ElasticSearch入门 第七篇:分词
这是ElasticSearch 2.4 版本系列的第七篇:
- ElasticSearch入门 第一篇:Windows下安装ElasticSearch
- ElasticSearch入门 第二篇:集群配置
- ElasticSearch入门 第三篇:索引
- ElasticSearch入门 第四篇:使用C#添加和更新文档
- ElasticSearch入门 第五篇:使用C#查询文档
- ElasticSearch入门 第六篇:复合数据类型——数组,对象和嵌套
- ElasticSearch入门 第七篇:分析器
- ElasticSearch入门 第八篇:存储
- ElasticSearch入门 第九篇:实现正则表达式查询的思路
在全文搜索(Fulltext Search)中,词(Term)是一个搜索单元,表示文本中的一个词,标记(Token)表示在文本字段中出现的词,由词的文本、在原始文本中的开始和结束偏移量、以及数据类型等组成。ElasticSearch 把文档数据写到倒排索引(Inverted Index)的结构中,倒排索引建立词(Term)和文档之间的映射,索引中的数据是面向词,而不是面向文档的。分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
在ElasticSearch引擎中,分析器的任务是分析(Analyze)文本数据,分析是分词,规范化文本的意思,其工作流程是:
- 首先,字符过滤器对分析(analyzed)文本进行过滤和处理,例如从原始文本中移除HTML标记,根据字符映射替换文本等,
- 过滤之后的文本被分词器接收,分词器把文本分割成标记流,也就是一个接一个的标记,
- 然后,标记过滤器对标记流进行过滤处理,例如,移除停用词,把词转换成其词干形式,把词转换成其同义词等,
- 最终,过滤之后的标记流被存储在倒排索引中;
- ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
可见,分析器扮演的是处理索引数据和查询条件的重要角色。在2.4版本中,ElasticSearch 预定义了7个分析器,并且支持用户根据预定义的字符过滤器,分词器和标记过滤器创建自定义的分析器,以满足用户多样性的文本分析需求。
用户在创建索引时配置索引的分析,通过向ElasticSearch发送请求,在请求body的settings 配置节中设置索引的分析器,例如,为索引配置默认的分析器:
"settings":{
"index":{
"analysis":{
"analyzer":{
"default":{
"type":"standard"
,"stopwords":"_english_"
}
}
}
}
}
一,字符过滤器(Char Filter)
字符过滤器对未经分析的文本起作用,作用于被分析的文本字段(该字段的index属性为analyzed),字符过滤器在分词器之前工作,用于从文档的原始文本去除HTML标记(markup),或者把字符“&”转换为单词“and”。ElasticSearch 2.4版本内置3个字符过滤器,分别是:映射字符过滤器(Mapping Char Filter)、HTML标记字符过滤器(HTML Strip Char Filter)和模式替换字符过滤器(Pattern Replace Char Filter)。
1,映射字符过滤器
映射字符过滤器,类型是mapping,需要建立一个查找字符和替换字符的映射(Mapping),过滤器根据映射把文本中的字符替换成指定的字符。
{
"index" : {
"analysis" : {
"char_filter" : {
"my_mapping" : {
"type" : "mapping",
"mappings" : [
"ph => f",
"qu => k"
]
}
},
"analyzer" : {
"custom_with_char_filter" : {
"tokenizer" : "standard",
"char_filter" : ["my_mapping"]
}
}
}
}
}
2,HTML标记字符过滤器
HTML标记字符过滤器,类型是html_strip,用于从原始文本中去除HTML标记。
3,模式替换字符过滤器
模式替换字符过滤器,类型是pattern_replace,它使用正则表达式(Regular Expression)匹配字符,把匹配到的字符替换为指定的替换字符串。
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
pattern参数:指定Java正则表达式;
replacement参数:指定替换字符串,把正则表达式匹配的字符串替换为replacement参数指定的字符串;
二,分词器(Tokenizer)
分词器在字符过滤器之后工作,用于把文本分割成多个标记(Token),一个标记基本上是词加上一些额外信息,分词器的处理结果是标记流,它是一个接一个的标记,准备被过滤器处理。ElasticSearch 2.4版本内置很多分词器,本节简单介绍常用的分词器。
1,标准分词器(Standard Tokenizer)
标准分词器类型是standard,用于大多数欧洲语言,使用Unicode文本分割算法对文档进行分词。
2,字母分词器(Letter Tokenizer)
字符分词器类型是letter,在非字母位置上分割文本,这就是说,根据相邻的词之间是否存在非字母(例如空格,逗号等)的字符,对文本进行分词,对大多数欧洲语言非常有用。
3,空格分词器(Whitespace Tokenizer)
空格分词类型是whitespace,在空格处分割文本
4,小写分词器(Lowercase Tokenizer)
