消息队列rabbitmq/kafka
12.1 rabbitMQ
1. 你了解的消息队列
rabbitmq是一个消息代理,它接收和转发消息,可以理解为是生活的邮局。
你可以将邮件放在邮箱里,你可以确定有邮递员会发送邮件给收件人。
概括:
rabbitmq是接收,存储,转发数据的。
官方教程:http://www.rabbitmq.com/tutorials/tutorial-one-python.html
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
2. 公司在什么情况下会用消息队列?
1.电商订单
想必同学们都点过外卖,点击下单后的业务逻辑可能包括:检查库存、生成单据、发红包、短信通知等,如果这些业务同步执行,完成下单率会非常低,如发红包,短信通知等不必要的流程,异步执行即可。
此时使用MQ,可以在核心流程(扣减库存、生成订单记录)等完成后发送消息到MQ,快速结束本次流程。消费者拉取MQ消息时,发现红包、短信等消息时,再进行处理。
场景:双11是购物狂节,用户下单后,订单系统需要通知库存系统,传统的做法就是订单系统调用库存系统的接口
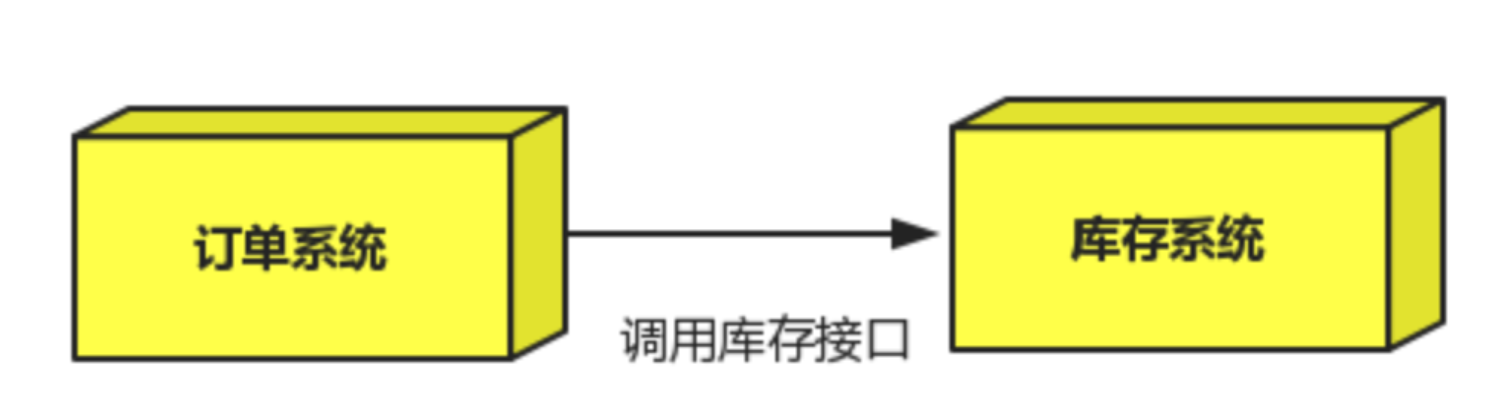
这种做法有一个缺点:
当库存系统出现故障时,订单就会失败。(这样马云将少赚好多好多钱钱。。。。)
订单系统和库存系统高耦合.
