03 flask数据库操作、flask-session、蓝图
ORM
ORM 全拼Object-Relation Mapping,中文意为 对象-关系映射。主要实现模型对象到关系数据库数据的映射。
1.优点 :
只需要面向对象编程, 不需要面向数据库编写代码.
对数据库的操作都转化成对类属性和方法的操作.
不用编写各种数据库的
sql语句.
实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异.
不再需要关注当前项目使用的是哪种数据库。
通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
2.缺点 :
相比较直接使用SQL语句操作数据库,有性能损失.
根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
Flask-SQLAlchemy
flask默认提供模型操作,但是并没有提供ORM,所以一般开发的时候我们会采用flask-SQLAlchemy模块来实现ORM操作。
SQLAlchemy是一个关系型数据库框架,它提供了高层的 ORM 和底层的原生数据库的操作。
flask-sqlalchemy 是一个简化了 SQLAlchemy 操作的flask扩展。
SQLAlchemy文档: https://www.sqlalchemy.org/
1.安装 flask-sqlalchemy
pip install flask-sqlalchemy
如果连接的是 mysql 数据库,需要安装 mysqldb 驱动
pip install flask-mysqldb
2.数据库连接设置
1. settings/dev.py 配置文件中配置如下信息
import redis
class DevConfig(object): DEBUG = True
SECRET_KEY = 'xiakeyun' # session 秘钥 # 数据库配置
# '数据库类型://账号:密码@数据库IP:端口/数据库名'
SQLALCHEMY_DATABASE_URI = 'mysql://root:123@127.0.0.1:3306/flaskdemo'
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = True
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = True # session存储数据到redis的配置
SESSION_TYPE = 'redis' # session类型为redis
SESSION_PERMANENT = False # 如果设置为True,则关闭浏览器session就失效。
SESSION_USE_SIGNER = False # 是否对发送到浏览器上session的cookie值进行加密
SESSION_KEY_PREFIX = 'session:' # 保存到session中的值的前缀
SESSION_REDIS = redis.Redis(host='127.0.0.1', port='') # 用于连接redis的配置
2.配置完成需要去 MySQL 中创建项目所使用的数据库
$ mysql -uroot -p123456 # 连接数据库
$ create database flaskdemo charset=utf8; # 创建数据库名为flaskdemo
3. 模型表
from flask import Flask
from flask_sqlalchemy import SQLAlchemy from settings.dev import DevConfig app = Flask(__name__) app.config.from_object(DevConfig) db = SQLAlchemy(app) class Role(db.Model):
# 定义表名
__tablename__ = 'roles' # 定义表名
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
# 设置外键[用于1查询多的情况]
us = db.relationship('User', backref='role',lazy='dynamic')
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'Role:%s'% self.name # 创建数据模型必须继承db.Model
class User(db.Model):
# 表选项
__tablename__ = 'users' # 设置表名
# 声明字段
# db.Column(字段类型,选项)
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(64),unique=True)
born = db.Column(db.Date, index=True)
email = db.Column(db.String(64), unique=True)
password = db.Column( db.String(64) )
# 设置外键
role_id = db.Column(db.Integer, db.ForeignKey("roles.id")) # __repr__方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'User:%s'% self.name # 创建表
# db.create_all() # 需要放在模型表之后
# 删除表
# db.drop_all()
if __name__ == '__main__':
app.run(host='127.0.0.1',port=80)
数据库基本操作
在Flask-SQLAlchemy中,插入、修改、删除操作,均由数据库会话管理。
会话用 db.session 表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用 commit() 方法提交会话。
在 Flask-SQLAlchemy 中,查询操作是通过 query 对象操作数据。
最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
1. 创建表
db.create_all() # 注意,create_all()方法执行的时候,需要放在模型的后面
2.删除表
db.drop_all()
3. 添加数据
1. 添加一条数据
role =Role(name='实习生')
db.session.add(role)
db.session.commit()
2. 添加多条数据
us1 = User(name='liu', email='liu@163.com', password='', role_id=2)
us2 = User(name='li', email='li@163.com', password='', role_id=3)
us3 = User(name='sun', email='sun@163.com', password='', role_id=2)
db.session.add_all([us1,us2,us3])
db.session.commit()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy from settings.dev import DevConfig app = Flask(__name__) app.config.from_object(DevConfig) db = SQLAlchemy(app) class Role(db.Model):
