python 图像处理中二值化方法归纳总结
python图像处理二值化方法
在用python进行图像处理时,二值化是非常重要的一步,现总结了自己遇到过的 6种 图像二值化的方法(当然这个绝对不是全部的二值化方法,若发现新的方法会继续新增)。
1. opencv 简单阈值 cv2.threshold
2. opencv 自适应阈值 cv2.adaptiveThreshold (自适应阈值中计算阈值的方法有两种:mean_c 和 guassian_c ,可以尝试用下哪种效果好)
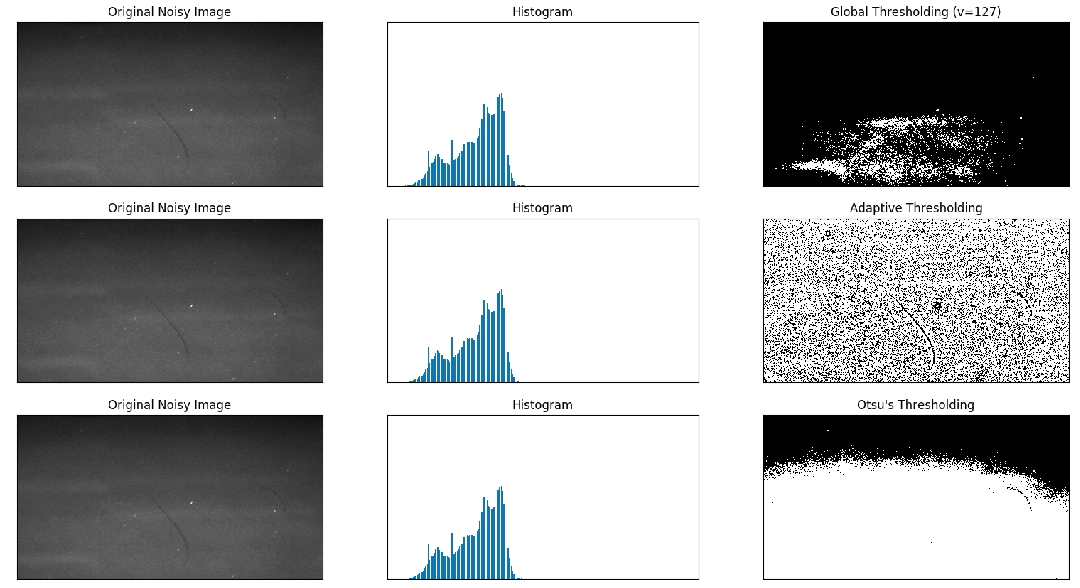
3. Otsu's 二值化
例子:
来自 : OpenCV-Python 中文教程
import cv2
import numpy as np
from matplotlib import pyplot as plt img = cv2.imread('scratch.png', 0)
# global thresholding
ret1, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
# Otsu's thresholding
th2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2)
# Otsu's thresholding
# 阈值一定要设为 0 !
ret3, th3 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# plot all the images and their histograms
images = [img, 0, th1, img, 0, th2, img, 0, th3]
titles = [
'Original Noisy Image', 'Histogram', 'Global Thresholding (v=127)',
'Original Noisy Image', 'Histogram', "Adaptive Thresholding",
'Original Noisy Image', 'Histogram', "Otsu's Thresholding"
]
# 这里使用了 pyplot 中画直方图的方法, plt.hist, 要注意的是它的参数是一维数组
# 所以这里使用了( numpy ) ravel 方法,将多维数组转换成一维,也可以使用 flatten 方法
# ndarray.flat 1-D iterator over an array.
# ndarray.flatten 1-D array copy of the elements of an array in row-major order.
for i in range(3):
plt.subplot(3, 3, i * 3 + 1), plt.imshow(images[i * 3], 'gray')
plt.title(titles[i * 3]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 2), plt.hist(images[i * 3].ravel(), 256)
plt.title(titles[i * 3 + 1]), plt.xticks([]), plt.yticks([])
plt.subplot(3, 3, i * 3 + 3), plt.imshow(images[i * 3 + 2], 'gray')
plt.title(titles[i * 3 + 2]), plt.xticks([]), plt.yticks([])
plt.show()
结果图:
4. skimage niblack阈值
5. skimage sauvola阈值 (主要用于文本检测)
例子:
https://scikit-image.org/docs/dev/auto_examples/segmentation/plot_niblack_sauvola.html
import matplotlib
import matplotlib.pyplot as plt from skimage.data import page
from skimage.filters import (threshold_otsu, threshold_niblack,
threshold_sauvola) matplotlib.rcParams['font.size'] = 9 image = page()
binary_global = image > threshold_otsu(image) window_size = 25
thresh_niblack = threshold_niblack(image, window_size=window_size, k=0.8)
thresh_sauvola = threshold_sauvola(image, window_size=window_size) binary_niblack = image > thresh_niblack
binary_sauvola = image > thresh_sauvola plt.figure(figsize=(8, 7))
plt.subplot(2, 2, 1)
plt.imshow(image, cmap=plt.cm.gray)
plt.title('Original')
plt.axis('off') plt.subplot(2, 2, 2)
plt.title('Global Threshold')
plt.imshow(binary_global, cmap=plt.cm.gray)
plt.axis('off') plt.subplot(2, 2, 3)
plt.imshow(binary_niblack, cmap=plt.cm.gray)
plt.title('Niblack Threshold')
plt.axis('off') plt.subplot(2, 2, 4)
plt.imshow(binary_sauvola, cmap=plt.cm.gray)
plt.title('Sauvola Threshold')
plt.axis('off') plt.show()
结果图:

6. IntegralThreshold (主要用于文本检测)
使用方法: 运行下面网址的util.py文件
https://github.com/Liang-yc/IntegralThreshold
结果图:

7.