引入消息队列
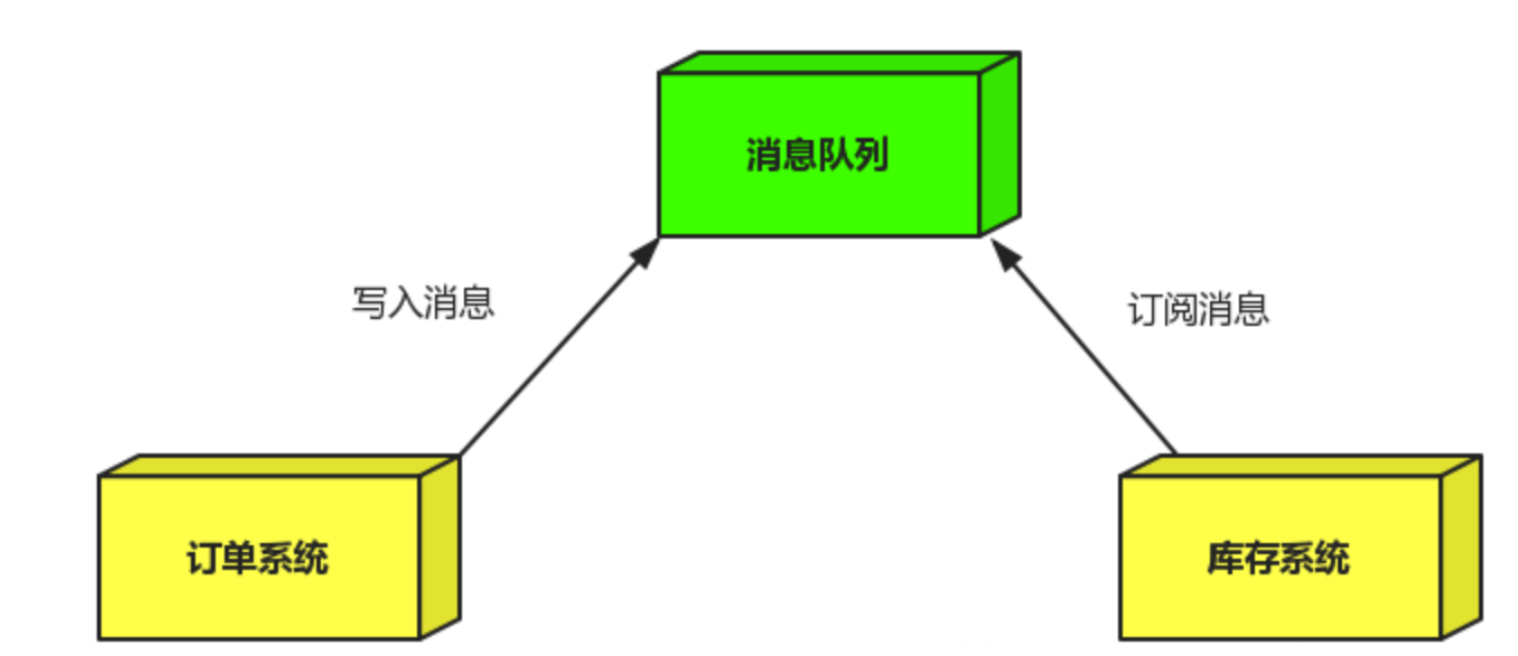
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功。
库存系统:订阅下单的消息,获取下单消息,进行库操作。 就算库存系统出现故障,消息队列也能保证消息的可靠投递,不会导致消息丢失(马云这下高兴了,钞票快快的来呀~~).
2.秒杀活动
流量削峰一般在秒杀活动中应用广泛 场景:秒杀活动,一般会因为流量过大,导致应用挂掉,为了解决这个问题,一般在应用前端加入消息队列。 作用: 1.可以控制活动人数,超过此一定阀值的订单直接丢弃(怪不得我一次秒杀都没抢到过。。。。。wtf???)
