[转帖]Prometheus监控系统存储容量优化攻略,让你的数据安心保存!
云原生监控领域不可撼动,Prometheus 是不是就没缺点?显然不是。
一个软件如果什么问题都想解决,就会导致什么问题都解决不好。所以Prometheus 也存在不足,广受诟病的问题就是 单机存储不好扩展。
1 真的需要扩展容量吗?
大部分场景其实不需要扩展,因为一般的数据量压根达不到 Prometheus 容量上限。很多中小型公司使用单机版本的 Prometheus 就足够了,这个时候不要想着去扩展,易过度设计。
Prometheus单机容量上限多少?每秒接收 80 万个数据点算较健康的上限,一开始也无需用一台配置特别高的机器,随数据量增长,再升级硬件配置。如想要硬件方便升配,就要借助虚拟机或容器,同时需要使用分布式块存储。
每秒接收 80 万个数据点
每台机器每个周期大概采集 200 个系统级指标,如CPU、内存、磁盘等相关的指标。假设采集频率是 10 秒,平均每秒上报 20 个数据点,可以支持同时监控的机器量是 4 万台。
很大的容量了。若使用 node-exporter,指标数量800左右,那也能支持 1 万台机器的监控。
这只计算了机器监控数据,若还要监控各类中间件,就得再估算。有些中间件会吐出较多指标,有些指标用处不大,可丢掉(drop)。
若单个 Prometheus 真扛不住,也可拆成多个 Prometheus,根据业务或地域拆都可。
2 Prometheus 联邦机制
Prometheus 内置支持的集群方式,Prometheus数据的级联抓取。如某公司有8套Kubernetes,每套Kubernetes集群都部署了一个Prometheus,这8个Prometheus就形成了8个数据孤岛,没法在一个地方看到8个Prometheus的数据。
用Grafana或Nightingale把这8个Prometheus作为数据源接入,就能在Web通过切换数据源查看不同数据,但本质还是分别查看,没法做多个Prometheus数据的联合运算。
而联邦机制就解决这问题,把不同的Prometheus数据聚拢到一个中心Prometheus:
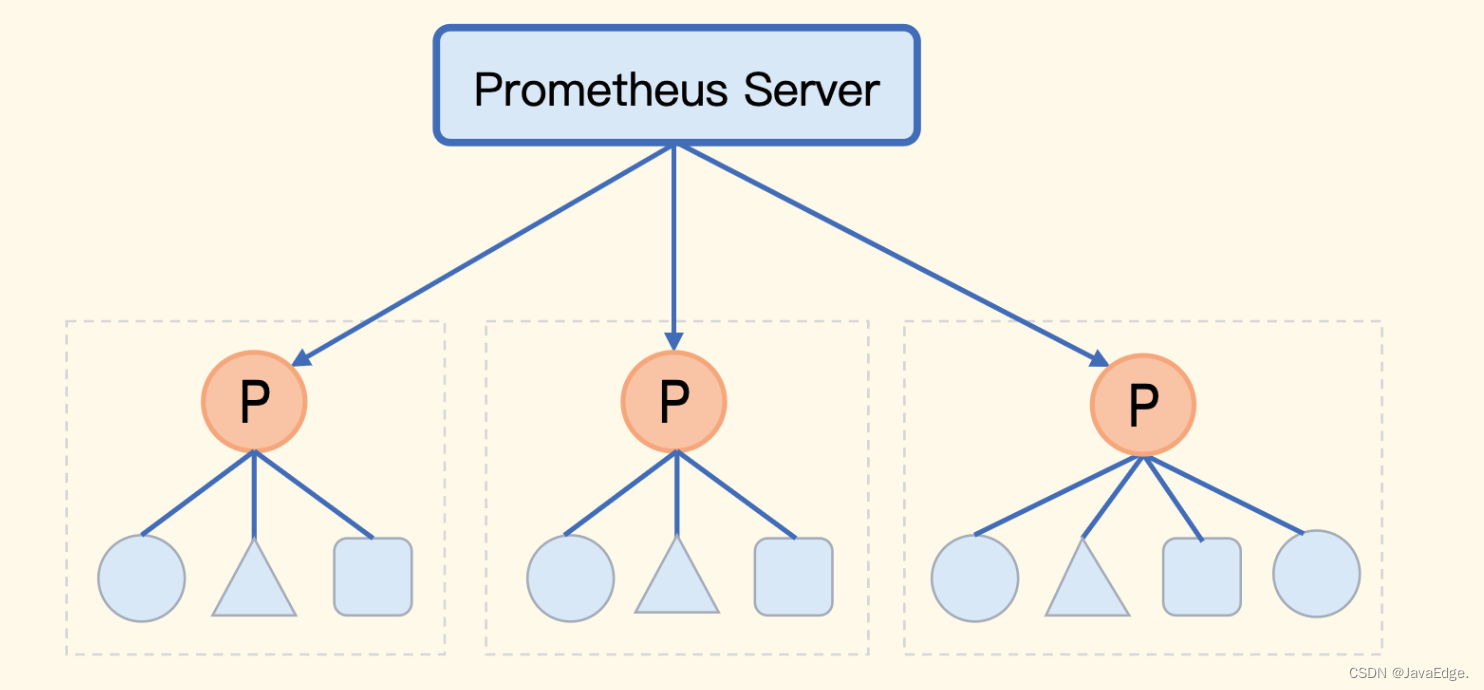
但中心Prometheus仍是瓶颈。所以联邦机制中,中心端的Prometheus去抓取边缘Prometheus数据时,不应该把所有数据都抓取到中心,而是 只抓取那些需要做聚合计算或其他团队也关注的指标,大部分数据还是下沉在各个边缘Prometheus内部消化。
怎么只抓取特定的指标到中心端?
通过 match[] 参数,指定过滤条件,如下就是中心 Prometheus 的抓取规则:
scrape_configs:
- job_name: 'federate'
scrape_interval: 30s
# 在标签重复时,以源数据的标签为准
honor_labels: true
# 边缘 Prometheus 会在 `/federate` 接口暴露监控数据,所以设置
metrics_path: '/federate'
params:
'match[]':
