学生课程分数的Spark SQL分析
读学生课程分数文件chapter4-data01.txt,创建DataFrame。
url = "file:///D:/chapter4-data01.txt"
rdd = spark.sparkContext.textFile(url).map(lambda line:line.split(','))
rdd.take(3) from pyspark.sql.types import IntegerType,StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
fields = [StructField('name',StringType(),True),StructField('course',StringType(),True),StructField('score',IntegerType(),True)]
schema = StructType(fields) # 生成“表中的记录”
data = rdd.map(lambda p:Row(p[0],p[1],int(p[2]))) # 把“表头”和“表中的记录”拼接在一起
df_scs = spark.createDataFrame(data,schema)
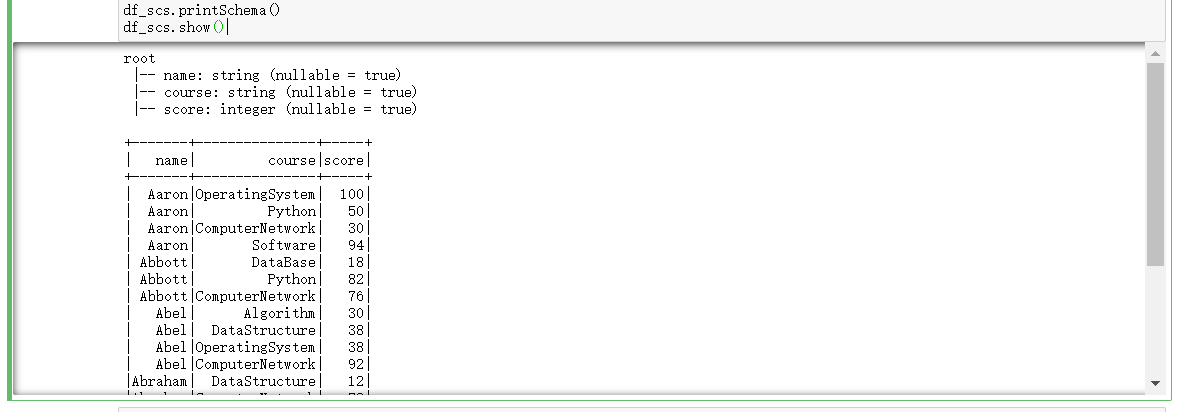
df_scs.printSchema()
df_scs.show()
一:用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
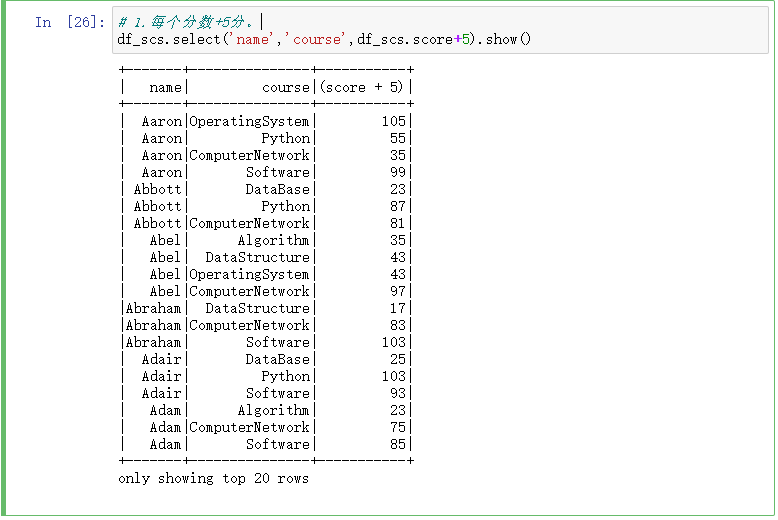
1.每个分数+5分。
# 1.每个分数+5分。
df_scs.select('name','course',df_scs.score+5).show()
2.总共有多少学生?
# 2.总共有多少学生?
df_scs.select(df_scs.name).distinct().count() df_scs.select(df_scs['name']).distinct().count() df_scs.select('name').distinct().count()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程?
df_scs.select('course').distinct().show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课?
df_scs.groupBy('name').count().show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选?
df_scs.groupBy('course').count().show()

