Paper Reading_Distributed System
最近(以及预感接下来的一年)会读很多很多的paper......不如开个帖子记录一下读paper心得
Mark一个上海交通大学东岳网络工作室的paper notebook
Mark一个大神的笔记
Edge computing
DLion: Decentralized Distributed Deep Learning in Micro-Clouds
在Distributed DL中,一个很常见的场景就是要在edge侧(Edge Device表示性能和稳定性都不太好的设备,比如用流量上网的手机)得到一些新的数据,然后去refine一个之前已经train好的model(incrementalor online deep learning over newly generated data in real-time)。但是广域网是很慢的,如果要所有edge把数据传给一个总服务器要耗费很大的带宽,而且现在手机的性能已经有点够用了,所以我们希望搞个decentralize的DL framework,直接在edge侧就解决问题。
相对于纯Decentralize DL的工作,本文提出了一个micro-cloud的概念:micro-clouds—small-scale clouds deployed near edge devices in many different locations(用于给本地的一小部分edge服务,感觉有点类似CDN的意思?),然后重点关注如何在micro-cloud内部去实现Distributed DL。micro-cloud内部具有如下特点:每个node的性能(计算资源)有差异;网络情况有差异;micro-cloud的总量是很大的,而且分布在不同地区。本文就要针对这三个问题,既要提高速度也要提高accuracy,然后还得handle system scalability。
- ch3.1:每个node的性能(计算资源)有差异,那么每个node根据自己的能力来设置batch size就完了。另外还应用了三种learning rate的调节方式。
- ch3.2:为了保证性能,node之间的数据通信涉及到交换weights和gradient。然后我们需要实时根据网络情况(controlling the quality of data and considering the available network bandwidth)来调整通信策略。这个又要考虑以下几个因素:
- when-to-do: when to exchange data, e.g., more frequently early or late in training, or periodically
- what-to-do: whether to exchange whole or partial data
- whom-to-do: whether to exchange data with all workers or a subset of workers
- how-to-do: whether to exchange data synchronously or asynchronously
这些是通过一个system parameter来调节的。然后Fig4和Fig5展示了不同策略的实验效果。
- ch3.3:在system scalability这里,我们要考虑的是在WAN环境下,不同micro-cloud之间的通信问题啦,这个涉及到broadcast gradient。本文选择了只在两个micro-cloud之间通信,而不是直接broadcasting。然后根据micro-cloud各自的特征来选择谁是sender/receiver:性能好的batch size大(ch3.1),会有更多的informative gradient,所以作为sender。反之就作为receiver。micro-cloud之间的通信也采用ch3.2里提到的方法。
Future work:
- 用更大的scale来实验
- data migration:低性能的node上可能数据多。在migrate和load balancing(ch3.1)之间要有个tradeoff
- 考虑edge device的电量消耗问题
DeCaf: Iterative Collaborative Processing over the Edge
最近有一个很火的概念叫做Federated Learning:意思就是在不能接触到数据(因为可能涉及用户隐私)的情况下来训练ML model。那么在geo-distributed以及edge computing的场景下,就需要在不能将用户数据从edge侧传到central服务器的前提下analysis data(there is a need for approaches which enable analytics without transferring the raw data out of the edge devices.)。本文的idea就是解决在edge设备上performing ICP computation时,如何处理geo-distributed的edge device的drop out率太高等问题,并设计了一套计算框架。
(ICP的含义[ch3.1]:Iterative Collaborative Processing(ICP) involves performing a set of computations in multiple iterations. ML中的training就是一种典型的ICP。比如在典型的参数服务器系统中,中心服务器上维护一套中心的parameter,各个edge负责用本地的数据训练自己的individual parameter,再和central进行同步。)
Related work中涉及到如下几个方面:1).Distributed ML system有很多,最著名的是parameter server,但它是centralized。2).Geo-distributed的系统也有很多,但针对ML workload的研究还不多。3).Federated ML的框架也有一些,但没有考虑edge computing中的一些场景:比如edge device经常会drop out(没电了或者关流量了)。 【所以知道idea都是怎么憋出来的了吧?】
我们这个system是一个星型拓扑的结构:所有edge连接到central controller上,但其实edge之间也可以P2P的通信。所有edge把本地计算结果推给controller,controller更新model parameter,再更新所有edge上的parameter。这个system要实现以下几个feature:
- 1. Proactive(主动的) Monitoring and Prediction
- edge设备的计算资源是很奇怪的(high variations in resource availability over time in edge environments),因此我们需要对edge device的资源(比如cpu使用率、剩余电量、网速等)进行实时监控,在后面会用到这些监控数据。这个就是很工程的东西了...安个鲁大师就行了hhhh
- 另外还可以通过记录过去的resource utilization pattern,来试着预测未来的resource availability。有些related work表明这玩意其实也是可以ML的...(the application usage on mobile devices indeed exhibits temporal patterns)。
- 2. Adaptive Tuning
