MySQL(2)数据库 表的查询操作
来源参考https://www.cnblogs.com/whgk/p/6149009.html
跟着源博客敲一遍可以加深对数据库的理解,同时对其中一些代码做一些改变,可以验证自己的理解。
本文改动了其中的一些代码和内容,删除了其中比较简单的内容,以便于操作和理解。
一、单表查询
创建查询环境
CREATE TABLE fruits(
f_id CHAR(10) NOT NULL,
s_id INT NOT NULL,
f_name char(255) NOT NULL,
f_price DECIMAL(8,2) NOT NULL,
PRIMARY KEY(f_id)
); 解释:
f_id:主键 使用的是CHAR类型的字符来代表主键
s_id:这个其实是供应商的编号,也就是代表该水果是从哪个供应商那里过来的,写这个字段的目的是为了方便后面扩增表。
f_name:水果的名字
f_price:水果的价格,使用的是DECIMAL这个数据类型
创建结果用desc命令查看:
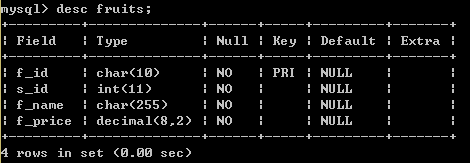
添加数据:
为了防止在cmd中直接敲打代码出错,所以新建了InsertFruits.sql文件,然后在cmd中调用:
//InsertFruits.sql INSERT INTO fruits(f_id,s_id,f_name,f_price) VALUES
('a1' , 101 , 'apple' , 5.2),
('b1' , 101 , 'blackberry' , 10.2),
('bs1' , 102 , 'orange' , 11.2),
('bs2' , 105 , 'melon' , 8.2),
('t1' , 102 , 'banana' , 10.3),
('t2' , 102 , 'grape' , 5.3),
('o2' , 103 , 'coconut' , 9.2),
('c0' , 101 , 'cherry' , 3.2),
('a2' , 103 , 'apricot' , 2.2),
('l2' , 104 , 'lemon' , 6.4),
('b2' , 104 , 'berry' , 7.6),
('m1' , 106, 'mango' , 15.6),
('m2' , 105 , 'xbabay' , 2.6),
('t4' , 107, 'xbababa' , 3.6),
('m3' , 105 , 'xxtt' , 11.6),
('b5' , 107, 'xxxx' , 3.6 );

1.1、查询所有字段
SELECT * FROM fruits;
* 代表所有字段,也就是从表中将所有字段下面的记录度查询出来

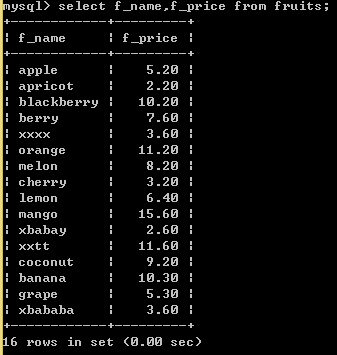
1.2、查询指定字段
SELECT f_name, f_price FROM fruits;
查询f_name 和 f_price 字段的记录
1.3、查询指定记录(where关键字)
SELECT * FROM fruits WHERE f_name = 'apple'; //将名为apple的记录的所有信息度查询出来

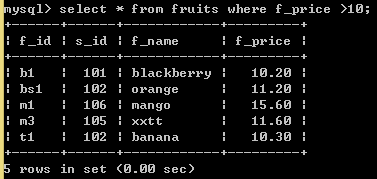
SELECT * FROM fruits WHERE f_price > 10; //将价格大于10的记录的所有字段查询出来
1.4、带IN关键字的查询
SELECT * FROM fruits WHERE f_name IN('apple','orange');