6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数?
df_scs.filter(df_scs.score>95).groupBy('course').count().show()

7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分?
df_scs.filter(df_scs.name=='Tom').show()

8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。
df_scs.filter(df_scs.name=='Tom').orderBy(df_scs.score).show()

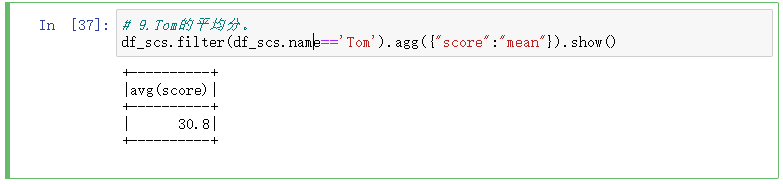
9.Tom的平均分。
# 9.Tom的平均分。
df_scs.filter(df_scs.name=='Tom').agg({"score":"mean"}).show()
10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。
df_scs.groupBy("course").agg({"score": "mean"}).show() df_scs.groupBy("course").agg({"score": "max"}).show() df_scs.groupBy("course").agg({"score": "min"}).show()

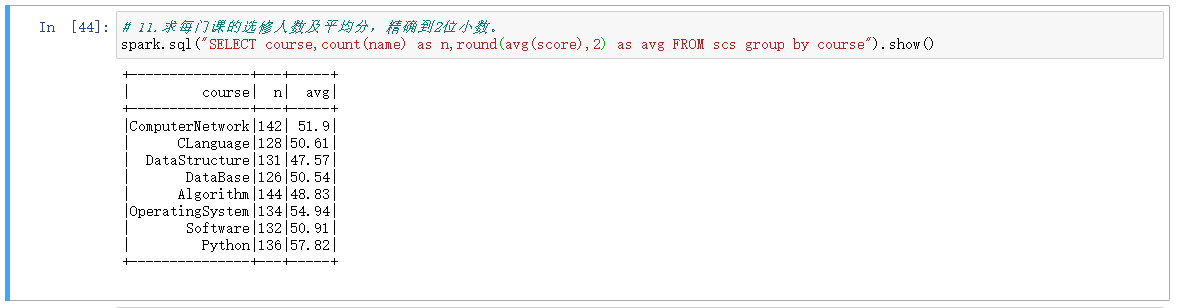
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。
df_scs.select(countDistinct('name').alias('学生人数'),countDistinct('course').alias('课程数'),round(mean('score'),2).alias('所有课的平均分')).show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率
df_scs.filter(df_scs.score<60).groupBy('course').count().show()

13.结果可视化。
二、用SQL语句完成以上数据分析要求
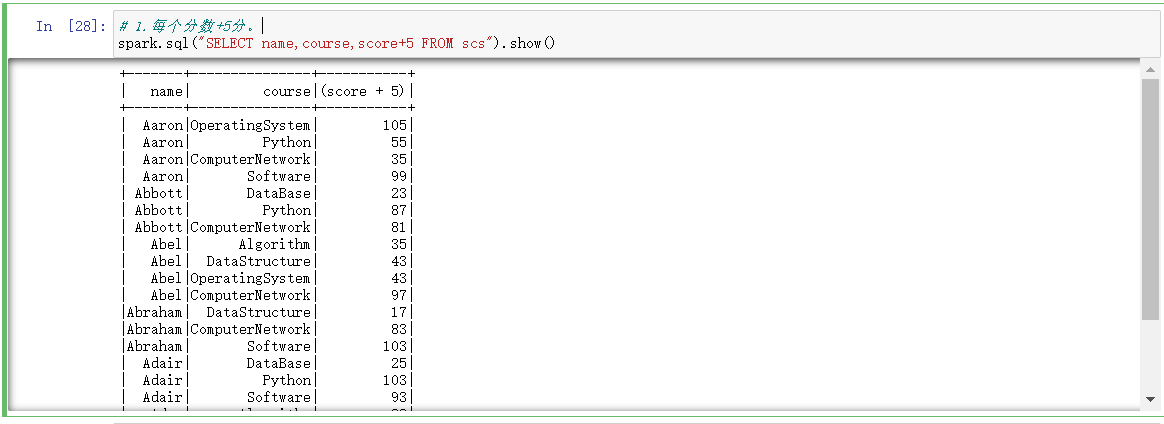
1.每个分数+5分。
# 1.每个分数+5分。
spark.sql("SELECT name,course,score+5 FROM scs").show()
2.总共有多少学生?
# 2.总共有多少学生?
spark.sql("SELECT course,count(name) as n FROM scs group by course").show()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程?
spark.sql("SELECT course FROM scs group by course").show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课?
spark.sql("SELECT name,count(course) FROM scs group by name").show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选?
spark.sql("SELECT course,count(name) FROM scs group by course").show()

