高性能mysql 第6章 查询性能优化
查询缓存:
在解析一个sql之前,如果查询缓存是打开的,mysql会去检查这个查询(根据sql的hash作为key)是否存在缓存中,如果命中的话,那么这个sql将会在解析,生成执行计划之前返回结果。
ps:在5.1版本之前,使用=?参数这种不能使用查询缓存。
查询优化器:
oracle使用基于cost的优化器。
可以使用last_query_cost来获取当前回话的上一个查询的cost:
- /*使用SQL_NO_CACHE禁用查询缓存*/
- show status like 'last_query_cost';
返回的结果10.499表示mysql查询优化器认为大概需要10个数据页的随机查找才能完成这个查询。这个结果是根据一系列的数据得出的,如每个表或者索引的页面个数,索引的基数,索引和数据行的长度,索引分布情况。
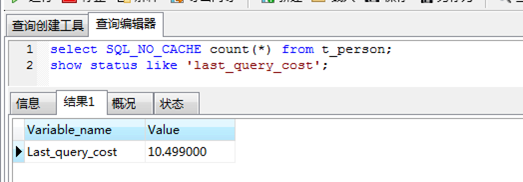
由于统计信息的不准确,或者mysql本身的实现机制,有些情况下,计算的成本并不准确。
mysql能够处理的优化有:
- 重新定义关联表的顺序
- 将外连接转换为内连接
- 使用等价变换规则 如(5=5 and a> 5)被改写成(a>5)
- 优化count(),min(),max(),如对有索引的列取min只需要取b-tree中找第一个节点就可以了。
- 预估并转化为常数表达式。不会改变的函数如上面提到的min函数会被转化为常数。
- 覆盖索引扫描
- 子查询优化
- 提前终只查询
- 等值传播
mysql对where条件的处理:
一般Mysql可以使用如下三种方式应用where条件,从好到坏依次为:
a. 在 索引 中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的。如果没有出现using where,那么代表所有的条件都走了索引。如果出现了Using index condition那么代表出现了索引条件下推。
b. 使用索引覆盖扫描(在Extra列中出现Using index)来返回记录,直接从索引中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层完成的,但无需再回表查询记录。
c. 从数据表中返回数据,然后过滤掉不满足条件的记录(在Extra列中出现Using Where)。这在MySQL服务器层完成,MySQL需要先从数据表读取记录然后过滤。
如果有如下表:
- CREATE TABLE `t_person` (
- `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
- `name` varchar(40) DEFAULT NULL,
- `age` mediumint(9) DEFAULT NULL,
- `address` varchar(100) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `idx_t_person_name_age` (`age`,`name`)
- )
对它执行查询:
注意using where只是标识,是否在服务层进行了过滤,并不代表没有走索引。因为存在走了索引条件之后,拿到数据到服务层进行其他条件的过滤的情况。虽然有了索引条件下推之后,一些低效的using where被避免了。




下面这个结果有点不能理解,我理解应该返回:Using index ,Using index condition才合适:

重构查询的方式1:切分查询
在大量更新的时候,切分查询:切分查询的一个重要使用是在对大量数据进行delete的时候,按照条件切分成多个sql,切分之后可以减少每次持有的锁。
如果一个查询涉及多张表关联,可以分解关联查询。
分解关联查询的方式重构查询有如下的优势:
a. 让缓存的效率更高。许多应用程序可以方便地使用缓存单表查询对应的结果集。
b. 将查询分解后,执行单个查询可以减少锁的竞争。(这个对非串行化事务隔离级别的innodb无效,因为它的查询没有锁。)
c. 在应用层做关联,可以更容易对数据库进行拆分,更容易做到高性能和可扩展性。
d. 查询本身效率也可能会有所提升。
e. 可以减少冗余记录的查询。管理查询中可能需要重复地访问一部分数据。
f. 更进一步,这样做相当于在应用中实现了哈希关联,而不是使用MySQL的嵌套循环关联。某些场景哈希关联的效率要高很多。(Hash关联适用于两张大表的关联,应该不适合在应用服务器的层面做这个)
但是分解关联查询这种方式我不太认可。要看具体的使用场景。比如查询很大,涉及复杂的子查询。我觉得可以切分。如果切分后需要在java应用层做大量的类似于join操作,也要考虑应用层的负载。
关联优化器:
mysql暂时只支持嵌套循环查询。也是就nest loops。