# 定义表名
__tablename__ = 'roles' # 定义表名
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
# 设置外键[用于1查询多的情况]
us = db.relationship('User', backref='role',lazy='dynamic')
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'Role:%s'% self.name # 创建数据模型必须继承db.Model
class User(db.Model):
# 表选项
__tablename__ = 'users' # 设置表名
# 声明字段
# db.Column(字段类型,选项)
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(64),unique=True)
born = db.Column(db.Date, index=True)
email = db.Column(db.String(64), unique=True)
password = db.Column( db.String(64) )
# 设置外键
role_id = db.Column(db.Integer, db.ForeignKey("roles.id")) # __repr__方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'User:%s'% self.name # 创建表
# db.create_all()
# 删除表
# db.drop_all()
# 删除表
@app.route('/add')
def add():
#数据库的基本操作 role =Role(name='实习生')
db.session.add(role)
db.session.commit() role = Role(name='正式员工')
db.session.add(role)
db.session.commit() role = Role(name='优秀员工')
db.session.add(role)
db.session.commit()
#
user = User(name='xiaoming',email='123@qq.com',password='',role_id=1)
us1 = User(name='wang', email='wang@163.com', password='', role_id=1)
us2 = User(name='zhang', email='zhang@189.com', password='', role_id=3)
us3 = User(name='chen', email='chen@126.com', password='', role_id=1)
us4 = User(name='zhou', email='zhou@163.com', password='', role_id=3)
us5 = User(name='tang', email='tang@163.com', password='', role_id=2)
us6 = User(name='wu', email='wu@gmail.com', password='', role_id=1)
us7 = User(name='qian', email='qian@gmail.com', password='', role_id=1)
us8 = User(name='liu', email='liu@163.com', password='', role_id=2)
us9 = User(name='li', email='li@163.com', password='', role_id=3)
us10 = User(name='sun', email='sun@163.com', password='', role_id=2)
db.session.add_all([user,us1,us2,us3,us4,us5,us6,us7,us8,us9,us10])
db.session.commit() return 'ok' if __name__ == '__main__': app.run(host='127.0.0.1',port=80)
添加数据
4 . 查询数据
1.filter_by精确查询
返回名字等于wang的所有人
User.query.filter_by(name='wang').all()
2.first()返回查询到的第一个对象
User.query.first()
3.all()返回查询到的所有对象
User.query.all()
4.filter模糊查询,返回名字结尾字符为g的所有数据。
User.query.filter(User.name.endswith('g')).all()
5.get():参数为主键,如果主键不存在没有返回内容
User.query.get(1)
6.逻辑非,返回名字不等于wang的所有数据
User.query.filter(User.name!='wang').all()
not_ 相当于取反
from sqlalchemy import not_
User.query.filter(not_(User.name=='chen')).all()
7.逻辑与,需要导入and,返回and()条件满足的所有数据
from sqlalchemy import and_
User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
8.逻辑或,需要导入or_
from sqlalchemy import or_
User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
from flask import Flask,render_template
from flask_sqlalchemy import SQLAlchemy
from sqlalchemy import or_,and_,not_
from settings.dev import DevConfig app = Flask(__name__) app.config.from_object(DevConfig) db = SQLAlchemy(app) class Role(db.Model):
# 定义表名
__tablename__ = 'roles' # 定义表名
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
# 设置外键[用于1查询多的情况]
us = db.relationship('User', backref='role',lazy='dynamic')
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'Role:%s'% self.name # 创建数据模型必须继承db.Model
class User(db.Model):
# 表选项
__tablename__ = 'users' # 设置表名
# 声明字段
# db.Column(字段类型,选项)
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(64),unique=True)
born = db.Column(db.Date, index=True)
email = db.Column(db.String(64), unique=True)
password = db.Column( db.String(64) )