python 图像处理中二值化方法归纳总结的更多相关文章
- Python实现熵值法确定权重
本文从以下四个方面,介绍用Python实现熵值法确定权重: 一. 熵值法介绍 二. 熵值法实现 三. Python实现熵值法示例1 四. Python实现熵值法示例2 一. 熵值法介绍 熵值法是计算指 ...
- 深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)(转)
转自: https://zhuanlan.zhihu.com/p/22252270 ycszen 另可参考: https://blog.csdn.net/llx1990rl/article/de ...
- 《零压力学Python》 之 第二章知识点归纳
第二章(数字)知识点归纳 要生成非常大的数字,最简单的办法是使用幂运算符,它由两个星号( ** )组成. 如: 在Python中,整数是绝对精确的,这意味着不管它多大,加上1后都将得到一个新的值.你将 ...
- python排序之二冒泡排序法
python排序之二冒泡排序法 如果你理解之前的插入排序法那冒泡排序法就很容易理解,冒泡排序是两个两个以向后位移的方式比较大小在互换的过程好了不多了先上代码吧如下: 首先还是一个无序列表lis,老规矩 ...
- Python图像处理库:Pillow 初级教程
Python图像处理库:Pillow 初级教程 2014-09-14 翻译 http://pillow.readthedocs.org/en/latest/handbook/tutorial.html ...
- 使用Python,字标注及最大熵法进行中文分词
使用Python,字标注及最大熵法进行中文分词 在前面的博文中使用python实现了基于词典及匹配的中文分词,这里介绍另外一种方法, 这种方法基于字标注法,并且基于最大熵法,使用机器学习方法进行训练, ...
- Python图像处理之验证码识别
在上一篇博客Python图像处理之图片文字识别(OCR)中我们介绍了在Python中如何利用Tesseract软件来识别图片中的英文与中文,本文将具体介绍如何在Python中利用Tesseract ...
- Python的生成器进阶玩法
Python的生成器进阶玩法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.yield的表达式形式 #!/usr/bin/env python #_*_coding:utf-8 ...
- Python字典按值排序的方法
Python字典按值排序的方法: 法1: (默认升序排序,加 reverse = True 指定为降序排序) # sorted的结果是一个list dic1SortList = sorted( di ...
随机推荐
- 基于ELK Stack7.1.0构建多用户安全认证日志系统
配置tls加密通信及身份验证,主要目的是为了确保集群数据安全.在es早期版本,安全认证相关功能都属于商业付费服务,一般普通公司如果集群部署在内网,基本上就忽略了这些安全认证,当然也可以通过Ngin ...
- iOS7上leftBarButtonItem无法实现滑动返回的完美解决方案
今天遇到了在iOS7上使用leftBarButtonItem却无法响应滑动返回事件的问题,一番谷歌,最后终于解决了,在这里把解决方案分享给大家. 在iOS7之前的系统,如果要自定义返回按钮,直接设置b ...
- php常用端口号
常见端口号 Nginx 80 Nginx (“engine x”) 是一个高性能的HTTP和反向代理服务器,也是一个IMAP/POP3/SMTP服务器. MySQL 3306 MySQL是一种关系数据 ...
- java 将数据库中的每一条数据取出放入数组或者List中
1.如何将数据库中数据按照行(即一整条数据)取出来,存入到数组当中? public static String str = null; // 将StringBuffer转化成字符串 public st ...
- Linux远程登录工具XShell安装
Xshell就是一个远程控制RHEL的软件:其他的还有很多,用什么都无所谓(根据公司情况). 下面我们来安装下这个工具: 双击exe 点下一步: 选 免费的 然后下一步:(免费的功能足够用了) 点接受 ...
- 专人写接口+模型,专人写业务逻辑---interface_model -- business logical
专人写接口+模型,专人写业务逻辑---interface_model -- business logical 0-控制台脚本重构为“面向接口编程”:1-仓库类通过__constru方法,来实现一处实例 ...
- 第 12 章 python并发编程之协程
一.引子 主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只用一个)情况下实现并发,并发的本质:切换+保存状态 cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作 ...
- 深入探讨vue响应式原理
现在是时候深入一下了!Vue 最独特的特性之一,是其非侵入性的响应式系统.数据模型仅仅是普通的 JavaScript 对象.而当你修改它们时,视图会进行更新.这使得状态管理非常简单直接,不过理解其工作 ...
- servlet--response、request
请求响应流程图 response 1 response概述 response是Servlet.service方法的一个参数,类型为javax.servlet.http.HttpServle ...
- 02 - Jmeter4.x正则表达式以及跨线程使用变量
话不多说 直接开撸 上图可以看出,有两个请求,其中第二个请求返回了登录超时,结合第一个登录接口来看,这个是需要header请求内容的也就是 token:当然设置一个token又怎么可能难得倒我们,无非 ...