小写分词器类型是lowercase,在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
5,经典分词器(Classic Tokenizer)
经典分词器类型是classic,基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好。
三,标记过滤器(Token Filter)
分析器包含零个或多个标记过滤器,标记过滤器在分词器之后工作,用来处理标记流中的标记。标记过滤从分词器中接收标记流,能够删除标记,转换标记,或添加标记。ElasticSearch 2.4版本内置很多标记过滤器,本节简单介绍常用的过滤器。
1,小写标记过滤器(Lowercase)
类型是lowercase,用于把标记转换为小写形式,通过language参数指定语言,小写标记过滤器支持的语言有:Greek, Irish, and Turkish
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myGreekLowerCaseFilter]
char_filter : [my_html]
tokenizer :
myTokenizer1 :
type : standard
max_token_length :
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myGreekLowerCaseFilter :
type : lowercase
language : greek
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead :
2,停用词标记过滤器(Stopwords)
类型是stop,用于从标记流中移除停用词。参数stopwords用于指定停用词,ElasticSearch 2.4版本提供的预定义的停用词列表:预定义的英语停用词是_english_,使用预定义的英语停用词列表是 “stopwords” :"_english_"
PUT /my_index
{
"settings": {
"analysis": {
"filter": {
"my_stop": {
"type": "stop",
"stopwords": ["and", "is", "the"]
}
}
}
}
}
3,词干过滤器(Stemmer)
类型是stemmer,用于把词转换为其词根形式存储在倒排索引,能够减少标记。
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"tokenizer" : "standard",
"filter" : ["standard", "lowercase", "my_stemmer"]
}
},
"filter" : {
"my_stemmer" : {
"type" : "stemmer",
"name" : "english"
}
}
}
}
}
4,同义词过滤器(Synonym)
类型是synonym,在分析阶段,基于同义词规则,把词转换为其同义词存储在倒排索引中
{
"index" : {
"analysis" : {
"analyzer" : {
"synonym" : {
"tokenizer" : "whitespace",
"filter" : ["synonym"]
}
},
"filter" : {
"synonym" : {
"type" : "synonym",
"synonyms_path" : "analysis/synonym.txt"
}
}
}
}
}
同义词文件的格式示例:
# Blank lines and lines starting with pound are comments. # Explicit mappings match any token sequence on the LHS of "=>"
# and replace with all alternatives on the RHS. These types of mappings
# ignore the expand parameter in the schema.
# Examples:
i-pod, i pod => ipod,
sea biscuit, sea biscit => seabiscuit # Equivalent synonyms may be separated with commas and give
# no explicit mapping. In this case the mapping behavior will
# be taken from the expand parameter in the schema. This allows
# the same synonym file to be used in different synonym handling strategies.
# Examples:
ipod, i-pod, i pod
foozball , foosball
universe , cosmos # If expand==true, "ipod, i-pod, i pod" is equivalent
# to the explicit mapping:
ipod, i-pod, i pod => ipod, i-pod, i pod
# If expand==false, "ipod, i-pod, i pod" is equivalent
# to the explicit mapping:
ipod, i-pod, i pod => ipod # Multiple synonym mapping entries are merged.
