带你了解磁盘驱动程序(xv6)
磁盘驱动程序
本文来聊聊磁盘驱动程序,驱动程序是硬件的接口,操作系统通过这个接口来控制硬件工作,所以驱动程序就好比是硬件和系统之间的桥梁。这是百科上给出的解释,可能看起来还是云里雾里,我来做做注解。
每个硬件都有自己的 “CPU”(控制器),寄存器,有着自己的一套执行逻辑。对外提供了一些列的物理接口,就是那一个个端口(寄存器),可以通过设置这些端口来控制硬件工作。要知道直接通过物理接口来控制硬件工作是很繁复的,所以将这些接口给封装起来便于使用,这就是驱动程序。
所以操作系统通过驱动程序提供的接口来间接控制硬件工作,驱动程序通过硬件实际的物理接口来直接控制硬件工作,驱动程序就是对硬件物理接口的封装。本文通过 xv6 来看一看简单的磁盘驱动程序是怎样的,以便对驱动程序有更深刻的认识
IDE接口
寄存器
首先来了解磁盘的一些寄存器:

xv6 中磁盘驱动程序需要用到的寄存器如上所示,没有翻译,有些也不太好翻译,就直接看英文吧,应该也能看懂,我们一个一个来看:
0x1F0/Data,唯一一个 16 bit 的寄存器,用来传输数据。
0x1F1/Error, 读的时候表示错误,8 bit,每一位表示一种错误,这里不展开了,有需要的看我后面给出的资料链接。
0x1F2/Sector Count,表扇区总数,读写的时候指定要操作的扇区总数
0x1F3,0x1F4,0x1F5 分别表示 LBA 地址的低中高 8 位,LBA 地址有 24 位,还有顶部的 4 位见下
0x1F6/Device/Head:
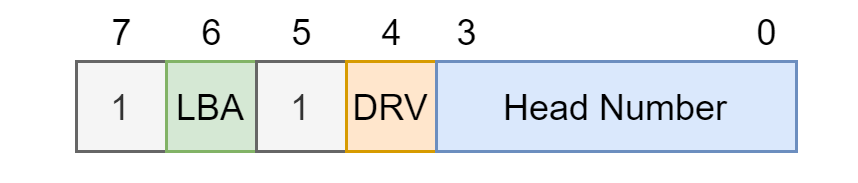
- 0~3 位为 LBA 地址的最高 4 位
DRV位为 1 表示该盘是主盘,0 表示该盘是从盘LBA位为 1 表示采用 LBA 寻址,0 表示采用 CHS 寻址,现今一般都采用 LBA 寻址,所以 0x1F3~5 表示 LBA 地址的 24 位,否则应表示 CHS 三个指标- bit 5 和 bit 1 固定为 1
0x1F7/Status
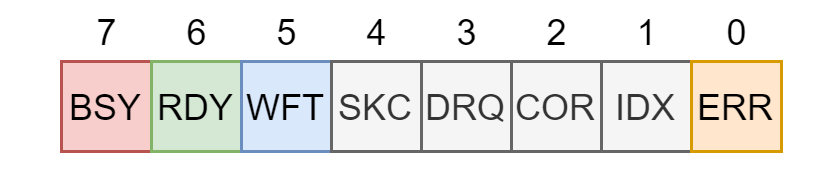
ERR,有错误发生,错误码放在错误寄存器中(0x1F1)WFT,检测到有写错误RDY,表示硬盘就绪,这是在对硬盘诊断的时候用的,表示硬盘检测正常,可以继续执行一些命令BSY,表示硬盘是否繁忙,1 表示繁忙,此时其他所有位无效
0x1F7/Command,向这个寄存器写入命令来操作硬盘,具体命令见后面
0x3F6/DeviceControl,这个寄存器只用到了低 2 位:
RST(bit2),设置为 1 时表示发送复位 reset 信号,正常情况下此位应为 0IEN(bit1),设置为 1 时键盘控制器将不会发送中断信号,正常情况应为 0,使得键盘在完成某些命令之后能够发送中断给 CPU,然后 CPU 进行后续处理。
命令
0x20,读扇区命令
0x30,写扇区命令
0xc4,读多个扇区
0xc5,写多个扇区
xv6 里面就只用了这几个命令,其他的命令见后链接资料,有了这些了解之后来看 xv6 的相关源码
xv6
缓存
具体看 xv6 有关磁盘操作的代码之前,先来了解磁盘缓存。磁盘读写操作是很慢的,所以一般都会将一部分内存作为磁盘的缓存,xv6 也是如此,专门在内存中分配一片区域作为磁盘缓存,这片缓存的最小单位是块。我在捋一捋文件系统一文中讲过,操作系统或者说文件系统层面磁盘读写的单位是块,磁盘自己本身的读写单位是扇区,一般块大小等于一个或多个扇区的大小。
因此我们来看看 xv6 中缓存块的定义:
struct buf {
int flags; //表示该块是否脏是否有效
uint dev; //该缓存块表示的设备
uint blockno; //块号
struct sleeplock lock; //休眠锁
uint refcnt; //引用该块的个数
struct buf *prev; //该块的前一个块
struct buf *next; //该块的后一个块
struct buf *qnext; //下一个磁盘队列块
uchar data[BSIZE]; //缓存的数据
};
#define B_VALID 0x2 // buffer has been read from disk
#define B_DIRTY 0x4 // buffer needs to be written to disk
缓存块缓存的是磁盘上的数据,缓存块的数据需要与磁盘数据同步,所以需要设定标志位来表示目前缓存块的数据是否有效,是否需要从磁盘中读取数据到该块;缓存块的数据是否已做改动变脏,是否需要写回磁盘上去。