6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数?
spark.sql("SELECT course,count(name) FROM scs where score>95 group by course").show()
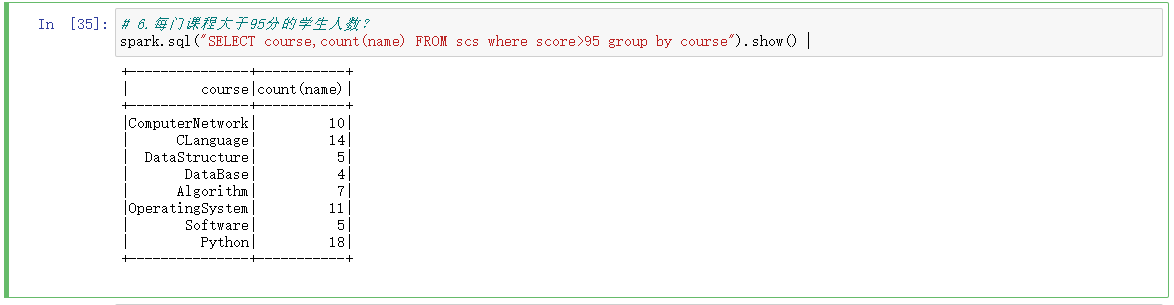
7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分?
spark.sql("SELECT * FROM scs where name=='Tom'").show()
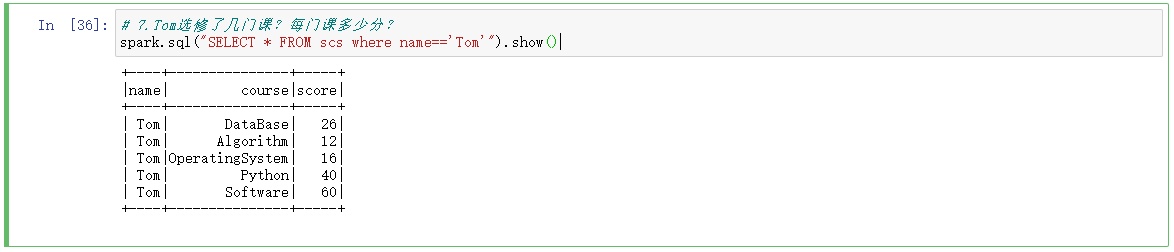
8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。
spark.sql("SELECT * FROM scs where name=='Tom' order by score desc").show()

9.Tom的平均分。
# 9.Tom的平均分。
spark.sql("SELECT avg(score) as avg FROM scs where name=='Tom'").show()

10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。
spark.sql("SELECT course,count(name) as n,avg(score) as avg,max(score) as max,min(score) as min FROM scs group by course").show()
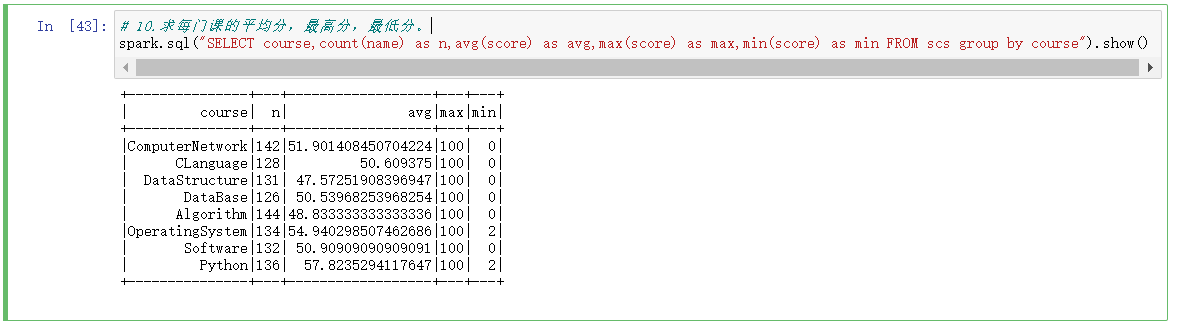
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。
spark.sql("SELECT course,count(name) as n,round(avg(score),2) as avg FROM scs group by course").show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").createOrReplaceTempView("a")
spark.sql("SELECT course,count(score) as notPass FROM scs where score<60 group by course").createOrReplaceTempView("b")
spark.sql("SELECT * from a left join b on a.course=b.course").show() spark.sql("select a.course,round(a.avg,2),b.notPass,round((a.n-b.notPass)/a.n,2) as passRat from a left join b on a.course=b.course").show()