# 设置外键
role_id = db.Column(db.Integer, db.ForeignKey("roles.id")) # __repr__方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'User:%s'% self.name @app.route('/query')
def query():
"""
查询所有用户数据
查询有多少个用户
查询第1个用户
查询id为4的用户[3种方式]
查询名字结尾字符为g的所有数据[开始/包含]
查询名字不等于wang的所有数据[2种方式]
查询名字和邮箱都以 li 开头的所有数据[2种方式]
查询password是 `123456` 或者 `email` 以 `163.com` 结尾的所有数据
查询id为 [1, 3, 5, 7, 9] 的用户列表
查询name为liu的角色数据
查询所有用户数据,并以邮箱排序
每页3个,查询第2页的数据 """
# 1 查询所有用户数据
users = User.query.all()
user_list =[]
for user in users:
user_list.append(
{
'name':user.name,
'email':user.name,
}
) print(user_list)
# 2 查询有多少个用户
count = User.query.count()
print(count)
# 3查询第1个用户
user1 = User.query.first() # 4 查询id为4的用户[3种方式]
# user4 = User.query.get(4)
# user4 = User.query.filter_by(id=4).all()[0] #5 查询名字结尾字符为g的所有数据[开始/包含] user = User.query.filter(User.name.startswith('z')).all()
user = User.query.filter(User.name.contains('l')).all()
# 6 查询名字不等于wang的所有数据[2种方式]
user = User.query.filter(User.name!='wang').all()
# 7 查询名字和邮箱都以 li 开头的所有数据[2种方式]
user = User.query.filter(and_(User.name.startswith('li'),User.email.startswith('li'))).all()
# for u in user:
# print(u.name,u.email) #8 查询password是 `123456` 或者 `email` 以 `163.com` 结尾的所有数据
user = User.query.filter(or_(User.password=='',User.email.endswith('163.com'))).all() # 9 查询id为 [1, 3, 5, 7, 9] 的用户列表
user = User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
# 10 查询name为liu的角色数据
user = User.query.filter_by(name='liu').all()
role = user[0].role_id
print('user.role_id',user[0].role_id) # 11 查询所有用户数据,并以邮箱排序
user = User.query.order_by(User.email).all()
# 12 11 查询所有用户数据,并以id倒序 排序
user = User.query.order_by(-User.id).all() # 13 每页3个,查询第2页的数据
# 不能接 all filter # limit表示取多少条(3条), offset 从第3+1 条开始取值
user = User.query.filter().limit(3).offset(3) # return render_template('user.html',users=users)
# return '总共有:%s用户'%count
# return '第1个用户:%s'%user1.name return '用户:%s'%[{'id':u.id,'name':u.name,'email':u.email}for u in user] if __name__ == '__main__': app.run(host='127.0.0.1',port=80)
查询更多方法
#案列:
# 5 查询名字结尾字符为g的所有数据[开始/包含] user = User.query.filter(User.name.startswith('z')).all()
user = User.query.filter(User.name.contains('l')).all()
# 6 查询名字不等于wang的所有数据[2种方式]
user = User.query.filter(User.name!='wang').all()
# 7 查询名字和邮箱都以 li 开头的所有数据[2种方式]
user = User.query.filter(and_(User.name.startswith('li'),User.email.startswith('li'))).all()
# for u in user:
# print(u.name,u.email) #8 查询password是 `123456` 或者 `email` 以 `163.com` 结尾的所有数据
user = User.query.filter(or_(User.password=='',User.email.endswith('163.com'))).all() # 9 查询id为 [1, 3, 5, 7, 9] 的用户列表
user = User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
# 10 查询name为liu的角色数据
user = User.query.filter_by(name='liu').all()
role = user[0].role_id
print('user.role_id',user[0].role_id) # 11 查询所有用户数据,并以邮箱排序
user = User.query.order_by(User.email).all()
# 12 11 查询所有用户数据,并以id倒序 排序
user = User.query.order_by(-User.id).all() # 13 每页3个,查询第2页的数据
# 不能接 all filter # limit表示取多少条(3条), offset 从第3+1 条开始取值
user = User.query.filter().limit(3).offset(3)
5.更新数据
@app.route('/delete')
def delete():
'''删除数据'''
user = User.query.get(1)
db.session.delete(user)
db.session.commit()
return 'ok'
6.删除数据
@app.route('/update')
def update():
user = User.query.get(2)
user.born = '2010-12-11'
db.session.commit()
return 'ok'

模型之间的关联
1.一对多
class Role(db.Model):
...
#关键代码
us = db.relationship('User', backref='role', lazy='dynamic')
... class User(db.Model):
...