以前的主板上为硬盘提供了两个通道,
P
r
i
m
a
r
y
Primary
Primary 通道和
S
e
c
o
n
d
a
r
y
Secondary
Secondary 通道,每个通道可以挂两个磁盘,分为主盘和从盘。不同通道的端口也就是寄存器地址不同,上面所讲的都是
P
r
i
m
a
r
y
Primary
Primary 通道的寄存器,一般也就是使用
P
r
i
m
a
r
y
Primary
Primary 通道,
S
e
c
o
n
d
a
r
y
Secondary
Secondary 通道相应的端口可以参考文末给出的手册。通道上的两块硬盘又分为主盘和从盘,这是根据 device 寄存器的第 4 位来区分的。主从,听名字就知道主盘要重要些,里面主要存放启动程序和操作系统,从盘主要就是拿来存储数据。就跟 windows 中常见的系统盘 C 和其他盘一样,如果没有从盘,那所有的信息就放在主盘上。
缓存块算作是公共资源,需要避免竞争条件,所以配了一把锁,而且是休眠锁,因为同步缓存块到磁盘涉及 I/O 操作是很慢的,所以一般在读写的时候进程就在上面休眠。
每个缓存块可能多个任务使用,所以有了 refcnt 来表示该块被引用了多少次,但是任何时刻应该最多只有一个任务在使用该缓存块。
当一个缓存块需要从磁盘读取数据或者写回磁盘,xv6 维持了一个磁盘的请求队列,所以有了
q
n
e
x
t
qnext
qnext 这个属性,它指向下一个请求磁盘的缓存块。
这些缓存块也是需要组织管理的,方便必要的时候进行分配和回收,前面文章说过,基本上组织这些块的方式一般就是位图或者链表,xv6 使用了链表的形式而且是双向循环链表,所以每个块有了
p
r
e
v
prev
prev 和
n
e
x
t
next
next 属性,分别指向前一个块和后一个块。来看具体的实现:
struct {
struct spinlock lock;
struct buf buf[NBUF];
struct buf head;
} bcache; //申明一片缓存区
void binit(void) //头插法将N个缓存块串起来
{
struct buf *b;
initlock(&bcache.lock, "bcache");
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
initsleeplock(&b->lock, "buffer");
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
上面函数应该很简单吧,就是双向链表的实现,数据结构课程上应该都练习过很多了,所以对代码也不解释了,只说明一点:每个缓存块有个休眠锁,因为可能要进行磁盘请求,速度很慢,所以使用了休眠锁,必要情况下直接让进程休眠让出 CPU,提高 CPU 利用率。而整个缓存区
b
c
a
c
h
e
bcache
bcache 也有个锁,是自旋锁,
b
c
a
c
h
e
bcache
bcache 就像缓存块的分配器一般,获取释放缓存块都需要
b
c
a
c
h
e
bcache
bcache 同意,而且
b
c
a
c
h
e
bcache
bcache 也是公共资源,任意时刻都应最多只有一个任务访问,另外获取释放缓存块的操作一般很短,所以配了一把自旋锁。
既然说到获取释放缓存块,那就来看看怎么实现的:
static struct buf* bget(uint dev, uint blockno)
{
struct buf *b;
acquire(&bcache.lock); //取bcache的锁
// Is the block already cached? 要获取的磁盘块已缓存
for(b = bcache.head.next; b != &bcache.head; b = b->next){ //双向循环链表,从前往后扫描
if(b->dev == dev && b->blockno == blockno){ //如果设备和块号都对上,那么是要找的块
b->refcnt++; //该块的引用加1
release(&bcache.lock); //释放bcache的锁
acquiresleep(&b->lock); //给该块加锁
return b; //返回该块
}
}
// Not cached; recycle an unused buffer.