三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
例如:每门课的选修人数与平均分
1.RDD实现
# 方法一 combineByKey()
course = words.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) #每门课的选修人数及所有人的总分。combineByKey()
course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect() #每门课的选修人数及平均分,精确到2位小数。 #方法二 reduceByKey()
lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).collect()

2.DataFrame实现
df_scs.groupBy("course").agg({'name':'count','score':'mean'}).withColumnRenamed("avg(score)",'avg').withColumnRenamed("count(name)",'n').show()
df_scs.groupBy("course").avg('score').show()
df_scs.groupBy("course").count().show()
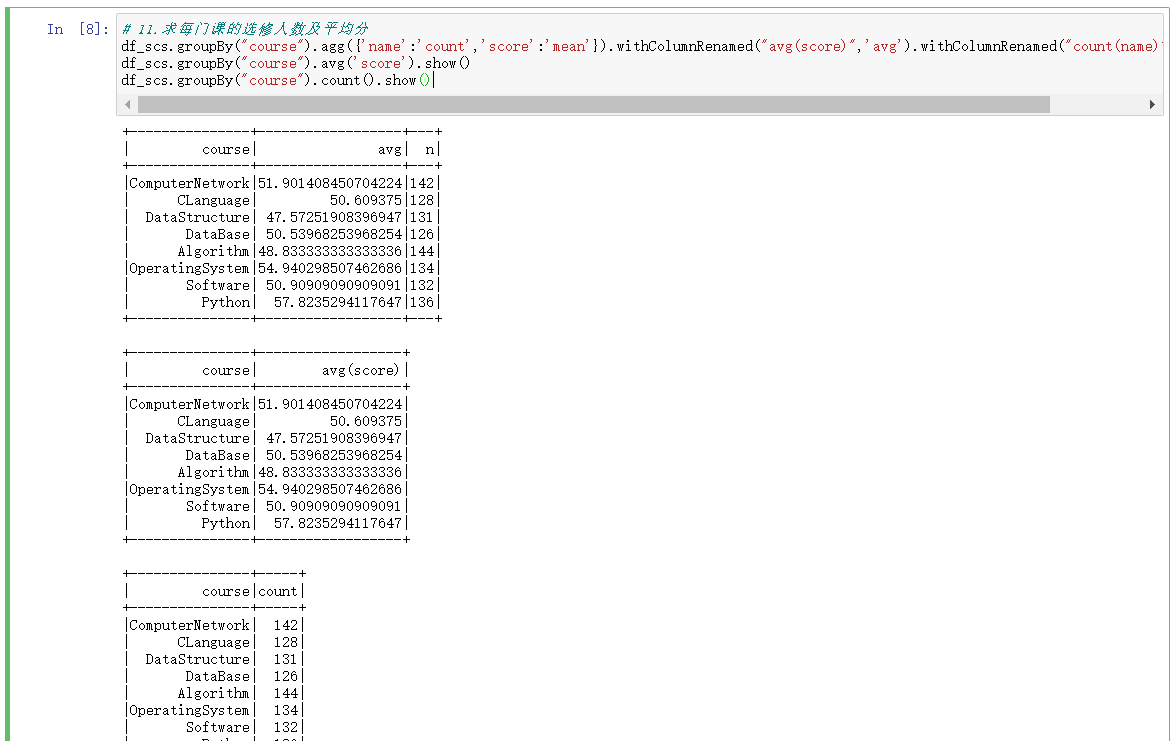
3.SQL语句
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").show()
四、结果可视化。
函数:http://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html#module-pyspark.sql.functions
学生课程分数的Spark SQL分析的更多相关文章
- 08 学生课程分数的Spark SQL分析
读学生课程分数文件chapter4-data01.txt,创建DataFrame. 用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比: 每个分数+5分. 总共 ...
- hive Spark SQL分析窗口函数
Spark1.4发布,支持了窗口分析函数(window functions).在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分 ...
- Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块) 通过SparkSQL导入的数据可以来自MySQL数据库.Json数据.Csv数据等,通过load这些数据可以对其做一系列计算 下面通过程序代码来 ...
- 05 RDD练习:词频统计,学习课程分数
.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5. ...
- 小菜菜mysql练习解读分析1——查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 好的,第一道题,刚开始做,就栽了个跟头,爽歪歪,至于怎么栽跟头的 ——需要分析题目,查询的是 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- Mysql--查询"01"课程比"02"课程成绩高的学生的信息及课程分数
