python入门第二篇
整体注释:ctrl+?
1、运算符
+ - * / //(取商)
**(幂)
%(求余)
判断某个东西是否在某个东西里面包含: in not in
不等于:
<>
!=
a=a+1 等于 a+=1
a=a-1 等于 a-=1
a=a%1 等于 a%=1
结果是值
算数运算
a = 10 * 10
赋值运算
a = a + 1 a+=1
结果是布尔值
比较运算
a = 1 > 5
逻辑运算
a = 1>6 or 1==1
成员运算
a = "蚊" in "郑建文"
补充:
字节, 位
unicode utf8 gbk
utf8: 3
gbk : 2
2、基本数据类型:
1、数字 int 所有的功能都放在int里
在python3里,所有的整型都是int类型
12354544788545454111 int
在python2里,超过一定范围后,是long int类型
1215551531152515 long int
- int
将字符串转换为数字
a = "123"
print(type(a),a)
b = int(a)
print(type(b),b)
运行结果:<class'str'>123
<class'int'>123

- bit_lenght
# 当前数字的二进制,至少用n位表示
r = age.bit_length()
2、字符串 str
#s1=“huang”
#s2="wei"
text="huang"
#首字母大写
v=text.capitalize()
print(v)
运行结果:
Huang
text="huAng"
#所有变小写,casefold更牛逼,很多未知的对应关系也可以变小写
v=text.casefold()
print(v)
运行结果:
huang
text="huAng"
#平时用的,英文小写的转换
v=text.lower()
print(v)
#判断是否全部是小写,转换成小写
text="Huang"
v1=text.islower()
v2=text.lower()
print(v1,v2)
运行结果: False huang
#判断是否全部是大写,转换成大写
text="Huang"
v1=text.isupper()
v2=text.upper()
print(v1,v2)
运行结果:
False HUANG
#大写换小写,小写换大写,,同时转换
text="huAng"
v=text.swapcase()
print(v)
运行结果:
HUaNG
text="huang"
# 设置宽度,并将内容居中
# 代指总长度
#* 空白未知填充,一个字符,可有可无
v=text.center(,"*")
print(v)
运行结果:
*******huang********
text="huang"
#* 空白未知填充,一个字符,可有可无
#填充右边
v=text.ljust(20,'*')
print(v)
运行结果:
huang***************
text="huang"
#* 空白未知填充,一个字符,可有可无
#填充左边
v=text.rjust(20,'*')
print(v)
运行结果:
***************huang
test="huanghuang"
#去字符串中寻找,寻找子序列的出现次数
v=test.count("a")
print(v)
运行结果:
2
test="huanghuang"
#去字符串中寻找,寻找子序列的出现次数
#后面的参数指起始位置到结束位置
v=test.count("a",2,6)
print(v)
运行结果:
1
test="huanghuang"
#以什么什么结尾
#以什么什么开始
v=test.endswith("ng")
v=test.startswith("u")
print(v)
#从开始往后找,找到第一个之后,获取其未知
#> 或 >=
test = "alexalex"
#未找到 -
v = test.find('ex',,)
print(v)
#index找不到,报错 忽略 test = "alexalex"
v = test.index('8')
print(v)
# 格式化,将一个字符串中的占位符替换为指定的值
test = 'i am {name}, age {a}'
print(test)
v = test.format(name='alex',a=19)
print(v)
运行结果:
i am {name}, age {a}
i am alex, age 19
#格式化,传入的值 {"name": 'alex', "a": 19}
test = 'i am {name}, age {a}'
v1 = test.format(name='df',a=10)
v2 = test.format_map({"name": 'alex', "a": 19})
print(v1)
print(v2)
运行结果:
i am df, age 10
i am alex, age 19
#字符串中是否只包含 字母和数字
test = ""
v = test.isalnum()
print(v)
#是否是字母,汉子
test = "5heer"
v = test.isalpha()
print(v)
# 当前输入是否是数字
test = "二" # 1,②
v1 = test.isdecimal() 十进制
v2 = test.isdigit() 特殊数字
v3 = test.isnumeric() 中文数字
print(v1,v2,v3)
# 是否存在不可显示的字符
#\t 制表符
# \n 换行
test = "oiuas\tdfkj"
v = test.isprintable()
print(v)
# 判断是否全部是空格
test = " "
v = test.isspace()
print(v)
#判断是否是标题
test = "Return True if all cased characters in S are uppercase and there is"