2.可以缓解短时间的高流量压垮应用(应用程序按自己的最大处理能力获取订单)
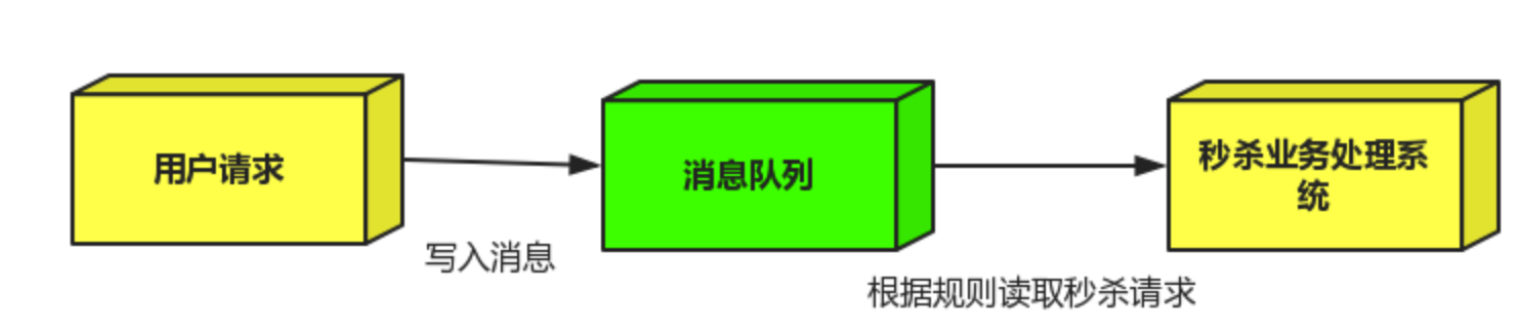
3.用户的请求,服务器接收到之后,写入消息队列,超过定义的阈值就直接丢弃请求,或者跳转错误页面。
4.业务系统取出队列中的消息,再做后续处理。
3. rabbitMQ安装
rabbitmq-server服务端
1.下载centos源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.cloud.tencent.com/repo/centos7_base.repo
2.下载epel源
wget -O /etc/yum.repos.d/epel.repo http://mirrors.cloud.tencent.com/repo/epel-7.repo
3.清空yum缓存并且生成新的yum缓存
yum clean all
yum makecache
4.安装erlang
$ yum -y install erlang
5.安装RabbitMQ
$ yum -y install rabbitmq-server
6.启动(无用户名密码):
systemctl start/stop/restart/status rabbitmq-server
设置rabbitmq账号密码,以及角色权限设置
# 设置新用户yugo 密码123
sudo rabbitmqctl add_user yugo 123
# 设置用户为administrator角色
sudo rabbitmqctl set_user_tags yugo administrator
# 设置权限,允许对所有的队列都有权限
sudo rabbitmqctl set_permissions -p "/" yugo ".*" ".*" ".*"
#重启服务生效设置
service rabbitmq-server start/stop/restart
rabbitmq相关命令
// 新建用户
rabbitmqctl add_user {用户名} {密码}
// 设置权限
rabbitmqctl set_user_tags {用户名} {权限}
// 查看用户列表
rabbitmqctl list_users
// 为用户授权
添加 Virtual Hosts :
rabbitmqctl add_vhost <vhost>
// 删除用户
rabbitmqctl delete_user Username
// 修改用户的密码
rabbitmqctl change_password Username Newpassword
// 删除 Virtual Hosts :
rabbitmqctl delete_vhost <vhost>
// 添加 Users :
rabbitmqctl add_user <username> <password>
rabbitmqctl set_user_tags <username> <tag> ...
