spark性能调优03-shuffle调优
1、开启map端输出文件的合并机制
1.1 为什么要开启map端输出文件的合并机制
默认情况下,map端的每个task会为reduce端的每个task生成一个输出文件,reduce段的每个task拉取map端每个task生成的相应文件

开启后,map端只会在并行执行的task生成reduce端task数目的文件,下一批map端的task执行时,会复用首次生成的文件
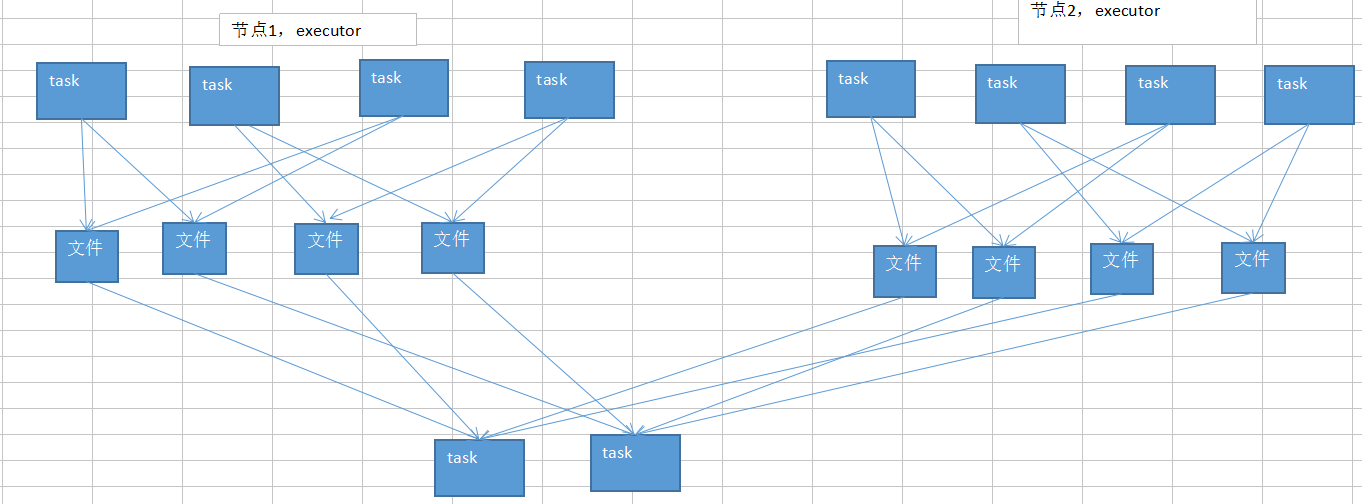
1.2 如何开启
//开启map端输出文件的合并机制
conf.set("spark.shuffle.consolidateFiles", "true");
2、调节map端内存缓冲区
2.1 为什么要调节map端内存缓冲区
默认情况下,shuffle的map task,输出的文件到内存缓冲区,当内存缓冲区满了,才会溢写spill操作到磁盘,如果该缓冲区比较小,而map端输出文件又比较大,会频繁的出现溢写到磁盘,影响性能。
2.2 如何调整
//设置map 端内存缓冲区大小(默认32k)
conf.set("spark.shuffle.file.buffer", "64k");
3、调节reduce端内存占比
3.1 为什么要调节reduce端内存占比
reduce task 在进行汇聚,聚合等操作时,实际上使用的是自己对应的executor内存,默认情况下executor分配给reduce进行聚合的内存比例是0.2,如果拉取的文件比较大,会频繁溢写到本地磁盘,影响性能。
3.2 如何调整
//设置reduce端内存占比
conf.set("spark.shuffle.memoryFraction", "0.4");
4、修改shuffle管理器
4.1 有哪些shuffle管理器
HashShuffleManager:1.2.x版本前的默认选择
SortShuffleManager:1.2.x版本之后的默认选择,会对每个task要处理的数据进行排序;同时,可以避免像HashShuffleManager那么默认去创建多份磁盘文件,而是一个task只会写入一个磁盘文件,不同reduce task需要的的数据使用offset来进行划分。
tungsten-sort(钨丝):1.5.x之后的出现,和SortShuffleManager相似,但是它本事实现了一套内存管理机制,性能有了很大的提高,而且避免了shuffle过程中产生大量的OOM、GC等相关问题。
4.2 如何选择
4.2.1 如果不需要排序,建议使用HashShuffleManager以提高性能
4.2.2 如果需要排序,建议使用SortShuffleManager
4.2.3 如果不需要排序,但是希望每个task输出的文件都合并到一个文件中,可以去调节bypassMergeThreshold这个阀值(默认为200),因为在合并文件的时候会进行排序,所以应该让该阀值大于reduce task数量。
4.2.4 如果需要排序,而且版本在1.5.x或者更高,可以尝试使用tungsten-sort
4.3 在项目中如何使用
//设置spark shuffle manager (hash,sort,tungsten-sort)
conf.set("spark.shuffle.manager", "tungsten-sort"); //设置文件合并的阀值
conf.set("spark.shuffle.sort.bypassMergeThreshold", "");
spark性能调优03-shuffle调优的更多相关文章
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- Spark性能优化:数据倾斜调优
前言 继<Spark性能优化:开发调优篇>和<Spark性能优化:资源调优篇>讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化 ...
