哈希表(hash)详解
哈希表结构讲解:
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
记录的存储位置 = function(关键字)
这里的对应关系function称为散列函数,又称为哈希(Hash函数),采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hash table)。
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数function既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。(或者:把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。) 而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标【仍通过映射哈希函数function】,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
Hash的应用:
1、Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。
2、查找:
哈希表,又称为散列,是一种更加快捷的查找技术。我们之前的查找,都是这样一种思路:集合中拿出来一个元素,看看是否与我们要找的相等,如果不等,缩小范围,继续查找。而哈希表是完全另外一种思路:当我知道key值以后,我就可以直接计算出这个元素在集合中的位置,根本不需要一次又一次的查找!
举一个例子,假如我的数组A中,第i个元素里面装的key就是i,那么数字3肯定是在第3个位置,数字10肯定是在第10个位置。哈希表就是利用利用这种基本的思想,建立一个从key到位置的函数,然后进行直接计算查找。
3、Hash表在海量数据处理中有着广泛应用。
Hash的特点:
Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
散列法:元素特征转变为数组下标的方法。
我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”。我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。
散列表的查找步骤 :
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
关键字——散列函数(哈希函数)——散列地址
优点:一对一的查找效率很高;
缺点:一个关键字可能对应多个散列地址;需要查找一个范围时,效果不好。
散列冲突:不同的关键字经过散列函数的计算得到了相同的散列地址。
好的散列函数=计算简单+分布均匀(计算得到的散列地址分布均匀)
哈希表是种数据结构,它可以提供快速的插入操作和查找操作。
Hash优缺点:
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即O(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
常见的散列法:
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
1、除法【求余】散列法
最直观的一种,公式:
index = value % 16
学过汇编的都知道,求模数其实是通过一个除法运算得到的,所以叫“除法散列法”。
一般哈希表的大小为素数,因为素数不存在因子,所以大大减少了位置冲突的概率
2、MAD法
除余法存在的不足
除余法虽能一定程度保证词条均匀分布,但从关键码空间到散列地址空间依然残留有一定的连续性,如 相邻关键码对应散列地址也相邻。
因此便有mad法,若常数ab选取得当,可以很好地克服除余法的这种连续性。除余法也可以看作Mad法a=1和b=0的特例,只是两个常数并未发挥实质作用。

表达式
hash(key) = (a*key+b) % M, 其中M仍为素数,a>0,b>0,且a % M != 0
3、数字分析法(selecting digits)
注:以下各方法为保证落在合法的散列地址空间上,最后通常还需对表长M取余。
思路
从关键码key特定进制的展开中抽取特定的若干位,构成整型地址。
表达式
例:选取key十进制展开中的奇数位
hash(123456789) = 13579
4、平方取中法(mid-square)
思路
从关键码key的平方的十进制或二进制展开中取居中的若干位,构成一个整型地址。
表达式
例:取平方并用十进制展开中的居中3位作为散列地址
123^2 = 15129,hash(123) = 512
5、折叠法(folding)
思路
将关键码的十进制或二进制展开分割成等宽的若干段,取其总和作为散列地址。
表达式
例:以十进制三个数位为分割单位
hash(123456789) = 123+456+789 = 1368
6、异或法(xor)
思路
将关键码的二进制展开分割成等宽的若干段,经异或运算得到散列地址。
表达式
例:以二进制三个数位为分割单位
hash(411) = hash(110011011b) = 110^011^011 = 110b = 6
7、平方散列法
求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。公式:
index = (value * value) >> 28
(右移,除以2^28。记法:左移变大,是乘。右移变小,是除。)
如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
8、斐波那契(Fibonacci)散列法
