Scrapy学习篇(四)之数据存储
上一篇中,我们简单的实现了toscrapy网页信息的爬取,并存储到mongo,本篇文章信息看看数据的存储。这一篇主要是实现信息的存储,我们以将信息保存到文件和mongo数据库为例,学习数据的存储,依然是上一节的例子。
编写爬虫
修改items.py文件来定义我们的item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似。虽然你也可以在Scrapy中直接使用dict,但是Item提供了额外保护机制来避免拼写错误导致的未定义字段错误。简单的来说,你所要保存的任何的内容,都需要使用item来定义,比如我们现在抓取的页面,我们希望保存名言,作者和tags, 那么你就要在items.py文件中定义他们,以后你会发现,items.py文件里面你所要填写的信息是最简单的了。
import scrapy
class QuoteItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
这样就已经定义好了。
编写spider文件
在项目中的spiders文件夹下面创建一个文件,命名为quotes.py我们将在这个文件里面编写我们的爬虫。先上代码再解释。
# -*- coding: utf-8 -*-
import scrapy
from bs4 import BeautifulSoup #新增加
from tutorial.items import QuoteItem #新增加
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = BeautifulSoup(response.text,'lxml')
for quote in quotes.find_all(name = 'div',class_='quote'):
item = QuoteItem() #使用items中定义的数据结构
for s in quote.find_all(name = 'span',class_='text'):
item['text'] = s.text
for s in quote.find_all(name= 'small',class_='author'):
item['author'] = s.text
for s in quote.find_all(name='div', class_='tags'):
item['tags'] = s.text.replace('\n','').strip().replace(' ','')
yield item
nexts = quotes.find_all(name='li', class_='next')
for next in nexts:
n = next.find(name='a')
url = 'http://quotes.toscrape.com/' + n['href']
yield scrapy.Request(url = url,callback = self.parse)
下面主要对新添加或者修改的地方讲解
- 导入QuoteItem自定义类,注意:新建项目中带有scrapy.cfg文件的那个目录默认作为项目的根目录,因此from tutorial.items import QuoteItem
就是从tutorial项目里面的items.py文件里面导入我们自定义的那个类,名称是QuoteItem,就是上面我们定义的那个QuoteItem ,只有导入了这个类,我们才可以保存我们的字段。 - item = QuoteItem() 实例化,不多说。
- item['text'] = s.text, item['author'] = s.text , item['tags'] = s.text.replace('\n','').strip().replace(' ',''), item其实就是可以简单的理解为字典,这个地方就是相当于给字典里面的键赋值。
- yield item生成器,scrapy会将item传递给pipeline进行后续的处理,当然,前提是你打开了settings设置里面的设置项,相关的设置马上就会说到。
- nexts = quotes.find_all(name='li', class_='next') 获取下一页,遍历nexts,如果有下一页,则 yield Request() ,此Request会作为一个新的Request加入调度队列,等待调度。
修改pipelines.py文件,实现保存。
class MongoPipeline(object):
def __init__(self,mongo_url,mongo_db):
self.mongo_url = mongo_url
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_url=crawler.settings.get('MONGO_URL'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
def process_item(self,item, spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
修改settings.py文件
之前,我们修改了两个内容,ROBOTSTXT_OBEY和DEFAULT_REQUEST_HEADERS,这里我们在之前的基础上,在添加如下内容。
ITEM_PIPELINES = {
'tutorial.pipelines.textPipeline':300,
'tutorial.pipelines.MongoPipeline':400
}
MONGO_URL = 'localhost'
MONGO_DB = 'test'
对于新修改的内容简单的解释,如果你仅仅想保存到txt文件,就将后者注释掉,同样的道理,如果你仅仅想保存到数据库,就将前者注释掉,当然,你可以两者都实现保存,就不用注释任何一个。对于上面的含义,tutorial.pipelines.textPipeline 其实就是应用tutorial/pipelines模块里面的textPipeline类,就是我们之前写的那个,300和400的含义是执行顺序,因为我们这里既要保存到文件,也要保存到数据库,那就定义一个顺序,这里的设置就是先执行保存到文件,在执行保存到数据库,数字是0-1000,你可以自定义。
运行爬虫
进入到项目文件,执行scrapy crawl quotes
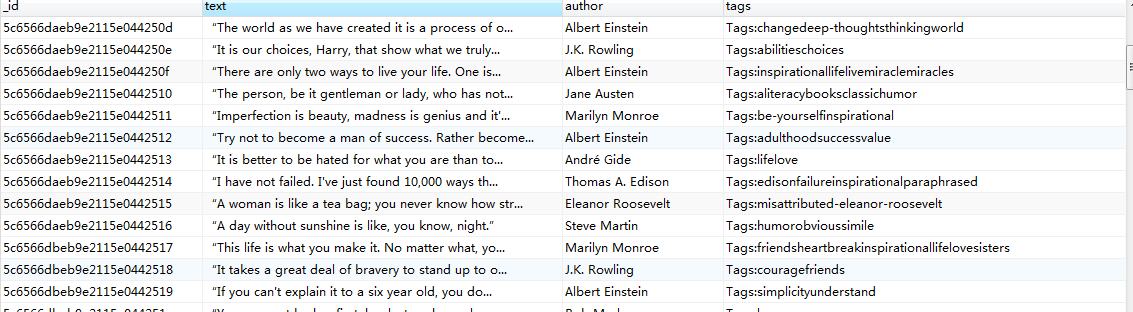
可以看到mongo数据库新增了相应的内容。
Scrapy学习篇(四)之数据存储的更多相关文章
- Scrapy学习篇(七)之Item Pipeline
在之前的Scrapy学习篇(四)之数据的存储的章节中,我们其实已经使用了Item Pipeline,那一章节主要的目的是形成一个笼统的认识,知道scrapy能干些什么,但是,为了形成一个更加全面的体系 ...
