Hive HiveServer2+beeline+jdbc客户端访问操作
HiveServer
查看/home/hadoop/bigdatasoftware/apache-hive-0.13.1-bin/bin目录文件,其中有hiveserver2
启动hiveserver2,如下图:

打开多一个终端,查看进程

有RunJar进程说明hiveserver正在运行;
beeline
启动beeline
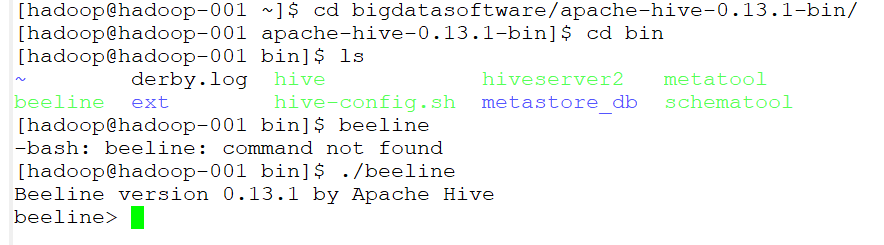
连接到jdbc
!connect jdbc:hive2://hadoop-001:10000 hadoop hadooporg.apache.hive.jdbc.HiveDriver;

然后就可以进行一系列操作了
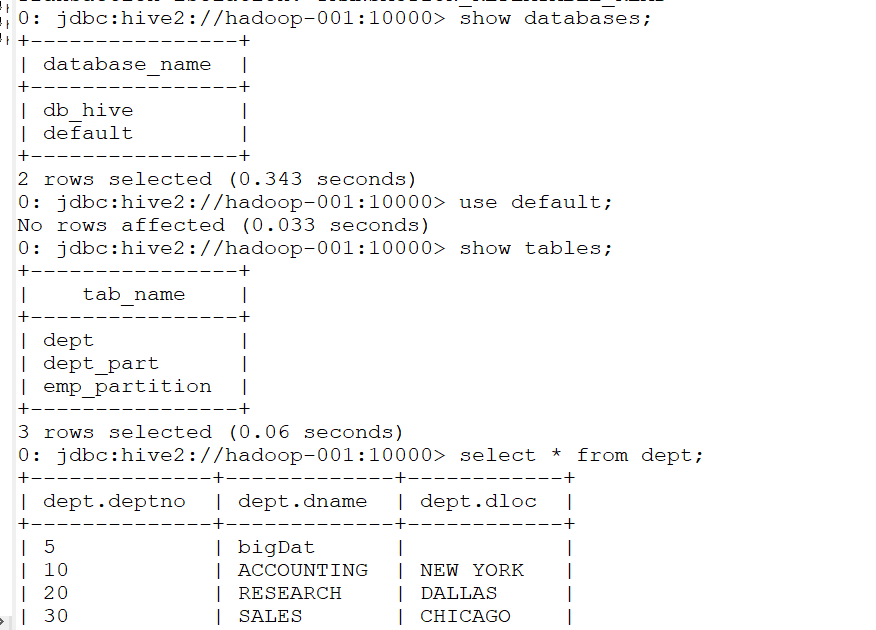
IDEA上jdbc客户端操作hive
Using JDBC
You can use JDBC to access data stored in a relational database or other tabular format.
Load the HiveServer2 JDBC driver. As of 1.2.0 applications no longer need to explicitly load JDBC drivers using Class.forName().
For example:
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connect to the database by creating a
Connectionobject with the JDBC driver.For example:
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "<password>");
The default
<port>is 10000. In non-secure configurations, specify a<user>for the query to run as. The<password>field value is ignored in non-secure mode.
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "");
In Kerberos secure mode, the user information is based on the Kerberos credentials.
Submit SQL to the database by creating a
Statementobject and using itsexecuteQuery()method.For example:
Statement stmt = cnct.createStatement();
ResultSet rset = stmt.executeQuery("SELECT foo FROM bar");
- Process the result set, if necessary.
These steps are illustrated in the sample code below.
代码如下:
package com.gec.demo; import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager; public class HiveJdbcClient {
private static final String DRIVERNAME = "org.apache.hive.jdbc.HiveDriver"; /**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(DRIVERNAME);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
//replace "hive" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://hadoop-001:10000/default", "hadoop", "hadoop");
Statement stmt = con.createStatement();
String tableName = "dept";
// stmt.execute("drop table if exists " + tableName);
// stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
} // load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
// String filepath = "/";
// sql = "load data local inpath '" + filepath + "' into table " + tableName;
// System.out.println("Running: " + sql);
// stmt.execute(sql); // select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
} // regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
pom.xml配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>BigdataStudy</artifactId>
<groupId>com.gec.demo</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion> <artifactId>HiveJdbcClient</artifactId> <name>HiveJdbcClient</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.7.2</hadoop.version>