# 通过正则匹配过滤出所有 `aggr:` 打头的指标
# 这类指标都是通过 Recoding Rules 聚合出来的关键指标
- '{__name__=~"aggr:.*"}'
static_configs:
- targets:
- '10.1.2.3:9090'
- '10.1.2.4:9090'
联邦机制落地的核心要求: 边缘 Prometheus 基本消化了绝大部分指标数据,比如告警、看图等,都在边缘的Prometheus搞定。只有少量数据,如需聚合计算或其他团队也关注的指标,被拉到中心,就不会触达中心端 Prometheus 容量上限。这就要求公司在使用 Prometheus 之前先做好规划、规范。落地的确有点难,更推荐如下的远程存储方案。
3 远程存储方案
Prometheus默认收集到监控数据后是存储本地,在本地查询计算。由于单机容量有限,对海量数据场景,要有其他解决方案。最直观想法:本地搞不定,那就在远端做个集群,分治处理。
Prometheus本身不提供集群存储能力,可复用其他时序库方案。时序库很多,挨个对接费劲,于是 Prometheus建立统一Remote Read、Remote Write接口协议,只要满足这个接口协议的时序库都可对接进来,作为 Prometheus remote storage 使用。
目前国内使用最广泛的远程存储主要是 VictoriaMetrics 和 Thanos。
3.1 VictoriaMetrics
VM 虽然可以作为 Prometheus 的远程存储,但志不在此。VM希望成为更好的 Prometheus,所以不只时序库,还有抓取器、告警等各个组件,体系完备,不过现在国内基本只是把它当做时序库用。
VM时序库核心组件
- vmstorage:存储时序数据
- vminsert:接收时序数据并写入到后端的vmstorage,Prometheus使用 Remote Write 对接的就是 vminsert 的地址
- vmselect:查询时序数据,没实现 Remote Read接口,而是实现 Prometheus 的 Querier 接口。因为VM 觉得 Remote Read 设计“挫”,性能不好,不如直接实现 Querier 接口。这样Grafana等前端应用直接和vmselect对接,而不用在中间加层Prometheus。
VM架构

n9e-webapi、n9e-server 是 Nightingale 的两个模块,都可看做 VM 的上层应用。
n9e-webapi 通过 vmselect 查询时序数据,vmselect 是无状态模块,可以水平扩展,通常部署多个实例,前面架设负载均衡,所以 n9e-webapi 通常是对接 vmselect 的负载均衡。n9e-server 也有一些查询VM的需求,先不用关注,重点关注 Remote Write 那条线,n9e-server 通过 Remote Write 协议,把数据转发给 vminsert 的负载均衡,vminsert 也是无状态的,可以水平扩展。
vmstorage存储模块,可部署多个以组成集群,只要把所有 vmstorage 地址告诉 vmselect 和 vminsert,整个集群就跑起来了。
数据通过 vminsert 后,如何分片?