rabbitmqctl set_permissions [-p <vhost>] <user> <conf> <write> <read>
// 删除 Users :
delete_user <username>
// 使用户user1具有vhost1这个virtual host中所有资源的配置、写、读权限以便管理其中的资源
rabbitmqctl set_permissions -p vhost1 user1 '.*' '.*' '.*'
// 查看权限
rabbitmqctl list_user_permissions user1
rabbitmqctl list_permissions -p vhost1
// 清除权限
rabbitmqctl clear_permissions [-p VHostPath] User
//清空队列步骤
rabbitmqctl reset
需要提前关闭应用rabbitmqctl stop_app ,
然后再清空队列,启动应用
rabbitmqctl start_app
此时查看队列rabbitmqctl list_queues
查看所有的exchange: rabbitmqctl list_exchanges
查看所有的queue: rabbitmqctl list_queues
查看所有的用户: rabbitmqctl list_users
查看所有的绑定(exchange和queue的绑定信息): rabbitmqctl list_bindings
查看消息确认信息:
rabbitmqctl list_queues name messages_ready messages_unacknowledged
查看RabbitMQ状态,包括版本号等信息:rabbitmqctl status
连接客户端
// rabbitmq官方推荐的python客户端pika模块
pip3 install pika
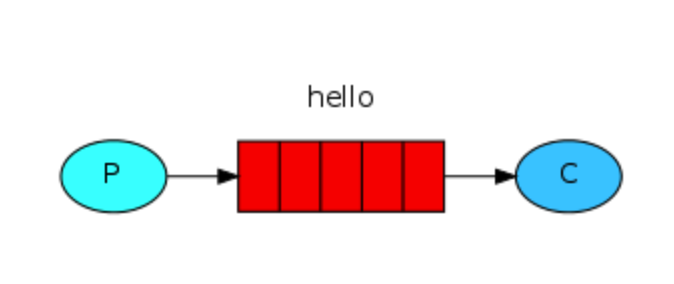
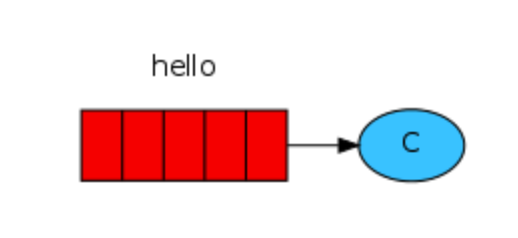
生产-消费者模型
P 是生产者
C 是消费者
中间hello是消息队列
可以有多个P、多个C
P发送消息给hello队列,C消费者从队列中获取消息,默认轮询方式
生产者send.py
我们的第一个程序send.py将向队列发送一条消息。我们需要做的第一件事是建立与RabbitMQ服务器的连接。
#!/usr/bin/env python
import pika
# 创建凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("root","123")
# 新建连接,这里localhost可以更换为服务器ip
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
# 创建频道
channel = connection.channel()
# 新建一个hello队列,用于接收消息
channel.queue_declare(queue='oldboypython')
# 注意在rabbitmq中,消息想要发送给队列,必须经过交换(exchange),初学可以使用空字符串交换(exchange=''),它允许我们精确的指定发送给哪个队列(routing_key=''),参数body值发送的数据
channel.basic_publish(exchange='',
routing_key='oldboypython',
body='msg6')
print("已经发送了消息")
# 程序退出前,确保刷新网络缓冲以及消息发送给rabbitmq,需要关闭本次连接
connection.close()
可以同时存在多个接受者,等待接收队列的消息,默认是轮训方式分配消息
接受者receive.py,可以运行多次,运行多个消费者
import pika
# 建立与rabbitmq的连接
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="oldboypython")
def callbak(ch,method,properties,body):
print("消费者接收到了任务:%r"%body)
# 有消息来临,立即执行callbak,没有消息则夯住,等待消息
channel.basic_consume(callbak,queue="oldboypython",no_ack=True)
# 开始消费,接收消息
channel.start_consuming()
练习:
分别启动生产者、两个消费者,往队列发送数据,查看消费者的结果
rabbitmq消息确认之ack
