Modern Data Lake with Minio : Part 1
转自:https://blog.minio.io/modern-data-lake-with-minio-part-1-716a49499533
Modern data lakes are now built on cloud storage, helping organizations leverage the scale and economics of object storage, while simplifying overall data storage and analysis flow.
In the first part of this two post series, we’ll take a look at how object storage is different from other storage approaches and why it makes sense to leverage object storage like Minio for data lakes.
What is object storage?
Object storage generally refers to the way in which the platforms organises units of storage, called objects. Every object generally consists of three things:
- The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for building a rocket.
- An expandable amount of metadata. The metadata is defined by whoever creates the object storage; it contains contextual information about what the data is, what it should be used for, its confidentiality, or anything else that is relevant to the way in which the data should be used.
- A globally unique identifier. The identifier is an address given to the object, so it can be found over a distributed system. This way, it’s possible to find the data without having to know its physical location (which could exist within different parts of a data centre or different parts of the world).
Block storage vs object storage
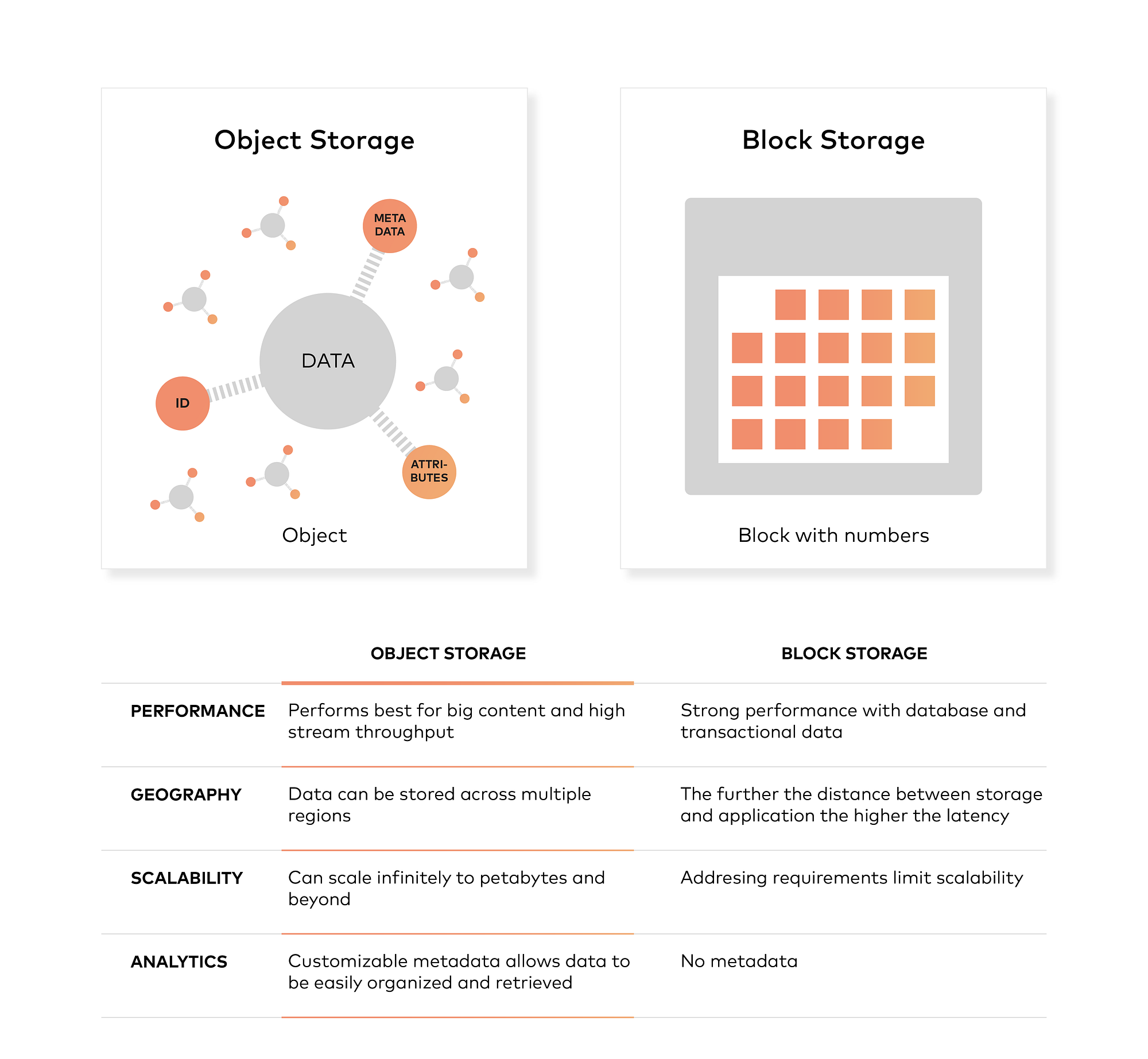
Object storage, unlike block storage, doesn’t split files up into raw blocks of data. Instead, data is stored as an object that contains the actual file data, metadata, identified by a unique identifier. Note that metadata can include any text information about the object.