foo => foo bar
foo => baz
# is equivalent to
foo => foo bar, baz
四,系统预定义的分析器
在创建索引映射时引用分析器,如果没有定义分析器,那么ElasticSearch将使用默认的分析器,用户可以通过API设置默认的分析器。
default 逻辑名称用于配置在索引和搜索时使用的分析器,default_search 逻辑名称用于配置在搜索时使用的分析器。
index :
analysis :
analyzer :
default :
tokenizer : keyword
1,标准分析器(Standard)
分析器类型是standard,由标准分词器(Standard Tokenizer),标准标记过滤器(Standard Token Filter),小写标记过滤器(Lower Case Token Filter)和停用词标记过滤器(Stopwords Token Filter)组成。参数stopwords用于初始化停用词列表,默认是空的。
2,简单分析器(Simple)
分析器类型是simple,实际上是小写标记分词器(Lower Case Tokenizer),在非字母位置上分割文本,并把分词转换为小写形式,功能上是Letter Tokenizer和 Lower Case Token Filter的结合(Combination),但是性能更高,一次性完成两个任务。
3,空格分析器(Whitespace)
分析器类型是whitespace,实际上是空格分词器(Whitespace Tokenizer)。
4,停用词分析器(Stopwords)
分析器类型是stop,由小写分词器(Lower Case Tokenizer)和停用词标记过滤器(Stop Token Filter)构成,配置参数stopwords 或 stopwords_path指定停用词列表。
5,雪球分析器(Snowball)
分析器类型是snowball,由标准分词器(Standard Tokenizer),标准过滤器(Standard Filter),小写过滤器(Lowercase Filter),停用词过滤器(Stop Filter)和雪球过滤器(Snowball Filter)构成。参数language用于指定语言。
{
"index" : {
"analysis" : {
"analyzer" : {
"my_analyzer" : {
"type" : "snowball",
"language" : "English"
}
}
}
}
}
6,自定义分析器
分析器类型是custom,允许用户定制分析器。参数tokenizer 用于指定分词器,filter用于指定过滤器,char_filter用于指定字符过滤器。
index :
analysis :
analyzer :
myAnalyzer2 :
type : custom
tokenizer : myTokenizer1
filter : [myTokenFilter1, myTokenFilter2]
char_filter : [my_html]
position_increment_gap:
tokenizer :
myTokenizer1 :
type : standard
max_token_length :
filter :
myTokenFilter1 :
type : stop
stopwords : [stop1, stop2, stop3, stop4]
myTokenFilter2 :
type : length
min :
max :
char_filter :
my_html :
type : html_strip
escaped_tags : [xxx, yyy]
read_ahead :
五,查询分析
在分析(_ayalyze)端点上执行分析查询,用于对查询参数进行分析,并返回分析的结果
1,使用默认的分析器执行查询分析
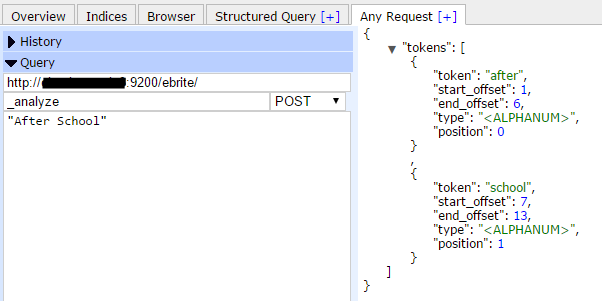
例如,在索引ebrite上执行分析查询,分析字符“After School”,从返回的结果中,可以看到两个标记(Token):“after”和“school”,类型(type)是字符数字类型(<ALPHANUM>),偏移量(offset)从1开始计数,位置(position)从0开始计数。
POST myindex/_analyze -d
"After School"
2,指定分析器
POST myindex/_analyze?analyzer=standard -d
"After School"

3,指定分词器和过滤器
POST myindex/_analyze?tokenizer=standard&filters=lowercase -d
"After School"
4,在特定的字段上执行分析查询
POST myindex/_analyze?field=doc_field&tokenizer=standard&filters=lowercase -d
"After School"
附,在创建索引时,指定默认的分析器
示例代码,使用PUT动词,在创建索引时指定默认的分析器,ElasticSearch引擎在索引文档时,使用默认的分析器对index属性为analyzed的文本字段执行分析操作,而非分析字段,将不会应用分析操作。
{
"settings":{
"number_of_shards":,
"number_of_replicas":,
"index":{
"analysis":{
"analyzer":{
"default":{
"type":"standard"
,"stopwords":"_english_"
}
}
}
}
},
"mappings":{
"events":{
"dynamic":"false",
"properties":{
"eventid":{
"type":"long",
"store":false,
