Android-Universal-Image-Loader的缓存处理机制与使用 LruCache 缓存图片
讲到缓存,平时流水线上的码农一定觉得这是一个高大上的东西。看过网上各种讲缓存原理的文章,总感觉那些文章讲的就是玩具,能用吗?这次我将带你一起看过UIL这个国内外大牛都追捧的图片缓存类库的缓存处理机制。看了UIL中的缓存实现,才发现其实这个东西不难,没有太多的进程调度,没有各种内存读取控制机制、没有各种异常处理。反正UIL中不单代码写的简单,连处理都简单。但是这个类库这么好用,又有这么多人用,那么非常有必要看看他是怎么实现的。先了解UIL中缓存流程的原理图。
原理示意图
主体有三个,分别是UI,缓存模块和数据源(网络)。它们之间的关系如下:
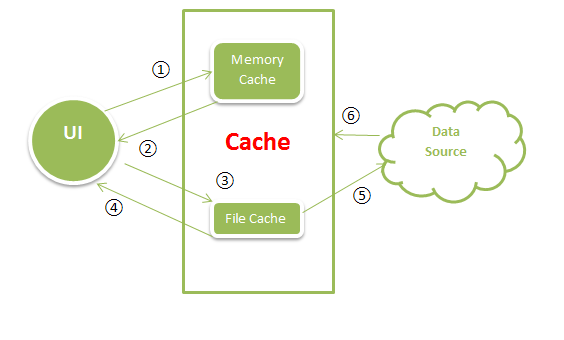
① UI:请求数据,使用唯一的Key值索引Memory Cache中的Bitmap。
② 内存缓存:缓存搜索,如果能找到Key值对应的Bitmap,则返回数据。否则执行第三步。
③ 硬盘存储:使用唯一Key值对应的文件名,检索SDCard上的文件。
④ 如果有对应文件,使用BitmapFactory.decode*方法,解码Bitmap并返回数据,同时将数据写入缓存。如果没有对应文件,执行第五步。
⑤ 下载图片:启动异步线程,从数据源下载数据(Web)。
⑥ 若下载成功,将数据同时写入硬盘和缓存,并将Bitmap显示在UI中。
接下来,我们回顾一下UIL中缓存的配置(具体的见《UNIVERSAL IMAGE LOADER.PART 2》)。重点关注注释部分,我们可以根据自己需要配置内存、磁盘缓存的实现。

File cacheDir = StorageUtils.getCacheDirectory(context,
"UniversalImageLoader/Cache"); ImageLoaderConfiguration config = new
ImageLoaderConfiguration .Builder(getApplicationContext())
.maxImageWidthForMemoryCache(800)
.maxImageHeightForMemoryCache(480)
.httpConnectTimeout(5000)
.httpReadTimeout(20000)
.threadPoolSize(5)
.threadPriority(Thread.MIN_PRIORITY + 3)
.denyCacheImageMultipleSizesInMemory()
.memoryCache(new UsingFreqLimitedCache(2000000)) // 你可以传入自己的内存缓存
.discCache(new UnlimitedDiscCache(cacheDir)) // 你可以传入自己的磁盘缓存
.defaultDisplayImageOptions(DisplayImageOptions.createSimple())
.build();
UIL中的内存缓存策略
1. 只使用的是强引用缓存
- LruMemoryCache(这个类就是这个开源框架默认的内存缓存类,缓存的是bitmap的强引用,下面我会从源码上面分析这个类)
2.使用强引用和弱引用相结合的缓存有
UsingFreqLimitedMemoryCache(如果缓存的图片总量超过限定值,先删除使用频率最小的bitmap)
- LRULimitedMemoryCache(这个也是使用的lru算法,和LruMemoryCache不同的是,他缓存的是bitmap的弱引用)
- FIFOLimitedMemoryCache(先进先出的缓存策略,当超过设定值,先删除最先加入缓存的bitmap)
- LargestLimitedMemoryCache(当超过缓存限定值,先删除最大的bitmap对象)
- LimitedAgeMemoryCache(当 bitmap加入缓存中的时间超过我们设定的值,将其删除)
3.只使用弱引用缓存
WeakMemoryCache(这个类缓存bitmap的总大小没有限制,唯一不足的地方就是不稳定,缓存的图片容易被回收掉)
我们直接选择UIL中的默认配置缓存策略进行分析。
ImageLoaderConfiguration config = ImageLoaderConfiguration.createDefault(context);
ImageLoaderConfiguration.createDefault(…)这个方法最后是调用Builder.build()方法创建默认的配置参数的。默认的内存缓存实现是LruMemoryCache,磁盘缓存是UnlimitedDiscCache。
LruMemoryCache解析
