三、Doris数据模型
DorisDB根据摄入数据和实际存储数据之间的映射关系, 将数据表的明细表, 聚合表和更新表, 分别对应有明细模型, 聚合模型和更新模型。
- Aggregate (聚合模型) : 将表中的列分为了Key和Value两种,数据会根据维度列进行分组,并对指标列进行聚合。
- Unique (唯一主键模型):
- Duplicate (明细模型)
其它提升效率的方式:
- 构建Rollup
- 前缀索引与 ROLLUP
Aggregate(聚合模型)
一个正常的模型它肯定会把明细的数据存储在一个数据库中,也就是存在Doris中。但是因为Doris它最早是给凤巢的一个广告报表做的,广告报表有一个很大的特点,就是它只关心统计分析的结果,而不太关心明细的数据,所以Doris最早一代的数据模型,是一个聚合的模型。
聚合模型的特点就是将表中的列分为了Key和Value两种。 Key 就是数据的维度列,比如时间,地区等等。 Value 则是数据的指标列,比如点击量,花费等。每个指标列还会有自己的聚合函数,包括sum、min、max和bitmap_union 等。数据会根据维度列进行分组,并对指标列进行聚合。如下图
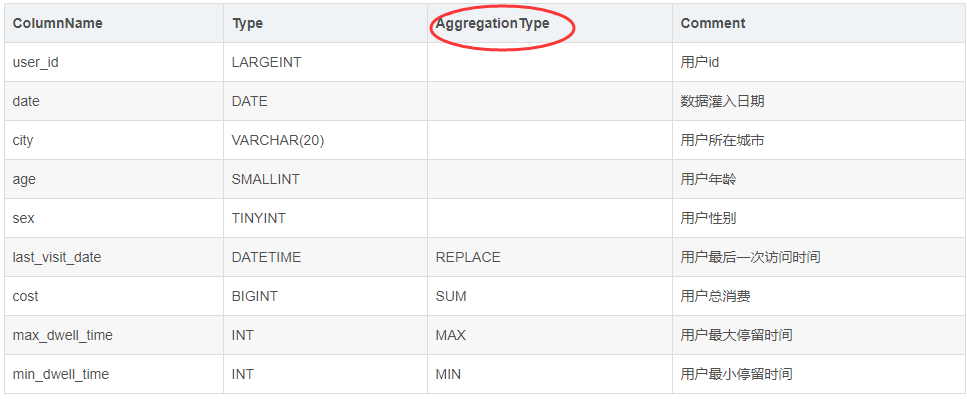
表中的列按照是否设置了 AggregationType,分为 Key (维度列) 和 Value(指标列)。没有设置 AggregationType 的,如 user_id、date、age ... 等称为 Key,而设置了 AggregationType 的称为 Value。
如果转换成建表语句则如下(省略建表语句中的 Partition 和 Distribution 信息)
1 CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
2 (
3 `user_id` LARGEINT NOT NULL COMMENT "用户id",
4 `date` DATE NOT NULL COMMENT "数据灌入日期时间",
5 `city` VARCHAR(20) COMMENT "用户所在城市",
6 `age` SMALLINT COMMENT "用户年龄",
7 `sex` TINYINT COMMENT "用户性别",
8 `last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
9 `cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
10 `max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
11 `min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
12 )
13 AGGREGATE KEY(`user_id`, `date`, `city`, `age`, `sex`)
14 ... /* 省略 Partition 和 Distribution 信息 */
聚合模型的数据在Doris的3种机制下都会发生聚和:
- 导入
- Compaction(合并)
- 查询
数据导入:
- 原始数据在导入过程中,会根据表结构中的Key进行分组,相同Key的Value会根据表中定义的Aggregation Function进行聚合。如下图
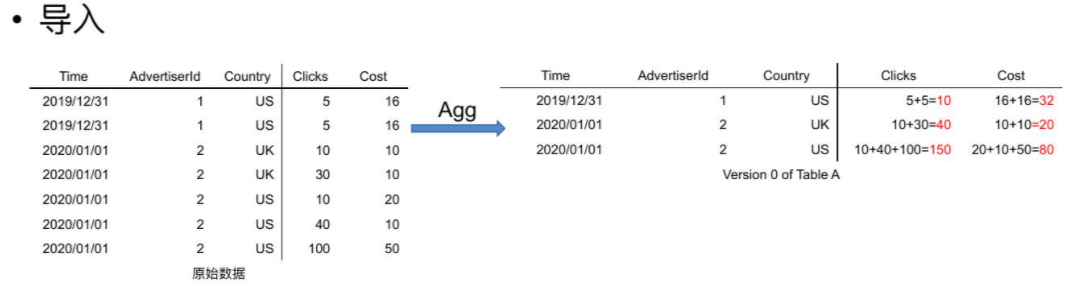