本质上说mysql对所有类型的查询都以同样的方式(嵌套循环连接)运行。包括子查询和union。
因为mysql只支持嵌套循环连接,所以它不支持全外连接。
所以,对mysql来说,选择最小表最为基表示非常重要的,mysql基于cost的优化器会选择最小表,也可以通过STRAIGHT_JOIN关键字指定mysql按照sql语句中的顺序来做join。
关联优化器会尝试所有的关联顺序,来计算成本。如果对于一个有n个表的join,那么需要检查n的阶乘中关联顺序。如果有10张表,那么共有3628800中不同的关联顺序!如果表太多,mysql会选择"贪婪"方式。
排序优化
排序是一项成本非常高的操作,所以从性能的角度上,尽量避免对大量数据进行排序。
数据量小的排序在内存中进行的,数据量大要使用磁盘,不过mysql将这个过程统一称为文件(filesort)。
在关联查询的时候,如果需要排序,有两种情况:
- 如果order by字句中的所有列都来自第一章表,那么mysql会在处理第一章表的时候就进行排序,如果是这样,mysql的执行计划的extra列会有using filesort的标识。
- 如果不是都来自己第一张表,那么mysql会将每一步join的结果放入临时表,在所有join执行完之后,在这个临时表进行排序,如果是这样,mysql的执行计划的extra列会有using temporary;using filesort的标识。
关联子查询的局限性
书上提到mysql关联子查询局限性。
比如in操作,mysql5.5版本会将外部查询作为基表,使用nl关联去loop遍历内部查询。这样其实非常不合理,因为一般in的内部的数据是比较少的,外部的数据是比较多的。这样loop性能肯定很慢。
可是我在实验的时候发现5.6的版本优化了这个问题。
5.6版本会将in内部的查询执行为一张临时表,然后在跟外表关联的时候,选择数据量小的表作为基表。我的测试如下:
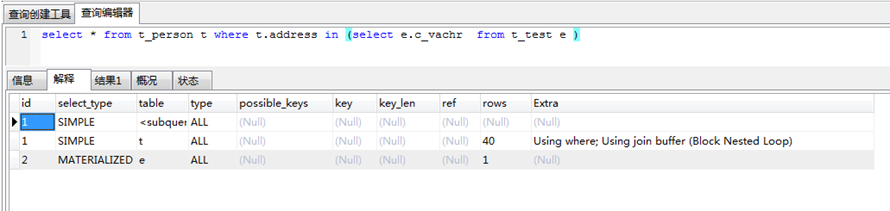
因为在5.5版本中的关联子查询性能很低,所以一般用inner join来改写in和exist,用left join来改写not in,not exist。
不过在5.6版本中,我建议先用子查询,如果有性能问题在优化不迟。
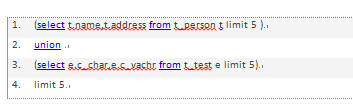
union的局限性:
mysql无法将limit条件从外层下推到内层。
如:

可以优化为:
并行执行:
mysql无法利用多核特性来并行执行查询。
hash关联:
mysql不支持hash关联。
跳跃索引扫描(skip index scan)
不支持。经过测试,在5.6版本支持了。
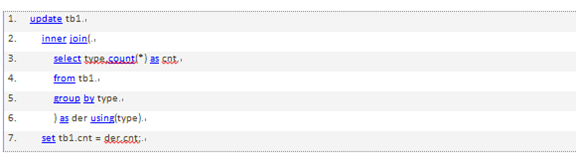
在同一张表上进行更新的限制:
MySQL不允许对同一张表同时进行查询和更新。这其实并不是优化器的限制,下面的SQL无法运行,这个SQL尝试将两个表中相似行的数量记录到字段cnt中:

可以通过生成表的形式绕过上面的限制,因为mysql只会把这个表当作一个临时表来处理。实际上,这执行了两个查询:一个是子查询中的select语句,另一个是多表关联update,只是关联的表是一个临时表。子查询会在update语句打开表之前就完成,所以下面的查询会正常执行:
hint提示:
DELAYED:针对insert和replace。执行后立即返回,然后在空闲的时候,数据才会写入到硬盘。比较适合记录日志。
STRAIGHT_JOIN:定义关联顺序。
SQL_SMALL_RESULT,SQL_BIG_RESULT:用于查询,标志结果集的大小,引导排序操作在内存或者硬盘中执行。
SQL_BUFFER_RESULT:将查询结果放入一个临时表,尽快的释放表锁。
SQL_CACHE,SQL_NO_CACHE:是否缓存。
USE INDEX,IGNORE INDEX,FORCE INDEX:强制使用索引,和不适用索引。
优化关联查询:
- 尽量确保on的列上有索引。
- 确保group by和order by只涉及一张表的列。这样才可以用到索引。ps(order by好理解,group by自己思考也会明白,如果group by上没有索引,肯定要全表并排序,或者使用临时表才能做group by)
- mysql内部有可能会自动转换等价的distinct和 group by语法。
用户自定义变量:
这一章节是mysql的独有的功能,不是sql标准,可以在查询里使用自定义变量,来实现行号、统计等功能。这里我没有细看,罗列了两篇文章可以参考:
http://www.cnblogs.com/guaidaodark/p/6037040.html
http://blog.csdn.net/muzizhuben/article/details/49449853
高性能mysql 第6章 查询性能优化的更多相关文章
- 高性能mysql 第六章查询性能优化 总结(上)查询的执行过程