SELECT * FROM fruits WHERE s_id NOT IN(101,105); //s_id 不为101或者105的记录

IN和=的区别:
- 相同点:均在WHERE中使用作为筛选条件之一、均是等于的含义
- 不同点:IN可以规定多个值,=一次只能规定一个值,要规定多个值需要使用逻辑符号
select * from fruits where f_name in ('apple','orange');
可以转换成 = 的表达:
select * from fruits where name='apple' or name='orange';
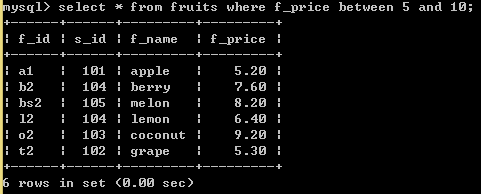
1.5、带BETWEEN AND 的范围查询
SELECT * FROM fruits WHERE f_price BETWEEN 5 AND 15; //f_price 在5到15之间,包括5和15。
1.6、带LIKE的字符匹配查询
LIKE: 相当于模糊查询,和LIKE一起使用的通配符有 "%"、"_"
"%":作用是能匹配任意长度的字符。
"_":只能匹配任意一个字符
SELECT * FROM fruits WHERE f_name LIKE 'c%'; //f_name以c字母开头的所有记录
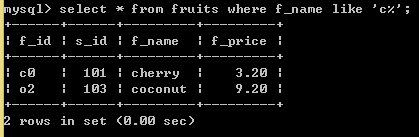
SELECT * FROM fruits WHERE f_name LIKE 'c%y'; //f_name以b字母开头,y字母结尾的所有记录
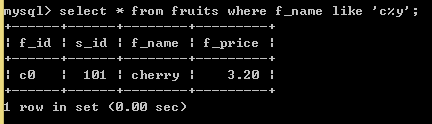
SELECT * FROM fruits WHERE f_name LIKE '____y'; //此处有四个_,说明要查询以y字母结尾并且y之前只有四

1.7、关键字DISTINCT(查询结果不重复)
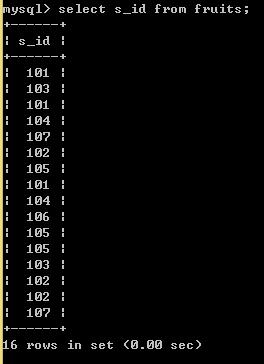
SELECT s_id FROM fruits; //查询所有的s_id,会出现很多重复的值。
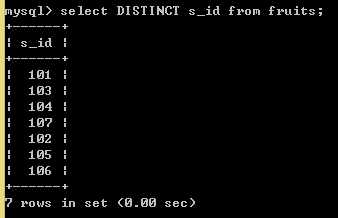
SELECT DISTINCT s_id FROM fruits;//使用DISTINCT就能消除重复的值
1.8、对查询结果排序(ORDER BY)
SELECT DISTINCT s_id FROM fruits ORDER BY s_id; //默认就是升序,使用降序时用SELECT DISTINCT s_id FROM fruits ORDER BY s_id DESC;
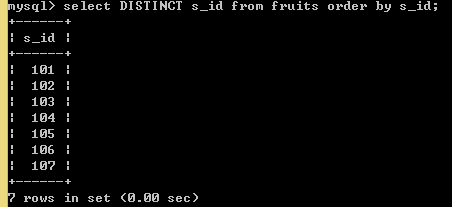
1.9 、分组查询(GROUP BY)
不分组时查询s_id,会出现一些重复的值

SELECT s_id FROM fruits GROUP BY s_id; //将s_id进行分组,有实际意义,按s_id进行分组,从101批发商这里拿的水果度会放在101这个组中
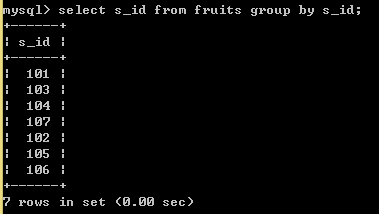
SELECT s_id, COUNT(f_name), GROUP_CONCAT(f_name) FROM fruits GROUP BY s_id; //
将s_id分组后,就没有重复的值了,因为重复的度被分到一个组中去了,现在在来看看每个组中有多少个值
COUNT():作用是计算每个组中有多少条记录,
GROUP_CONCAT(): 将分组中的各个字段的值显示出来。concat本来是连接两个或者多个字符,这里GROUP_CONCAT(f_name)就是将这些水果名连接在一起

SELECT s_id, COUNT(f_name), GROUP_CONCAT(f_name), GROUP_CONCAT(f_price) FROM fruits GROUP BY s_id; //这里显示多个列的连接