Modern enterprise data centre is increasingly looking like private cloud, with object storage as the de facto storage. Object storage provides better economy at scale, ensures data is available across the world, in a highly available and highly durable manner.

Why is object storage is relevant?
Hadoop was once the dominant choice for data lakes. But in today’s fast-moving world of technology, there’s already a modern approach in town. Modern data lakes are based on object storage, with tools like Apache Spark, Presto, Tensorflow being used for advanced analytics and machine learning.
Let’s try to look back and understand how things have changed. Hadoop arose in the early 2000s and became massively popular in the last five years or so. In fact, because many companies committed to open source, most of the first big data projects five or six years ago were based on Hadoop.
Simply put, you can think of Hadoop as having two main capabilities:
- Distributed file system (HDFS) to persist data.
- Processing framework (MapReduce) that enables you to process all that data in parallel.
Increasingly, organisations started wanting to work with all of their data and not just some of it. And as a result of that, Hadoop became popular because of its ability to store and process new data sources, including system logs, click streams, and sensor- and machine-generated data.
Around 2008 or 2009, this was a game changer. At that time, Hadoop made perfect sense for the primary design goal of enabling you to build an on-premises cluster with commodity hardware to store and process this new data cheaply.
It was the right choice for the time — but it isn’t the right choice today.
Spark emerges
The good thing about open source is that it’s always evolving. The bad thing about open source is that it’s always evolving too.
What I mean is that there’s a bit of a game of catch-up you have to play, as the newest, biggest, best new projects come rolling out. So let’s take a look at what’s happening now.
Over the last few years, a newer framework than MapReduce emerged: Apache Spark. Conceptually, it’s similar to MapReduce. But the key difference is that it’s optimized to work with data in memory rather than disk. And this, of course, means that algorithms run on Spark will be faster, often dramatically so.
In fact, if you’re starting a new big data project today and don’t have a compelling requirement to interoperate with legacy Hadoop or MapReduce applications, then you should be using Spark. You’ll still need to persist the data and since Spark has been bundled with many Hadoop distributions, most on-premises clusters have used HDFS. That works, but with the rise of the cloud, there’s a better approach to persisting your data: object storage.
Object storage differs from file storage and block storage in that it keeps data in an “object” versus a block to make up a file. Metadata is associated to that file which eliminates the need for the hierarchical structure used in file storage — there is no limit to the amount of metadata that can be used. Everything is placed into a flat address space, which is easily scalable.
Object storage offers multiple advantages
Essentially, object storage performs very well for big content and high stream throughput. It allows data to be stored across multiple regions, it scales infinitely to petabytes and beyond, and it offers customizable metadata to aid with retrieving files.
Many companies, especially those running a private cloud environment, look at object stores as a long-term repository for massive, unstructured data that needs to be kept for compliance reasons.
But it’s not just data for compliance reasons. Companies use object storage to store photos on Facebook, songs on Spotify, and files in Dropbox.
The factor that likely makes most people’s eyes light up is the cost. The cost of bulk storage for object store is much less than the block storage you would need for HDFS. Depending upon where you shop around, you can find that object storage costs about 1/3 to 1/5 as much as block storage (remember, HDFS requires block storage). This means that storing the same amount of data in HDFS could be three to five times as expensive as putting it in object storage.
So, Spark is a faster framework than MapReduce, and object storage is cheaper than HDFS with its block storage requirement. But let’s stop looking at those two components in isolation and look at the new architecture as a whole.
The Benefits of combining object storage and Spark
What we recommend especially, is building a data lake in the cloud based on object storage and Spark. This combination is faster, more flexible and lower cost than a Hadoop-based data lake. Let’s explain this more.
Combining object storage in the cloud with Spark is more elastic than your typical Hadoop/MapReduce configuration. If you’ve ever tried to add and subtract nodes to a Hadoop cluster, you’ll know what I mean. It can be done but it’s not easy, while that same task is trivial in the cloud.
But there’s another aspect of elasticity. With Hadoop if you want to add more storage, you do so by adding more nodes (with compute). If you need more storage, you’re going to get more compute whether you need it or not.
With the object storage architecture, it’s different. If you need more compute, you can spin up a new Spark cluster and leave your storage alone. If you’ve just acquired many terabytes of new data, then just expand your object storage. In the cloud, compute and storage aren’t just elastic. They’re independently elastic. And that’s good, because your needs for compute and storage are also independently elastic.
What can you gain with object storage and Spark?
Business Agility: All of this means that your performance can improve. You can spin up many different compute clusters according to your needs. A cluster with lots of RAM, heavy-duty general-purpose compute, or GPUs for machine learning — you can do all of this as needed and all at the same time.
By tailoring your cluster to your compute needs, you can get results more quickly. When you’re not using the cluster, you can turn it off so you’re not paying for it.
Use object storage to become the persistent storage repository for the data in your data lake. On the cloud, you’ll only pay for the amount of data you have stored, and you can add or remove data whenever you want.