// Even if refcnt==0, B_DIRTY indicates a buffer is in use
// because log.c has modified it but not yet committed it.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){ //该磁盘块没有缓存,从后往前扫描
if(b->refcnt == 0 && (b->flags & B_DIRTY) == 0) { //找一个引用为0,且脏位也为0的空闲缓存块
b->dev = dev; //设备
b->blockno = blockno; //块号
b->flags = 0; //刚分配的缓存块,数据无效
b->refcnt = 1; //引用数为1
release(&bcache.lock); //释放bcache的锁
acquiresleep(&b->lock); //给该缓存块加锁
return b; //返回该缓存块
}
}
panic("bget: no buffers"); //既没缓存该块,也没得空闲缓存块了,panic
}
根据设备和块号在缓存区中寻找该磁盘块是否已经缓存,如果已缓存,则返回该缓存块。如果没有缓存,那么在缓存区中找一个空闲缓存块来缓存相应磁盘块,这里要注意,只是将磁盘块所属设备和块号赋给了刚分配的缓存块,但是数据还没有传到缓存块,这需要磁盘请求,所以
f
l
a
g
s
flags
flags 为 0 表示缓存块里面的数据无效。
void brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock); //释放缓存块的锁
acquire(&bcache.lock); //获取bcache的锁
b->refcnt--; //该块的引用减1
if (b->refcnt == 0) { //没有地方再引用这个块,将块链接到缓存区链头
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head.next;
b->prev = &bcache.head;
bcache.head.next->prev = b;
bcache.head.next = b;
}
release(&bcache.lock); //释放bache的锁
}
该函数释放缓存块,如果引用该块的进程较多,直接将引用数减 1,减 1 之后如果没有进程再引用该缓存块,则真正的释放该缓存块,直接将该块放在链头。缓存块的引用数为 0 一般就认为该块就是空闲的了,所以不用做什么额外工作,当然这只是一般情况,还有特殊情况超出本文范围,后面文件系统的文章再详述。
struct buf* bread(uint dev, uint blockno) //返回一个存在有效数据的缓存块
{
struct buf *b;
b = bget(dev, blockno); //获取一个缓存块
if((b->flags & B_VALID) == 0) { //如果该块是临时分配的数据无效
iderw(b); //请求磁盘,读取数据
}
return b;
}
// Write b's contents to disk. Must be locked.
void bwrite(struct buf *b) //将缓存块写到相应磁盘块
{
if(!holdingsleep(&b->lock)) //要写这个块,那说明已经拿到了这个块,所以肯定也拿到锁了
panic("bwrite");
b->flags |= B_DIRTY; //设置脏位
iderw(b); //请求磁盘写数据
}
读写磁盘块变成读写缓存块,然后再由操作系统给同步到磁盘。
i
d
e
r
w
(
)
iderw()
iderw() 负责将数据读到缓存块或者将数据写到磁盘中去,到底是读还是写根据缓存块
f
l
a
g
s
flags
flags 来判断,如果无效则需要从磁盘读取数据,如果缓存块的数据脏则将数据写到磁盘。
磁盘驱动程序
下面来看看底层磁盘的操作,也就是常说的磁盘驱动程序,驱动程序听起来很复杂,但是简单来讲的话,驱动程序就是将硬件操作封装成过程,避免每次进行重复无味的操作,来具体看看:
#define SECTOR_SIZE 512 //扇区大小512字节
#define IDE_BSY 0x80 //状态寄存器的第7位表硬盘是否繁忙
#define IDE_DRDY 0x40 //状态寄存器的第6位表硬盘是否就绪,可继续执行命令
#define IDE_DF 0x20 //写错误
#define IDE_ERR 0x01 //出错
#define IDE_CMD_READ 0x20 //读扇区命令
#define IDE_CMD_WRITE 0x30 //写扇区命令
#define IDE_CMD_RDMUL 0xc4 //读多个扇区
#define IDE_CMD_WRMUL 0xc5 //写多个扇区
首先是一些宏定义,上述为
x
v
6
/
i
d
e
.