平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
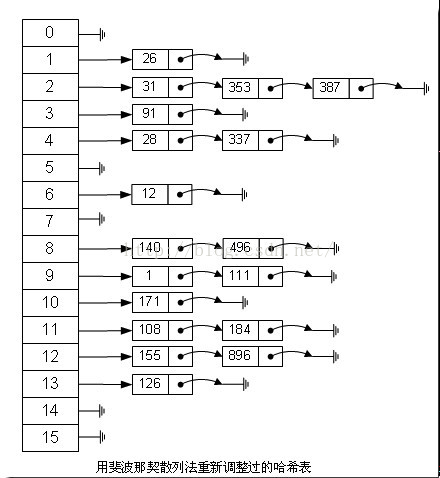
1,对于16位整数而言,这个乘数是40503
2,对于32位整数而言,这个乘数是2654435769
3,对于64位整数而言,这个乘数是11400714819323198485
这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377, 610, 987, 1597, 2584, 4181, 6765, 10946,…。另外,斐波那契数列的值和太阳系八大行星的轨道半径的比例出奇吻合。
对我们常见的32位整数而言,公式:
index = (value * 2654435769) >> 28
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
注:用斐波那契散列法调整之后会比原来的取摸散列法好很多。
适用范围
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
基本原理及要点
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。
碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
散列冲突的解决方案:
1.建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
2.进行再探测。就是在其他地方查找。探测的方法也可以有很多种。
(1)在找到查找位置的index的index-1,index+1位置查找,index-2,index+2查找,依次类推。这种方法称为线性再探测。
(2)在查找位置index周围随机的查找。称为随机在探测。
(3)再哈希。就是当冲突时,采用另外一种映射方式来查找。
这个程序中是通过取模来模拟查找到重复元素的过程。对待重复元素的方法就是再哈希:对当前key的位置+7。最后,可以通过全局变量来判断需要查找多少次。我这里通过依次查找26个英文字母的小写计算的出了总的查找次数。显然,当总的查找次数/查找的总元素数越接近1时,哈希表更接近于一一映射的函数,查找的效率更高。
哈希冲突解决办法:
冲突必然的
因为用短位(散列地址空间)表示长位数据(关键码空间),肯定会出现冲突。比如 常见的 MD5 码,一共就128bit,但却要表示无限的数据的散列码,因此必然会出现不同数据具有相同MD5码的情况。
如果遇到冲突,哈希表一般是怎么解决的呢?具体方法有很多,百度也会有一堆,最常用的就是开发定址法和链地址法。
冲突排解策略分为以下两种类型:
- 开放定址(open addressing) / 闭散列(closed hashing):散列地址空间对所有词条开放(即 桶单元允许装hash(key)不对应的词条);词条存储地址(散列地址)仅限于散列表所覆盖的范围之内。
如:线性试探、查找链法等。
注:因闭散列不得使用附加空间的原因,装填因子通常<=0.5
- 封闭定址(closed addressing) / 开散列(open hashing):散列地址空间只对对应的词条开放;词条存储地址不局限于散列表范围之内。
如:多槽位法、独立链法、公共溢出区等
1、多槽位法(multiple slots)
思路

每个桶本身再细分为若干槽位,用于存放彼此冲突的词条。每个桶槽位的词典结构为向量,因此整体物理存储结构类似于二维数组。
如:put操作,首先通过hash(key)定位到对应的桶单元,并在该桶内部槽位中进一步查找key,若没找到,则创建新词条插入到该桶的空闲槽位中。
缺点
·绝大多数的槽位都处于空闲状态,造成空间浪费。若桶被细分为k个槽位,则装填因子将直接降低为原来的1/k.
·很难实现确定应该细分为多少个槽位,才能保证够用。
2、 独立链法(separate chaining) / 拉链法
思路

与多槽位思想类似,但每个桶的子词典是使用链表实现,令彼此冲突的词条互相串接。
优点:
能灵活动态地调整子词典的规模,有效地使用空间。
缺点
空间未必连续分布,会导致系统缓存失效。

3、公共溢出区
原理

在原散列表之外另设一个词典结构$D_{overflow}$,插入词条一旦发生冲突,则转存到该词典中。$D_{overflow}$相当于存放冲突词条的公共缓冲池。
4.线性探查法 【Linear Probing】
当得到key的hash值H(key),但是表中下标为H(key)的位置已经被某个其他元素使用了,那么就检查下一个位置H(key) + 1 是否被占,如果没有,就使用这个位置;否则就继续检查下一个位置(也就是将hash值H(key)不断加1)。如果检查过程中超过了表长,那么就回到表的首位继续循环,直到找到一个可以使用的位置,或者是发现表中所有位置都已被使用。显然,这个做法容易导致扎堆,即表中连续若干个位置都被使用,这在一定程度上会降低效率。
5.采用平方探查法【Quadratic Probing】
通过将给定元素值对表长的余数作为在哈希表中的插入位置,如果出现冲突,采用平方探查法解决。平方探查法的具体过程是,假设给定元素值为a,表长为M,插入位置为a%M,假设a%M位置已有元素,即发生冲突,则查找
(a+1^2)%M,(a-1^2)%M, (a+2^2)%M,(a-2^2)%M,⋯⋯, (a+k^2)%M,(a-k^2)%M直至查找到一个可进行插入的位置,否则当查找到(a+k^2)%M,(a-k^2)%M仍然不能插入则该元素插入失败。其中 k<=M/2 【有的是k<M】
扩展
具体查找逻辑
查找链(probing chain):对于待查找的key,从hash(key)桶单元开始,直接空桶结束的顺序序列。