LruMemoryCache:一种使用强引用来保存有数量限制的Bitmap的cache(在空间有限的情况,保留最近使用过的Bitmap)。每次Bitmap被访问时,它就被移动到一个队列的头部。当Bitmap被添加到一个空间已满的cache时,在队列末尾的Bitmap会被挤出去并变成适合被GC回收的状态。
注意:这个cache只使用强引用来保存Bitmap。
LruMemoryCache实现MemoryCache,而MemoryCache继承自MemoryCacheAware。
public interface MemoryCache extends MemoryCacheAware<String, Bitmap>
下面给出继承关系图

LruMemoryCache.get(…)
我相信接下去你看到这段代码的时候会跟我一样惊讶于代码的简单,代码中除了异常判断,就是利用synchronized进行同步控制。
/**
* Returns the Bitmap for {@code key} if it exists in the cache. If a Bitmap was returned, it is moved to the head
* of the queue. This returns null if a Bitmap is not cached.
*/
@Override
public final Bitmap get(String key) {
if (key == null) {
throw new NullPointerException("key == null");
} synchronized (this) {
return map.get(key);
}
}
我们会好奇,这不是就简简单单将Bitmap从map中取出来吗?但LruMemoryCache声称保留在空间有限的情况下保留最近使用过的Bitmap。不急,让我们细细观察一下map。他是一个LinkedHashMap<String, Bitmap>型的对象。
LinkedHashMap中的get()方法不仅返回所匹配的值,并且在返回前还会将所匹配的key对应的entry调整在列表中的顺序(LinkedHashMap使用双链表来保存数据),让它处于列表的最后。当然,这种情况必须是在LinkedHashMap中accessOrder==true的情况下才生效的,反之就是get()方法不会改变被匹配的key对应的entry在列表中的位置。
1 @Override public V get(Object key) {
2 /*
3 * This method is overridden to eliminate the need for a polymorphic
4 * invocation in superclass at the expense of code duplication.
5 */
6 if (key == null) {
7 HashMapEntry<K, V> e = entryForNullKey;
8 if (e == null)
9 return null;
10 if (accessOrder)
11 makeTail((LinkedEntry<K, V>) e);
12 return e.value;
13 }
14
15 // Replace with Collections.secondaryHash when the VM is fast enough (http://b/8290590).
16 int hash = secondaryHash(key);
17 HashMapEntry<K, V>[] tab = table;
18 for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
19 e != null; e = e.next) {
20 K eKey = e.key;
21 if (eKey == key || (e.hash == hash && key.equals(eKey))) {
22 if (accessOrder)
23 makeTail((LinkedEntry<K, V>) e);
24 return e.value;
25 }
26 }
27 return null;
28 }
代码第11行的makeTail()就是调整entry在列表中的位置,其实就是双向链表的调整。它判断accessOrder
。到现在我们就清楚LruMemoryCache使用LinkedHashMap来缓存数据,在LinkedHashMap.get()方法执行后,LinkedHashMap中entry的顺序会得到调整。那么我们怎么保证最近使用的项不会被剔除呢?接下去,让我们看看LruMemoryCache.put(...)。
LruMemoryCache.put(...)