The practical effect of this newfound flexibility in allocating and using resources is greater agility for the business. When a new requirement arises, you can spin up independent clusters to meet that need. If another department wants to make use of your data that’s also possible because all of those clusters are independent.
Stability and Reliability: Operating a stable and reliable Hadoop cluster over an extended period of time delivers more than its share of complexity.
If you have an on-premise solution, upgrading your cluster typically means taking the whole cluster down and upgrading everything before bringing it up again. But doing so means you’re without access to that cluster while that’s happening, which could be a very long time if you run into difficulties. And when you bring it back up again, you might find new issues.
Rolling upgrades (node by node) are possible, but they’re still a very difficult process. So, it’s not widely recommended. Not just upgrades and patches, running and tuning a Hadoop cluster potentially involves adjusting as many as 500 different parameters.
One way to address this kind of problem is through automation.
But the cloud gives you another option. Fully managed Spark and object storage services can do all that work for you. Backup, replication, patching, upgrades, tuning, all outsourced.
In the cloud, the responsibility for stability and reliability is shifted from your IT department to the cloud vendor, whether it is private cloud or public.
Lowered TCO: Shifting the work of managing your object storage/Spark configuration to the cloud has another advantage too. You’re essentially outsourcing the storage management part of the work to a vendor. It’s a way to keep your employees engaged and working on exciting projects while saving on costs and contributing to a lowered TCO.
The lower TCO for this new architecture is about more than reducing labor costs, important though that is. Remember that object storage is cheaper than the block storage required by HDFS. Independent elastic scaling really does mean paying for what you use.
In essence
We boil down the advantages of this new data lake architecture built on object storage and Spark to three:
- Increased business agility
- More stability and reliability
- Lowered total cost of ownership
In the next and final post of this series, we’ll learn about object storage architecture in general and then see how to integrate Minio object store with tools like Apache Spark and Presto to simplify data flows across the organization.
This is a guest post by our community member Ravishankar Nair.
Modern Data Lake with Minio : Part 1的更多相关文章
- Modern Data Lake with Minio : Part 2
转自: https://blog.minio.io/modern-data-lake-with-minio-part-2-f24fb5f82424 In the first part of this ...
- Data Lake Analytics的Geospatial分析函数
0. 简介 为满足部分客户在云上做Geometry数据的分析需求,阿里云Data Lake Analytics(以下简称:DLA)支持多种格式的地理空间数据处理函数,符合Open Geospatial ...
- Data Lake Analytics + OSS数据文件格式处理大全
0. 前言 Data Lake Analytics是Serverless化的云上交互式查询分析服务.用户可以使用标准的SQL语句,对存储在OSS.TableStore上的数据无需移动,直接进行查询分析 ...
- data lake 新式数据仓库
Data lake - Wikipedia https://en.wikipedia.org/wiki/Data_lake 数据湖 Azure Data Lake Storage Gen2 预览版简介 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 因此数据湖相关服务 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- Azure Data Lake Storage Gen2实战体验
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- Data Lake Analytics: 读/写PolarDB的数据
Data Lake Analytics 作为云上数据处理的枢纽,最近加入了对于PolarDB的支持, PolarDB 是阿里云自研的下一代关系型分布式云原生数据库,100%兼容MySQL,存储容量最高 ...
随机推荐
- 7.6 C++基本序列式容器效率比较
参考:http://www.weixueyuan.net/view/6403.html 总结: 对于vector而言,它只是一个可以伸缩长度的数组 对于deque而言,它是一个可以操作头部和尾部的并且 ...
- Centos7 LNMP 一键安装
首页: https://lnmp.org/ 安装包生成页: https://lnmp.org/auto.html
- maven包上传私服
选择需要上传的项目右键-->Run As-->Run Configurations-->Maven Buid-->右键 new -->选择 base directory- ...
- netty的decoder encoder
public class DelimiterBasedFrameDecoder extends ByteToMessageDecoder { 随便找了一个用字符串分割粘包的decoder,继承了Byt ...
- 火狐下,td 的 bug;
想实现类似的效果,看代码, <div style="width:488px;float:left; margin:-52px 0px 15px 15px;"> < ...
- Effective Java Chapter4 Classes and Interface
MInimize the accessibility of classes and members 这个叫做所谓的 information hiding ,这么做在于让程序耦合度更低,增加程序的健壮性 ...
- mysql关系型和非关系型区别
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织优点:1.易于维护:都是使用表结构,格式一致:2.使用方便:SQL语言通用,可用于复杂查询:3.复杂操作:支持SQL,可用于 ...
- python--Selenium-模拟浏览器
python--Selenium-模拟浏览器基本使用from selenium import webdriverfrom selenium.webdriver.common.by import Byf ...
- 解决IDEA16闪退的问题
问题描述:在编辑等使用过程中,IDEA有时会突然闪退,一脸懵逼...... 原因: 1.内存分配不够 修改home/bin/目录下面的配置文件: idea.exe.vmoptions idea64.e ...
- Maven下用MyBatis Generator生成文件
使用Maven命令用MyBatis Generator生成MyBatis的文件步骤如下: 1.在mop文件内添加plugin <build> <finalName>KenShr ...