- 在controller向edge分发计算任务后,edge就开始计算啦,当然这个也是会被controller指定一个deadline的。为了确保every edge device finishes the model update within the deadline stipulated by the controller,有些edge device可能等不及处理完所有的数据,就要把结果发给central了(based on the resource availability, we can choose a subset of data points to iterate through)。当然这个subset的percentage的选择也是很有讲究的,需要在保证能赶得上deadline的情况下,选择尽量多的percentage(因为数据多的训练效果肯定好嘛,参考Fig2)
- 那么这个percentage怎么选呢?可以构建一个resource-computation profile,意思就是根据当前device的resource availability来选择这个percentage。构建这个profile也是个很工程的东西(大体意思和鲁大师跑个分差不多......)
- 本文中使用了一个比较基本的方法:在计算的过程中,根据已经计算了的数据量和已用时间,来推算deadline前还能处理多少数据。实验证明这个方法还可以。
- 3. Fault Tolerance and Load Balancing
- 前面说过数据太少的时候,训练出来的模型的quality是不大能用的。那么如果当前设备的available resource实在太少(比如快没电了),完成不了多少运算了,就需要直接放弃这个设备(也就是drop out),然后migrating the task to another edge device。但是在Federated Learning的场景下,migrate也要考虑用户数据的隐私问题。因此提出了下面的概念:Trusted Device Set。
- Trusted Device Set:每个设备都可以指定自己的一个Trusted Device Set,表示数据可以在这些设备之间进行migrate(比如一个人有很多个手机、电脑、平板)。当某个设备发现自己蹦跶不了多久了,需要migrate时,就像trust set里的设备发出请求,然后在respond了的设备中选择一个migrate成本最小的进行migrate。因为local dataset一般是很小的,所以这个开销也不会很大。
- 另外,在load balancing中,可能也会涉及到migration。比如把负责太重的device上的workload移到它的trust set中负载较轻的设备里。
本文以SVM为例测试了整个framework的效果。
An Edge-based Framework for Cooperation in Internet of Things Applications
111
Cloud
Rethinking Adaptability in Wide-Area Stream Processing Systems
111
Multi-Query Optimization in Wide-Area Streaming Analytics
这是SOCC2018的一篇文章,关注的是如何在Geo-Distributed的情况下进行data analysis,提高WAN bandwidth的使用效率并提高性能。
在streaming analysis query中,很多情况下执行情况都是类似的,比如使用相同的input dataset或者perform the same data processing procedure(比如大家都用Twitter data,只是进行的analyze任务不同,有人做sentiment analysis,有人做topic啥的),这种就是本文所说的multi-query。本文的idea关注的就是optimizing multiple queries by applying multi-query optimization in a WAN-aware manner。这里有两个key point:multi-query optimization、WAN awareness(这是为保证multi-query的性能必须要加的)。
Streaming按照computional model又可以分为两类:dataflow和bulk-synchronous parallel。本文先focus on dataflow model,意思是data streams flow continuously
from data sources into the system and are transformed by a set of stream operators。streaming query可以被视为像SQL一样的查询语句。另外,本文中的系统是geo-distributed,意味着数据可能一开始存在A地,然后由B地的服务器处理,又交给C地的用户,数据就要飞过来飞过去。如果系统能对WAN的拓扑结构有所了解,就可以设计更优化的执行方案了。这也就是需要WAN-aware的原因。
Multi-Query Optimization这个概念也是在DB那边学来的,目的是identify the commonality between queries and potentially combine their executions to mitigate redundant executions。另外在我们这个场景中,Multi-Query Optimization需要be done in an online manner as new queries arrive by sharing any common execution incrementally。因为streaming analysis query通常都是deployed once and run indefinitely,中间停个机改一改是不现实的。2.2节的后半部分举了个例子:Query1和Query2虽然业务逻辑不完全相同,但仍然有很多可以share的元素(both queries partially share common input streams (US and EU) and perform similar data processing (e.g., filtering user info)),如果这些只执行一次就可以省下很多带宽。
下面详细介绍下这两个组件:
- Multi-Query Optimization:
- WAN-aware Optimization:
Wiera: Policy-Driven Multi-Tiered Geo-Distributed Cloud Storage System
本文关注的是Cloud Storage System的问题,重点关注在storage system具有很多tier(专门为不同application优化的,不同种类的Storage System。比如ElasticCache/S3/...)、分布在很多location(multi-DC)的情况下,如何进行data placement。目标是achieve desired fault tolerance or to serve a dispersed set of end-users。
本文提出了一个叫做Wiera的存储系统,将data placement的问题抽象成一个constrained optimization problem(比如minimize total cost),然后用一些算法来优化它。另外还要处理一些类似fault tolerance之类的问题。
看起来很像5105的pa3啊......一致性协议都用的一样的Quorum......