注意到代码第8行中的size+= sizeOf(key, value),这个size是什么呢?我们注意到在第19行有一个trimToSize(maxSize),trimToSize(...)这个函数就是用来限定LruMemoryCache的大小不要超过用户限定的大小,cache的大小由用户在LruMemoryCache刚开始初始化的时候限定。
1 @Override
2 public final boolean put(String key, Bitmap value) {
3 if (key == null || value == null) {
4 throw new NullPointerException("key == null || value == null");
5 }
6
7 synchronized (this) {
8 size += sizeOf(key, value);
9 //map.put()的返回值如果不为空,说明存在跟key对应的entry,put操作只是更新原有key对应的entry
10 Bitmap previous = map.put(key, value);
11 if (previous != null) {
12 size -= sizeOf(key, previous);
13 }
14 }
15
16 trimToSize(maxSize);
17 return true;
18 }
其实不难想到,当Bitmap缓存的大小超过原来设定的maxSize时应该是在trimToSize(...)这个函数中做到的。这个函数做的事情也简单,遍历map,将多余的项(代码中对应toEvict)剔除掉,直到当前cache的大小等于或小于限定的大小。
1 private void trimToSize(int maxSize) {
2 while (true) {
3 String key;
4 Bitmap value;
5 synchronized (this) {
6 if (size < 0 || (map.isEmpty() && size != 0)) {
7 throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
8 }
9
10 if (size <= maxSize || map.isEmpty()) {
11 break;
12 }
13
14 Map.Entry<String, Bitmap> toEvict = map.entrySet().iterator().next();
15 if (toEvict == null) {
16 break;
17 }
18 key = toEvict.getKey();
19 value = toEvict.getValue();
20 map.remove(key);
21 size -= sizeOf(key, value);
22 }
23 }
24 }
这时候我们会有一个以为,为什么遍历一下就可以将使用最少的bitmap缓存给剔除,不会误删到最近使用的bitmap缓存吗?首先,我们要清楚,LruMemoryCache定义的最近使用是指最近用get或put方式操作到的bitmap缓存。其次,之前我们直到LruMemoryCache的get操作其实是通过其内部字段LinkedHashMap.get(...)实现的,当LinkedHashMap的accessOrder==true时,每一次get或put操作都会将所操作项(图中第3项)移动到链表的尾部(见下图,链表头被认为是最少使用的,链表尾被认为是最常使用的。),每一次操作到的项我们都认为它是最近使用过的,当内存不够的时候被剔除的优先级最低。需要注意的是一开始的LinkedHashMap链表是按插入的顺序构成的,也就是第一个插入的项就在链表头,最后一个插入的就在链表尾。假设只要剔除图中的1,2项就能让LruMemoryCache小于原先限定的大小,那么我们只要从链表头遍历下去(从1→最后一项)那么就可以剔除使用最少的项了。
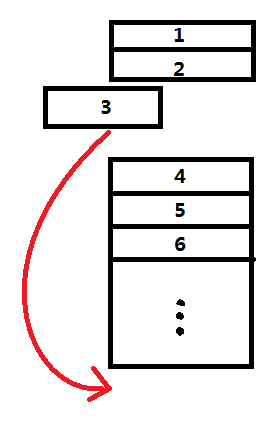

至此,我们就知道了LruMemoryCache缓存的整个原理,包括他怎么put、get、剔除一个元素的的策略。接下去,我们要开始分析默认的磁盘缓存策略了。
UIL中的磁盘缓存策略
像新浪微博、花瓣这种应用需要加载很多图片,本来图片的加载就慢了,如果下次打开的时候还需要再一次下载上次已经有过的图片,相信用户的流量会让他们的叫骂声很响亮。对于图片很多的应用,一个好的磁盘缓存直接决定了应用在用户手机的留存时间。我们自己实现磁盘缓存,要考虑的太多,幸好UIL提供了几种常见的磁盘缓存策略,当然如果你觉得都不符合你的要求,你也可以自己去扩展
- FileCountLimitedDiscCache(可以设定缓存图片的个数,当超过设定值,删除掉最先加入到硬盘的文件)
- LimitedAgeDiscCache(设定文件存活的最长时间,当超过这个值,就删除该文件)