vmselect 和 vminsert 之间无关系,vmselect查询某指标数据时,怎么知道数据位于哪个 vmstorage?
VM采用merge read方案,一个查询请求发给 vmselect 之后,vmselect 会向所有 vmstorage 发起查询请求,然后把结果合并在一起,返给前端。所以,vmselect 不关心数据位于哪个 vmstorage。此时 vminsert 用什么分片算法都无所谓了,数据写到哪个 vmstorage 都行,反正最后都会 merge read。
这设计有问题吗?显然有,vmstorage 集群不能太大。若有几千个节点,随便一个查询过来,vmselect 都会向所有 vmstorage 发起查询,任何一个节点慢了都会拖慢整体速度,让人无法接受。一般一个 vmstorage 集群,有一二十个节点还是比较健康的,这容量就已经很大了,能满足大部分公司需求,所以这不是大问题。
推荐选型远程存储时使用 VictoriaMetrics,架构简单,更有掌控力。像M3虽然容量比VM大得多,但是架构复杂。
3.2 Thanos
和VM不同,Thanos完全拥抱Prometheus,对Prometheus做增强,核心特点:使用 对象存储 做海量时序存储。
架构
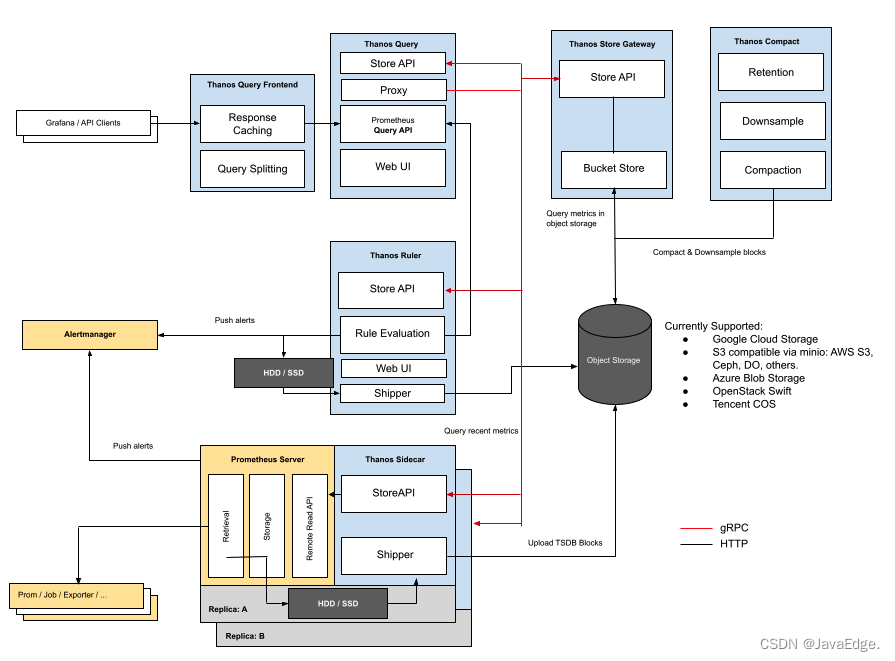
黄色:Prometheus自身
蓝色:Thanos
黑色:存储
每个 Prometheus 都要伴生一个 Thanos Sidecar 组件:
- 响应Thanos Query的查询请求
- 把Prometheus产生的块数据上传到对象存储
Thanos Sidecar 调用 Prometheus 的接口查询数据,暴露为 StoreAPI,Thanos Store Gateway 调用对象存储的接口查询数据,也暴露为 StoreAPI。Thanos Query就可以从这两个地方查询数据了,相当于近期数据从Prometheus获取,比较久远的数据从对象存储获取。
虽然对象存储比较廉价,但这个架构看起来还是过于复杂了,没有 VM 看起来干净。另外这个架构是和 Prometheus 强绑定的,没法用作单独的时序存储,比较遗憾。不过好在 Thanos 还有另一种方案,不用 Sidecar,使用 Receive 模块,来接收 Remote Write 协议的数据,写入本地,同时上传对象存储,你看一下这个架构。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PUWxwLqa-1682922349277)(images/624038/25a79b6dfeeaf07e41810f283057d128.png)]