Distributed ML
Decentralized distributed deep learning in heterogeneous WAN environments
这篇文章的idea一目了然:在geo-distributed的节点上进行Decentralized DL
这个场景下的Decentralized DL是有很多问题要解决的:
- WAN网络带宽很有限
- 节点之间计算能力差异很大,容易导致训练变慢,甚至不coverage
本文感觉没有提出啥自己的idea......就总结了下面几个方法,然后implement了一个framework:
- automatically adjust:
- 1) the frequency of parameter sharing
- 2) the size of parameters shared depending on individual network bandwidth and data processing power
- 3) introduces a new scaling factor to control the degree of contribution to parameter updates by considering the amount of data trained during unit time in each device.
本文主要参考了Ako这篇文章,他们通过sharing partial parameters来减少了通信开销。
好水啊。。。
Link:
https://www-users.cs.umn.edu/~chandra/tfako/home.html
Ako: Decentralised Deep Learning with Partial Gradient Exchange
23333
Towards Federated Learning at Scale: System Design
联邦学习是一个最近提出的概念。大概意思就是:假设A和B各自有不同数据,由于隐私需要他们的数据都不能公开,但A、B各自训练的小模型都不大好。因此他们希望结合AB双方的数据,来训练一个比较好的大模型。
联邦学习是要解决这个问题: 它希望做到各个企业的自有数据不出本地,而后联邦系统可以通过加密机制下的参数交换方式,即在不违反数据隐私法规情况下,建立一个虚拟的共有模型。这个虚拟模型就好像大家把数据聚合在一起建立的最优模型一样。但是在建立虚拟模型的时候,数据本身不移动,也不泄露隐私和影响数据合规。这样,建好的模型在各自的区域仅为本地的目标服务。在这样一个联邦机制下,各个参与者的身份和地位相同,而联邦系统帮助大家建立了“共同富裕”的策略。 这就是为什么这个体系叫做“联邦学习”。
因为数据是分散在各地的,联邦学习天然的自带分布式属性。本文通过一个例子来关注联邦学习系统的system design,目的是对于很多手机上的data训练一个global的模型,同时要保证这些data不能离开手机本地。The weights are combined in the cloud with Federated Averaging。Federated Learning System的大致流程如下:
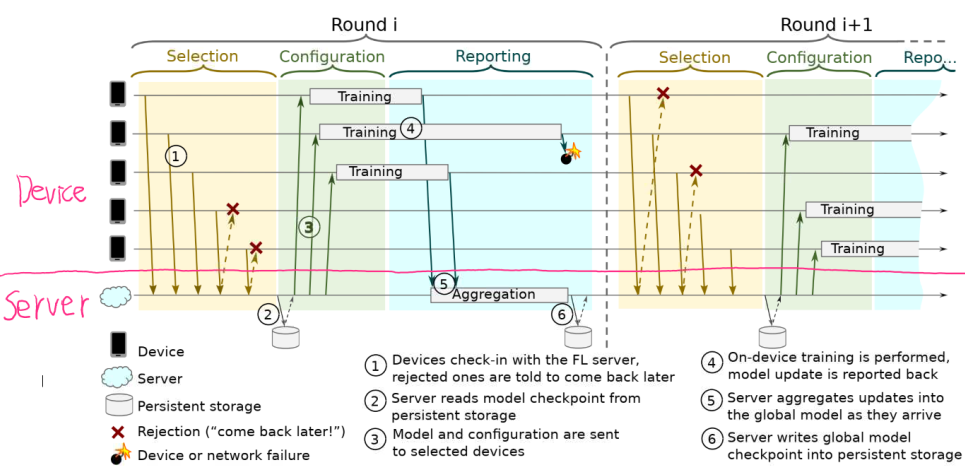
- (1)、Device们联系FL Server,申请加入当前轮的FL job。但是Device太多啦,目前只能先接受一部分Device。剩下的下一轮再说。(这个选择策略参考ch2.2的selection部分)
- (2)(3)、FL Server从persistent store(可以理解成server的硬盘)读取模型,然后将current global model parameters打包成FL checkpoints,发给参与本次任务的device们。
- (4)、所有的device使用收到的model和本地的data,在本地进行training(performs a local computation based on the global state and its local dataset)。完了之后将更新后的FL checkpoints发回FL server。
- (5)、FL server根据devices发来的checkpoints进行incorporate(比如使用Federated Averaging),更新global的模型。然后GOTO (1)开始下一轮的job。
Fault tolerance:在(4)中没有按时向FL server返回checkpoints的device会被直接丢弃。而在(1)的select阶段中, 也会有一个timeout或者counter之类的约束规则。
Flow control:ch2.3