c
xv6/ide.c
xv6/ide.c 中定义的各个宏,对照着上述讲的寄存器应该很容易明白什么意思。下面来看一些关键函数:
static int idewait(int checkerr) //等待硬盘就绪
{
int r;
while(((r = inb(0x1f7)) & (IDE_BSY|IDE_DRDY)) != IDE_DRDY) //从端口0x1f7读出状态,若硬盘忙,空循环等待
;
if(checkerr && (r & (IDE_DF|IDE_ERR)) != 0) //检查是否有错误发生,若checkerr为0则不检查
return -1;
return 0;
}
inb(0x1f7) 表示从状态寄存器读出一字节的状态数据,对其 BSY 位和 DRDY 位做与运算,检查磁盘是否就绪。inb 是用内敛汇编封装的函数,用来从 I/O 端口读取数据,详见:内联汇编一文。其他的没什么说的,见注释,应该很好理解。
void ideinit(void) //初始化磁盘
{
int i;
initlock(&idelock, "ide");
ioapicenable(IRQ_IDE, ncpu - 1); //让这个CPU来处理硬盘中断
idewait(0); //等磁盘就绪,不过以0来调用错误检查就不起作用了,猜测是为了更快返回
// Check if disk 1 is present
outb(0x1f6, 0xe0 | (1<<4)); //将硬盘device寄存器高4位设置为1111,表示从盘,寻址模式为LBA
for(i=0; i<1000; i++){ //指定为从盘后,循环读取状态来判断是否有从盘
if(inb(0x1f7) != 0){
havedisk1 = 1;
break;
}
}
// Switch back to disk 0.
outb(0x1f6, 0xe0 | (0<<4)); //将第4位置0表切换成主盘
}
这个函数用来初始化硬盘,被
m
a
i
n
.
c
main.c
main.c 中的
m
a
i
n
(
)
main()
main() 函数锁调用,作为启动时建立环境的一项。
磁盘有一把锁,磁盘是公共资源,每次进行磁盘操作的进程最多只有一个。关于中断 APIC 的配置后面讲中断的时候详述,可以先参考前文:再谈中断(APIC)。
前面说过每个通道支持两块磁盘,将 device 寄存器第 4 位置 1 来表示从盘,从状态寄存器读数据,如果有数据那说明从盘存在,反之从盘不存在,至于循环 1000 次那是因为切换磁盘得需要一定时间吧。最后再切换成主盘,因为目前正在初始化环境阶段,这些较为重要的数据比如操作系统等都在主盘。
static void idestart(struct buf *b)
{
if(b == 0)
panic("idestart");
if(b->blockno >= FSSIZE) //块号超过了文件系统支持的块数
panic("incorrect blockno");
int sector_per_block = BSIZE/SECTOR_SIZE; //每块的扇区数
int sector = b->blockno * sector_per_block; //扇区数
int read_cmd = (sector_per_block == 1) ? IDE_CMD_READ : IDE_CMD_RDMUL; //一个块包含多个扇区的话就用读多个块的命令
int write_cmd = (sector_per_block == 1) ? IDE_CMD_WRITE : IDE_CMD_WRMUL; //一个块包含多个扇区的话就用写多个块的命令
if (sector_per_block > 7) panic("idestart"); //每个块不能大于7个扇区
idewait(0); //等待磁盘就绪
outb(0x3f6, 0); //用来产生磁盘中断,详见前面0x3f6寄存器
outb(0x1f2, sector_per_block); // 读取几个扇区
/*像0x1f3~6写入扇区地址*/
outb(0x1f3, sector & 0xff); //LBA地址 低8位
outb(0x1f4, (sector >> 8) & 0xff); //LAB地址 中8位
outb(0x1f5, (sector >> 16) & 0xff); //LBA地址 高8位
outb(0x1f6, 0xe0 | ((b->dev&1)<<4) | ((sector>>24)&0x0f)); //LBA地址最高的4位,(b->dev&1)<<4来选择读写主盘还是从盘
if(b->flags & B_DIRTY){ //表示数据脏了,需要写到磁盘去了
outb(0x1f7, write_cmd); //向0x1f7发送写命令
outsl(0x1f0, b->data, BSIZE/4); //向磁盘写数据
} else {
outb(0x1f7, read_cmd); //否则发送读命令,但没有读
}
}
先不解释此函数,接着看磁盘中断处理程序:
void ideintr(void)
{
struct buf *b;
// First queued buffer is the active request.