v1 = test.istitle()
print(v1)
v2 = test.title()
print(v2)
v3 = v2.istitle()
print(v3)
运行结果:
False
Return True If All Cased Characters In S Are Uppercase And There Is
True
# ** ** *将字符串中的每一个元素按照指定分隔符进行拼接
test = "你是风儿我是沙"
print(test)
#t = ' '
v = "_".join(test)
print(v)
运行结果:
你是风儿我是沙
你_是_风_儿_我_是_沙
#去除\n\t
#移除指定字符串
text=" huang "
v1=text.lstrip()#去除左边空白
print(v1)
v2=text.rstrip()
print(v2)#去除右边空白
v3=text.strip()
print(v3)#去除两边空白
#对应关系替换
test = "aeiou"
test1 = ""
v = "asidufkasd;fiuadkf;adfkjalsdjf"
m = str.maketrans("aeiou", "")
new_v = v.translate(m)
print(new_v)
运行结果:
1s3d5fk1sd;f351dkf;1dfkj1lsdjf
#分割为三部分
test = "testasdsddfg"
v = test.partition('s')
print(v)
v = test.rpartition('s')
print(v)
#分割为指定个数,但不包括定位符
test = "testasdsddfg"
v = test.split('s',2)
print(v)
test.rsplit()
#分割,只能根据换行符分割 ,true,false:是否保留换行符
test = "asdfadfasdf\nasdfasdf\nadfasdf"
v= test.splitlines(False)
print(v)
#以xxx开头,以xx结尾
test = "backend 1.1.1.1"
v = test.startswith('a')
print(v)
#test.endswith('a)
#将指定字符串替换为指定字符串
test = "alexalexalex"
v = test.replace("ex",'bbb')
print(v)
v = test.replace("ex",'bbb',2)
print(v)
将指定字符串替换为指定字符串
-------------------7个 基本魔法
join
split
find
strip
upper
lower
replce
--------------------灰魔法(几乎所有的数据类型都能使用)
1、#索引,下标,获取字符串中的某个字符
text="huang"
v=text[0]
print(v)
2、#索引,下标,获取字符串中的某个字符
text="huang"
#[0:-1]指到最后位置
v=text [0:3]#索引范围,0=<范围<3 切片
print(v)
v=len(text)#len 获取字符串里面由多少字符组成
print(v)
3、 for循环:
for 变量名 in 字符串:
print()
text="敢问今夕是何年"
for abc in text:
print(abc)
4、len
5、rang
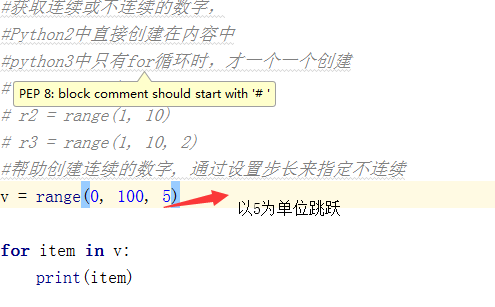
#将文字对应的索引打印出来:
text=input(">>>")
for item in range(0,len(text)):
print(item,text[item]) 运行结果:
>>>huang
0 h
1 u
2 a
3 n
4 g
#将文字对应的索引打印出来:
test = input(">>>")
print(test) # test = qwe test[0] test[1]
l = len(test) # l = 3
print(l)
r=range(0,3)
for item in r:
print(item,test[item])
运行结果:
>>>huang
huang
5
0 h
1 u
2 a
2
#断句
text="username\temail\tpassword\nhuang\t135168@qq.com\t123\nhuang\t123151@qq.com\t123\nhuang\t1641115@qq.com\t123"
v=text.expandtabs()
print(v)
运行结果:
username email password
huang 135168@qq.com 123
huang 123151@qq.com 123
huang 1641115@qq.com 123
###################### 1个深灰魔法 ######################
# 字符串一旦创建,不可修改
# 一旦修改或者拼接,都会造成重新生成字符串
# name = "zhengjianwen"
# age = "18"
#
# info = name + age
# print(info)
3、列表 list
4、元祖 tuple
5、字典 dict
6、布尔值 bool
python入门第二篇的更多相关文章
- ElasticSearch入门 第二篇:集群配置
这是ElasticSearch 2.4 版本系列的第二篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- Python人工智能第二篇:人脸检测和图像识别
Python人工智能第二篇:人脸检测和图像识别 人脸检测 详细内容请看技术文档:https://ai.baidu.com/docs#/Face-Python-SDK/top from aip impo ...