<!--<hive.version> 0.13.1</hive.version>-->
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency> </dependencies>
</project>
Hive HiveServer2+beeline+jdbc客户端访问操作的更多相关文章
- 3.1 HiveServer2.Beeline JDBC使用
https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients 一.HiveServer2.Beeline 1.HiveSer ...
- JDBC数据库访问操作的动态监测 之 Log4JDBC
log4jdbc是一个JDBC驱动器,能够记录SQL日志和SQL执行时间等信息.log4jdbc使用SLF4J(Simple Logging Facade)作为日志系统. 特性: 1.支持JDBC3和 ...
- JDBC数据库访问操作的动态监测 之 p6spy
P6spy是一个JDBC Driver的包装工具,p6spy通过对JDBC Driver的封装以达到对SQL语句的监听和分析,以达到各种目的. P6spy1.3 sf.net http://sourc ...
- hive JDBC客户端启动
JDBC客户端操作步骤
- [Hive]HiveServer2配置
HiveServer2(HS2)是一个服务器接口,能使远程客户端执行Hive查询,并且可以检索结果.HiveServer2是HiveServer1的改进版,HiveServer1已经被废弃.HiveS ...
- [Hive]HiveServer2概述
1. HiveServer1 HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交请求并检索结果.HiveServer是建立在Apache ThriftTM(http: ...
- [Spark][Hive]Hive的命令行客户端启动:
[Spark][Hive]Hive的命令行客户端启动: [training@localhost Desktop]$ chkconfig | grep hive hive-metastore 0:off ...
- jdbc数据访问技术
jdbc数据访问技术 1.JDBC如何做事务处理? Con.setAutoCommit(false) Con.commit(); Con.rollback(); 2.写出几个在Jdbc中常用的接口 p ...
- Redis的C++与JavaScript访问操作
上篇简单介绍了Redis及其安装部署,这篇记录一下如何用C++语言和JavaScript语言访问操作Redis 1. Redis的接口访问方式(通用接口或者语言接口) 很多语言都包含Redis支持,R ...
随机推荐
- git 实现提交远程分支步骤
git clone git branch [分支名] 创建分支 git branch 查看本地所有分支 git checkout [分支名称] 切换分支 ---写代码--- git status (查 ...
- Python 深度递归
class A: pass class B(A): pass class C(A): pass class D(B, C): pass class E: pass class F(D, E): pas ...
- 在使用MyCat和MySqL时的错误总结
在mysql中,无法连接虚拟机中的mysql. 原因:防火墙没有关闭 解决方案:service iptables stop 在mycat中,无法打开数据库的表, 原因:mycat在配置文件中设置的是自 ...
- encodeURI和encodeURIComponent区别
参考:https://www.jianshu.com/p/075f5567c9a1 这两个函数功能上面比较接近,但是有一些区别. encodeURI:不会进行编码的字符有82个 :!,#,$,& ...
- [转]ZooKeeper 集群环境搭建 (本机3个节点)
ZooKeeper 集群环境搭建 (本机3个节点) 是一个简单的分布式同步数据库(或者是小文件系统) ------------------------------------------------- ...
- Swig--模板引擎
{% filter uppercase %} oh hi, {{ name }} {% endfilter %} {% filter replace "." "!&quo ...
- Ajax的简单介绍与使用
1.什么是Ajax? Ajax(Asynchronous JavaScript and XML),简单说就是不需要刷新当前页面而实现javaScript和和后台服务器交换数据以更新网页中的部分内容. ...
- 2017 乌鲁木齐赛区网络赛 J Our Journey of Dalian Ends 费用流
题目描述: Life is a journey, and the road we travel has twists and turns, which sometimes lead us to une ...
- [LeetCode&Python] Problem 100. Same Tree
Given two binary trees, write a function to check if they are the same or not. Two binary trees are ...
- P3084 [USACO13OPEN]照片Photo (dp+单调队列优化)
题目链接:传送门 题目: 题目描述 Farmer John has decided to assemble a panoramic photo of a lineup of his N cows ( ...