- LOWER/UPPER: 转换大小写
- CONCAT: 字符串拼接
- CONTAINS: 寻找是否包含某个字符
- REPLACE:用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式。
- LEN:返回字符串长度
日期时间处理函数
- NOW(): 返回当前时间
- CURRENT_DATE(): 返回 当前日期
- DATE_ADD/DATE_SUB: 日期的加减
- MONTH/YEAR/DAY/WEEKDAY/QUARTER/WEEK: 返回日期中的年月日周几(看数据库设置,通常0代表周一、1代表周二)
- TO_DATE:将字符串时间转化为日期格式
- DATEDIFF:计算两个日期间的天数
DATE_FORMAT(date, format)函数
DATE_FORMAT(date, format)函数可根据format字符串格式化日期或日期和时间值date,返回结果串。 也可用DATE_FORMAT()来格式化DATE 或DATETIME 值,以便得到所希望的格式。根据format字符串格式化date值:
- %S, %s 两位数字形式的秒( 00,01, . . ., 59)
- %i 两位数字形式的分( 00,01, . . ., 59)
- %H 两位数字形式的小时,24 小时(00,01, . . ., 23)
- %h, %I 两位数字形式的小时,12 小时(01,02, . . ., 12)
- %k 数字形式的小时,24 小时(0,1, . . ., 23)
- %l 数字形式的小时,12 小时(1, 2, . . ., 12)
- %T 24 小时的时间形式(hh : mm : s s)
- %r 12 小时的时间形式(hhss AM 或hhss PM)
- %p AM 或P M
- %W 一周中每一天的名称( Sunday, Monday, . . ., Saturday)
- %a 一周中每一天名称的缩写( Sun, Mon, . . ., Sat)
- %d 两位数字表示月中的天数( 00, 01, . . ., 31)
- %e 数字形式表示月中的天数( 1, 2, . . ., 31)
- %D 英文后缀表示月中的天数( 1st, 2nd, 3rd, . . .)
- %w 以数字形式表示周中的天数( 0 = Sunday, 1=Monday, . . ., 6=Saturday)
- %j 以三位数字表示年中的天数( 001, 002, . . ., 366)
- % U 周(0, 1, 52),其中Sunday 为周中的第一天
- %u 周(0, 1, 52),其中Monday 为周中的第一天
- %M 月名(January, February, . . ., December)
- %b 缩写的月名( January, February, . . ., December)
- %m 两位数字表示的月份( 01, 02, . . ., 12)
- %c 数字表示的月份( 1, 2, . . ., 12)
- %Y 四位数字表示的年份
- %y 两位数字表示的年份
- %% 直接值“%”
NULL相关函数
- COALESCE()对NULL值进行替换
- ISNULL:判断是否为空
- ISEXIST:判断是否存在
7、窗口函数
窗口函数针对指定的行集合(分组)执行聚合运算。不同之处在于,窗口函数能够为每个分组返回多个值,而聚合函数只能返回单一值。聚合运算的对象其实是一组行记录,我们称之为“窗口”(因此才有了术语“窗口函数”)
窗口函数
- FIRST_VALUE:取出分组内排序后,截止到当前行,第一个值
- LAST_VALUE:取出分组内排序后,截止到当前行,最后一个值
- LEAD(col, n, DEFAULT):用于统计窗口内往下第n行的值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时,取默认值)
- LAG(col,n,DEFAULT):与lead相反,用于统计窗口内往下第n个值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1)
分析函数
- ROW_NUMBER()从1开始,按照顺序,生成分组内记录的序列,比如,按照pv降序排列,生成分组内每天的pv名次,ROW_NUMBER()的应用 场景非常多,再比如,获取分组内排序第一的记录,获取一个session中的第一条refer等
- RANK()生成数据项在分组中的排名,排名相等会在名次中留下空位
- DENSE_RANK()生成数据项在分组中的排名,排名相等会在名次中不会留下空位
- CUME_DIST()小于等于当前值的行数除以分组内总行数。比如,统计小于等于当前薪水的人数所占总人数的比例
- PERCENT_RANK()分组内当前行的RANK值/分组内总行数
- NTILE(n)用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。
OVER从句
- 使用标准的聚合函数COUNT,SUM,MIN,MAX,AVG
- 使用PARTITION BY语句,使用一个或者多个原始数据类型的列
- 使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
- 使用窗口规范
8、其他操作
1、查看当前有哪些数据库
SHOW DATABASES;
2、创建一个数据库
CREATE DATABASE <database_name>;
3、使用一个数据库
USE <database_name>;
4、数据.sql文件中导入指令
SOURCE <path_of_.sql_file>;
5、删除一个数据库
DROP DATABASE <database_name>;
6、查看选定的库下有哪些表
SHOW TABLES;
7、创建一张临时表
CREATE TABLE <table_name1> (
<col_name1> <col_type1>,
<col_name2> <col_type2>,
<col_name3> <col_type3>
PRIMARY KEY (<col_name1>),
FOREIGN KEY (<col_name2>) REFERENCES <table_name2>(<col_name2>)
);
8、显示表字符描述
DESCRIBE <table_name>;
9、插入数据
INSERT INTO <table_name> (<col_name1>, <col_name2>, <col_name3>, …)
VALUES (<value1>, <value2>, <value3>, …);
10、更新数据
UPDATE <table_name>
SET <col_name1> = <value1>, <col_name2> = <value2>, ...