接下来分别来看两个重要的部件:Device(ch3)和Server(ch4)。这两节讲的比较工程化......
- Device:Device上要存储本地的training data。还要通过一个schedule来控制启动training。
- FL Server:FL server的实现基于Actor Programming Model,这是一种并发编程中的常用模型,用于处理系统中不同部件的通信和并发控制。整个结构如图Fig3所示。
- Selector:负责直接和device通信。device请求加入时也是和selector联系,selector选好设备后forward给Aggregator。selector相当于公司的HR...
- Aggregator:又分为master aggregator和aggregator,用于管理FL task中的每一轮。相当于公司里的一个个部门
- Coordinator:负责控制整个FL训练的流程。比如要决定需要多少device然后报告给selector。然后让Aggregator来具体管理FL task。相当于公司的老总...
Secure Aggregation:uses encryption to make individual devices` updates uninspectable by a server.
上面balabala了这么多理论,那么一个FL模型的开发和上线过程是什么样的呢?可以分解为这么几步:
- Modeling and simulation:指的是MLE在本地先写好model(个人理解就像平时写个deep learning模型一样)。这里提出了proxy data的概念:MLE用来模拟用户端training data的一些data(Proxy data is similar in shape to the on-device data but drawn from a different distribution – for example, text from Wikipedia may be viewed as proxy data for text typed on a mobile keyboard.)。MLE在开发阶段可以拿这些data来调试自己的模型。同时可以用simulated FL server and devices来模拟FL的场景。
- Plan Generation:一个FL Plan可以理解为MLE针对某个任务开发好的FL模型,FL Plan会被部署到device和server上。device端包括tensorflow graph、模型的一些参数(比如batch size、epoch之类)、还有对training data的一些处理规则。而server端包括aggregation logic(用于把各个device的模型拼起来)。
正好学姐让我implement一下......那来看看用tensorflow如何实现吧!
Scaling Distributed Machine Learning with the Parameter Server
https://blog.csdn.net/stdcoutzyx/article/details/51241868
Streaming
TTL-based Approach for Data Aggregation in Geo-Distributed Streaming Analytics
这是一篇OSDI poster,后来转手就中了SIGMETRICS....orz
A TTL-based Approach for Data Aggregation in Geo-distributed Streaming Analytics
就是上面poster对应的长文...
Others
Flexible Paxos: Quorum intersection revisited
https://www.bilibili.com/video/av70763749
https://www.zhihu.com/question/320838210
....
Paper Reading_Distributed System的更多相关文章
- Paper Reading
Paper Reading_SysML Paper Reading_Computer Architecture Paper Reading_Database Paper Reading_Distrib ...
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
- 64位下pwntools中dynELF函数的使用
这几天有同学问我在64位下怎么用这个函数,于是针对同一道题写了个利用dynELF的方法 编译好的程序 http://pan.baidu.com/s/1jImF95O 源码在后面 from pwn im ...