分组之后还可以进行条件过滤,将不想要的分组丢弃,使用关键字 HAVING SELECT s_id,COUNT(f_name),GROUP_CONCAT(f_name) FROM fruits GROUP BY s_id HAVING COUNT(f_name) > 1;//他能够过s_id分组,然后过滤出水果种类大于1的分组信息。
总结:HAVING和WHERE都是进行条件过滤的,区别就在于 WHERE 是在分组之前进行过滤,而HAVING是在分组之后进行条件过滤。
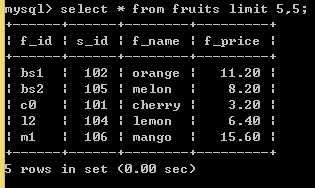
1.13、使用LIMIT限制查询结果的数量
语法:
LIMIT[位置偏移量] 行数
SELECT * FROM fruits LIMIT 5,5; //从第5条数据开始,往后取5条数据,也就是从第6条到第10条
二、多表查询
搭建查询环境,前面已经有一张表了,现在在增加一张suppliers(供应商)表和前面哪个fruits表创建练习,也就是说让fruits中s_id字段值指向suppliers的主键值,创建一个外键约束关系。
CREATE TABLE suppliers(
s_id INT NOT NULL,
s_name CHAR(50) NOT NULL,
s_city CHAR(50) NULL,
s_zip CHAR(10) NULL,
s_call CHAR(50) NOT NULL,
PRIMARY KEY(s_id)
); //在某个目录下新建一个suppliers.sql的文件
mysql> source C:\web\mysql-8.0.13\CommandCreateTables\suppliers.sql;// 创建一个suppliers新表
INSERT INTO suppliers(s_id,s_name,s_city,s_zip,s_call)VALUES
(101,'Supplies A','Tianjin','',''),
(102,'Supplies B','Chongqing','',''),
(103,'Supplies C','Shanghai','',''),
(104,'Supplies D','Zhongshan','',''),
(105,'Supplies E','Taiyuang','',''),
(106,'Supplies F','Beijing','',''),
(107,'Supplies G','Zhengzhou','','');
mysql> source C:\web\mysql-8.0.13\CommandCreateTables\InsertSuppliers.sql ;//插入数据
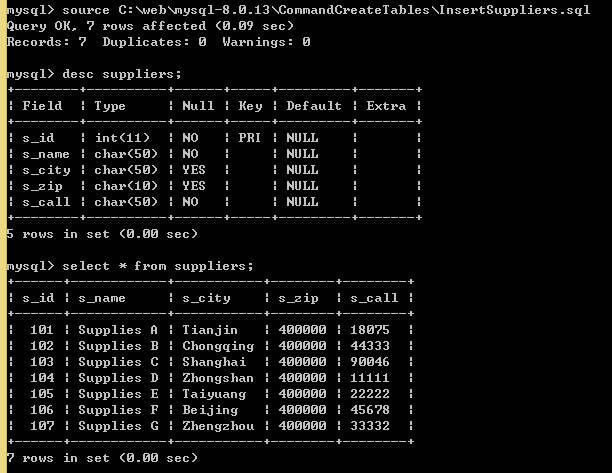
2.1、普通双表连接查询
问题:查询水果的批发商编号(s_id),批发商名字(s_name),水果名称(f_name),水果价格(f_price)。
分析:需要查询两张表。如果需要查询两张表,那么两张表的关系必定是外键关系,或者类似于外键关系(类似于也就是说两张表并没有真正加外键约束,但是其特点和外键是一样的,就像上面我们手动创建的两张表一样,虽然没有设置外键关联关系,但是其特性跟外键关系是一样的,都存在s_id字段,这样两张表就联系起来了。)
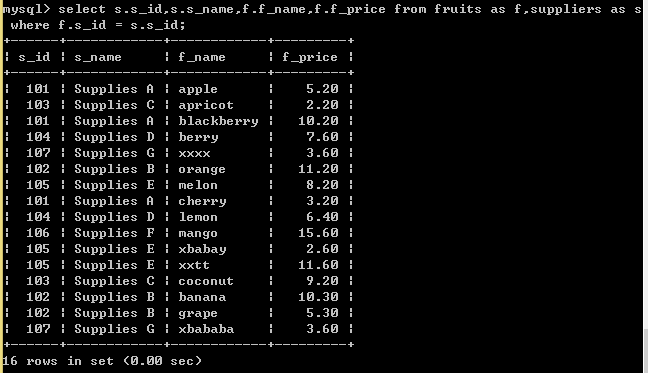
SELECT s.s_id,s.s_name,f.f_name,f.f_price FROM fruits AS f, suppliers AS s WHERE f.s_id = s.s_id; //执行逻辑和顺序:SELECT s.s_id,
/s.s_name,f.f_name,f.f_price(选择其中两个表中的各两个字段,使用别名来进行访问)
//FROM (fruits AS f取别名为了简单好记), suppliers AS s(取别名) WHERE f.s_id = s.s_id; 附:sql执行顺序 (1)from 2) on (3) join (4) where (5)group by (6) avg,sum.... (7)having (8) select (9) distinct (10) order by
也就是说,我们每次执行的SQL语句,都是从FROM开始的。
2.2、内连接查询
格式:表名 INNER JOIN 表名 ON 连接条件 SELECT s.s_id,s.s_name,f.f_name,f.f_price
FROM fruits AS f INNER JOIN suppliers AS s
ON f.s_id = s.s_id; //跟2.1的作用是一样的