- Python人工智能第二篇
Python人工智能之路 - 第二篇 : 现成的技术 预备资料: 1.FFmpeg: 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w ...
- 【python自动化第二篇:python入门】
内容概览 模块 python运行过程 基本数据类型(数字,字符串) 序列类型(列表,元组,字典) 模块使用 模块我们可以把它想象成导入到python以增强其功能的一种拓展.需要使用import来导入模 ...
- python爬虫入门---第二篇:获取2019年中国大学排名
我们需要爬取的网站:最好大学网 我们需要爬取的内容即为该网页中的表格部分: 该部分的html关键代码为: 其中整个表的标签为<tbody>标签,每行的标签为<tr>标签,每行中 ...
- [Python笔记]第二篇:运算符、基本数据类型
本篇主要内容有:运算符 基本数据类型等 一.运算符 1.算术运算 2.比较运算 3.赋值运算 4.逻辑运算 5.成员运算 6.身份运算 7.位运算 8.运算符优先级 二.基本数据类型 1.整数:int ...
- python初识第二篇
python 编码: 第一次编程有时候会遇到乱码的情况,就可以通过以下的情况来解决 在Windows中默认的就是gbk编码,如果在代码头两部定义utf-8,系统还会按照系统的方式来定义. python ...
- JavaMail入门第二篇 创建邮件
JavaMail API使用javax.mail.Message类来表示一封邮件,Message类是一个抽象类,所以我们需要使用其子类javax.mail.internet.MimeMessage类来 ...
- python入门 第二天笔记
程序主文件标志if __name__=="__main__": 在程序执行python 1.py 时候 程序1.py __name__ 为 main调用其他文件是,__name__ ...
随机推荐
- Xml文件删除节点总是留有空标签
---恢复内容开始--- 在删除Xml文件时,删除成功后还有标签,让我百思不得其解,因为xml文档中留着这空标签会对后续的操作带来很多麻烦,会取出空值,人后导致程序中止. 导致这种情况的原因是删除xm ...
- ubuntu物理机上搭建Kubernetes集群 -- minion 配置
1. flannel配置 下载二进制文件 https://github.com/coreos/flannel/releases 版本:flannel-v0.7.0-linux-amd64.tar.gz ...
- 重读《深入理解Java虚拟机》四、虚拟机如何加载Class文件
1.Java语言的特性 Java代码经过编译器编译成Class文件(字节码)后,就需要虚拟机将其加载到内存里面执行字节码所定义的代码实现程序开发设定的功能. Java语言中类型的加载.连接(验证.准备 ...
- JavaScript深度克隆
深度克隆函数: function deepClone(obj){ var str = ""; var newobj = obj.constructor === Array ? [] ...
- cors与jsonp
在.net中,可以在webApiConfig代码里写,也可以在web.config里配置,但都需要引入System.Web.Cors.这些都是服务器端的配置,对整个项目有效. {若只想对某个请求有效, ...
- .NET Core 使用 Kestrel
Kestrel介绍 Kestrel是一个基于libuv的跨平台web服务器 在.net core项目中就可以不一定要发布在iis下面了 Kestrel体验 可以使用useUrls来设置一个请求的地址 ...
- GPT转MBR怎么转?
GPT转MBR分区怎么转?现在很多笔记本的硬盘分区都是GPT模式,如果想装XP的话,那只能将GPT磁盘转换成MBR磁盘分区才行.接下来,简单说说如何将GPT分区转成MBR分区! 如果本身电脑有两个硬盘 ...
- wx 文件编辑框
# -*- coding: utf- -*- import wx import os class my_frame(wx.Frame): """This is a sim ...
- 实例讲解TP5中关联模型
https://blog.csdn.net/github_37512301/article/details/75675054 一.关联模型在关系型数据库中,表之间有一对一.一对多.多对多的关系.在 T ...
- root_objectlist, root_object, container_objectlist, container_object 之间的关系。