- 由于Doris采用的是MVCC(Multi-version Cocurrent Control,多版本并发控制)机制进行的并发控制,所以每一次新的导入都是一个新的版本。我们把这种版本称为 Singleton。
Compaction:
- 不断的导入新的数据后,尽管同一批次的数据在导入过程中已经发生了聚合,但不同版本之间的数据依旧存在维度列相同但是指标列并没有被聚合的情况。这时候就需要通过Compaction机制进行二次聚合。
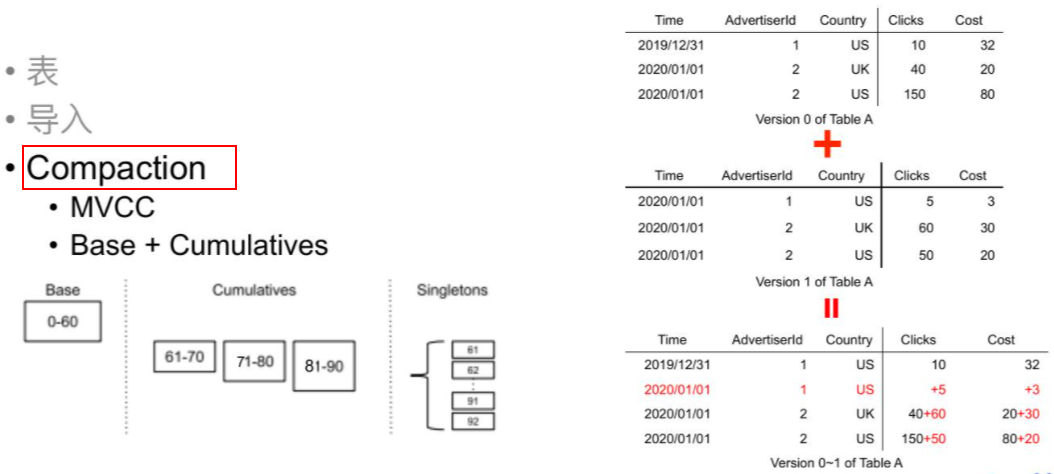
Compaction 的意思其实就是将不同版本的数据进行合并。它 分为两个阶段:
- 第一个阶段是: 当Singleton的数据版本个数到达Doris设置的阈值时,就会触发 Cumulative 级别的Compaction。 这个级别的Compaction会将一个区间段内的版本数据根据定义好的聚合函数进行再聚合。
- 例如: Cumulative Compaction 会将61~70的这10个Singleton版本的数据合并成一个版本。这个版本的范围就是61~70。
- 经过Cumulative Compaction后的数据已经合并多个区间内的版本,但并没有最终合并成一个版本。这时候就需要 Base Compaction 来对已经完成Cumulative Compaction的版本做一个最终的合并。
- 例如: 上图中的Base Compaction已经完成后第0个版本到第60个版本的聚合。那么下一次的Base Compaction 就是把61~70这个已经完成Cumulative合并的版本和 0~60版本再进行一个Base Compaction,最终生成一个0~70的版本。
查询:
- 由于Compaction是异步后台执行的,在用户查询之前数据还并未合并在同一个版本中,而是存在于多个版本中的。所以用户查询数据的时候,为了保证查询结果的正确性,Doris会把从0到当前最新版本的数据都读出来然后再做一次聚合,最后将结果返回给用户。

例如: 有一个订单表,以订单id为维度列,订单的状态为指标列,且聚合函数为Replace,也就是当订单id相同时,新订单状态覆盖旧的订单状态。
这时候版本0~30中订单1的状态可能是待付款,版本31~35中订单1的状态是已收货,最后一个版本36中订单1的状态是已完成。 那么用户在查询每个订单状态的时候,不同版本之间的数据就需要进行一个Replace, 取最后一个版本中的已完成状态作为查询的结果。
Uniq 模型(唯一主键)
在某些多维分析场景下,用户更关注的是如何保证 Key 的唯一性,即如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。举例说明:

这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username),建表语法如下:
1 CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
2 (
3 `user_id` LARGEINT NOT NULL COMMENT "用户id",
4 `username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
5 `city` VARCHAR(20) COMMENT "用户所在城市",
6 `age` SMALLINT COMMENT "用户年龄",
7 `sex` TINYINT COMMENT "用户性别",
8 `phone` LARGEINT COMMENT "用户电话",
9 `address` VARCHAR(500) COMMENT "用户地址",