官网资料:http://www.rabbitmq.com/tutorials/tutorial-two-python.html
默认情况下,生产者发送数据给队列,消费者取出消息后,数据将被清除。
特殊情况,如果消费者处理过程中,出现错误,数据处理没有完成,那么这段数据将从队列丢失
no-ack机制
不确认机制也就是说每次消费者接收到数据后,不管是否处理完毕,rabbitmq-server都会把这个消息标记完成,从队列中删除
ACK机制
ACK机制用于保证消费者如果拿了队列的消息,客户端处理时出错了,那么队列中仍然还存在这个消息,提供下一位消费者继续取
生产者.py 只负责发送数据即可
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61'))
# 有密码
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='s13q2')
channel.basic_publish(exchange='',
routing_key='s13q2', # 关键字查找到队列名
body='msg8')
connection.close()
消费者.py给与ack回复
拿到消息必须给rabbitmq服务端回复ack信息,否则消息不会被删除,防止客户端出错,数据丢失
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='s13q2')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# int('asdfasdf')
# 我告诉rabbitmq服务端,我已经取走了消息
ch.basic_ack(delivery_tag=method.delivery_tag)
# 关闭no_ack,给与服务端ack回复
channel.basic_consume(callback,queue='s13q2',no_ack=False)
channel.start_consuming()
消息持久化
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢——消息持久化。 为了保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。
生产者.py
import pika
# 无密码
# connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61'))
# 有密码
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
# 默认此队列不支持持久化,如果服务挂掉,数据丢失
# durable=True 开启持久化,必须新开启一个队列,原本的队列已经不支持持久化了
channel.queue_declare(queue='music',durable=True)
channel.basic_publish(exchange='',
routing_key='music', # 消息队列名称
body='haohaio4',
# 支持数据持久化
properties=pika.BasicProperties(
delivery_mode=2,
)
)
connection.close()
消费者.py
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 声明一个队列(创建一个队列)
channel.queue_declare(queue='music',durable=True)
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
# 模拟代码报错
# int('asdfasdf')
# 此处报错,没有给予回复,保证客户端挂掉,数据不丢失
# 告诉服务端,我已经取走了数据
# ch.basic_ack(delivery_tag=method.delivery_tag)
# 关闭no_ack,代表给与回复确认
channel.basic_consume(callback,queue='music',no_ack=False)
channel.start_consuming()
Exchange模型
rabbitmq发送消息首先是发给exchange,然后再通过exchange发送消息给队列(queue)
exchange有四种模式
fanout
exchange将消息发送给和该exchange连接的所有queue;也就是所谓的广播模式;此模式下忽略routing_key;
direct