- 经hash(key)算得的当前桶单元,若关键码相等,则成功返回。
- 当前桶单元非空,但关键码不等,则转入下一桶单元继续试探。
- 当前桶为空,则返回查找失败。
注:相互冲突的关键码比属于同一查找链(即中途不包含空桶),但同一查找链的关键码未必相互冲突。多组各自冲突的关键码所对应的查找链,有可能相互交织和重叠。
优点
具体由良好的数据局部性,试探地桶单元在物理空间上依次连贯,系统缓存能发挥作用。
懒惰删除:
定义:
从词典删除词条时,暂时并不实际将桶置空,而是额外维护一个删除标记Bitmap,标记该桶已删除。
为什么需要懒惰删除?
因为查找链中任何一环的缺失,都会导致后续词条的“丢失”,即无法找到已存在词条;同时因为开销问题,不可能每次删除操作都对查找链进行维护重建(在扩容时,才重建链)。
因此懒惰删除机制既能保证查找链的完整,也不需要太多开销。
加入懒惰删除后,操作逻辑的变化:
- 在删除等操作查询指定词条时,判断失败的条件变为:为空且不带懒惰删除标记。
- 在插入操作时,找空桶过程中,判断桶为空条件为:带有懒惰标记或当前桶为空。
d-left hashing:
其中的d是多个的意思,我们先简化这个问题,看一看2-left hashing。2-left hashing指的是将一个哈希表分成长度相等的两半,分别叫做T1和T2,给T1和T2分别配备一个哈希函数,h1和h2。在存储一个新的key时,同 时用两个哈希函数进行计算,得出两个地址h1[key]和h2[key]。这时需要检查T1中的h1[key]位置和T2中的h2[key]位置,哪一个 位置已经存储的(有碰撞的)key比较多,然后将新key存储在负载少的位置。如果两边一样多,比如两个位置都为空或者都存储了一个key,就把新key 存储在左边的T1子表中,2-left也由此而来。在查找一个key时,必须进行两次hash,同时查找两个位置。
问题实例(海量数据处理)
我们知道hash 表在海量数据处理中有着广泛的应用,下面,请看另一道百度面试题:
题目:海量日志数据,提取出某日访问百度次数最多的那个IP。
方案:IP的数目还是有限的,最多2^32个,所以可以考虑使用hash将ip直接存入内存,然后进行统计。
hash_map的使用:
hash函数系统自带的类型函数:
struct hash<char*>
struct hash<const char*>
struct hash<char>
struct hash<unsigned char>
struct hash<signed char>
struct hash<short>
struct hash<unsigned short>
struct hash<int>
struct hash<unsigned int>
struct hash<long>
struct hash<unsigned long> 普通的hash使用: hash_map<string, int>map1; 自定义hash函数的使用: hash_map<int, string, hash<int>, equal_to<int> > mymap; hash函数的自定义与默认函数: struct str_hash { //自写hash函数 size_t operator()(const string& str) const { unsigned long __h = ; for (size_t i = ; i < str.size() ; i ++) { __h = *__h + str[i]; } return size_t(__h); } }; / struct str_hash // { //自带的string hash函数 // size_t operator()(const string& str) const // { // return __stl_hash_string(str.c_str()); // } // }; // struct hash<int> // { //自带的int hash函数 // size_t operator()(int __x) const { return __x; } // }; struct str_equal //即压入数据时,去重的比较函数 { //string 判断相等函数 bool operator()(const string& s1,const string& s2) const { return s1==s2; } }; 注意hash函数只指的是第一个元素类型 hash_map<string,int,str_hash,str_equal> map2; }
hash_map的案例——布隆过滤器
不安全网页的黑名单包含100亿个黑名单网页,每个网页的URL最多占用64B。现在想要实现一种网页过滤系统,可以根据网页的URL判断该网页是否在黑名单上,请设计该系统。
要求如下:
该系统允许有万分之一以下的判断失误率。
使用的额外空间不要超过30GB。
如果将这100亿个URL通过数据库或哈希表保存起来,就可以对每条URL进行查询,但是每个URL有64B,数量是100亿个,所以至少需要640GB的空间,不满足要求2。
如果面试者遇到网页黑名单系统、垃圾邮件过滤系统,爬虫的网页判重系统等题目,又看到系统容忍一定程度的失误率,但是对空间要求比较严格,那么很可能是面试官希望面试者具备布隆过滤器的知识。一个布隆过滤器精确地代表一个集合,并可以精确判断一个元素是否在集合中。注意,只是精确代表和精确判断,到底有多精确呢?则完全在于你具体的设计,但想做到完全正确是不可能的。布隆过滤器的优势就在于使用很少的空间就可以将准确率做到很高的程度。该结构由Burton Howard Bloom于1970年提出。
那么什么是布隆过滤器呢?