今天在写Mysql代码作业时,写到这个题,感觉值得分享!!!!!!! 查询"01"课程比"02"课程成绩高的学生的信息及课程分数 分析如下: 首先先查询&quo ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
随机推荐
- centos7无网环境安装docker
1.下载docker的安装文件 https://download.docker.com/linux/static/stable/x86_64/ 由于公司OpenStack用的docker版本是18.0 ...
- 鸿蒙开发学习笔记-UIAbility-Router页面跳转接口源码分析
在鸿蒙开发中,UIAbility的跳转使用 router 方法. 在使用的时候需导入 import router from '@ohos.router'; 该方法接口成员如下: 1.interface ...
- GET 和 POST 到底有什么区别?
HTTP最早被用来做浏览器与服务器之间交互HTML和表单的通讯协议:后来又被被广泛的扩充到接口格式的定义上.所以在讨论GET和POST区别的时候,需要现确定下到底是浏览器使用的GET/POST还是用H ...
- 二进制安装Kubernetes(k8s) v1.23.6
二进制安装Kubernetes(k8s) v1.23.6 背景 kubernetes二进制安装 1.23.3 和 1.23.4 和 1.23.5 和 1.23.6 文档以及安装包已生成. 后续尽可能第 ...
- YUM下载全量依赖
在离线的内网环境下进行安装一些软件的时候会出现依赖不完整的情况,一般情况下会使用如下方式进行下载依赖包 查看依赖包可以使用 yum deplist 进行查找 [root@localhost ~]# y ...
- Luogu P2574 XOR的艺术 P3870 [TJOI2009]开关 P2846 [USACO08NOV]光开关Light Switching SP7259 LITE - Light Switching
四倍经验题 简单线段树qwq(那你怎么还调了好几个小时) 修改:\(ans[cur]=(r-l+1-ans[cur]);\) 点表示的区间有多长就是有多少盏灯 亮着的关掉 暗的开启 就是上述语句了. ...
- day14:列表/集合/字典推导式&生成器表达式&生成器函数
推导式 推导式的定义: 通过一行循环判断,遍历一系列数据的方式 推导式的语法: val for val in Iterable 三种方式: [val for val in Iterable] {val ...
- HashMap实现原理和自动扩容
HashMap实现原理: JDK1.7:数组+单向链表(头插) 在并发情况下头插可能出现循环链表(死循环)问题.原因:因为头插,在新数组中链表的元素顺序发生了变化, 如上图,假设线程1在扩容,刚刚调整 ...
- NC51101 Lost Cows
题目链接 题目 题目描述 \(N (2 \leq N \leq 8,000)\) cows have unique brands in the range 1..N. In a spectacular ...
- 一文吃透Tomcat核心知识点
架构 首先,看一下整个架构图.最全面的Java面试网站 接下来简单解释一下. Server:服务器.Tomcat 就是一个 Server 服务器. Service:在服务器中可以有多个 Service ...