路由模式,通过routing_key将消息发送给对应的queue; 如下面这句即可设置exchange为direct模式,只有routing_key为“black”时才将其发送到队列queue_name; channel.queue_bind(exchange=exchange_name,queue=queue_name,routing_key='black')
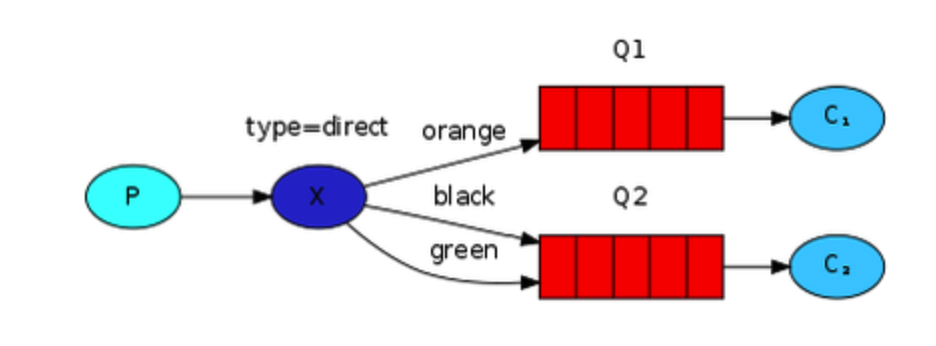
在上图中,Q1和Q2可以绑定同一个key,如绑定routing_key=‘KeySame’,那么收到routing_key为KeySame的消息时将会同时发送给Q1和Q2,退化为广播模式;
top
topic模式类似于direct模式,只是其中的routing_key变成了一个有“.”分隔的字符串,“.”将字符串分割成几个单词,每个单词代表一个条件;
headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
官方教程:http://www.rabbitmq.com/tutorials/tutorial-three-python.html
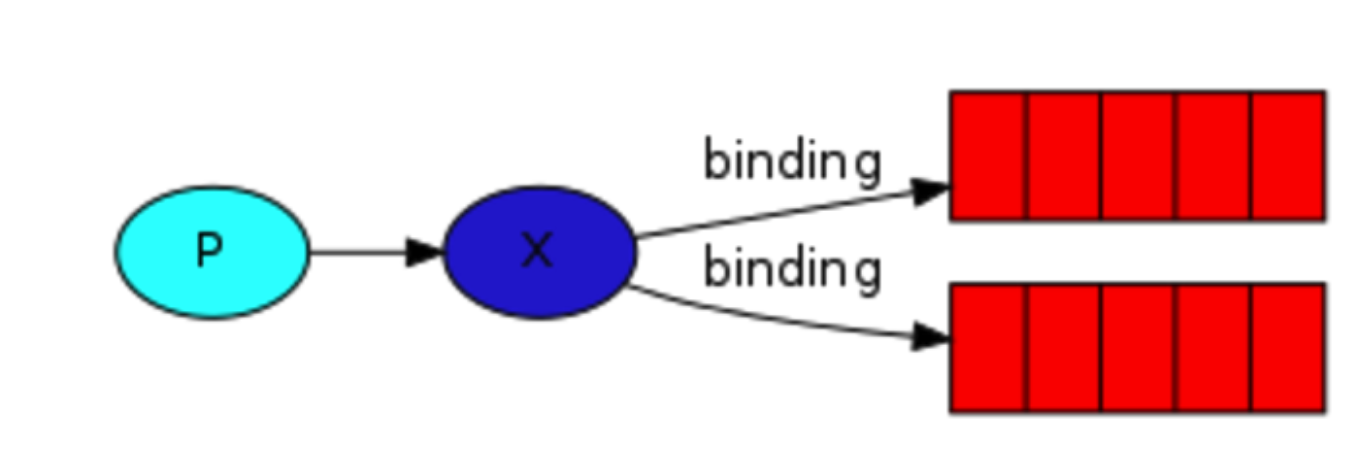
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
# fanout所有的队列放一份/给某些队列发
# 传送消息的模式
# 与exchange有关的模式都发
exchange_type = fanout
消费者_订阅.py
可以运行多次,运行多个消费者,等待消息
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m1',exchange_type='fanout')
# 随机生成一个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m1',queue=queue_name)
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
生产者_发布者.py
# -*- coding: utf-8 -*-
# __author__ = "yugo"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 指定exchange
channel.exchange_declare(exchange='m1',exchange_type='fanout')
channel.basic_publish(exchange='m1',
routing_key='',# 这里不再指定队列,由exchange分配,如果是fanout模式,每一个队列放一份
body='haohaio')
connection.close()
实例
1.可以运行多个消费者,相当于有多个滴滴司机,等待着Exchange同一个电台发消息
2.运行发布者,发送消息给Exchange,查看是否给所有的队列(滴滴司机)发送了消息
关键字发布Exchange
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。

消费者1.py
路由关键字是sb,alex
# -*- coding: utf-8 -*-
# __author__ = "maple"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 随机生成一个队列,队列退出时,删除这个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定,只要
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='alex')
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
消费者2.py
路由关键字sb
# -*- coding: utf-8 -*-
# __author__ = "maple"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# exchange='m1',exchange(秘书)的名称
# exchange_type='fanout' , 秘书工作方式将消息发送给所有的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 随机生成一个队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 让exchange和queque进行绑定.