WHERE <condition>;
11、删除表中内容,可以条件WHERE条件来限定要删除的内容
DELETE FROM <table_name> WHERE <condition>;
12、清空表中所有数据
TRUNCATE <table_name>;
13、删除数据库表
DROP TABLE <table_name>;
14、创建视图
数据库中的数据都是存储在表中的,而视图只是一个或多个表依照某个条件组合而成的结果集,一般来说你可以用update,insert,delete等sql语句修改表中的数据,而对视图只能进行select操作。
- 表是物理存在的
- 视图是虚拟的内存表
CREATE VIEW <view_name> AS
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <condition>;
15、删除视图
DROP VIEW <view_name>;
数据分析应该掌握的知识及SQL技能的更多相关文章
- Python 数据分析:让你像写 Sql 语句一样,使用 Pandas 做数据分析
Python 数据分析:让你像写 Sql 语句一样,使用 Pandas 做数据分析 一.加载数据 import pandas as pd import numpy as np url = ('http ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- sql server 数据分析优化实战(一)——SQL语句优化
前言 在我们进行数据分析的时候,首要的目标是根据业务逻辑,通过编写SQL代码得到我们想要的结果,这是毋庸置疑的.一般情况下,由于我们分析的数据量比较少,体会不出SQL语句各种写法的性能优劣,对SQL代 ...
- SQL知识以及SQL语句简单实践
综述 大家都知道SQL是结构化查询语言,是关系数据库的标准语言,是一个综合的,功能极强的同时又简洁易学的,它集级数据查询(Data Quest),数据操纵(Data Manipulation),数据定 ...
- oracle 基础知识(九)----SQL解析
一,解析过程 二,硬解析,软解析,软软解析 01,硬解析 将SQL语句通过监听器发送到Oracle时, 会触发一个Server process生成,来对该客户进程服务.Server process得到 ...
- pl/sql基础知识—pl/sql块介绍
n 介绍 块(block)是pl/sql的基本成型单元,编写pl/sql程序实际上就是编写pl/sql块.要完成相对简单的应用功能,可能只需要编写一个pl/sql块:但是如果要想实现复杂的功能,可能 ...
- 小知识:SQL Monitor Report的使用
在上一篇 优化利器In-Memory开启和效果 中,提到的两个SQL对比,使用的是传统的dbms_xplan.display_cursor方式来查看执行计划,好处是文本输出的通用性强,基本信息也都有. ...
- 【基础知识】Sql和Ado.Net第12天
一. 主键(PrimaryKey) 1. 主键是数据行的唯一标识.不能重复,不可为空,主键建议选择一般不会修改的列! 2. 主键的作用:保证表中的每条数据的唯一性. 3. 主键的分类: a) 逻辑主键 ...
- 数据分析常用的python工具和SQL语句
select symbol, "price.*" from stocks :使用正则表达式来指定列查询 select count(*), avg(salary) from empl ...
- 【SQL知识】SQL中的join操作总结:内连接、外连接(左右全)
一.含义 基于表之间的共同字段,把来自两个或多个表的行结合起来 二.分类 内连接:join / inner join 外连接:left join / right join / full outer j ...
随机推荐
- 一篇文章让你读懂Java异常栈信息
一. 基本的异常打印 public class Test { public static void main(String[] args) { fun1();//第4行 } public static ...
- nginx学习记录【二】nginx跟.net core结合,实现一个域名访问多个.net core应用
1.实现转发 打开conf下的nginx.conf文件,如下图: 2.添加.net core网站的转发 按下面的进行修改,修改完后,就把localhost的80转发到了https://localhos ...
- FreeSWITCH使用soundtouch进行变声
操作系统 :CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 FreeSWITCH里面有个mod_soundtouch模块,支持通话实时变声,今天整理下CentOS 7环境下 ...
- exception EXC_RESOURCE - WAKEUPS 分析(二)
一.问题: 直播助手在使用ReplayKit2 Extension的过程中,ReplayKit2的Upload进程工作在后台模式,苹果对处于后台的进程进行了内存和CPU资源的限制. 对于内存: 每种E ...
- Redisson 限流器源码分析
Redisson 限流器源码分析 对上篇文章网友评论给出问题进行解答:redis 的key 是否会过期 可以先阅读上篇文章: redis + AOP + 自定义注解实现接口限流 - 古渡蓝按 - 博客 ...
- LeetCode 449. Serialize and Deserialize BST 序列化和反序列化二叉搜索树 (Java)
题目: Serialization is the process of converting a data structure or object into a sequence of bits so ...
- 编程语言界的丐帮 C#.NET FRAMEWORK 4.6 EF 连接MYSQL
1.nuget 引用 EntityFramework .和 MySql.Data.EntityFramework. EntityFramework 版本:6.4.4,MySql.Data.Entit ...
- flutter 尝试创建第一个页面(三)
新建目录 assets 存放图片 在pubspec..yaml 中添加 flutter: # The following line ensures that the Material Icons f ...
- python 文件查找及截取字符串 (替换,分割) demo
#"F:\\test.txt" ''' # 例1:字符串截取 str = '12345678' print str[0:1] # 例2:字符串替换 str = 'akakak' s ...
- kafka事务流程
流程 kafka事务使用的5个API // 1. 初始化事务 void initTransactions(); // 2. 开启事务 void beginTransaction() throws Pr ...