假设有一个长度为m的bit类型的数组,即数组的每个位置只占一个bit,如果我们所知,每一个bit只有0和1两种状态,如图所示:
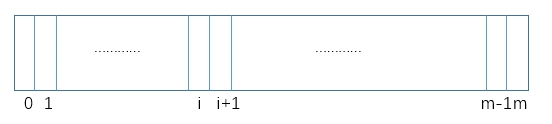
再假设一共有k个哈希函数,这些函数的输出域S都大于或等于m,并且这些哈希函数都足够优秀且彼此之间相互独立(将一个哈希函数的计算结果乘以6除以7得出的新哈希函数和原函数就是相互独立的)。那么对同一个输入对象(假设是一个字符串,记为URL),经过k个哈希函数算出来的结果也是独立的。可能相同,也可能不同,但彼此独立。对算出来的每一个结果都对m取余(%m),然后在bit array 上把相应位置设置为1(我们形象的称为涂黑)。如图所示

我们把bit类型的数组记为bitMap。至此,一个输入对象对bitMap的影响过程就结束了,也就是bitMap的一些位置会被涂黑。接下来按照该方法,处理所有的输入对象(黑名单中的100亿个URL)。每个对象都可能把bitMap中的一些白位置涂黑,也可能遇到已经涂黑的位置,遇到已经涂黑的位置让其继续为黑即可。处理完所有的输入对象后,可能bitMap中已经有相当多的位置被涂黑。至此,一个布隆过滤器生成完毕,这个布隆过滤器代表之前所有输入对象组成的集合。
那么在检查阶段时,如何检查一个对象是否是之前的某一个输入对象呢(判断一个URL是否是黑名单中的URL)?假设一个对象为a,想检查它是否是之前的输入对象,就把a通过k个哈希函数算出k个值,然后把k个值都取余(%m),就得到在[0,m-1]范围伤的k个值。接下来在bitMap上看这些位置是不是都为黑。如果有一个不为黑,说明a一定不再这个集合里。如果都为黑,说明a在这个集合里,但可能误判。
再解释具体一点,如果a的确是输入对象 ,那么在生成布隆过滤器时,bitMap中相应的k个位置一定已经涂黑了,所以在检查阶段,a一定不会被漏过,这个不会产生误判。会产生误判的是,a明明不是输入对象,但如果在生成布隆过滤器的阶段因为输入对象过多,而bitMap过小,则会导致bitMap绝大多数的位置都已经变黑。那么在检查a时,可能a对应的k个位置都是黑的,从而错误地认为a是输入对象(即是黑名单中的URL)。通俗地说,布隆过滤器的失误类型是“宁可错杀三千,绝不放过一个”。
布隆过滤器到底该怎么生成呢?只需记住下列三个公式即可:
对于输入的数据量n(这里是100亿)和失误率p(这里是万分之一),布隆过滤器的大小m:m = - (n*lnp)/(ln2*ln2),计算结果向上取整(这道题m=19.19n,向上取整为20n,即需要2000亿个bit,也就是25GB)
需要的哈希函数的个数k:k = ln2 * m/n = 0.7 * m/n(这道题k = 0.7 * 20n/n = 14)
由于前两步都进行了向上取整,那么由前两步确定的布隆过滤器的真正失误率p:p = (1 - e^(-nk/m))^k
一致性哈希算法的基本原理
题目
工程师常使用服务器集群来设计和实现数据缓存,以下是常见的策略:
无论是添加、查询还是珊瑚数据,都先将数据的id通过哈希函数换成一个哈希值,记为key
如果目前机器有N台,则计算key%N的值,这个值就是该数据所属的机器编号,无论是添加、删除还是查询操作,都只在这台机器上进行。
请分析这种缓存策略可能带来的问题,并提出改进的方案。
解析
题目中描述的缓存从策略的潜在问题是,如果增加或删除机器时(N变化)代价会很高,所有的数据都不得不根据id重新计算一遍哈希值,并将哈希值对新的机器数进行取模啊哦做。然后进行大规模的数据迁移。
为了解决这些问题,下面介绍一下一致性哈希算法,这时一种很好的数据缓存设计方案。我们假设数据的id通过哈希函数转换成的哈希值范围是2^32,也就是0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形,那么一个数据id在计算出哈希值之后认为对应到环中的一个位置上,如图所示

接下来想象有三台机器也处在这样一个环中,这三台机器在环中的位置根据机器id(主机名或者主机IP,是主机唯一的就行)设计算出的哈希值对2^32取模对应到环上。那么一条数据如何确定归属哪台机器呢?我们可以在该数据对应环上的位置顺时针寻找离该位置最近的机器,将数据归属于该机器上:
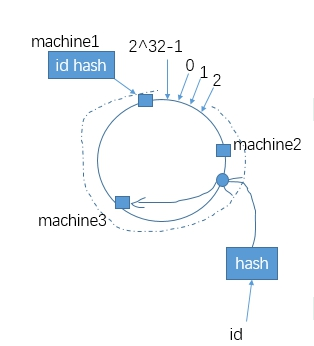
这样的话,如果删除machine2节点,则只需将machine2上的数据迁移到machine3上即可,而不必大动干戈迁移所有数据。当添加节点的时候,也只需将新增节点到逆时针方向新增节点前一个节点这之间的数据迁移给新增节点即可。