acquire(&idelock); //取锁
if((b = idequeue) == 0){ //如果磁盘请求队列为空
release(&idelock);
return;
}
idequeue = b->qnext; //磁盘请求队列链首向后移
// Read data if needed.
if(!(b->flags & B_DIRTY) && idewait(1) >= 0) //如果此次请求磁盘的操作是读且磁盘已经就绪
insl(0x1f0, b->data, BSIZE/4); //从0x1f0端口读取数据到b->data
// Wake process waiting for this buf.
b->flags |= B_VALID; //此时缓存块数据有效
b->flags &= ~B_DIRTY; //此时缓存块数据不脏
wakeup(b); //唤醒等待在缓存块b上的进程
// Start disk on next buf in queue.
if(idequeue != 0) //此时队列还不空,则处理下一个
idestart(idequeue);
release(&idelock); //释放锁
}
这两个函数应该结合在一起看,才是完整的一次磁盘操作。CPU 不能直接和磁盘进行数据交换,要用内存来中转或者说是缓存,所以进程要读写磁盘的数据的话都不是直接对磁盘进行读写的,而是读写磁盘在内存中的缓存,随后再同步到磁盘。这里所说的同步到磁盘就要用到上述的两个函数了也就是磁盘驱动程序。磁盘是公共资源,每次最多应只有一个进程操作磁盘,而且每次操作的单位是块,对于所有需要同步到磁盘的块维护了一个请求队列
i
d
e
q
u
e
u
e
idequeue
idequeue,这是一个单链表,
i
d
e
q
u
e
u
e
idequeue
idequeue 是其头指针,同步完一个缓存块,头指针便向后移动一个结点。
磁盘的操作大致可以分为以下几个步骤:
- 等待磁盘就绪
- 向相应的寄存器写入 要读写的扇区数,首个扇区的 LBA 地址,指定主盘和从盘
- 然后向命令寄存器写入命令
- 等待磁盘完成任务触发中断
- 执行磁盘中断程序完成磁盘操作
等待磁盘就绪就是上述的
i
d
e
w
a
i
t
(
)
idewait()
idewait() 函数,它读取状态寄存器查看磁盘是否就绪是否发生错误
向扇区数目寄存器写要操作的扇区数,这个跟块大小有关,据代码的意思每次操作不能超过 7 个扇区,但实际在硬件方面应该没有这个规定,据实际测试修改数值也能正常运行。
向 LBA 寄存器填写扇区地址的低 24 位,
s
e
c
t
o
r
&
0
x
f
f
sector \& 0xff
sector&0xff 表示低 8 位写到端口 0x1F3,
(
s
e
c
t
o
r
>
>
8
)
&
0
x
f
f
(sector >> 8) \& 0xff
(sector>>8)&0xff 表示中 8 位,写到端口 0x1F4,
(
s
e
c
t
o
r
>
>
16
)
&
0
x
f
f
(sector >> 16) \& 0xff
(sector>>16)&0xff 表示高 8 位,写到端口 0x1F5。
(
s
e
c
t
o
r
>
>
24
)
&
0
x
0
f
(sector>>24) \& 0x0f
(sector>>24)&0x0f 表示顶 4 位,写到 device寄存器低 4 位,
(
b
→
d
e
v
)
&
1
(b \rightarrow dev) \& 1
(b→dev)&1 表示缓存块缓存的数据所属哪个设备:主盘还是从盘,另外 device 寄存器的第 5 位和第 7 位始终为 1,所表示的值为
0
x
e
0
0xe0
0xe0。将上述三者做或运算就是 device 寄存器该填写的值。
磁盘操作需要的参数已经传给磁盘了,现在该发送命令了,向命令寄存器(0x1F7) 发送相应的命令,这里只使用了读写两种命令,当然两种命令又分为读写一个扇区还是读写多个扇区,这个就还是跟块大小相关了,xv6 里面就是读写一个扇区的命令。
不论是
i
d
e
s
t
a
r
t
(
)
idestart()
idestart() 函数还是
i
d
e
i
n
t
r
(
)
ideintr()
ideintr() 函数,两者既处理读操作,又处理写操作,如何区分呢?就是靠缓存块的
