大数据学习笔记之Zookeeper(三):Zookeeper理论篇(二)
3.1 数据结构
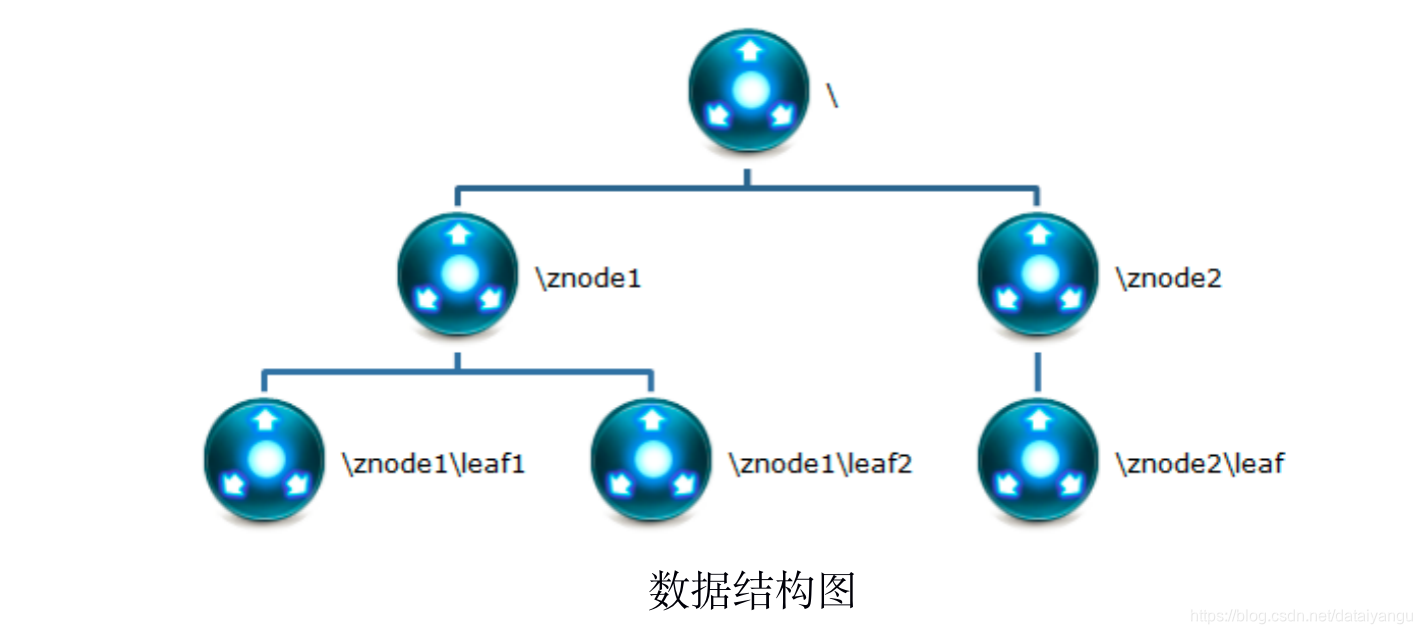
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。
很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
3.2 节点类型
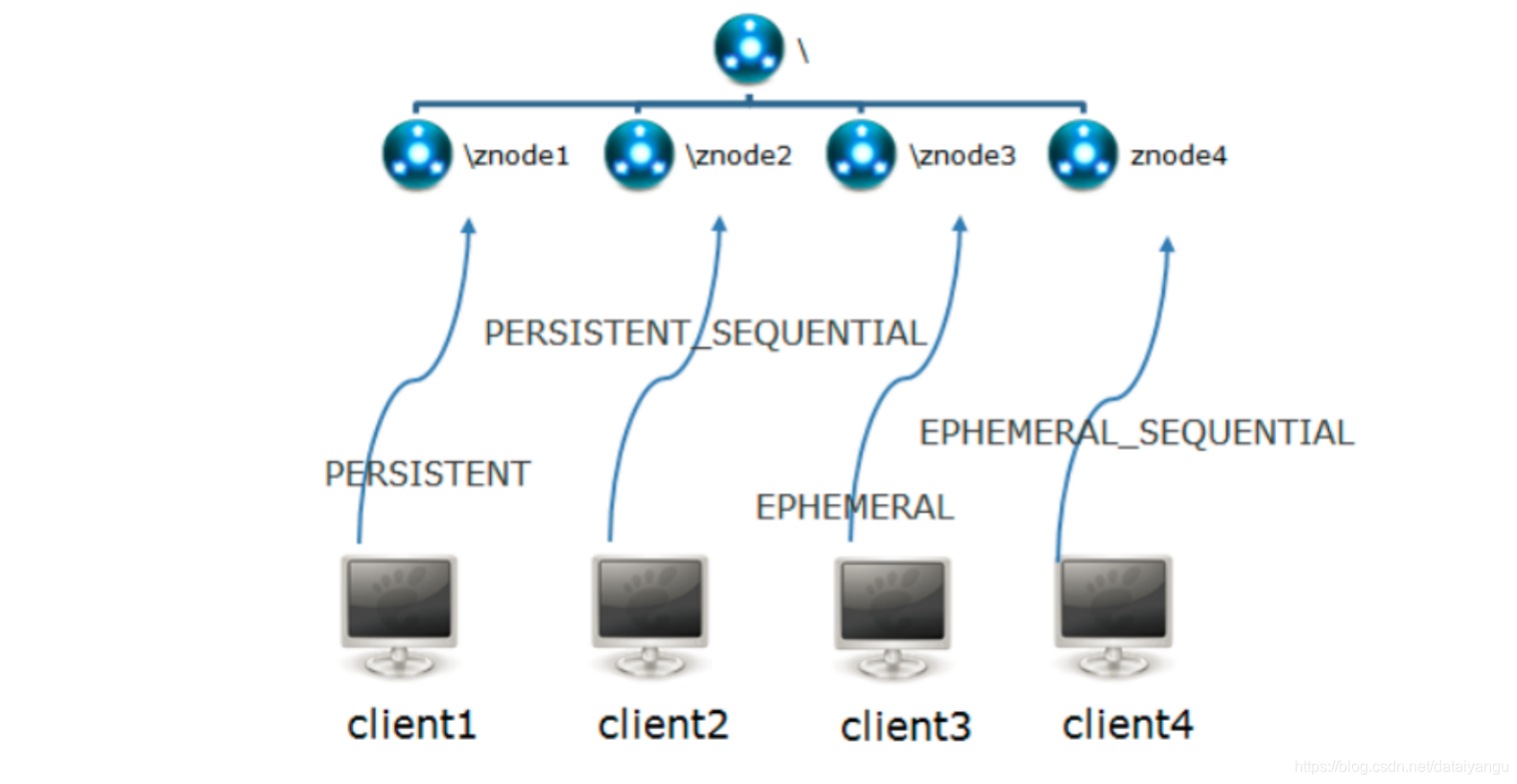
1)Znode有两种类型:
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除
2)Znode有四种形式的目录节点(默认是persistent )
(1)持久化目录节点(PERSISTENT)
客户端与zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
如果是PERSISTENT的,需要记着自己的名字是否被用过,是否会发生和之前的节点有冲突的情况,如果创建带序号的,默认都会带编号而且保证不重复。
(3)临时目录节点(EPHEMERAL)
客户端与zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
3)创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4)在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