JOIN :基于两个或多个表之间的共同字段,把这些表符合条件的所有行结合起来,从而查询到需要的信息。
比如上述问题:查询水果的供应商编号,供应商名字,水果名称,水果价格
自连接查询:涉及到的两张表是同一张表。
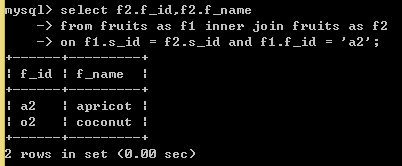
问题:查询供应f_id='a2'的水果供应商提供的其他水果种类?
SELECT f2.f_id,f2.f_name
FROM fruits AS f1 INNER JOIN fruits AS f2
ON f1.s_id = f2.s_id AND f1.f_id = 'a2';
2.3、外连接查询
2.3.1、左外连接查询
不仅会显示共有的,还会把table1的其他行也列出来(如图绿色部分)。如果,右表没有匹配的,则以NULL显示。
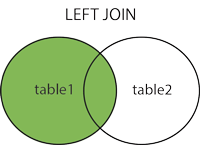
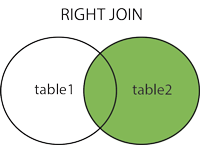
2.3.2、右外连接查询
2.4 子查询
带ANY、SOME关键字的子查询;
带ALL关键字的子查询;
带EXISTS关键字的子查询;
带IN关键字的子查询;
搭建环境
CREATE TABLE tb11 (num1 INT NOT NULL);
CREATE TABLE tb12 (num2 INT NOT NULL);
INSERT INTO tb11 VALUES(1),(5),(13),(27);
INSERT INTO tb12 VALUES(6),(14),(11),(20);
ANY关键字接在一个比较操作符的后面,表示若与子查询返回的任何值比较为TRUE,则返回TRUE,通俗点讲,只要满足任意一个条件,就返回TRUE。 SELECT num1 FROM tb11 WHERE num1 > ANY(SELECT num2 FROM tb12);//这里就是将在tb12表中查询的结果放在前一个查询语句中充当条件参数。
//只要num1大于其结果中的任意一个数,那么就算匹配。
//下图解析:num2中的值为6,14,11,20;num1中13大于6,27大于num2中所有数,所以取出num1中的这两个数
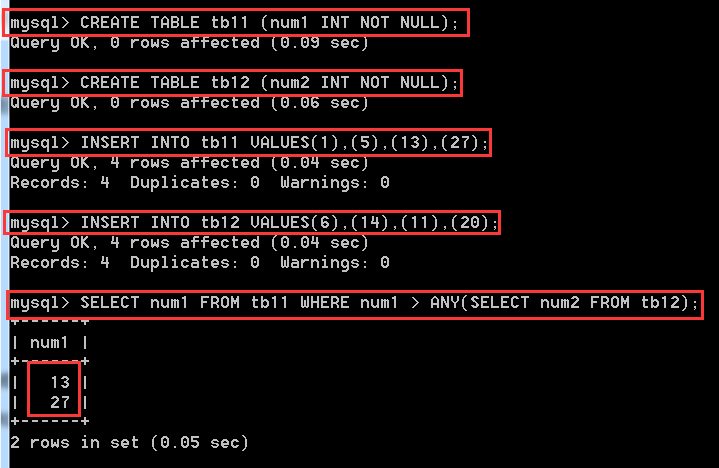
使用ALL时表示需要同时满足所有条件。
SELECT num1 FROM tb11 WHERE num1 > ALL(SELECT num2 FROM tb12); //num1需要大于所有的查询结果才算匹配
SLEECT * FROM tb11 WHERE EXISTS(SELECT * FROM tb12 WHERE num2 = 3); //查询tb12中有没有num2=3的记录,有的话则会将tb11的所有记录查询出来,没有的话,不做查询
这个IN关键字的作用跟上面单表查询的IN是一样的,不过这里IN中的参数放的是一个子查询语句。
SELECT s_id,f_id,f_name
FROM fruits
WHERE s_id IN(SELECT s_id FROM suppliers WHERE s_id = 107);
具体实例类似,不赘述。
MySQL(2)数据库 表的查询操作的更多相关文章
- MySQL(三) 数据库表的查询操作【重要】
序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VARCHAR.BLOB,等), 本节比较重要,对数据表数据进行查询操作,其中可能大家不熟悉的就对 ...
- mysql数据库表的查询操作-总结
转自:https://www.cnblogs.com/whgk/p/6149009.html 序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VA ...
- 最全MySQL数据库表的查询操作
序言 1.MySQL表操作(创建表,查询表结构,更改表字段等), 2.MySQL的数据类型(CHAR.VARCHAR.BLOB,等), 本节比较重要,对数据表数据进行查询操作,其中可能大家不熟悉的就对 ...
- mysql基础-数据库表简单查询-记录(五)
