大数据笔记(四)——操作HDFS
一.Web Console:端口50070
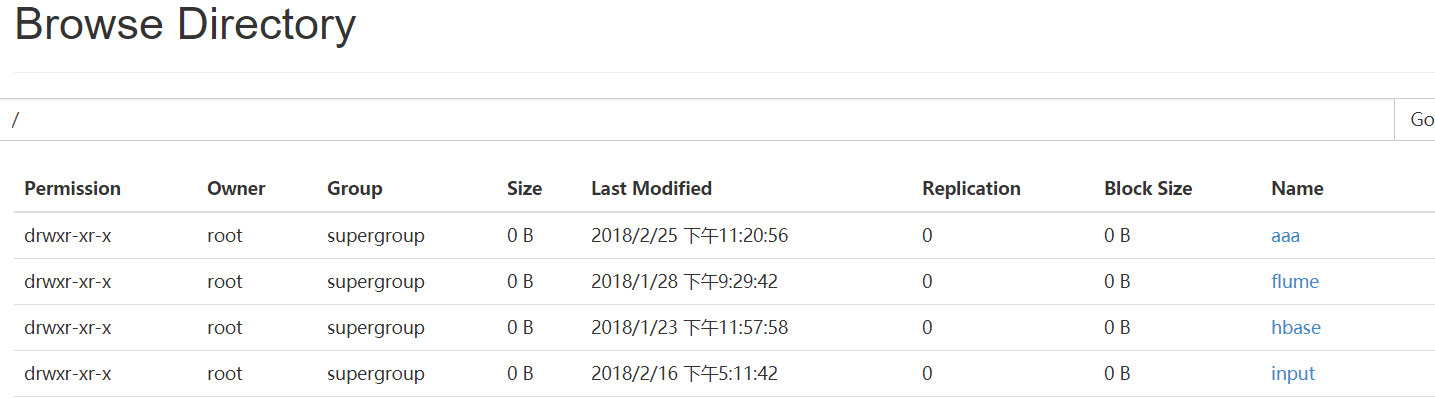
二.HDFS的命令行操作
(一)普通操作命令
HDFS 操作命令帮助信息: hdfs dfs + Enter键
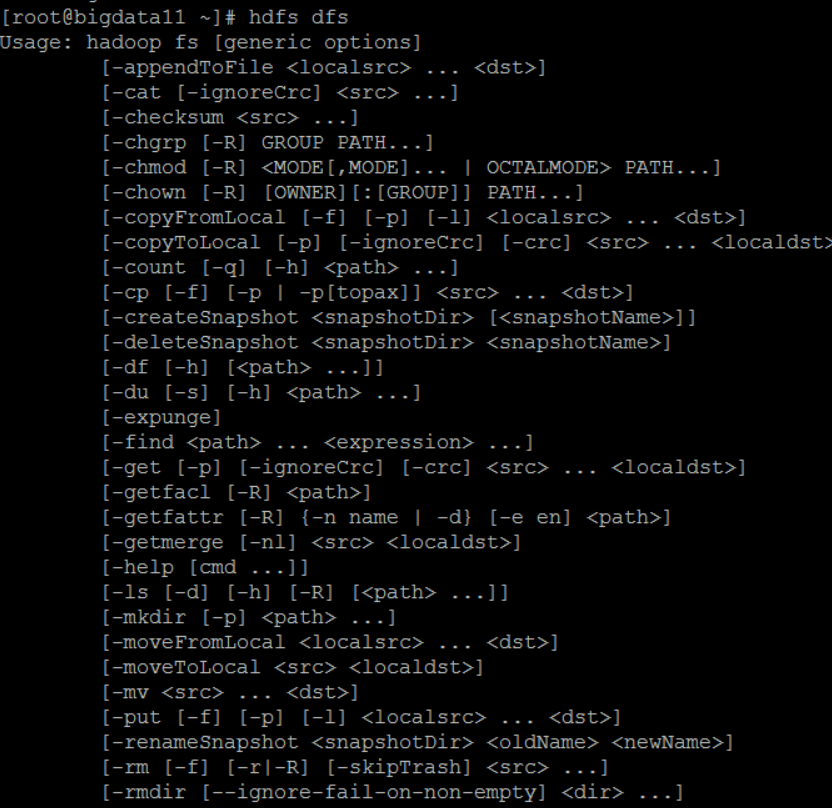
常见命令
1. -mkdir
- 在HDFS上创建目录:hdfs dfs -mkdir /aaa
- 如果父目录不存在,使用 -p 命令先创建父目录:

2. -ls /
查看hdfs文件系统根目录下的目录和文件:

3.-ls -R /
查看所有目录和文件:

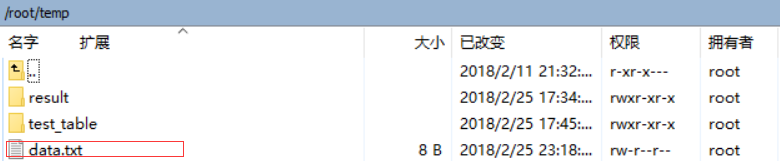
4.-put
上传数据:将本地Linux文件data.txt上传到HDFS的aaa目录下
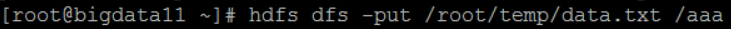
-copyFromLocal 上传数据,类似-put
-moveFromLocal 上传数据,类似-put,相当于ctrl+x
5.-get 下载数据(刚才上传数据时已经有data.txt,所以要把Linux目录下的data.txt先删除)

6.-rm: 删除目录
-rmr: 删除目录,包括子目录
hdfs dfs -rmr /bbb

7. -getmerge:把某个目录下的文件,合并后再下载
8.-cp:拷贝 hdfs dfs -cp /input/data.txt /input/data2.txt
9.-mv:移动 hdfs dfs -cp /input/data.txt /aaa/a.txt
10.-count 统计hdfs对应路径下的目录个数,文件个数,文件总计大小:hdfs dfs -count /students

11.-du 显示hdfs对应路径下每个文件夹和目录的大小 hdfs dfs -du /students

12.-cat 查看文本的内容 hdfs dfs -cat /input/data.txt

13.balancer:平衡操作 如果管理员发现某些DataNode上保存数据过多,某些过少,就可以采取此操作
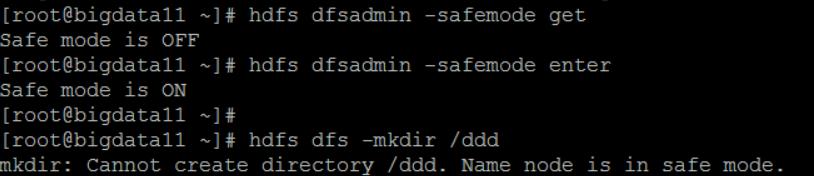
(二)管理命令:hdfs dfsadmin
举例:
1.-report 打印hdfs的报告 hdfs dfsadmin -report
2.-safemode:安全模式(安全模式下对hdfs只能进行只读操作)

三.JavaAPI
通过HDFS提供的JavaAPI,我们可以完成以下的功能:
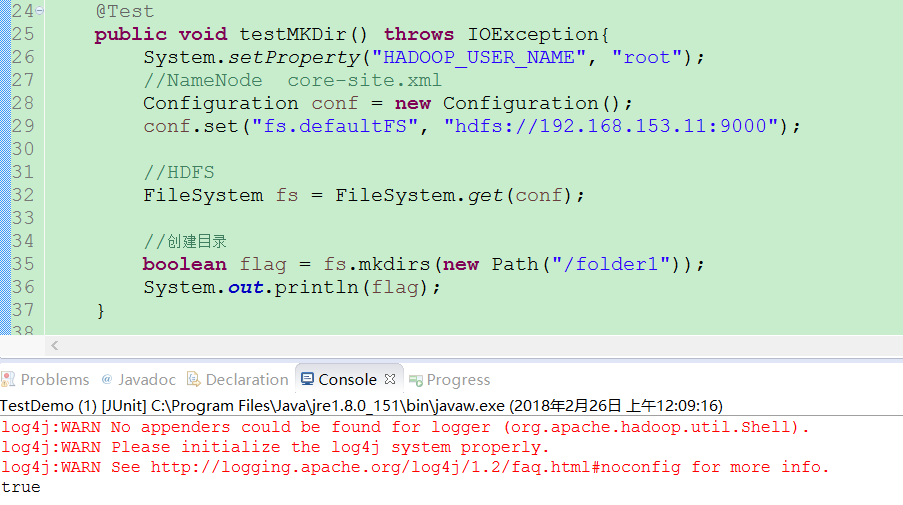
(一)在HDFS上创建目录
(二)写入数据(上传文件)
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test; import com.jcraft.jsch.Buffer; public class TestUpload { @Test
public void testUpload() throws IOException{
System.setProperty("HADOOP_USER_NAME", "root");
//NameNode core.site.xml
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.153.11:9000"); //构造一个输入流 <---HDFS
FileSystem fs = FileSystem.get(conf); InputStream in = new FileInputStream("D:\\temp\\hadoop-2.7.3.tar.gz"); //构造一个输出流------> HDFS
OutputStream out = fs.create(new Path("/tools/hadoop-2.7.3.tar.gz")); byte[] buffer = new byte[1024];
int len = 0; while ((len=in.read(buffer)) > 0) {
out.write(buffer, 0, len);
} out.flush(); in.close();
out.close(); }
}
(三)通过 FileSystem API 读取数据(下载文件)
(四)查看目录及文件信息
(五)查找某个文件在HDFS集群的位置
(六)删除数据
(七)获取HDFS集群上所有数据节点信息