- TotalSizeLimitedDiscCache(设定缓存bitmap的最大值,当超过这个值,删除最先加入到硬盘的文件)
- UnlimitedDiscCache(这个缓存类没有任何的限制)
在UIL中有着比较完整的存储策略,根据预先指定的空间大小,使用频率(生命周期),文件个数的约束条件,都有着对应的实现策略。最基础的接口DiscCacheAware和抽象类BaseDiscCache
UnlimitedDiscCache解析
UnlimitedDiscCache实现disk cache接口,是ImageLoaderConfiguration中默认的磁盘缓存处理。用它的时候,磁盘缓存的大小是不受限的。
接下来我们来看看实现UnlimitedDiscCache的源代码,通过源代码我们发现他其实就是继承了BaseDiscCache,这个类内部没有实现自己独特的方法,也没有重写什么,那么我们就直接看BaseDiscCache这个类。在分析这个类之前,我们先想想自己实现一个磁盘缓存需要做多少麻烦的事情:
1、图片的命名会不会重。你没有办法知道用户下载的图片原始的文件名是怎么样的,因此很可能因为文件重名将有用的图片给覆盖掉了。
2、当应用卡顿或网络延迟的时候,同一张图片反复被下载。
3、处理图片写入磁盘可能遇到的延迟和同步问题。
BaseDiscCache构造函数
首先,我们看一下BaseDiscCache的构造函数:
cacheDir:文件缓存目录
reserveCacheDir:备用的文件缓存目录,可以为null。它只有当cacheDir不能用的时候才有用。
fileNameGenerator:文件名生成器。为缓存的文件生成文件名。
public BaseDiscCache(File cacheDir, File reserveCacheDir, FileNameGenerator fileNameGenerator) {
if (cacheDir == null) {
throw new IllegalArgumentException("cacheDir" + ERROR_ARG_NULL);
}
if (fileNameGenerator == null) {
throw new IllegalArgumentException("fileNameGenerator" + ERROR_ARG_NULL);
}
this.cacheDir = cacheDir;
this.reserveCacheDir = reserveCacheDir;
this.fileNameGenerator = fileNameGenerator;
}
我们可以看到一个fileNameGenerator,接下来我们来了解UIL具体是怎么生成不重复的文件名的。UIL中有3种文件命名策略,这里我们只对默认的文件名策略进行分析。默认的文件命名策略在DefaultConfigurationFactory.createFileNameGenerator()。它是一个HashCodeFileNameGenerator。真的是你意想不到的简单,就是运用String.hashCode()进行文件名的生成。
public class HashCodeFileNameGenerator implements FileNameGenerator {
@Override
public String generate(String imageUri) {
return String.valueOf(imageUri.hashCode());
}
}
BaseDiscCache.save()
分析完了命名策略,再看一下BaseDiscCache.save(...)方法。注意到第2行有一个getFile()函数,它主要用于生成一个指向缓存目录中的文件,在这个函数里面调用了刚刚介绍过的fileNameGenerator来生成文件名。注意第3行的tmpFile,它是用来写入bitmap的临时文件(见第8行),然后就把这个文件给删除了。大家可能会困惑,为什么在save()函数里面没有判断要写入的bitmap文件是否存在的判断,我们不由得要看看UIL中是否有对它进行判断。还记得我们在《从代码分析Android-Universal-Image-Loader的图片加载、显示流程》介绍的,UIL加载图片的一般流程是先判断内存中是否有对应的Bitmap,再判断磁盘(disk)中是否有,如果没有就从网络中加载。最后根据原先在UIL中的配置判断是否需要缓存Bitmap到内存或磁盘中。也就是说,当需要调用BaseDiscCache.save(...)之前,其实已经判断过这个文件不在磁盘中。
1 public boolean save(String imageUri, InputStream imageStream, IoUtils.CopyListener listener) throws IOException {
2 File imageFile = getFile(imageUri);
3 File tmpFile = new File(imageFile.getAbsolutePath() + TEMP_IMAGE_POSTFIX);