但这时还是存在如下两个问题:
机器较少时,通过机器id哈希将机器对应到环上之后,几个机器可能没有均分环

那么这样会导致负载不均。
增加机器时,可能会打破现有的平衡:
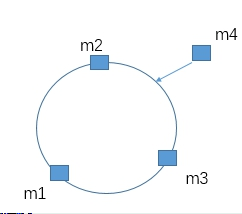
为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一台机器通过不同的哈希函数计算出多个哈希值,对多个位置都放置一个服务节点,称为虚拟节点。具体做法:比如对于machine1的IP192.168.25.132(或机器名),计算出192.168.25.132-1、192.168.25.132-2、192.168.25.132-3、192.168.25.132-4的哈希值,然后对应到环上,其他的机器也是如此,这样的话节点数就变多了,根据哈希函数的性质,平衡性自然会变好:
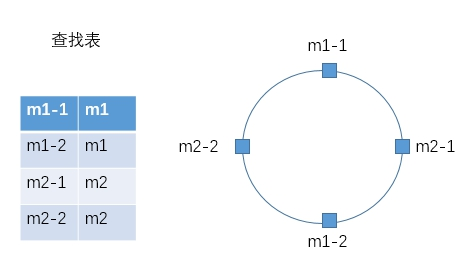
此时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,比如上图的查找表。当某一条数据计算出归属于m2-1时再根据查找表的跳转,数据将最终归属于实际的m1节点。
基于一致性哈希的原理有很多种具体的实现,包括Chord算法、KAD算法等,有兴趣的话可以进一步学习。
RandomPool
设计一种结构,在该结构中有如下三个功能:
inserrt(key):将某个key加入到该结构中,做到不重复加入。
delete(key):将原本在结构中的某个key移除。
getRandom():等概率随机返回结构中的任何一个key。
要求:insert、delete和getRandom方法的时间复杂度都是O(1)
思路:使用两个哈希表和一个变量size,一个表存放某key的标号,另一个表根据根据标号取某个key。size用来记录结构中的数据量。加入key时,将size作为该key的标号加入到两表中;删除key时,将标号最大的key替换它并将size--;随机取key时,将size范围内的随机数作为标号取key。
template<class T>
class RandomPool
{
public:
void insert(T key);
void del(T key);
T getRandom();
void getPrint(T key);
void getPrint(int index);
private:
hash_map<T, int>KeyMap;
hash_map<int, T>IndexMap;
int size = ;
};
template<class T>
void RandomPool<T>::insert(T key)
{
if (KeyMap.find(key) == KeyMap.end())
{
KeyMap[key] = this->size;
IndexMap[this->size] = key;
++(this->size);
cout << "add succeed!" << endl;
}
else
cout << "add filed!" << endl;
}
template<class T>
void RandomPool<T>::del(T key)
{
auto ptr = KeyMap.find(key);
if (ptr == KeyMap.end())
{
cout << "delete filed! there is not exsite the key!" << endl;
return;
}
//交换查找到元素与最后一个元素
T temp = IndexMap[--(this->size)];//最后一个元素的关键词,同时将hash表中的元素删除了
int index = KeyMap[key];//要删除元素的位置
KeyMap[temp] = index;
IndexMap[index] = temp;//将最后一个元素替换要删除元素的位置
//正式删除
KeyMap.erase(ptr);
IndexMap.erase(IndexMap.find(index));
}
template<class T>
T RandomPool<T>::getRandom()
{
if (this->size == )
{
cout << "the map is empty!" << endl;
}
else
{