- 深入解析SQL Server并行执行原理及实践(上)
在成熟领先的企业级数据库系统中,并行查询可以说是一大利器,在某些场景下他可以显著的提升查询的相应时间,提升用户体验.如SQL Server, Oracle等, Mysql目前还未实现,而Postgre ...
- 谷歌三大核心技术(三)Google BigTable中文版
谷歌三大核心技术(三)Google BigTable中文版 Bigtable:一个分布式的结构化数据存储系统 译者:alex 摘要 Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海 ...
- Java实现打印功能
用java实现打印,java.awt中提供了一些打印的API,要实现打印,首先要获得打印对象,然后继承Printable实现接口方法print,以便打印机进行打印,最后用Graphics2D直接输出直 ...
- Hibernate(七)一对一映射
一.创建数据库表 --班级表 create table grade ( gid number primary key, --班级ID gname ), --班级名称 gdesc ) --班级介绍 ); ...
- NAND Flash memory in embedded systems
参考:http://www.design-reuse.com/articles/24503/nand-flash-memory-embedded-systems.html Abstract : Thi ...
- Java实现打印功能-AWT Graphics2D
Java实现打印功能 用java实现打印,java.awt中提供了一些打印的API,要实现打印,首先要获得打印对象,然后继承Printable实现接口方法print,以便打印机进行打印,最后用用Gra ...
随机推荐
- UVa 1343 The Rotation Game (状态空间搜索 && IDA*)
题意:有个#字型的棋盘,2行2列,一共24个格. 如图:每个格子是1或2或3,一共8个1,8个2,8个3. 有A~H一共8种合法操作,比如A代表把A这一列向上移动一个,最上面的格会补到最下面. 求:使 ...
- UVa 10603 Fill (BFS && 经典模拟倒水 && 隐式图)
题意 : 有装满水的6升的杯子.空的3升杯子和1升杯子,3个杯子中都没有刻度.不使用道具情况下,是否可量出4升水呢? 你的任务是解决一般性的问题:设3个杯子的容量分别为a, b, c,最初只有第3个杯 ...
- golang rabbitmq实践 (一 rabbitmq配置)
1:环境选择 系统为ubuntu 15.04 ,我装在虚拟机里面的 2:rabbitmq tabbitmq 3.5.4 download url : http://www.rabbitmq.com/ ...
- vue 使用 vue-awesome-swiper (基础版)
1.0 安装 vue-awesome-swiper(稳定版本 2.6.7) npm install vue-awesome-swiper@2.6.7 --save 2.0 引入配置(全局使用) 2.1 ...
- Java并发编程的艺术笔记(二)——wait/notify机制
一.概述 一个线程修改了一个对象的值,另一个线程感知到变化从而做出相应的操作.前者是生产者,后者是消费者. 等待/通知机制,是指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B调用 ...
- hadoop stop-dfs.sh 无法停止 namenode datanode
原因: HADOOP_PID_DIR 默认为 /tmp 目录,如果长期不访问/tmp/目录下的文件,文件会被自动清理,因此 stop-dfs.sh 无法根据 pid 停止 namenode, data ...
- 修改web项目发布路径
Eclipse中用Tomcat发布的Web项目,更改其部署路径 我的Eclipse的工作目录是D:/workspace先配置Tomcat 选择你的tomcat版本 点击next 这里先不要把项目添加进 ...
- (C++C#类型互转工具)使用Signature Tool自动生成P/Invoke调用Windows API的C#函数声明
在网上看到很多网友在.NET程序中调用Win32 API,或者调用自己的VC DLL里面提供的函数的时候,总是被生成正确的C函数在C#中的正确声明而困扰,而生成C++中结构体在C#中的声明 - 天,没 ...
- 硬件-硬盘-SSD(固态硬盘):百科
ylbtech-硬件-硬盘-SSD(固态硬盘):百科 固态驱动器(Solid State Disk或Solid State Drive,简称SSD),俗称固态硬盘,固态硬盘是用固态电子存储芯片阵列而制 ...
- 细数EDM营销中存在的两大盲点
国庆节了,祝大家国庆快乐,转眼博客至今已有三年了.下面博主为大家介绍EDM营销中存在的两大盲点,供大家参考. 一是忽略用户友好.用户友好策略是Email营销成功的关键要素,具体包括内容友好策略.方式友 ...