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
其中realtionship描述了Role和User的关系。在此文中,第一个参数为对应参照的类"User"
第二个参数backref为类User申明新属性的方法
第三个参数lazy决定了什么时候SQLALchemy从数据库中加载数据
如果设置为子查询方式(subquery),则会在加载完Role对象后,就立即加载与其关联的对象,这样会让总查询数量减少,但如果返回的条目数量很多,就会比较慢
设置为 subquery 的话,role.users 返回所有数据列表
另外,也可以设置为动态方式(dynamic),这样关联对象会在被使用的时候再进行加载,并且在返回前进行过滤,如果返回的对象数很多,或者未来会变得很多,那最好采用这种方式
设置为 dynamic 的话,role.users 返回查询对象,并没有做真正的查询,可以利用查询对象做其他逻辑,比如:先排序再返回结果
2. 多对多
registrations = db.Table('registrations',
db.Column('student_id', db.Integer, db.ForeignKey('students.id')),
db.Column('course_id', db.Integer, db.ForeignKey('courses.id'))
)
class Course(db.Model):
...
class Student(db.Model):
...
courses = db.relationship('Course',secondary=registrations,
backref='students',
lazy='dynamic')
数据库迁移
在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库。最直接的方式就是删除旧表,但这样会丢失数据。
更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化,然后把变动应用到数据库中。
在Flask中可以使用Flask-Migrate扩展,来实现数据迁移。并且集成到Flask-Script中,所有操作通过命令就能完成。
为了导出数据库迁移命令,Flask-Migrate提供了一个MigrateCommand类,可以附加到flask-script的manager对象上。
首先要在虚拟环境中安装Flask-Migrate。
pip install flask-migrate
创建迁移仓库
#这个命令会创建migrations文件夹,所有迁移文件都放在里面。
python manage.py db init
创建迁移脚本
自动创建迁移脚本有两个函数
upgrade():函数把迁移中的改动应用到数据库中。
downgrade():函数则将改动删除。
自动创建的迁移脚本会根据模型定义和数据库当前状态的差异,生成upgrade()和downgrade()函数的内容。
对比不一定完全正确,有可能会遗漏一些细节,需要进行检查
python manage.py db migrate -m 'initial migration'
更新数据库
python manage.py db upgrade
返回以前的版本
可以根据history命令找到版本号,然后传给downgrade命令:
python manage.py db history 输出格式:<base> -> 版本号 (head), initial migration
回滚到指定版本:
python manage.py db downgrade # 默认返回上一个版本
python manage.py db downgrade 版本号 # 返回到指定版本号对应的版本
数据迁移的步骤:
1. 初始化数据迁移的目录
python manage.py db init
2. 数据库的数据迁移版本初始化
python manage.py db migrate -m 'initial migration'
3. 升级版本[创建表]
python manage.py db upgrade
4. 降级版本[删除表]
python manage.py db downgrade
flask-session
允许设置session到指定存储的空间中, 文档:
安装命令: https://pythonhosted.org/Flask-Session/
pip install Flask-Session
使用session之前,必须配置一下配置项:
SECRET_KEY = "xiakeyun" # session秘钥
redis基本配置:
app.config['SESSION_TYPE'] = 'redis' # session类型为redis
app.config['SESSION_PERMANENT'] = False # 如果设置为True,则关闭浏览器session就失效。
app.config['SESSION_USE_SIGNER'] = False # 是否对发送到浏览器上session的cookie值进行加密
app.config['SESSION_KEY_PREFIX'] = 'session:' # 保存到session中的值的前缀
app.config['SESSION_REDIS'] = redis.Redis(host='127.0.0.1', port='', password='') # 用于连接redis的配置 Session(app)
SQLAlchemy基本配置:
db = SQLAlchemy(app) app.config['SESSION_TYPE'] = 'sqlalchemy' # session类型为sqlalchemy