int index = (int)((rand() % ( + ) / (double)( + ))*(this->size));//随机生成一个位置
return IndexMap[index];
}
}
template<class T>
void RandomPool<T>::getPrint(T key)
{
if (KeyMap.find(key) == KeyMap.end())
cout << "the key is not exsite!" << endl;
else
cout << KeyMap[key] << endl;
}
template<class T>
void RandomPool<T>::getPrint(int index)
{
if (IndexMap.find(index) == IndexMap.end())
cout << "the key is not exsite!" << endl;
else
cout << IndexMap[index] << endl;
}
<code class="lang-java">import java.util.HashMap;
public class RandomPool {
public int size;
public HashMap<Object, Integer> keySignMap;
public HashMap<Integer, Object> signKeyMap;
public RandomPool() {
this.size = ;
this.keySignMap = new HashMap<>();
this.signKeyMap = new HashMap<>();
}
public void insert(Object key) {
//不重复添加
if (keySignMap.containsKey(key)) {
return;
}
keySignMap.put(key, size);
signKeyMap.put(size, key);
size++;
}
public void delete(Object key) {
if (keySignMap.containsKey(key)) {
Object lastKey = signKeyMap.get(--size);
int deleteSign = keySignMap.get(key);
keySignMap.put(lastKey, deleteSign);
signKeyMap.put(deleteSign, lastKey);
keySignMap.remove(key);
signKeyMap.remove(lastKey);
}
}
public Object getRandom() {
if (size > ) {
return signKeyMap.get((int) (Math.random() * size));
}
return null;
}
}
认识一致性哈希
使用二分法,找到hash值大于等于该值的hash值的服务器即为管理该值的服务器
一致性哈希的应用:
当我们要添加或减少服务器时,一般操作是将已存的值重新计算hash值,然后取mod,来决定管理该数据的服务器,代价太高,时间太长
于是使用一个环来减少操作:
将hash范围组成一个环,如图所示,然后将服务器按其hash值按顺序数组中,
然后每输入一个数据,根据其hash值,使用二分法将其放入刚刚>=该数hash值的服务器。
当添加服务器时,【假如添加一个服务器mx在m1-m2之间】只需要将原m1-m2中一部分小于mx的数据改为有mx来管理。
如何确保服务器负载均衡【因为服务器的hash值不均匀】?
使用一致hash
将每个服务器产生N个虚拟服务器,如1000个,则有3个服务器就有3000个虚拟服务器,然后让3000个虚拟去负载整个hash范围,那么这三个服务器的虚拟服务器所管理的数据就几乎均分分布在整个hash域中
那么就认为这3个服务器的负载均衡。
添加与删除原理也是如此。
哈希表(hash)详解的更多相关文章
- Hash之哈希表的详解
Hash算法 Hash算法的原理; 决绝冲突的办法是: 线性探查法; 双散列函数法; 拉链法处理碰撞; 哈希原理及实现; 哈希表-Hash table, 也叫散列表;
- oracle表分区详解
原文来自:http://www.cnblogs.com/leiOOlei/archive/2012/06/08/2541306.html oracle表分区详解 从以下几个方面来整理关于分区表的概念及 ...