从存储角度来看,这个架构和 Prometheus 就没有那么强的绑定关系了,可以单独用作时序库。关键点还是对象存储,虽然对象存储是海量、廉价的,但是延迟较高,而且一个请求拆成两部分,一部分查本地,一部分查对象存储,也没有那么可靠。
相比日志数据,指标数据的体量较小,一般存储3个月即可,对象存储优势就不大了。我来选型,VictoriaMetrics 和 Thanos 之间,我选前者。
4 Prometheus自身搭建集群
远程存储方案核心就是 Remote Read/Write,Prometheus自身也可被别的 Prometheus 当做 Remote storage,只要开启 --enable-feature=remote-write-receiver 。
架构图
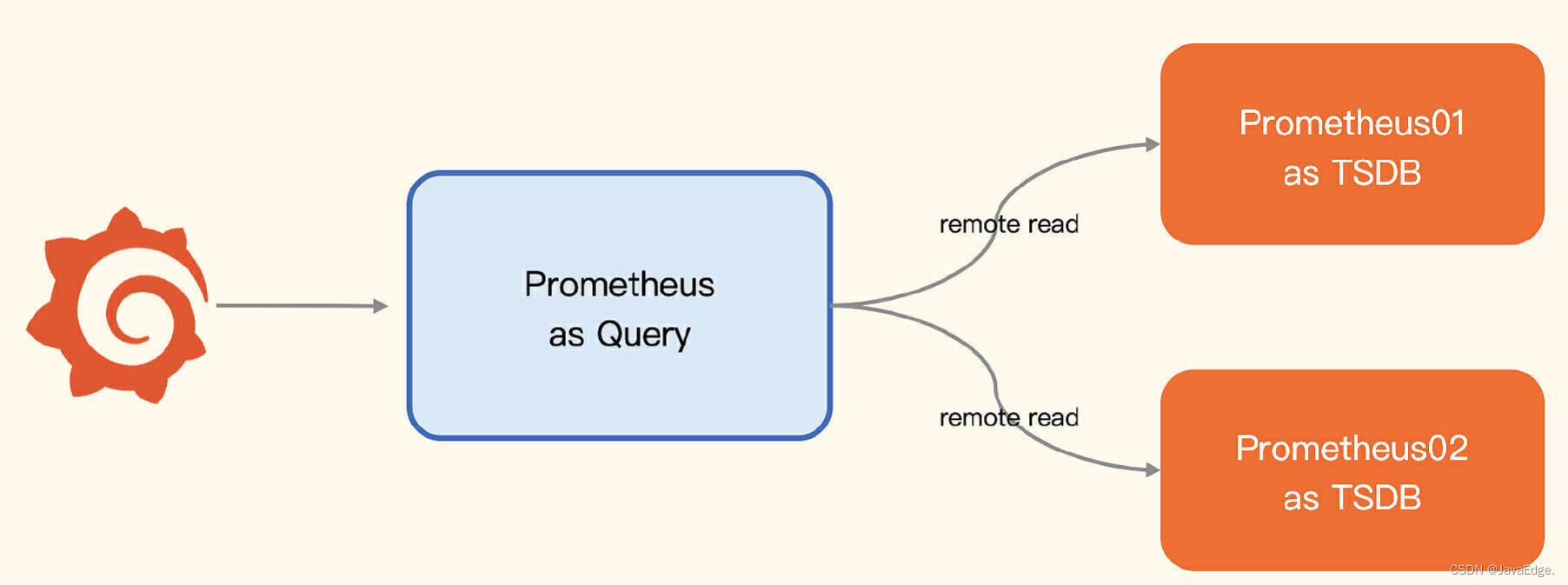
三个 Prometheus 进程:
两个作存储
一个作查询器
通过 Remote Read 读取后端多个 Prometheus 的数据,通过几行 remote_read 配置就能实现
remote_read:
- url: "http://prometheus01:9090/api/v1/read"
read_recent: true
- url: "http://prometheus02:9090/api/v1/read"
read_recent: true
Prometheus 的 remote_read 也是 merge read,跟 vmselect 逻辑类似。不过VM集群是有副本机制的,使用Prometheus来做集群,不太好做副本。当然,可以粗暴地为每个分片数据部署多份采集器和PromTSDB,也基本可以解决高可用的问题。
在实际生产环境中,如果所有数据都是通过拉的方式来收集,这种架构也是可以尝试的,不过我看到大部分企业都是推拉结合,甚至推是主流,Remote Write 到一个统一的时序库集群,是一个更加顺畅的方案。
5 总结
Prometheus生态常见的存储扩展问题,3种集群方案:
- Prometheus联邦集群:按照业务或者地域,拆成多个边缘Prometheus,然后在中心搭建一个Prometheus,把一些重要的多团队关注的指标或需要二次计算的指标拉到中心。