app.config['SESSION_SQLALCHEMY'] = db # SQLAlchemy对象
app.config['SESSION_SQLALCHEMY_TABLE'] = 'session' # session要保存的表名称
app.config['SESSION_PERMANENT'] = True # 如果设置为True,则关闭浏览器session就失效。
app.config['SESSION_USE_SIGNER'] = False # 是否对发送到浏览器上session的cookie值进行加密
app.config['SESSION_KEY_PREFIX'] = 'session:' # 保存到session中的值的前缀 Session(app)
以上两个配置一般统一配置到配置文件
settings/dev.py:
import redis
class DevConfig(object): DEBUG = True
SECRET_KEY = 'xiakeyun' # session 秘钥 HOST ='127.0.0.1'
PORT =80 # 数据库配置
# '数据库类型://账号:密码@数据库IP:端口/数据库名'
SQLALCHEMY_DATABASE_URI = 'mysql://root:123@127.0.0.1:3306/flaskdemo'
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = True
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = True # session存储数据到redis的配置
SESSION_TYPE = 'redis' # session类型为redis
SESSION_PERMANENT = False # 如果设置为True,则关闭浏览器session就失效。
SESSION_USE_SIGNER = False # 是否对发送到浏览器上session的cookie值进行加密
SESSION_KEY_PREFIX = 'session:' # 保存到session中的值的前缀
SESSION_REDIS = redis.Redis(host='127.0.0.1', port='') # 用于连接redis的配置
蓝图 Blueprint
1.创建蓝图的步骤:
1.创建一个蓝图目录,例如users,并在__init__.py文件中创建蓝图对象
from flask import Blueprint
users=Blueprint('users',__name__)
2. 在这个蓝图目录下, 创建views.py文件,保存当前蓝图使用的视图函数
from . import users
@users.route('/')
def index():
return '蓝图首页'
3 在users/init.py中引入views.py中所有的视图函数
from flask import Blueprint
users=Blueprint('users',__name__)
# 导入users 所有视图
from .views import *
4.在主应用manage.py文件中的app对象上注册这个users蓝图对象
from flask import Blueprint
users=Blueprint('users',__name__)
# 导入users 所有视图
from .views import *
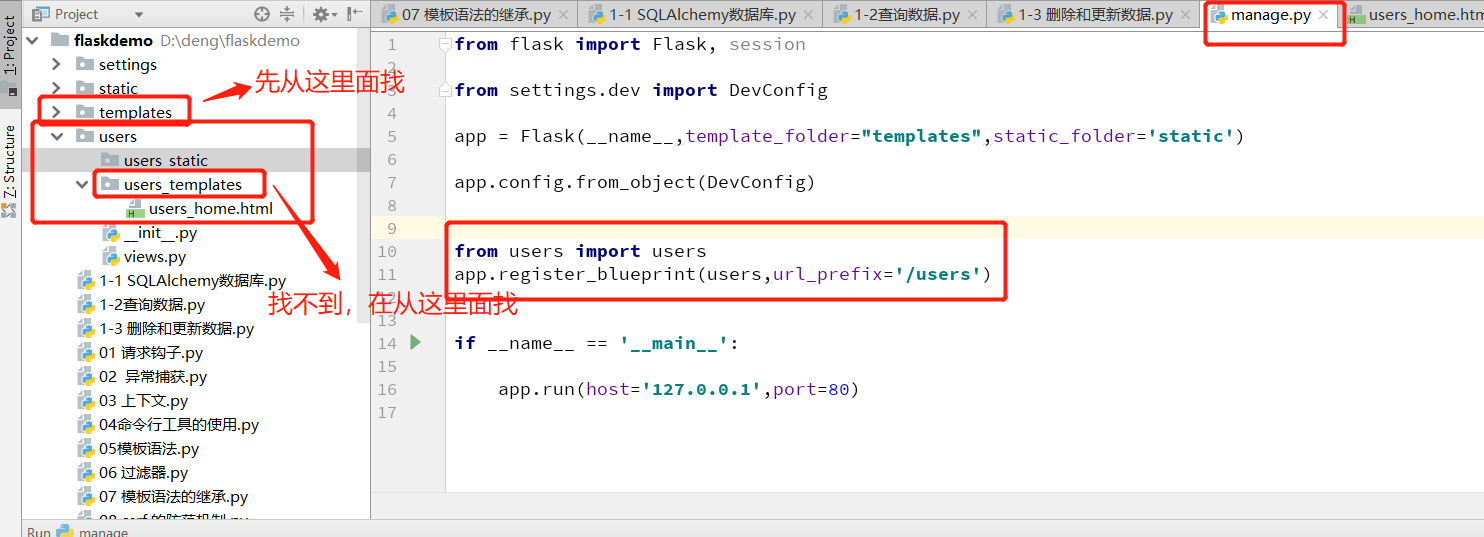
例子:
1. users/__init__.py 文件:
from flask import Blueprint
users=Blueprint('users',__name__,static_folder='users_static',template_folder='users_templates')
# 导入users 所有视图
from .views import *
2. users/views.py文件:
def index():
return '蓝图首页'
@users.route('/home')
def home():
'''
如果外层templates 中也有 home.html 文件时,会直接访问外层的home.html
外层找不到home.html文件时,才会到子应用users_templates中找,
所以需要注意文件最好不要同名
'''
# return render_template('home.html')
return render_template('users_home.html')
3.主应用 manage.py
from flask import Flask, session from settings.dev import DevConfig app = Flask(__name__,template_folder="templates",static_folder='static') app.config.from_object(DevConfig) from users import users
app.register_blueprint(users,url_prefix='/users') if __name__ == '__main__': app.run(host='127.0.0.1',port=80)
03 flask数据库操作、flask-session、蓝图的更多相关文章
- flask数据库操作
Python 数据库框架 大多数的数据库引擎都有对应的 Python 包,包括开源包和商业包.Flask 并不限制你使用何种类型的数据库包,因此可以根据自己的喜好选择使用 MySQL.Postgres ...