- Spark性能优化--数据倾斜调优与shuffle调优
一.数据倾斜发生的原理 原理:在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作.此时如果某个key对应的数据量特 ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark性能优化:开发调优篇
1.前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算 ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- Spark性能调优-高级篇
前言 继基础篇讲解了每个Spark开发人员都必须熟知的开发调优与资源调优之后,本文作为<Spark性能优化指南>的高级篇,将深入分析数据倾斜调优与shuffle调优,以解决更加棘手的性能问 ...
- Spark性能调优-基础篇
前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark的功能涵盖了大数据领域的离线批处理.SQL类处理.流式/实时计算.机器学习.图计算等各种不同类型的计算操作 ...
- Spark学习之路 (八)SparkCore的调优之开发调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 前言 在大数据计算领域,Spark已经成为了越来越流行.越来越受欢迎的计算平台之一.Spark ...
随机推荐
- 对flex深入研究一点
flex顶层设计 1.在任何流动的方向上(包括上下左右)都能进行良好的布局 2.可以以逆序 或者 以任意顺序排列布局 3.可以线性的沿着主轴一字排开 或者 沿着侧轴换行排列 4.可以弹性的在任意的容器 ...
- shell练习--PAT题目1005:继续(3n+1)猜想(全绿失败喜加一)
卡拉兹(Callatz)猜想已经在1001中给出了描述.在这个题目里,情况稍微有些复杂. 当我们验证卡拉兹猜想的时候,为了避免重复计算,可以记录下递推过程中遇到的每一个数.例如对 n=3 进行验证的时 ...
- PHP 发邮件《转》
导读:PHP自带的mail()函数,是php内置发邮件的函数,该函数虽然简单,但是要想真正可以发邮件得有很复杂的配置.不适合新手,以及项目实际的应用的开发. php的mail()函数复杂配置,使得直接 ...
- [design pattern](5) Factory Method
前言 在前面一章博主介绍了简单工厂模式(Simple Factory),接着上面的章节,今天博主就来介绍下工厂方法模式(Factory Method). 思考题 首先,让我们来思考下面的问题: 在上一 ...
- 【每日一包0005】arr-flatten
github地址:https://github.com/ABCDdouyae... arr-flatten 将多维数组展开成一维数组 文档地址:https://www.npmjs.com/packag ...
- Codeforces Aim Tech Round4 (Div2) D
题目链接: 题意: 给你一个严格升序的单链表,但是是用数组来存放的.对于每一个位置来说,你可以知道这个位置的值和下一个的位置.你每一个可以询问一个位置,机器会告诉你这个位置的值,和下一个位置的指针.要 ...
- VLC for Android编译
编译环境是ubuntu 64bit 全程参考https://wiki.videolan.org/AndroidCompile/ 一:环境准备 1.安装系统 尽量使用最新的ubuntu系统 可以省去很多 ...
- mysql高水位问题解决办法
数据库中有些表使用delete删除了一些行后,发现空间并未释放产生原因:类比Oracle的高水位线产生原理 delete 不会释放文件高水位 truncate会释放 ,实际是把.ibd文件删掉了,再建 ...
- RAC_单实例_DG 关于两端创建表空间数据文件路径不一致的问题注意点
RAC_单实例_DG 关于两端创建表空间数据文件路径不一致的问题注意点 主库SYS@orcl1>show parameter db_file_name_convert NAME TYPE VAL ...
- 四十、python中的生成器和迭代器
A.生成器(包含yield的就是生成器) def func(): print(11) yield 1 print(22) yield 2 print(33) yield 3 print(44) yie ...