0x01 MySQL的查询操作 单表查询:简单查询 多表查询:连续查询 联合查询 选择和投影 投影:挑选要符合的字段 select ...
- MySql数据库表的查询操作
http://www.cnblogs.com/whgk/p/6149009.html 优化:http://www.ihref.com/read-16422.html MYSQL常用的几种连接查询方法
- MySQL创建数据库/表等基本命令操作
前提:安装好MySQL并且配置好服务,能够正常使用 按住键盘上的Windows图标,通过搜索框找到MySQL5.7 Command Line Client,点击启动 输入安装时设置用户的密码 成功连接 ...
- mysql(三) 数据表的基本操作操作
mysql(三) 数据表的基本操作操作 创建表,曾删改查,主键,外键,基本数据类型. 1. 创建表 create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGIN ...
- MySQL查看数据库表容量大小
本文介绍MySQL查看数据库表容量大小的命令语句,提供完整查询语句及实例,方便大家学习使用. 1.查看所有数据库容量大小 select table_schema as '数据库', sum(table ...
- MySQL更改数据库表的存储引擎
MySQL更改数据库表的存储引擎 1.查看表的原存储引擎 show create table user; 'user', 'CREATE TABLE `user` (\n `id` int(11) N ...
随机推荐
- PostgreSQL常用函数
1.系统信息函数 1.会话信息函数 edbstore=# select current_catalog; #查询当前数据库名称 current_database ------------------ ...
- ActiveMQ 中的链表
ActiveMQ 中的消息在内存中时,以链表形式保存,以 PendingList 表示,每一个消息是 PendingNode. PendingList 主要有2种实现:OrderedPendingLi ...
- axure rp安装
axure rp安装 1◆ axure rp 文件下载 2◆创建安装目录 3◆ 安装图解 4◆汉化 替换 5◆ 使用 success 1★AxureRP 8.0安装包 2★ ...
- js 日期格式化函数(可自定义)
js 日期格式化函数 DateFormat var DateFormat = function (datetime, formatStr) { var dat = datetime; var str ...
- linux磁盘管理 文件挂载
文件挂载的概念 根文件系统之外的其他文件要想能够被访问,都必须通过"关联"到根文件系统上的某个系统来实现,此关联操作即为"挂载",此目录即为"挂载点& ...
- SpringWeb项目常用注解简单介绍
注解分为两类: 一类是使用Bean,即是把已经在xml文件中配置好的Bean拿来用,完成属性.方法的组装:比如@Autowired , @Resource,可以通过byTYPE(@Autowired) ...
- c#7的新特性
1.out关键字 //可以直接声明使用 ",out int number); 2.元组 //有点类似匿名对象的样子 //用小括号包含变量,可以当做返回值,可以当做变量赋值等 //1.当做函数 ...
- angular4-事件绑定
事件绑定语法(可以通过 (事件名) 的语法,实现事件绑定) <date-picker (dateChanged)="statement()"></date-pic ...
- MarkDown编辑器中缩进
首先,Markdown是不支持缩进的. 在Markdown里按下四个空格,就自动转入Code模式. 在Markdown里一个回车,不是分段而是换行,要两个回车,才是分段. 分段和换行的区别是:换行后, ...
- [Linux]Linux下rsync服务器和客户端配置
一.rsync简介 Rsync(remote sync)是UNIX及类UNIX平台下一款神奇的数据镜像备份软件,它不像FTP或其他文件传输服务那样需要进行全备份,Rsync可以根据数据的变化进行差异( ...