大数据笔记(四)——操作HDFS的更多相关文章
- 大数据学习——java操作hdfs环境搭建以及环境测试
1 新建一个maven项目 打印根目录下的文件的名字 添加pom依赖 pom.xml <?xml version="1.0" encoding="UTF-8&quo ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- Dapper学习(四)之Dapper Plus的大数据量的操作
这篇文章主要讲 Dapper Plus,它使用用来操作大数量的一些操作的.比如插入1000条,或者10000条的数据时,再使用Dapper的Execute方法,就会比较慢了.这时候,可以使用Dappe ...
- 大数据笔记04:大数据之Hadoop的HDFS(基本概念)
1.HDFS是什么? Hadoop分布式文件系统(HDFS),被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点. 2.HDFS ...
- 大数据笔记09:大数据之Hadoop的HDFS使用
1. HDFS使用: HDFS内部中提供了Shell接口,所以我们可以以命令行的形式操作HDFS
- 大数据-hadoop生态之-HDFS
一.HDFS初识 hdfs的概念: HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色 HDFS设计适合一次 ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述 1' DFS 分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.该系统架构 ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
随机推荐
- 正斜杠"/"与反斜杠"\"
刚开始做前端,发现前端路径都用正斜杠"/"与Windows下路径定义完全不同 查了一下资料总结如下: Windows 用反斜杠(“\”)的历史来自 DOS,而 DOS 的另一个传统 ...
- C++基础-类和对象
本文为 C++ 学习笔记,参考<Sams Teach Yourself C++ in One Hour a Day>第 8 版.<C++ Primer>第 5 版.<代码 ...
- python3—廖雪峰之练习(二)
函数的参数练习 请定义一个函数quadratic(a, b, c), 接收3个参数,返回一元二次方程 : $ ax^2+b+c=0 $ 的两个解 提示:计算平方根可以调用math.sqrt()函数: ...
- thinkPHP三级城市联动
html+js: <!doctype html> <html lang="en"> <head> <meta charset=" ...
- 结构体指针,C语言结构体指针详解
结构体指针,可细分为指向结构体变量的指针和指向结构体数组的指针. 指向结构体变量的指针 前面我们通过“结构体变量名.成员名”的方式引用结构体变量中的成员,除了这种方法之外还可以使用指针. 前面讲过,& ...
- 自动布局(storyboard,code)
xcode 6使用storyboard 进行自动布局,迷惑的问题主要由: 1,classsize 到底是一个什么东东? 2,classSize 和 layout 有什么区别? 3, 如何使用stor ...
- 019-openstack组件使用的默认端口号
一.OpenStack组件使用的默认端口号 openstack openstack service default ports port type keystone Identity service ...
- PAT Advanced 1009 Product of Polynomials (25 分)(vector删除元素用的是erase)
This time, you are supposed to find A×B where A and B are two polynomials. Input Specification: Each ...
- 洛谷P1879 [USACO06NOV]玉米田Corn Fields (状态压缩DP)
题目描述 Farmer John has purchased a lush new rectangular pasture composed of M by N (1 ≤ M ≤ 12; 1 ≤ N ...
- AtCoder Regular Contest 092 2D Plane 2N Points AtCoder - 3942 (匈牙利算法)
Problem Statement On a two-dimensional plane, there are N red points and N blue points. The coordina ...