- Oracle表空间详解
Oracle表空间详解 1.表空间的分类 Oracle数据库把表空间分为两类:系统表空间和非系统表空间. 1.1系统表空间指的是数据库系统创建时需要的表空间,这些表空间在数据库创建时自动创建,是每个数 ...
- SQL Server表分区详解
原文:SQL Server表分区详解 什么是表分区 一般情况下,我们建立数据库表时,表数据都存放在一个文件里. 但是如果是分区表的话,表数据就会按照你指定的规则分放到不同的文件里,把一个大的数据文件拆 ...
- [转帖]Windows注册表内容详解
Windows注册表内容详解 来源:http://blog.sina.com.cn/s/blog_4d41e2690100q33v.html 对 windows注册表一知半解 不是很清晰 这里学习一下 ...
- ORACLE结构体系篇之表空间详解.md
表空间详解一.系统表空间SYSTEM 表空间是Oracle 数据库最重要的一个表空间,存放了一些DDL 语言产生的信息以及PL/SQL 包.视图.函数.过程等,称之为数据字典,因此该表空间也具有其特殊 ...
- (转)Mysql 多表查询详解
MySQL 多表查询详解 一.前言 二.示例 三.注意事项 一.前言 上篇讲到mysql中关键字执行的顺序,只涉及了一张表:实际应用大部分情况下,查询语句都会涉及到多张表格 : 1.1 多表连接有 ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- Windows注册表内容详解
Windows注册表内容详解 http://blog.sina.com.cn/s/blog_4d41e2690100q33v.html (2011-04-05 10:46:17) 第一课 注册表 ...
- Hash表算法详解
Hash表定义 散列表(Hash table,也叫哈希表),是根据关键字值(Key value)直接进行访问的数据结构.也就是说,它通过把关键字(关键字通过Hash算法生成)映射到表中一个位置来访问记 ...
随机推荐
- Linux下实现MySQL数据库每天定时自动备份
使用MySQL自带的备份工具+ crontab 的方式来实现备份 1.查看磁盘挂载信息(选一个容量合适的) #df -h 2.创建备份目录 为了方便,在/home保存备份文件: cd /home/ga ...
- 每天一个linux常用命令--ls 和 -ll 有什么区别?
一.-ls 和 -ll 有什么区别? 1. ls 命令可以说是linux下最常用的命令之一.ll不是命令,是ls -l的别名相当于windows里的快捷方式.所以"ll"和“ls ...
- 时间复杂度为n^2的排序
时间复杂度为n^2的排序 冒泡排序和选择排序的共同点:每次都是在找剩下元素中最小(大)的元素 不同点:冒泡排序存在多次交换,而选择排序每次只存在一次交换序号 #include<iostream& ...
- 我的js
<case value="select"> <div class="form-group item_{$[type]form.name} {$[type ...
- 正则finditer的使用
import re #\. 是刚需必须有 d+ 必须一个或多个数字 pattern = re.compile(r'\d+\.\d*') d = pattern.finditer('3.14159265 ...
- Cocos2d-x之MessageBox
| 版权声明:本文为博主原创文章,未经博主允许不得转载. 在cocos2d-x中使用的对话框为MessageBox,因为cocos2d-x已经包装好了:但是在一般的游戏设置中,我们不会使用coco ...
- Python 学习笔记14 类 - 使用类和实例
当我们熟悉和掌握了怎么样创建类和实例以后,我们编程中的大多数工作都讲关注在类的简历和实例对象使用,修改和维护上. 结合实例我们来进一步的学习类和实例的使用: 我们新建一个汽车的类: #-*- codi ...
- [Leetcode] 176.第二高薪水
题目: 编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) . +----+--------+ | Id | Salary | +----+--------+ | 1 | ...
- CentOS7下Docker与.net Core 2.2
一.使用 yum 安装(CentOS 7下) Docker 要求 CentOS 系统的内核版本高于 3.10 ,查看本页面的前提条件来验证你的CentOS 版本是否支持 Docker . 通过 una ...
- MySQLSyntaxErrorException: Row size too large 转摘自:https://confluence.atlassian.com/display/CONFKB/MySQLSyntaxErrorException%3A+Row+size+too+large
Symptoms The following appears in the atlassian-confluence.log: Caused by: com.mysql.jdbc.exceptions ...