f
l
a
g
s
flags
flags 标识,如果数据脏说明应该是写操作,否则就是读操作。但仔细看
i
d
e
s
t
a
r
t
(
)
idestart()
idestart() 函数最后几行代码:
if(b->flags & B_DIRTY){ //表示数据脏了,需要写到磁盘去了
outb(0x1f7, write_cmd); //向0x1f7发送写命令
outsl(0x1f0, b->data, BSIZE/4); //向磁盘写数据
} else {
outb(0x1f7, read_cmd); //否则发送读命令,但没有读
}
写操作的话,将写命令发给命令寄存器,然后开始写,将数据传给数据寄存。但是读呢?只是将读命令发送给命令寄存,然后就没下文了。为什么会这样呢?来捋捋磁盘的工作方式:
要让磁盘工作,就要给他发送命令,想让磁盘执行这些命令的话,还要提前将需要的参数给它,就比如要操作的扇区数,扇区地址等等,然后再写入命令。等待磁盘完成任务后它自己会触发中断通知 CPU 去拿结果。
除了我们在内存中给磁盘专门留了一块缓存区之外,磁盘自己本身有个缓冲区,一般也是 512 字节。所以当 CPU 发送读命令给磁盘后,磁盘就马不停蹄的将数据准备到自己的缓冲区,准备好了之后,触发中断通知 CPU 来拿数据。而写操作呢,直接将写命令写入命令寄存器,再将数据通过数据寄存器写到磁盘的缓冲区就行了,剩下的事交给磁盘自己去做,完成任务之后触发中断,执行中断处理程序修改缓存块的属性数据不再脏。
所以知道了为什么
i
d
e
s
t
a
r
t
(
)
idestart()
idestart() 对待读写操作不同的原因了吧,读操作要磁盘准备好数据触发中断后才能从数据寄存器读到缓存块,而写操作直接通过数据寄存器写到磁盘的缓冲区就行了,剩下实际物理上的写操作磁盘自己完成,完成之后触发中断 CPU 再去收尾。
到这儿磁盘的中断处理程序应该也很好理解了,如果缓存块的
f
l
a
g
s
flags
flags 标志位显示不脏,说明本次磁盘操作应该是读操作,所以现在发生中断了,说明磁盘数据已经准备好了,该读取数据到缓存块了。如果不是读操作那就是写了,这里就只需要收个尾将缓存块的脏位去除掉就行。最后将休眠在这个缓存块上的进程唤醒。
中断处理程序最后应该显示通知磁盘本次中断完成,可以通过再次读取状态寄存器来完成。xv6 并没有这样操作,而是在每次 磁盘操作之前先向 端口0x3F6 写 0 来表示每次命令完成之后要产生中断。我在 ATA 手册里面没有找到这种显式通知磁盘中断结束的方式,但事实证明的确能够运行,有知情的大佬还请告知,另外据我测试,注释掉
i
d
e
s
t
a
r
t
(
)
idestart()
idestart() 中
o
u
t
b
(
0
x
3
F
6
,
0
)
;
outb(0x3F6, 0);
outb(0x3F6,0); 这行代码,在中断处理程序末尾加上 $inb(0x1F7); $也是能够正常工作的。
执行完本次的磁盘操作后,如果磁盘的请求队列不为空,那么就开始执行下一个。
void iderw(struct buf *b)
{
struct buf **pp;
if(!holdingsleep(&b->lock)) //要同步该块到磁盘,那前面应该是已经拿到了这个块的锁
panic("iderw: buf not locked");
if((b->flags & (B_VALID|B_DIRTY)) == B_VALID) //这个缓存块既不脏数据又有效的话,则无事可做
panic("iderw: nothing to do");
if(b->dev != 0 && !havedisk1) //这个缓存块缓存的不是任一设备的数据
panic("iderw: ide disk 1 not present");
acquire(&idelock); //DOC:acquire-lock
// 将这个块放进请求队列
b->qnext = 0;
for(pp=&idequeue; *pp; pp=&(*pp)->qnext) //DOC:insert-queue
;
*pp = b;
// 如果请求队列为空,当前块是唯一请求磁盘的块,则可以马上进行磁盘操作
if(idequeue == b)
idestart(b);
// Wait for request to finish.