4 boolean loaded = false;
5 try {
6 OutputStream os = new BufferedOutputStream(new FileOutputStream(tmpFile), bufferSize);
7 try {
8 loaded = IoUtils.copyStream(imageStream, os, listener, bufferSize);
9 } finally {
10 IoUtils.closeSilently(os);
11 }
12 } finally {
13 IoUtils.closeSilently(imageStream);
14 if (loaded && !tmpFile.renameTo(imageFile)) {
15 loaded = false;
16 }
17 if (!loaded) {
18 tmpFile.delete();
19 }
20 }
21 return loaded;
22 }
BaseDiscCache.get()
BaseDiscCache.get()方法内部调用了BaseDiscCache.getFile(...)方法,让我们来分析一下这个在之前碰过的函数。 第2行就是利用fileNameGenerator生成一个唯一的文件名。第3~8行是指定缓存目录,这时候你就可以清楚地看到cacheDir和reserveCacheDir之间的关系了,当cacheDir不可用的时候,就是用reserveCachedir作为缓存目录了。
最后返回一个指向文件的对象,但是要注意当File类型的对象指向的文件不存在时,file会为null,而不是报错。
1 protected File getFile(String imageUri) {
2 String fileName = fileNameGenerator.generate(imageUri);
3 File dir = cacheDir;
4 if (!cacheDir.exists() && !cacheDir.mkdirs()) {
5 if (reserveCacheDir != null && (reserveCacheDir.exists() || reserveCacheDir.mkdirs())) {
6 dir = reserveCacheDir;
7 }
8 }
9 return new File(dir, fileName);
10 }
总结
现在,我们已经分析了UIL的缓存机制。其实从UIL的缓存机制的实现并不是很复杂,虽然有各种缓存机制,但是简单地说:内存缓存其实就是利用Map接口的对象在内存中进行缓存,可能有不同的存储机制。磁盘缓存其实就是将文件写入磁盘。
在你应用程序的 UI 界面加载一张图片是一件很简单的事情,但是当你需要在界面上加载一大堆图片的时候,情况就变得复杂起来。在很多情况下,(比如使用 ListView, GridView 或者 ViewPager 这样的组件),屏幕上显示的图片可以通过滑动屏幕等事件不断地增加,最终导致 OOM。为了保证内存的使用始终维持在一个合理的范围,通常会把被移除屏幕的图片进行回收处理。此时垃圾回收器也会认为你不再持有这些图片的引用,从而对这些图片进行 GC 操作。用这种思路来解决问题是非常好的,可是为了能让程序快速运行,在界面上迅速地加载图片,你又必须要考虑到某些图片被回收之后,用户又将它重新滑入屏幕这种情况。这时重新去加载一遍刚刚加载过的图片无疑是性能的瓶颈,你需要想办法去避免这个情况的发生。
这个时候,使用内存缓存技术可以很好的解决这个问题,它可以让组件快速地重新加载和处理图片。下面我们就来看一看如何使用内存缓存技术来对图片进行缓存,从而让你的应用程序在加载很多图片的时候可以提高响应速度和流畅性。内存缓存技术对那些大量占用应用程序宝贵内存的图片提供了快速访问的方法。其中最核心的类是 LruCache ( 此类在 android-support-v4 的包中提供 ) 。这个类非常适合用来缓存图片,它的主要算法原理是把最近使用的对象用强引用存储在 LinkedHashMap 中,并且把最近最少使用的对象在缓存值达到预设定值之前从内存中移除。
在过去,我们经常会使用一种非常流行的内存缓存技术的实现,即软引用或弱引用 (SoftReference or WeakReference)。但是现在已经不再推荐使用这种方式了,因为从 Android 2.3 (API Level 9)开始,垃圾回收器会更倾向于回收持有软引用或弱引用的对象,这让软引用和弱引用变得不再可靠。另外,Android 3.0 (API Level 11)中,图片的数据会存储在本地的内存当中,因而无法用一种可预见的方式将其释放,这就有潜在的风险造成应用程序的内存溢出并崩溃。为了能够选择一个合适的缓存大小给 LruCache, 有以下多个因素应该放入考虑范围内,例如:
- 你的设备可以为每个应用程序分配多大的内存?
- 设备屏幕上一次最多能显示多少张图片?
- 有多少图片需要进行预加载,因为有可能很快也会显示在屏幕上?