- 实验3、Flask数据库操作-如何使用Flask与数据库
1. 实验内容 数据库的使用对于可交互的Web应用程序是极其重要的,本节我们主要学习如何与各种主要数据库进行连接和使用,以及ORM的使用 2. 实验要点 掌握Flask对于各种主要数据库的连接方法 掌 ...
- flask 数据库操作(增删改查)
数据库操作 现在我们创建了模型,生成了数据库和表,下面来学习常用的数据库操作,数据库操作主要是CRUD,即Create(创建).Read(读取/查询).Update(更新)和Delete(删除). S ...
- MSSQL→ 03:数据库操作
一.数据库的操作 1.1.新增 使用SSMS图形界面创建数据库 在SQL Server 2008 中,通过SQL Server Management Studio 创建数据库 使用Transact-S ...
- Python框架学习之Flask中的数据库操作
数据库操作在web开发中扮演着一个很重要的角色,网站中很多重要的信息都需要保存到数据库中.如用户名.密码等等其他信息.Django框架是一个基于MVT思想的框架,也就是说他本身就已经封装了Model类 ...
- flask session,蓝图,装饰器,路由和对象配置
1.Flask 中的路由 *endpoint - url_for 反向地址 *endpoint 默认是视图函数名 *methods 指定视图函数的请求方式,默认GET defaults={& ...
- flask + pymysql操作Mysql数据库
安装flask-sqlalchemy.pymysql模块 pip install flask-sqlalchemy pymysql ### Flask-SQLAlchemy的介绍 1. ORM:Obj ...
- Flask开发系列之数据库操作
Flask开发系列之数据库操作 Python数据库框架 我们可以在Flask中使用MySQL.Postgres.SQLite.Redis.MongoDB 或者 CouchDB. 还有一些数据库抽象层代 ...
- Flask从入门到精通之MySQL数据库操作
前面的章节中我们已经学习了如何建立模型和关系,接下来我们学习如何使用模型的最好方法是在Python shell 中实际操作.并将介绍最常用的数据库操作. 一.创建表 首先,我们要让Flask-SQLA ...
随机推荐
- js 根据对象属性对数组进行按字母排序
$scope.input.sort(compare('ticked','name')); var compare = function(ticked, name){ return function(a ...
- Materialize和Material Design Lite的区别
Material Design Lite是google官方库,Materialize是第三方 Material Design Lite不依赖jquery,Materialize依赖jquery Mat ...
- cygwin如何下编译安装tmux?
1. 准备工作 1.1 安装ncurses开发库 apt-cyg install libncurses-deve 1.2 安装libevent apt-cyg install libevent-dev ...
- LeetCode - 198 简单动态规划 打家劫舍
你是一个专业的小偷,计划偷窃沿街的房屋.每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警. 给定一个代表每 ...
- 最大匹配字符串LCS,The Longest Common Substring
public enum BackTracking { UP, LEFT, NEITHER, UP_AND_LEFT } public abstract class LCSBaseMatch { /// ...
- Lintcode452-Remove Linked List Elements-Easy
Remove Linked List Elements Remove all elements from a linked list of integers that have value val. ...
- Python: find the smallest and largest value
题目要求: Write a program that repeatedly prompts a user for integer numbers until the user enters 'done ...
- 七牛云存储上传自有证书开启https访问
虽然七牛云存储也提供免费SSL证书申请,但我就喜欢用其他平台申请的,于是在腾讯云申请了免费SSL证书,正准备在七牛上传,弹出的界面却让我傻了眼,如下图所示: 腾讯免费SSL证书提供了不同服务器环境的版 ...
- 《spring boot 实战》读书笔记
前言:虽然已经用spring boot开发过一套系统,但是之前都是拿来主义,没有系统的,全面的了解过这套框架.现在通过学习<spring boot实战>这本书,希望温故知新.顺便实现自己的 ...
- php 中 public private protected的区别
public 子类,外部都可调用. protected 子类可以调用,外部不可以调用. private 子类不可以调用,外部不可以调用. <?php class AA { public func ...