10 `register_time` DATETIME COMMENT "用户注册时间"
11 )
12 UNIQUE KEY(`user_id`, `user_name`)
13 ... /* 省略 Partition 和 Distribution 信息 */
而这个表结构,完全同等于以下使用聚合模型描述的表结构:
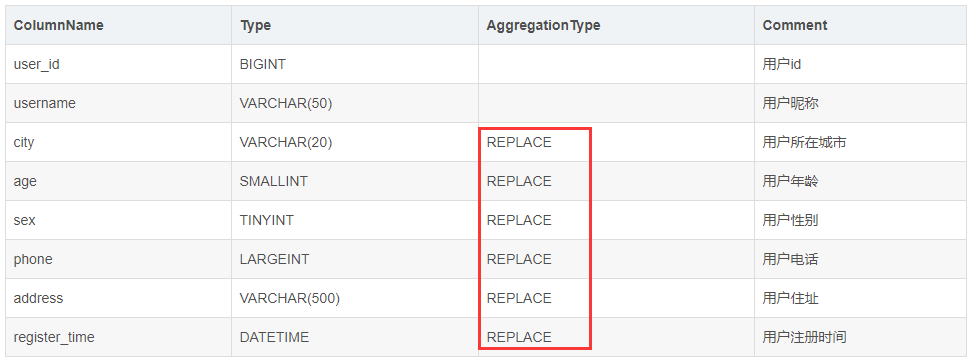
即 Uniq 模型完全可以用聚合模型中的 REPLACE 方式替代。其内部的实现方式和数据存储方式也完全一样
Duplicate (明细模型)
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。举例说明

建表语句:
1 CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
2 (
3 `timestamp` DATETIME NOT NULL COMMENT "日志时间",
4 `type` INT NOT NULL COMMENT "日志类型",
5 `error_code` INT COMMENT "错误码",
6 `error_msg` VARCHAR(1024) COMMENT "错误详细信息",
7 `op_id` BIGINT COMMENT "负责人id",
8 `op_time` DATETIME COMMENT "处理时间"
9 )
10 DUPLICATE KEY(`timestamp`, `type`)
11 ... /* 省略 Partition 和 Distribution 信息 */
这种数据模型区别于 Aggregate 和 Uniq 模型。数据完全按照导入文件中的数据进行存储,不会有任何聚合。即使两行数据完全相同,也都会保留。 而在建表语句中指定的 DUPLICATE KEY,只是用来指明底层数据按照那些列进行排序。(更贴切的名称应该为 “Sorted Column”,这里取名 “DUPLICATE KEY” 只是用以明确表示所用的数据模型 )
明细模型就像Mysql中的表一样,优势就在于你可以详细追溯每个用户行为或订单详情。但劣势也很明显,分析型的查询效率不高。
构建Rollup:
ROLLUP 在多维分析中是“上卷”的意思,也就是从细粒度的数据向高层的聚合。
在 Doris 中,我们将用户通过建表语句创建出来的表成为 Base 表(Base Table),Base 表中保存着按用户建表语句指定的方式存储的基础数据。在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
Rollup还有一点好处在于,由于Doris具有在原始数据上实时计算的能力,因此不需要对所有维度的每个组合都创建Rollup。尤其是在维度很多的情况下,可以取得一个存储空间和查询效率之间的平衡。
举例:Aggregate 和 Uniq 模型中的 ROLLUP, 因为 Uniq 只是 Aggregate 模型的一个特例,所以这里我们不加以区别

例如: 在刚才的广告点击率表上选取 城市 和 广告id 作为维度列构建一个Rollup表。
- 那么不同时间的相同 广告id ,就会再次进行聚合。比如12月31日和1月1日在美国对广告1的点击量就会相加得到40这个总和。
- 在导入新数据的过程中:为保证Rollup表和原始表的数据一致性。新增数据会同时导入Base表和Rollup表。对Rollup表的更新并不是拿整个Base数据重新构建一遍Rollup,而是增量更新。
- 例如: 12月31日广告1在美国的点击量增加一次,则Base表中的点击量就会变成11,而Rollup表中的点击量就会变成41。