3.3 特点
1)Zookeeper:一个领导者(leader),多个跟随者(follower)组成的集群。
2)Leader负责进行投票的发起和决议,更新系统状态,即写操作都是由leader来完成,读操作都是有follower完成
3)Follower用于接收客户请求并向客户端返回结果,在选举Leader过程中参与投票
4)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。为什么是半数?因为偶数没有意义,浪费了一个设备。
5)全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
6)更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
7)数据更新原子性,一次数据更新要么成功,要么失败。
8)实时性,在一定时间范围内,client能读到最新数据。
3.4 选举机制
1)半数机制:集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
2)Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
3)以一个简单的例子来说明整个选举的过程。
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
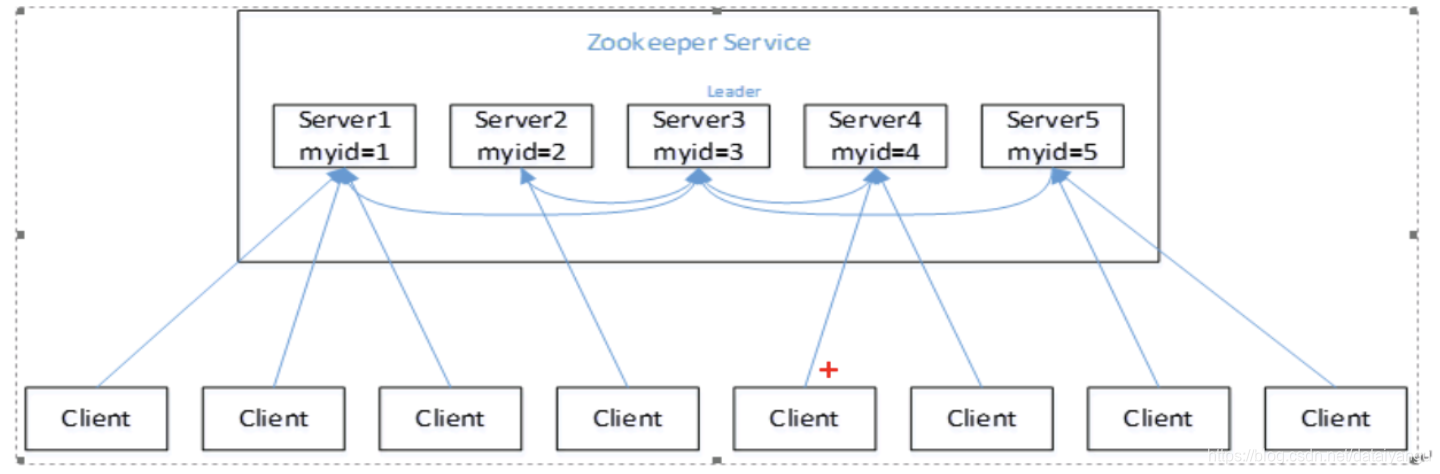
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
3.5 stat结构体
1)czxid- 引起这个znode创建的zxid,创建节点的事务的zxid(ZooKeeper Transaction Id)
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
事务ID是ZooKeeper中所有修改总的次序。每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
2)ctime - znode被创建的毫秒数(从1970年开始)
3)mzxid - znode最后更新的zxid
4)mtime - znode最后修改的毫秒数(从1970年开始)
5)pZxid-znode最后更新的子节点zxid
6)cversion - znode子节点变化号,znode子节点修改次数
7)dataversion - znode数据变化号
8)aclVersion - znode访问控制列表的变化号
9)ephemeralOwner- 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0。
10)dataLength- znode的数据长度
