【转载】 深度强化学习处理cartpole为什么reward很难超过200?
原贴地址:
https://www.zhihu.com/question/266493753
一直在看强化学习方面的内容,cartpole是最简单的入门实验环境,最原始的评判标准是连续100次episode的奖励均值在195以上即可认定是到达最优,说明此问题得以解决,(但是有很多的研究是没有采用这个条件的,也就是按照训练的次数固定,在一定的训练次数后看测试时的奖励均值和方差)。如果我们不按照这个评价标准来运行该环境的话,那么我们需要对gym中的某些原始设定进行修改。
----------------------------------------------------------------------------------------

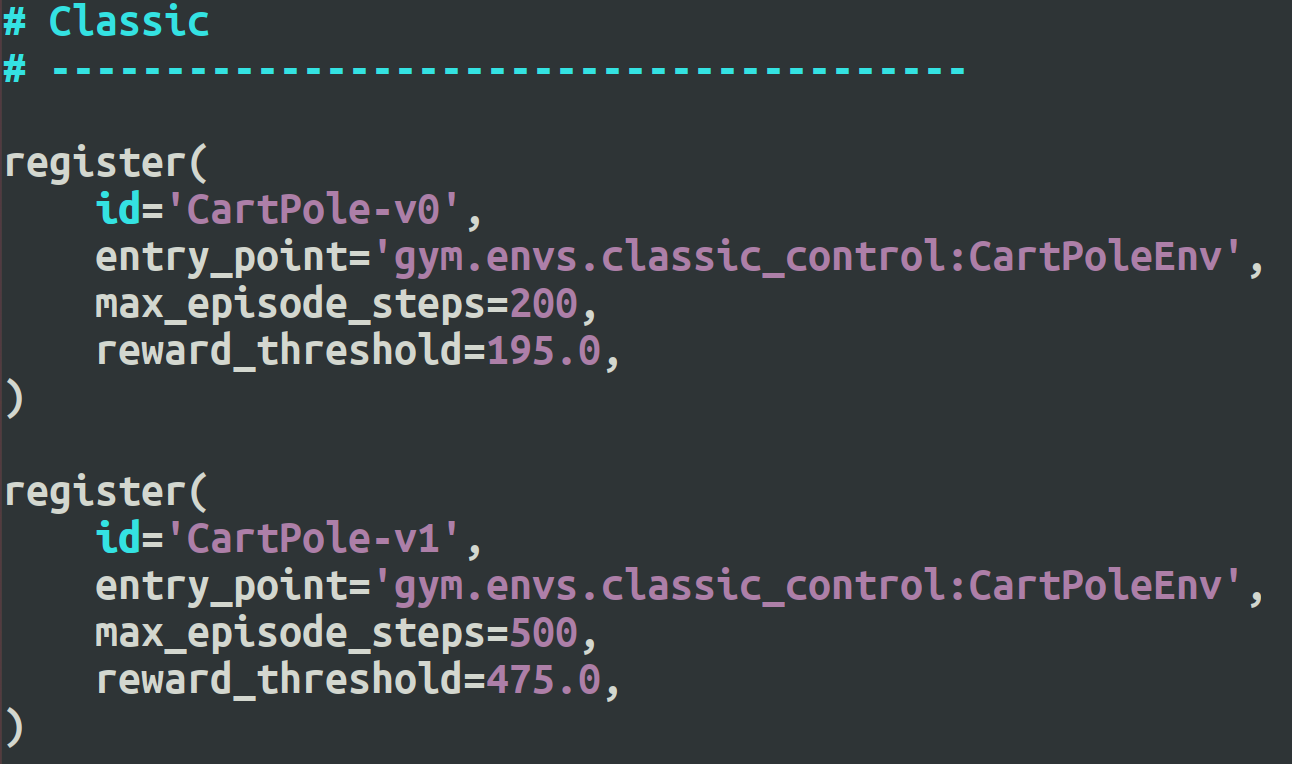
在文件gym/envs/__init__.py 中,限定了max_episode_steps
register(
id='CartPole-v0',
entry_point='gym.envs.classic_control:CartPoleEnv',
max_episode_steps=200,
reward_threshold=195.0,
)
作者:冰璐
链接:https://www.zhihu.com/question/266493753/answer/317795225
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

【转载】 深度强化学习处理cartpole为什么reward很难超过200?的更多相关文章
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 【转载】 强化学习(七)时序差分离线控制算法Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9669263.html ------------------------------------------------ ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
- 强化学习之CartPole
0x00 任务 通过强化学习算法完成倒立摆任务,控制倒立摆在一定范围内摆动. 0x01 设置jupyter登录密码 jupyter notebook --generate-config jupyt ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 【转载】 强化学习(五)用时序差分法(TD)求解
原文地址: https://www.cnblogs.com/pinard/p/9529828.html ------------------------------------------------ ...
- 深度强化学习day01初探强化学习
深度强化学习 基本概念 强化学习 强化学习(Reinforcement Learning)是机器学习的一个重要的分支,主要用来解决连续决策的问题.强化学习可以在复杂的.不确定的环境中学习如何实现我们设 ...
随机推荐
- 构建RESTful API(十八)
首先,回顾并详细说明一下在快速入门中使用的@Controller.@RestController.@RequestMapping注解.如果您对Spring MVC不熟悉并且还没有尝试过快速入门案例,建 ...
- 解决win10打开组策略弹出管理模板对话框问题
今天win10企业版更新完系统,打开组策略编辑器时弹出管理模板对话框问题 1.问题描述 打开组策略编辑器时弹出管理模板对话框问题 2.解决方法 1)window+x 打开命令提示符(管理员) 2)输入 ...
- 蓝桥杯—BASIC-19 完美的代价(贪心)
问题描述 回文串,是一种特殊的字符串,它从左往右读和从右往左读是一样的.小龙龙认为回文串才是完美的. 现在给你一个串,它不一定是回文的,请你计算最少的交换次数使得该串变成一个完美的回文串. 交换的定义 ...
- 1-3Controller之Response
控制器中的方法: public function response1(){ /*响应的常见类型: * 1.字符串 * 2.视图 * 3.json * 4.重定向 * */ //响应JSON /*$da ...
- MAVEN 创建WAR项目
MAVEN 创建WEB项目 $ mvn archetype:generate -DgroupId=com.aouo -DartifactId=myWebApp -DarchetypeArtifactI ...
- NOIP2018复赛获奖分数线及名额分配办法
中国计算机学会CCF NOI科学委员会.竞赛委员会召开会议,确定了CCF NOIP2018复赛获奖分数线及获奖名额分配方案. 提高组一等奖名额分配方案 提高组一等奖全国基准分数线: 245分 CCF ...
- go中for循环使用多个变量避坑
go for循环语法为: for expression1, expression2, expression3 { // ... } 使用多个变量时,使用平行赋值,需要留意的是expression3处的 ...
- python介绍与入门
一.python 的介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为 ...
- 在docker hub,用github的dockerfile自动生成docker镜像
简介: 我已经深深的爱上了docker技术. 在日常使用中,经常看到docker hub 中有很多autobuild的镜像.基本使用是在github中上传dockerfile,过一会儿,docker ...
- linux 基础储备
ls命令是Linux下最常用的命令之一,ls跟dos下的dir命令是一样的都是用来列出目录下的文件,下面我们就来一起看看ls的用法ls /home 这个命令不但可以添加用户到系统,而且可以默认为新用户 ...