- 查询的时候会根据查询需要的维度列以及聚合方式,自动匹配到最优的(一般就是聚合程度最高的)Rollup表。由于聚合数据已经提前计算好了,所以Rollup是一个能加快查询效率的功能。
- 例如: 如果想要分析每条广告在不同国家的点击量,Doris就会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。
前缀索引与 ROLLUP
不同于传统的数据库设计,Doris 不支持在任意列上创建索引。Doris 这类 MPP 架构的 OLAP 数据库,通常都是通过提高并发,来处理大量数据的。
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
在 Aggregate、Uniq 和 Duplicate 三种数据模型中。底层的数据存储,是按照各自建表语句中,AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 中指定的列进行排序存储的。
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。举例说明
Base 表结构如下:

我们可以在此基础上创建一个 ROLLUP 表:
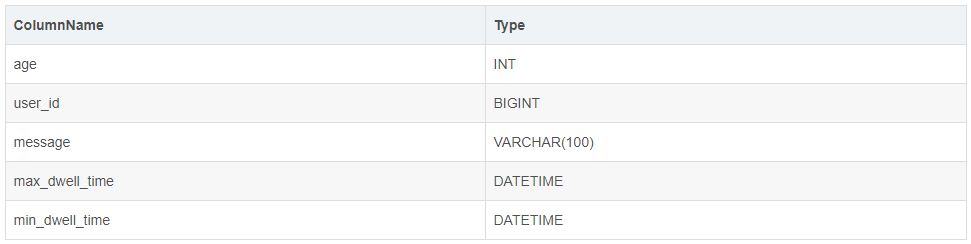
可以看到,ROLLUP 和 Base 表的列完全一样,只是将 user_id 和 age 的顺序调换了。那么当我们进行如下查询时:
- SELECT * FROM table where age=20 and massage LIKE "%error%";
会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
数据模型小结:
1、聚合模型特点与适合场景:
- 老数据不会被更新,只会追加新数据
- 不需要召回原始的明细数据
- 业务方进行的查询为汇总类查询
- 场景如:网站或App的访问流量、广告点击总量等
2、唯一主键模型特点与适合场景:
- 已经写入的数据有大量的更新需求;
- 注意事项:
- 导入数据时需要将所有字段补全才能够完成更新操作
- 对于更新模型的数据读取,需要在查询时完成多版本合并,当版本过多时会导致查询性能降低。所以在向更新模型导入数据时,应该适当降低导入频率,从而提升查询性能。
- 因为合并过程需要将所有主键字段进行比较,所以应该避免放置过多的主键字段,以免降低查询性能。
3、明细模型特点与适合场景:
- 明细模型表中导入完全相同的两行数据时,DorisDB会认为是两行数据
- 需要保留原始的数据(例如原始日志,原始操作记录等)来进行分析的场景
- 注意:
- 充分利用排序列,在建表时将经常在查询中用于过滤的列放在表的前面,这样能够提升查询速度。
- 明细模型中, 可以指定部分的维度列为排序键; 而聚合模型和更新模型中, 排序键只能是全体维度列
4、数据模型的选择建议
- 因为数据模型在建表时就已经确定,且无法修改。所以,选择一个合适的数据模型非常重要
- Aggregate 模型可以通过预聚合,极大地降低聚合查询时所需扫描的数据量和查询的计算量,非常适合有固定模式的报表类查询场景。但是该模型对 count(*) 查询很不友好。同时因为固定了 Value 列上的聚合方式,在进行其他类型的聚合查询时,需要考虑语意正确性。
- Uniq 模型针对需要唯一主键约束的场景,可以保证主键唯一性约束。但是无法利用 ROLLUP 等预聚合带来的查询优势(因为本质是 REPLACE,没有 SUM 这种聚合方式)