11)numChildren - znode子节点数量
3.6 监听器原理
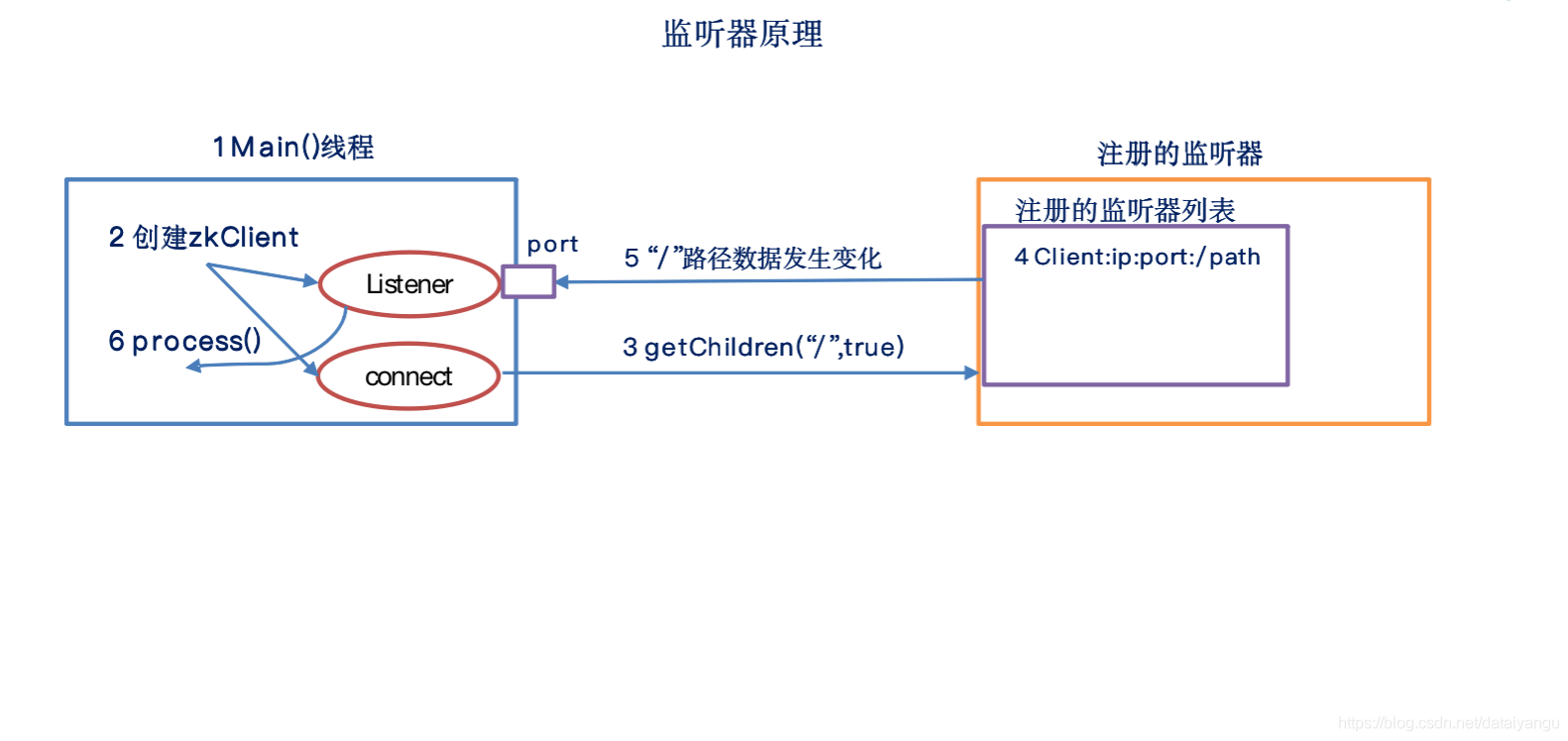
监听器是一个接口,我们的代码中可以实现Wather这个接口,实现其中的process方法,方法中即我们自己的业务逻辑
监听器的注册是在获取数据的操作中实现:
getData(path,watch?)监听的事件是:节点数据变化事件
getChildren(path,watch?)监听的事件是:节点下的子节点增减变化事件
大数据学习笔记之Zookeeper(三):Zookeeper理论篇(二)的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- 大数据学习笔记——Java篇之集合框架(ArrayList)
Java集合框架学习笔记 1. Java集合框架中各接口或子类的继承以及实现关系图: 2. 数组和集合类的区别整理: 数组: 1. 长度是固定的 2. 既可以存放基本数据类型又可以存放引用数据类型 3 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习笔记之Zookeeper(四):Zookeeper实战篇(二)
文章目录 4.1 分布式安装部署 4.2 客户端命令行操作 4.3 API应用 4.3.1 eclipse环境搭建 4.3.2 创建ZooKeeper客户端: 4.3.3 创建子节点 4.3.4 获取 ...