"index":"not_analyzed"
},
"eventname":{
"type":"string",
"store":false,
"index":"analyzed",
"fields":{
"raw":{
"type":"string",
"store":false,
"index":"not_analyzed"
}
}
}
}
}
}
}
参考文档:
Elasticsearch: Analyzing Text with the Analyze API
Elasticsearch: The Definitive Guide [2.x] » Dealing with Human Language
Elasticsearch Reference [2.4] » Analysis
ElasticSearch入门 第七篇:分词的更多相关文章
- ElasticSearch入门 第八篇:存储
这是ElasticSearch 2.4 版本系列的第八篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第三篇:索引
这是ElasticSearch 2.4 版本系列的第三篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第六篇:复合数据类型——数组,对象和嵌套
这是ElasticSearch 2.4 版本系列的第六篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第五篇:使用C#查询文档
这是ElasticSearch 2.4 版本系列的第五篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第四篇:使用C#添加和更新文档
这是ElasticSearch 2.4 版本系列的第四篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- 《ElasticSearch入门》一篇管够,持续更新
一.顾名思义: Elastic:灵活的:Search:搜索引擎 二.官方简介: Elasticsearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTf ...
- ElasticSearch入门 第一篇:Windows下安装ElasticSearch
这是ElasticSearch 2.4 版本系列的第一篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第九篇:实现正则表达式查询的思路
这是ElasticSearch 2.4 版本系列的第九篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- ElasticSearch入门 第二篇:集群配置
这是ElasticSearch 2.4 版本系列的第二篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
随机推荐
- MySql之存储过程的使用
一:创建存储过程 1:简单存储过程 CREATE PROCEDURE 存储过程名() BEGIN SQL操作 END; 2:使用参数的存储过程 CREATE PROCEDURE 存储过程名(IN in ...
- MySql之修改操作与进阶
一:更新特定行 UPDATE tableName SET 列名 = 值,列名 = 值... WHERE 条件; 二:使用子查询更新数据 UPDATE tableName SET 列名 = SELECT ...
- git代码统计
1.统计一段时间的代码量 git log --format='%aN' | sort -u | while read name; do echo -en "$name\t"; gi ...
- 第一部分:开发前的准备-第八章 Android SDK与源码下载
第8章 Android SDK与源码下载 如果你是新下载的SDK,请阅读一下步骤了解如何设置SDK.如果你已经下载使用过SDK,那么你应该使用AVD Manager,来更新即可. 下面是构建Andro ...
- 每日英语:How To Survive The Windows XPiration Date
The default background for Microsoft's Windows XP operating system -- a perfect blue sky full of cot ...
- 【iCore1S 双核心板_ARM】例程二:读取ARM按键状态
实验原理: 按键的一端与STM32的GPIO(PB9)相连,且PB9外接一个1k大小的限流上接电阻. 初始化时把PB9设置成输入模式,当按键弹起时,PB9由于上拉电阻的作用呈高电平(3.3V): 当按 ...
- 【Unity】讯飞语音识别SDK
1.进入讯飞官网,注册帐号,进入控制台,创建新应用UnityXunfeiDemo,平台选Android.在当前应用这点下载SDK,添加AI能力(添加新服务),选择语音听写,即可下载安卓SDK(下称讯飞 ...
- Spring Mvc 入门Demo
1.web.xml配置 <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns=" ...
- 【转】Spring Framework灰度发布
今天简单介绍下SpringFramework微服务中几种服务发布策略以及实现方式.我接触过的有蓝绿.滚筒和灰度发布. 蓝绿发布: 简单说就像美帝选总统投票一样,非蓝即绿一刀切,这个其实也是传统软件架构 ...
- Ubuntu下CUDA8.0卸载
Ubuntu下CUDA8.0卸载 https://www.jianshu.com/p/45e07114463a 由于目前CUDA9.0已经发布,很多朋友需要升级,而在升级前需要卸载CUDA8.0,方法 ...