- Duplicate 适合任意维度的 Ad-hoc 查询。虽然同样无法利用预聚合的特性,但是不受聚合模型的约束,可以发挥列存模型的优势(只读取相关列,而不需要读取所有 Key 列)
5、ROLLUP 小结:
- ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了 “上卷” 的范围。这也是为什么我们在源代码中,将其命名为 Materized Index(物化索引)的原因。
- ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
- ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- ROLLUP 的数据更新与 Base 表示完全同步的。
- ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
- 查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
- 某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP
- 可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP
- 可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP
- 这里Rollup说明的补充Rollup
Flag:
- 比较适合于Once Write 的场景
- 交易订单存在多次更新的场景,同时也存在着按维度聚合的场景,好象并不适合此组件?
参考资料
- https://blog.csdn.net/kaede1209/article/details/112243447
- https://ai.baidu.com/forum/topic/show/987485
- https://www.kancloud.cn/dorisdb/dorisdb/2142134
- https://www.yuque.com/zailushang-j5dyp/wn32ln/rgf09k
- Apache Doris (Incubating) 原理与实践
- https://ai.baidu.com/forum/topic/show/987485
- Doris核心功能介绍—预聚合引擎和物化视图
三、Doris数据模型的更多相关文章
- MVC中使用EF(1):为ASP.NET MVC程序创建Entity Framework数据模型
为ASP.NET MVC程序创建Entity Framework数据模型 (1 of 10) By Tom Dykstra |July 30, 2013 Translated by litdwg ...
- Java学习笔记三十:Java小项目之租车系统
Java小项目之租车系统 一:项目背景介绍: 根据所学知识,编写一个控制台版的“呱呱租车系统” 功能: 1.展示所有可租车辆: 2.选择车型.租车量: 3.展示租车清单,包含:总金额.总载货量以及其车 ...
- Android联系人数据库
转载自http://www.2cto.com/kf/201406/309356.html 通信录是一个3层的数据存储模型,这三个数据模型就是ContactsContact.Data,ContactsC ...
- SQL常用语句整理
有次笔试最后一页的三个数据库连接查询,没有写出来,被考官暗讽了下.现在想来,实习初,确实很LOW.现公司刚入职的时候,负责过ETL方面,所以和数据库打了不少交道,五十行的联合查询.上百行的存储过程很常 ...