- 大数据学习笔记之Hadoop(三):MapReduce&YARN
文章目录 一 MapReduce概念 1.1 为什么要MapReduce 1.2 MapReduce核心思想 1.3 MapReduce进程 1.4 MapReduce编程规范(八股文) 1.5 Ma ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习笔记——Linux基本知识及指令(理论部分)
Linux学习笔记整理 上一篇博客中,我们详细地整理了如何从0部署一套Linux操作系统,那么这一篇就承接上篇文章,我们仔细地把Linux的一些基础知识以及常用指令(包括一小部分高级命令)做一个梳理, ...
- 大数据学习笔记——Java篇之IO
IO学习笔记整理 1. File类 1.1 File对象的三种创建方式: File对象是一个抽象的概念,只有被创建出来之后,文件或文件夹才会真正存在 注意:File对象想要创建成功,它的目录必须存在! ...
随机推荐
- Error querying database. Cause: org.apache.ibatis.reflection.ReflectionException: There is no getter for property named 'ItemsCustom' in 'class com.pojo.OrderDetailCustom
再用 junit 测试MyBatis时发现的错误: org.apache.ibatis.exceptions.PersistenceException: ### Error querying data ...
- BZOJ 3252题解(贪心+dfs序+线段树)
题面 传送门 分析 此题做法很多,树形DP,DFS序+线段树,树链剖分都可以做 这里给出DFS序+线段树的代码 我们用线段树维护到根节点路径上节点权值之和的最大值,以及取到最大值的节点编号x 每次从根 ...
- Sudoku (剪枝+状态压缩+预处理)
[题目描述] In the game of Sudoku, you are given a large 9 × 9 grid divided into smaller 3 × 3 subgrids. ...
- 第7章 PTA查找练习题
这道题与第7章查找有关,当时提前看到,翻到书里面的算法,然后打进去,虽然是正确的,但是那时候并不知道二叉排序树的基础知识,包括插入查找的来龙去脉,现在已经学到了,有了一定了解,发现题目只用到了其中部分 ...
- 回溯---IP 地址划分
IP 地址划分 93. Restore IP Addresses(Medium) Given "25525511135", return ["255.255.11.135 ...
- the sum of two fixed value
the sum of two fixed value description Input an array and an integer, fina a pair of number in the a ...
- ssh免口令密码登录及兼容性处理
1). client ---> server 客户端发起对服务器的连接,登录服务器. 2). 须在客户端生成密钥对 注意: 公钥加密私钥解:私钥加密公钥解. 可以发布公钥,但私钥是不能出本机的. ...
- hadoop HA架构
什么是Hadoop? http://hadoop.apache.org/ 解决问题:·海量数据的存储 (HDFS)·海量数据的分析 (MapReduce)·资源管理调度 (YARN) 集群规划:(这里 ...
- [Tyvj2032]升降梯上(最短路)
[Tyvj2032]升降梯上 Description 开启了升降梯的动力之后,探险队员们进入了升降梯运行的那条竖直的隧道,映入眼帘的是一条直通塔顶的轨道.一辆停在轨道底部的电梯.和电梯内一杆控制电梯升 ...
- openGL如何在改变窗口大小时,使自己的图形不被拉伸
这里要注意两个概念:视口和视景体,当视口的纵横比和视景体的纵横比相同的时候,改变窗口大小,图像才不会变形: 视景体是指成像景物所在空间的集合.它是一个空间集合体. 单个的视景体,比如一个球体,若要完全 ...