- 你的设备的屏幕大小和分辨率分别是多少?一个超高分辨率的设备(例如 Galaxy Nexus)比起一个较低分辨率的设备(例如 Nexus S),在持有相同数量图片的时候,需要更大的缓存空间。
- 图片的尺寸和大小,还有每张图片会占据多少内存空间?
- 图片被访问的频率有多高?会不会有一些图片的访问频率比其它图片要高?如果有的话,你也许应该让一些图片常驻在内存当中,或者使用多个 LruCache 对象来区分不同组的图片。
- 你能维持好数量和质量之间的平衡吗?有些时候,存储多个低像素的图片,而在后台去开线程加载高像素的图片会更加的有效。
并没有一个指定的缓存大小可以满足所有的应用程序,这是由你决定的。你应该去分析程序内存的使用情况,然后制定出一个合适的解决方案。一个太小的缓存空间,有可能造成图片频繁地被释放和重新加载,这并没有好处。而一个太大的缓存空间,则有可能还是会引起 java.lang.OutOfMemory 的异常。
下面是一个使用 LruCache 来缓存图片的例子:
private LruCache<String, Bitmap> mMemoryCache; @Override
protected void onCreate(Bundle savedInstanceState) {
// 获取到可用内存的最大值,使用内存超出这个值会引起OutOfMemory异常。
// LruCache通过构造函数传入缓存值,以KB为单位。
int maxMemory = (int) (Runtime.getRuntime().maxMemory() / 1024);
// 使用最大可用内存值的1/8作为缓存的大小。
int cacheSize = maxMemory / 8;
mMemoryCache = new LruCache<String, Bitmap>(cacheSize) {
protected int sizeOf(String key, Bitmap bitmap) {
// 重写此方法来衡量每张图片的大小,默认返回图片数量。
return bitmap.getByteCount() / 1024;
}
};
} public void addBitmapToMemoryCache(String key, Bitmap bitmap) {
if (getBitmapFromMemCache(key) == null) {
mMemoryCache.put(key, bitmap);
}
} public Bitmap getBitmapFromMemCache(String key) {
return mMemoryCache.get(key);
}
在这个例子当中,使用了系统分配给应用程序的八分之一内存来作为缓存大小。在中高配置的手机当中,这大概会有4兆(32/8)的缓存空间。一个全屏幕的 GridView 使用 4 张 800x480 分辨率的图片来填充,则大概会占用 1.5 兆的空间 (800*480*4)。因此,这个缓存大小可以存储 2.5 页的图片。当向 ImageView 中加载一张图片时,首先会在 LruCache 的缓存中进行检查。如果找到了相应的键值,则会立刻更新 ImageView ,否则开启一个后台线程来加载这张图片。
public void loadBitmap(int resId, ImageView imageView) {
final String imageKey = String.valueOf(resId);
final Bitmap bitmap = getBitmapFromMemCache(imageKey);
if (bitmap != null) {
imageView.setImageBitmap(bitmap);
} else {
imageView.setImageResource(R.drawable.image_placeholder);
BitmapWorkerTask task = new BitmapWorkerTask(imageView);
task.execute(resId);
}
}
BitmapWorkerTask 还要把新加载的图片的键值对放到缓存中。
class BitmapWorkerTask extends AsyncTask<Integer, Void, Bitmap> {
// 在后台加载图片。 protected Bitmap doInBackground(Integer... params) {
final Bitmap bitmap = decodeSampledBitmapFromResource(
getResources(), params[0], 100, 100);
addBitmapToMemoryCache(String.valueOf(params[0]), bitmap);
return bitmap;
}
}
Android-Universal-Image-Loader的缓存处理机制与使用 LruCache 缓存图片的更多相关文章
- android universal image loader 缓冲原理详解
1. 功能介绍 1.1 Android Universal Image Loader Android Universal Image Loader 是一个强大的.可高度定制的图片缓存,本文简称为UIL ...
- Android Universal Image Loader java.io.FileNotFoundException: http:/xxx/lxx/xxxx.jpg
前段时间在使用ImageLoader异步加载服务端返回的图片时总是出现 java.io.FileNotFoundException: http://xxxx/l046/10046137034b1c0d ...