- 远程存储方案:通过 Remote Read/Write 协议,Prometheus 可以和第三方存储对接,把存储的难题抛给了第三方来解决,常用方案是 M3DB、VictoriaMetrics、Thanos。我最推荐的是 VictoriaMetrics,架构简单,更可控一些。
- Prometheus自身搭建集群:也是利用了 Remote Read/Write 机制,只是把存储换成了多个 Prometheus,对于全部采用拉模型抓取数据的公司,是可以考虑的方案。
这三种很好解决Prometheus存储问题,根据实际情况选用。不要做过度设计,数据量不大就无需搭建时序集群。


微信公众号

关注后台回复“面试”,领取海量学习资源
[转帖]Prometheus监控系统存储容量优化攻略,让你的数据安心保存!的更多相关文章
- Nagios 监控系统架设全攻略
Nagios 全名为(Nagios Ain’t Goona Insist on Saintood),最初项目名字是 NetSaint.它是一款免费的开源 IT 基础设施监控系统,其功能强大,灵活性强, ...
- Prometheus监控系统之入门篇(一)续
在上篇Prometheus监控系统之入门篇(一)中我们讲解了Prometheus的基本架构和工作流程, 并从0到1搭建了Prometheus服务,pushgateway以及告警系统. 本篇我们主要介绍 ...
- 容器编排系统K8s之Prometheus监控系统+Grafana部署
前文我们聊到了k8s的apiservice资源结合自定义apiserver扩展原生apiserver功能的相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/ ...
- Oracle12c 性能优化攻略:攻略目录表
注:本文来源于 [美] Sam Alapati , Darl Kuhn , Bill Padfield 著 朱浩波 翻译 <Oracle Database 12C 性能优化攻略> ...
- Oracle12c 性能优化攻略:攻略1-3: 匹配表类型与业务需求
注:目录表 <Oracle12c 性能优化攻略:攻略目录表> 问题描述 你刚开始使用oracle数据库,并且学习了一些关于可用的各种表类型的知识.例如:可以在堆组织表.索引组织表等之间支出 ...
- Oracle12c 性能优化攻略:攻略1-2:创建具有最优性能的表空间
问题描述: 1:表空间是存储数据库对象(例如索引 .表)的逻辑容器. 2:在创建数据库对象不为其指定存储属性,则相应的表和索引会自动继承表空间的存储特性. 故:若需要好的索引.表的性 ...