- iOS中Cell高度如何能够自动适应需要显示的内容
本文的代码例子 : "Cell行高自适应.zip" http://vdisk.weibo.com/s/Gb9Mt 下面我们来看看代码.我需要一个第三方库EGO异步下载.addtio ...
- android 联系数据库
联系人数据库学习 2011-10-31(这是android2.3在接触db) 简单介绍 Android中联系人的信息都是存储在一个叫contacts2.db的数据库中.该数据库的路径是:/data/d ...
- 我的Android 4 学习系列之数据库和Content Provider
目录 创建数据库和使用SQLite 使用Content Provider.Cusor和Content Value来存储.共享和使用应用程序数据 使用Cursor Loader异步查询Content P ...
- [转载] ZooKeeper简介
转载自http://blog.csdn.net/kobejayandy/article/details/17738435 一. Paxos 基于消息传递通信模型的分布式系统,不可避免的会发生 ...
- 初步了解 Django Models
Part1:了解主键 1. Python和Django版本如下: E:\django>python3 -V Python 3.5.2 E:\django>python3 -m d ...
- OpenStack容器网络项目Kuryr(libnetwork)
转:https://www.aliyun.com/jiaocheng/518375.html 摘要:容器近几年非常流行,有很多项目都考虑将容器与SDN结合.Kuryr就是其中一个项目.Kuryr项目在 ...
随机推荐
- Oracle 关闭 DBLink
alter system set open_links=0 sid ='*' scope=spfile; System altered. alter system set open_links_per ...
- KingbaseES V8R6 备份恢复案例 -- 自定义表空间指定目录恢复
案例说明: KingbaseES V8R6在通过sys_rman执行物理备份恢复时,可以通过参数'--kb1-path',指定恢复的数据(data)目录,但如果原备份中包含自定义表空间时,需要建立 ...
- KingbaseES V8R6 运维案例 -- sys_filenode.map故障案例
案例说明: 数据库下的sys_filenode.map文件被破坏,导致此数据库无法连接访问. Nail表(内核系统表)Relfilenode的存储机制: 经过研究发现,在数据目录里存在着pg_fi ...
- debian12 出现Waiting for suspend/resume device ... Begin: Running /scripts/local-block ... done.
/etc/initramfs-tools/conf.d/resume里对应的交换分区的uuid不正确 删除/etc/initramfs-tools/conf.d/resume 再运行 sudo upd ...
- NUMA 平台
What is NUMA? This question can be answered from a couple of perspectives: the hardware view and the ...
- Go~开发笔记~目录
Go(又称为Golang)是一门由Google开发的开源编程语言,于2009年首次公开发布.Go语言被设计用来提高软件开发的效率和可靠性,在处理大规模系统时表现出色.以下是Go语言的一些特点和优势: ...
- SQL 递归核心思想(递归思维)
目前很缺递归思维,主要是算法代码写得少,本篇记录下以 PostgreSQL 代码举例(主要是非常喜欢这款性能小钢炮数据库). 树状查询不多说,很简单大家基本都会,主要讲 cte 代码递归实现不同需求. ...
- #KMP,矩阵乘法#洛谷 3193 [HNOI2008]GT考试
题目 给定\(n,m,K\)和一个长度为\(m\)的数\(x\), 问有多少个\(n\)位数满足任意一段不与\(x\)完全相同,可含前导0 \(n\leq 10^9,m\leq 20\) 分析 设\( ...
- #树状数组#洛谷 4113 [HEOI2012]采花
题目 分析 与HH的项链类似 离线处理询问,按右端点排序,维护最近的颜色和第二近的颜色,修改以第二近的颜色为准 换句话说,若最近颜色的位置为\(pos2\),第二近颜色的位置为\(pos1\) 加入一 ...
- Docker学习路线6:使用第三方镜像
第三方镜像是在Docker Hub或其他容器注册表上提供的预构建Docker容器镜像.这些镜像由个人或组织创建和维护,可以作为您容器化应用程序的起点. 查找第三方镜像 Docker Hub 是最大和最 ...