- 使用memcached缓存 替代solr中的LRUCache缓存
前沿 在搜索引擎中,缓存被当做是不可缺少的部分,但是很多情况下,将缓存的实现过度依赖于分发服务器及webserver会很大程度上加重webserver 的负担,具体表现就是经常性的假死,拒绝服务,因此 ...
- Hibernate——脏检查和缓存清理机制
Session到底是如何进行脏检查的呢? 当一个Customer对象被加入到Session缓存中时,Session会为Customer对象的值类型的属性复制一份快照.当Session清理缓存时,会先进 ...
- Android二级缓存之物理存储介质上的缓存DiskLruCache
Android二级缓存之物理存储介质上的缓存DiskLruCache Android DiskLruCache属于物理性质的缓存,相较于LruCache缓存,则DiskLruCache属于And ...
- Redis 缓存失效机制
Redis缓存失效的故事要从EXPIRE这个命令说起,EXPIRE允许用户为某个key指定超时时间,当超过这个时间之后key对应的值会被清除,这篇文章主要在分析Redis源码的基础上站在Redis设计 ...
- redis缓存处理机制
1.redis缓存处理机制:先从缓存里面取,取不到去数据库里面取,然后丢入缓存中 例如:系统参数处理工具类 package com.ztesoft.iotcmp.utils; import com.e ...
- Redis 的缓存淘汰机制(Eviction)
本文从源码层面分析了 redis 的缓存淘汰机制,并在文章末尾描述使用 Java 实现的思路,以供参考. 相关配置 为了适配用作缓存的场景,redis 支持缓存淘汰(eviction)并提供相应的了配 ...
- redis,缓存雪崩,粗粒度锁,缓存一致性
1, redis单线程为什么快 io多路复用技术 单线程避免多线程的频繁切换问题 memcache缺点 kv形式数据 没有持久化mongodb 海量数据的访问效率 mr的计算模型文档就是类似json的 ...
随机推荐
- IDEA + SpringBoot + maven 项目文件说明
Springboot + maven + IDEA + git 项目文件介绍 1..gitignore 分布式版本控制系统git的配置文件,意思为忽略提交 在 .gitingore 文件中,遵循相应 ...
- Delphi RadioGroup 组件
- centos 7 安装 redis-5.0.5
[root@localhost ~]# yum -y install gcc make [root@localhost ~]# wget http://download.redis.io/releas ...
- Qt Creator 4.10 Beta版发布
使用Qt Creator 4.10 Beta,现在支持固定文件,因此即使在关闭所有文件时它们仍然保持打开状态,围绕语言服务器协议支持继续集成,将Android目标添加到CMake/Qbs项目,支持Bo ...
- 了解并安装Nginx
公司使用nginx作为请求分发服务器,发现本人在查看nginx配置上存在些许困难,故仔细阅读了陶辉的<深入理解nginx模块开发与框架>第一部分,并作此记录. 了解 我根据书上的思路来了解 ...
- 003-centos7:rsyslog简单配置客户端和服务器端
实现把一个主机作为客户端,把日志发送到指定的服务器端: [服务器端] 开放tcp端口,udp端口: vim /etc/rsyslog.conf: # Provides UDP syslog recep ...
- FushionCharts
FushionCharts官网:http://www.fusioncharts.com/ 在线Demo:http://www.fusioncharts.com/free/demos/Blueprint ...
- zabbix的简单操作(监控客户端MySQL数据包库)
环境准备: 192.168.175.102 zabbix服务端 192.168.175.106 zabbix客户端(监控MySQL) 命令:iptables -F #清空防火 ...
- Pandas的常见使用方法操作
Series Series是一种类似于一维数组的 对象,由一组数据(各种NumPy数据类型)以及一组与之对应的索引(数据标签)组成. 类似一维数组的对象由数据和索引组成索引(index)在左,数据(v ...
- 服务端获取参数(koa)
1.获取query(问号后面的内容) ctx.query 2.获取路由参数(如'/user/:id'的id) ctx.param 3.获取body请求体 koa不能直接获取请求体里的body,需要安装 ...