while((b->flags & (B_VALID|B_DIRTY)) != B_VALID){ //数据无效,进程休眠
sleep(b, &idelock);
}
release(&idelock); //释放锁
}
这个函数就没多少说的了,主要是将要同步的缓存块加进磁盘的请求队列,如果请求队列为空则可以马上执行,否则将当前缓存块加进请求队列的末尾。另外只有缓存块数据有效且不脏的时候才不会休眠,否则进程在缓存块之上休眠,等到中断服务程序处理之后再唤醒。
再者这个链表的操作还是值得说道说道,使用的是二级指针,主要因为这个队列是个单链表,再者就是为了操作的一致性,但也增加了复杂性。指针就是个存储地址的变量,而二级指针就是这个指针的地址。牢牢把握主这个指向关系,实际的问题应该就能够解决了,这里我就不详细解释了。设想如果请求队列为空,只有一个结点,有多个结点的情况,可以自己去模拟模拟增删的过程。
那就使用普通的一级指针行不行呢?也是得行的,就是普通的链表操作,我简单的写了下代码:
/**************/
struct buf *pp;
/**************/
pp = idequeue;
if(idequeue){ //请求队列不空的情况
while(pp->qnext)
pp = pp->qnext;
pp->qnext = b;
}else{ //请求队列为空的情况
idequeue = b;
}
/**************/
经测试也是能够正常工作的,如果使用一级指针,又没有头结点,那就需要分情况讨论,具体操作见上。
本文差不多到这就结束了,本文主要讲了简单的磁盘驱动程序,听起来高大上,细细研究其实也不难发现其本质。从上面已经可以看出,如果没得磁盘驱动程序,操作磁盘的步骤是很繁复的,要操作各个寄存器,处理各种前后的逻辑关系。所以磁盘驱动程序就将这些繁复操作给封装起来,形成几个函数,要操作磁盘调用这几个函数就是了。这么一说是不是对于磁盘驱动程序很清楚了,好啦本文就到这里了,有什么错误还请批评指针,也欢迎大家来同我讨论交流一起学习进步。
参考
https://www.unige.ch/medecine/nouspikel/ti99/ide.htm
还有个 ATA 手册,后台回复手册可获取各种手册。
- 公众号:Rand_cs
带你了解磁盘驱动程序(xv6)的更多相关文章
- windows server 2003中用系统自带工具调整磁盘分区大小
先在需要扩展的右边留出未分配的磁盘空间,可以通过 我的电脑 右键 管理 磁盘管理来操作 首先 进入cmd界面 然后输入Diskpart 这个时候进入DISKPART> 界面 然后你 先选择磁盘一 ...
- XV6陷入,中断和驱动程序
陷入,中断和驱动程序 运行进程时,cpu 一直处于一个大循环中:取指,更新 PC,执行,取指…….但有些情况下用户程序需要进入内核,而不是执行下一条用户指令.这些情况包括设备信号的发出.用户程序的非法 ...
- 阵列卡,组成的磁盘组就像是一个硬盘,pci-e扩展出sata3.0
你想提升性能,那么组RAID0,主板上的RAID应该是软RAID,肯定没有阵列卡来得稳定.如果你有闲钱,可以考虑用阵列卡. 不会的.即使不能起到RAID的作用,起码也可以当作直接连接了2个硬盘.不会影 ...
- XV6文件系统
文件系统 文件系统的目的是组织和存储数据,典型的文件系统支持用户和程序间的数据共享,并提供数据持久化的支持(即重启之后数据仍然可用). xv6 的文件系统中使用了类似 Unix 的文件,文件描述符,目 ...
- [整]磁盘 I/O 性能监控指标和调优方法
在介绍磁盘 I/O 监控命令前,我们需要了解磁盘 I/O 性能监控的指标,以及每个指标的所揭示的磁盘某方面的性能. 磁盘 I/O 性能监控的指标主要包括: 指标 1:每秒 I/O 数(IOPS 或 t ...
- Linux磁盘管理之实现多文件系统及VFS06
待续 Linux如何支持多文件系统 不同磁盘需要不同类型的磁盘驱动程序,驱动向上提供接口,不同驱动提供的接口格式不同,在上层是块设备层,用来屏蔽下边驱动接口的差别,向上统一提供,把所有硬盘当成块设备, ...