6 查询性能优化 6.1为什么查询会变慢 这里说明了的查询执行周期,从客户端到服务器端,服务器端解析,优化器生成执行计划,执行(可以细分,大体过程可以通过show profile查看),从服务器端返 ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- MySQL性能调优与架构设计——第9章 MySQL数据库Schema设计的性能优化
第9章 MySQL数据库Schema设计的性能优化 前言: 很多人都认为性能是在通过编写代码(程序代码或者是数据库代码)的过程中优化出来的,其实这是一个非常大的误区.真正影响性能最大的部分是在设计中就 ...
- mysql笔记03 查询性能优化
查询性能优化 1. 为什么查询速度会慢? 1). 如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间.如果要优化查询,实际上要优化其子任务,要么消除其中一些子任务,要么减 ...
- MySQL查询性能优化(精)
MySQL查询性能优化 MySQL查询性能的优化涉及多个方面,其中包括库表结构.建立合理的索引.设计合理的查询.库表结构包括如何设计表之间的关联.表字段的数据类型等.这需要依据具体的场景进行设计.如下 ...
- 170727、MySQL查询性能优化
MySQL查询性能优化 MySQL查询性能的优化涉及多个方面,其中包括库表结构.建立合理的索引.设计合理的查询.库表结构包括如何设计表之间的关联.表字段的数据类型等.这需要依据具体的场景进行设计.如下 ...
- 到底该不该使用存储过程 MySQL查询性能优化一则
到底该不该使用存储过程 看到<阿里巴巴java编码规范>有这样一条 关于这条规范,我说说我个人的看法 用不用存储过程要视所使用的数据库和业务场景而定的,不能因为阿里巴巴的技术牛逼,就视 ...
- MySQL查询性能优化七种武器之索引下推
前面已经讲了MySQL的其他查询性能优化方式,没看过可以去了解一下: MySQL查询性能优化七种武器之索引潜水 MySQL查询性能优化七种武器之链路追踪 今天要讲的是MySQL的另一种查询性能优化方式 ...
- mysql索引原理及查询速度优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
随机推荐
- style属性
style加样式是加在行间,取样式也是在行间取: 我们来看下面这段代码: <!DOCTYPE HTML> <html> <head> <meta charse ...
- 3D玫瑰花
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/ ...
- 【C/C++】什么是线程安全
<strong>线程安全</strong>就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用.不 ...
- [转帖]ORA-00600-[kcratr_nab_less_than_odr]问题小记
ORA-00600-[kcratr_nab_less_than_odr]问题小记 2018年03月12日 20:56:57 我不是VIP 阅读数 1500 https://blog.csdn.ne ...
- 友善的树形DP
一棵树,如果有序点对(x,y)之间路径的长度取模于3==0,那么ans0便加上这个长度: 如果取模于3==1,那么ans1便加上这个长度: 如果取模于3==2,那么ans2便加上这个长度: 让你求an ...
- C++练习 | 类的继承与派生练习(1)
#include <iostream> #include <cmath> #include <cstring> #include <string> #i ...
- python_0基础开始_day10
第十节 一.函数进阶 动态参数 *a r g s —— 聚合位置参数,动态位置参数 默认返回的是tuple元组 def eat(*args): # 函数的定义阶段 *聚合(打包) print( ...
- git bash中不能显示中文
git bash中不能显示中文 问题描述:当使用git log查看提交日志时,中文字符不能正常显示问题 1.首先把git的配置改一下 git config --global core.quotepat ...
- 设置Cookies
设置Cookies: public ActionResult Index() { // if (Request.Cookies["user"] != null) { //Serve ...
- js 禁用F12 和右键查看源码
<script> window.onkeydown = function(e) { if (e.keyCode === 123) { e.preventDefault() } } wind ...