- prometheus监控系统
关于Prometheus Prometheus是一套开源的监控系统,它将所有信息都存储为时间序列数据:因此实现一种Profiling监控方式,实时分析系统运行的状态.执行时间.调用次数等,以找到系统的 ...
- Prometheus监控系统之入门篇(一)
1. 简介 Prometheus: (简称Prom)是由SoundCloud开发的开源监控报警系统.是大名鼎鼎的CNCF云原生基金会下的第二大开源项目.具有如下特点: 使用Go语言开发 内置时序数据库 ...
- Oracle12c 性能优化攻略:攻略1-1:创建具有最优性能的数据库
一:章节前言 本章着眼于影响表中数据存储性能的数据库特性. 表的性能部分取决于在创建之前所应用的数据库特性.例如:在最初创建数据库时采用的物理存储特性以及相关的表空间都会在后来影响表的性能.类似地,表 ...
- Grafana+Zabbix+Prometheus 监控系统
环境说明 软件 版本 操作系统 IP地址 Grafana 5.4.3-1 Centos7.5 192.168.18.231 Prometheus 2.6.1 Centos7.5 192.168.18. ...
随机推荐
- 开发篇1:使用原生api和Langchain调用大模型
对大模型的调用通常有以下几种方式:方式一.大模型厂商都会定义http风格的请求接口,在代码中可以直接发起http请求调用:方式二.在开发环境中使用大模型厂商提供的api:方式三.使用开发框架Langc ...
- 增长黑客招聘条件 JD
HubSpot招聘T型营销人员加入我们的营销团队.担任此职务后,您将成为第二个致力于HubSpot正在构建的新产品的营销人员.由于其高度机密,我们无法告诉您该产品是什么. 我们正在寻找符合以下条件的人 ...
- C#/VB.NET 添加、删除PPT幻灯片中的数字签名
本文介绍如何通过C#及VB.NET代码来添加数字签名到PPT幻灯片文档,以及如何将文档中的数字签名删除. 辅助工具: Spire.Presentation.dll (dll版本为5.11.2) 注意: ...
- 不同数据库模式下DATE类型的行为解析
摘要:本文章主要介绍了GaussDB(DWS)数据类型中的DATE类型在不同数据库模式下且在不同应用场景下的行为表现及对比. 本文分享自华为云社区<GaussDB(DWS)数据类型之DATE类型 ...
- 10年经验总结,华为fellow教你如何成为一名优秀的架构师?
摘要:华为云首席架构师分享成为架构师必备的一些特质和能力. 本文分享自华为云社区<10年经验总结,华为fellow教你如何成为一名优秀的架构师?>,作者: 技术火炬手 . 在<云享人 ...
- 抖音APP如何实现用户生命周期提升
> 更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 近日,在火山引擎数智平台在北京举办的"超话数据:企业产品优化分享"的活动上,抖音策略 ...
- Codeforces Round 913 (Div. 3)
CF1907总结 A. Rook 题面翻译 给出车在国际象棋棋盘中的位置,输出其可到达的坐标(不必在意顺序). 车可以横着或竖着走任意格数. 分析 题意明了,输出车所在行和列所有格子的序号(除车所在位 ...
- 【Vue】表单数据双向绑定 vue生命周期 fetch和axios发送请求 Vue全局组件
目录 昨日回顾 表单数据双向绑定(重要) checkbox单选 --- 布尔值 checkbox多选 --- 数组 radio单选 --- 字符串 给后端发送数据 购物车案例 全选按钮 商品添加删除 ...
- AtCoder Beginner Contest 218 A~D
比赛链接:Here A - Weather Forecas 水题,判断 \(s[n - 1] = o\) 的话输出 YES B - qwerty 题意:给出 \((1,2,...,26)\) 的某个全 ...
- spring中这些编程技巧,真的让我爱不释手
前言 最近越来越多的读者认可我的文章,还是挺让人高兴的.有些读者希望我多分享spring方面的知识点,能够在实际工作中派的上用场.我对spring的源码有过一定的研究,结合我这几年实际的工作经验,把s ...