- 磁盘 I/O 性能监控指标和调优方法
在介绍磁盘 I/O 监控命令前,我们需要了解磁盘 I/O 性能监控的指标,以及每个指标的所揭示的磁盘某方面的性能.磁盘 I/O 性能监控的指标主要包括:指标 1:每秒 I/O 数(IOPS 或 tps ...
- Linux磁盘设备文件(sda,sdb,sdc…)变化问题
在Linux下往往会碰到这样的问题,磁盘的设备文件,比如/dev/sda, sdb, sdc等等在某些情况下会混乱掉,比如sda变成了sdb或者sdc变成了sdb等等,这样无形中会导致磁盘设备管理的混 ...
- Linux磁盘IO监控[zz]
磁盘 I/O 监控是 Unix/Linux 系统管理中一个非常重要的组成部分.它可以监控吞吐量.每秒 I/O 数.磁盘利用率.服务时间等信息,并且在发现异常时,发送告警信息给系统管理员,便于系统管理员 ...
- [AWS vs Azure] 云计算里AWS和Azure的探究(5) ——EC2和Azure VM磁盘性能分析
云计算里AWS和Azure的探究(5) ——EC2和Azure VM磁盘性能分析 在虚拟机创建完成之后,CPU和内存的配置等等基本上是一目了然的.如果不考虑显卡性能,一台机器最重要的性能瓶颈就是硬盘. ...
随机推荐
- axios请求时获取不到错误提示问题。
前端方面使用axios请求,由于新增时,有的条件格式填写错误.后端返回412状态码. ,axios可能封装不完善,他获取数据使状态码为4开头的统统不暴露出去,导致请求时,412这样的状态码,获取不到里 ...
- 【ASPLOS 2022】机器学习访存密集计算编译优化框架AStitch,大幅提升任务执行效率
简介: 近日,关于机器学习访存密集计算编译优化框架的论文<AStitch: Enabling A New Multi-Dimensional Optimization Space for Mem ...
- Java 定时任务技术趋势
简介:定时任务是每个业务常见的需求,比如每分钟扫描超时支付的订单,每小时清理一次数据库历史数据,每天统计前一天的数据并生成报表等等. 作者:黄晓萌(学仁) Java 中自带的解决方案 使用 Time ...
- 阿里云CDN产品经理陈章炜:边缘创新技术和落地实践
简介: CDN除了加速外,不断被赋予更多价值.在阿里云CDN推出的<极速奔跑吧 2021>首场直播中,阿里云架构师和产品经理不仅对近期阿里云发布的CDN产品最佳实践图进行了详细解读,还对C ...
- 基于 Wasm 和 ORAS 简化扩展服务网格功能
简介: 本文将介绍如何使用 ORAS 客户端将具有允许的媒体类型的 Wasm 模块推送到 ACR 注册库(一个 OCI 兼容的注册库)中,然后通过 ASM 控制器将 Wasm Filter 部署到指定 ...
- 深度解析PolarDB数据库并行查询技术
简介: 随着数据规模的不断扩大,用户SQL的执行时间越来越长,这不仅对数据库的优化能力提出更高的要求,并且对数据库的执行模式也提出了新的挑战.本文将介绍基于代价进行并行优化.并行执行的云数据库的并行查 ...
- [Blockchain] 去中心化与互联网分布式的联系与区别
去中心化和传统分布式都是多机应用,这是它们的共同之处,但是背后有着不一样的用途. 我们所理解的传统分布式及其应用可以解决两个问题:冗余备份/扩容 和 并行计算. 而去中心化应用的目的是维护不可逆转数据 ...
- 实践探讨Python如何进行异常处理与日志记录
本文分享自华为云社区<Python异常处理与日志记录构建稳健可靠的应用>,作者:柠檬味拥抱. 异常处理和日志记录是编写可靠且易于维护的软件应用程序中至关重要的组成部分.Python提供了强 ...
- EPAI手绘建模APP常用工具栏_1
1.常用工具栏 图 1 常用工具栏 (1) 撤销 (2) 重做 (3) 删除 (4) 复制 ① 选中场景中的模型后,复制按钮变成可用状态,否则变成禁用状态.可以选择多个模型一起复制. (5) 变换 图 ...
- ABAP RSA 加密
最近出现一些SAP ABAP RSA加密的需求,这里搬运一篇文章,用于学习参考. 本文链接:https://www.cnblogs.com/hhelibeb/p/14952732.html 原文标题: ...