- Scrapy学习篇(十)之下载器中间件(Downloader Middleware)
下载器中间件是介于Scrapy的request/response处理的钩子框架,是用于全局修改Scrapy request和response的一个轻量.底层的系统. 激活Downloader Midd ...
- iOS开发UI篇—ios应用数据存储方式(XML属性列表-plist)
iOS开发UI篇—ios应用数据存储方式(XML属性列表-plist) 一.ios应用常用的数据存储方式 1.plist(XML属性列表归档) 2.偏好设置 3.NSKeydeArchiver归档(存 ...
- iOS开发UI篇—ios应用数据存储方式(归档)
iOS开发UI篇—ios应用数据存储方式(归档) 一.简单说明 在使用plist进行数据存储和读取,只适用于系统自带的一些常用类型才能用,且必须先获取路径相对麻烦: 偏好设置(将所有的东西都保存在同 ...
- iOS开发UI篇—ios应用数据存储方式(归档) :转发
本文转发至:文顶顶http://www.cnblogs.com/wendingding/p/3775293.html iOS开发UI篇—ios应用数据存储方式(归档) 一.简单说明 在使用plist ...
- pandas学习(四)--数据的归一化
欢迎加入python学习交流群 667279387 Pandas学习(一)–数据的导入 pandas学习(二)–双色球数据分析 pandas学习(三)–NAB球员薪资分析 pandas学习(四)–数据 ...
- iOS开发UI篇—ios应用数据存储方式(偏好设置)
iOS开发UI篇—ios应用数据存储方式(偏好设置) 一.简单介绍 很多iOS应用都支持偏好设置,比如保存用户名.密码.字体大小等设置,iOS提供了一套标准的解决方案来为应用加入偏好设置功能 每个应用 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- Android四种数据存储方式
一.SharedPreference数据存储篇 1.作用范围 (1).它是一种轻型的数据存储方式 (2).本质是基于XML文件存储key-value键值对数据 (3).通常用来存储一些简单的配置方式 ...
- IOS的四种数据存储方式及优劣
IOS有四种经常使用数据存储方式: 第一种方法:用NSUserDefaults存储配置信息 NSUserDefaults被设计用来存储设备和应用的配置信息.它通过一个工厂方法返回默认的.也是最经常使用 ...
随机推荐
- 浮动IP(Floating IPs):开始构建你的高可用性的应用
高可用性是所有生产环境的关键.开发者因此可以高枕无忧因为他们知道他们的应用被设计为可以承受住故障. 今天,我们非常激动的宣布我们应用了浮动IP技术.浮动IP指的是一个IP地址可以立即从一个Drople ...
- mysql-The-server-quit-without-updating-PID-file
mysql 编译后执行 /etc/init.d/mysqld start 启动失败 提示:"The server quit without updating PID file" 排 ...
- python-xlsxwriter模块绘制表格
#coding: utf-8 import xlsxwriter workbook=xlsxwriter.Workbook('chart.xlsx') worksheet=workbook.add_w ...
- MySQL安装步骤详解
MySQL安装 一.MYSQL的安装 1.打开下载的mysql安装文件mysql-5.5.27-win32.zip,双击解压缩,运行“setup.exe”. 2.选择安装类型,有“Typical(默认 ...
- C/S架构程序多种类服务器之间实现单点登录
(一) 在项目开发的过程中,经常会出现这样的情况:我们的产品包括很多,以QQ举例,如登陆.好友下载.群下载.网络硬盘.QQ游戏.QQ音乐等,总不能要求用户每次输入用户名.密码吧,为解决这个问题,高手提 ...
- IBM websphere MQ使用说明
百度文库: IBM websphere MQ使用说明 IBM MQ安装和配置
- python之路---06 小数据池 编码
二十二.小数据池, id() 进行缓存 1.小数据池针对的是: int, str, bool 2.在py文件中几乎所有的字符串都会缓存. 在cmd命令窗口中几乎都不会缓存 不同的解释器有 ...
- mysql创建部分索引
mysql中,字符串如何建立索引的(本文中截取一部分) 只对字符串的前几个字符进行索引.通过字符串的前几个字符我们已经能大概排序字符串了,剩下不能排序的可以通过遍历进行查找啊,这样只在B+树中存储字符 ...
- 在公司上wifi
公司的wifi上不了咋办?自己搞! 做法: 把自己的newifi mini带到公司, 记录公司内网ip,登入路由器设置, 1. 把ip改为内网一致, 2.关闭dhcp功能 3.设置wifi 网线连接: ...
- js检测字符串的字节数
在js中字符串可以存放数字,字母或者汉字,但是又一个问题就是,数字和字母都是占一个字节,而一个汉字占2个字节.如果在一个字符串中既有字母又有汉字怎么判断字节数呢 第一种简单粗暴 var str = ' ...