channel.queue_bind(exchange='m2',queue=queue_name,routing_key='sb')
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()
生产者.py
发送消息给匹配的路由,sb或者alex
# -*- coding: utf-8 -*-
# __author__ = "yugo"
import pika
credentials = pika.PlainCredentials("root","123")
connection = pika.BlockingConnection(pika.ConnectionParameters('123.206.16.61',credentials=credentials))
channel = connection.channel()
# 路由模式的交换机会发送给绑定的key和routing_key匹配的队列
channel.exchange_declare(exchange='m2',exchange_type='direct')
# 发送消息,给有关sb的路由关键字
channel.basic_publish(exchange='m2',
routing_key='sb',
body='aaaalexlaolelaodi')
connection.close()
RPC之远程过程调用
将一个函数运行在远程计算机上并且等待获取那里的结果,这个称作远程过程调用(Remote Procedure Call)或者 RPC。RPC是一个计算机通信协议。
比喻
将计算机服务运行理解为厨师做饭,厨师想做一个小葱拌豆腐,厨师需要洗小葱、切豆腐、调汁、凉拌。他一个人完成所有的事,如同古老的集中式应用,一台计算机做所有的事。
制作小葱拌豆腐{
厨师>洗小葱>切豆腐>凉拌
}
rpc应用场景
而如今,饭店做大了,有钱了,专职分工来干活,不再是厨师单打独斗,备菜师傅准备小葱、豆腐,切菜师傅切小葱、豆腐,厨师只负责调味,完成食品。
制作小葱拌豆腐{
备菜师>洗菜
切菜师>切菜
厨师>调味
}
此时一件事好多人在做,厨师就得和其他人沟通,通知备菜、洗菜师傅的这个动作就是远程过程调用(RPC)。
这个过程在计算机系统中,一个电商的下单过程,涉及物流、支付、库存、红包等多个系统,多个系统又在多个服务器上,由不同的技术团队负责,整个下单过程,需要所有团队进行远程调用。
下单{
库存>减少库存
支付>扣款
红包>减免红包
物流>生成订单
}
到底什么是rpc
rpc指的是在计算机A上的进程,调用另外一台计算机B的进程,A上的进程被挂起,B上的被调用进程开始执行后,产生返回值给A,A继续执行。
调用方可以通过参数将信息传递给被调用方,而后通过返回结果得到信息,这个过程对于开发人员来说是透明的。
如同厨师一样,服务员把菜单给后厨,厨师告诉洗菜人,备菜人,开始工作,完成工作后,整个过程对于服务员是透明的,他完全不用管后厨是怎么把菜做好的。
由于服务在不同的机器上,远程调用必经网络通信,调用服务必须写一坨网络通信代码,很容易出错且很复杂,因此就出现了RPC框架。
阿里巴巴的 Dubbo java
新浪的 Motan java
谷歌的 gRPC 多语言
Apache thrift 多语言
python实现RPC
利用RabbitMQ构建一个RPC系统,包含了客户端和RPC服务器,依旧使用pika模块
Callback queue 回调队列
一个客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识
一个客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
客户端发送请求:某个应用将请求信息交给客户端,然后客户端发送RPC请求,在发送RPC请求到RPC请求队列时,客户端至少发送带有reply_to以及correlation_id两个属性的信息
服务器端工作流: 等待接受客户端发来RPC请求,当请求出现的时候,服务器从RPC请求队列中取出请求,然后处理后,将响应发送到reply_to指定的回调队列中
客户端接受处理结果: 客户端等待回调队列中出现响应,当响应出现时,它会根据响应中correlation_id字段的值,将其返回给对应的应用
rpc_server.py
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
# 客户端启动时,创建回调队列,会开启会话用于发送RPC请求以及接受响应
# 建立连接,指定服务器的ip地址
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='123.206.16.61'))
# 建立一个会话,每个channel代表一个会话任务
self.channel = self.connection.channel()
# 声明回调队列,再次声明的原因是,服务器和客户端可能先后开启,该声明是幂等的,多次声明,但只生效一次
result = self.channel.queue_declare(exclusive=True)
# 将次队列指定为当前客户端的回调队列
self.callback_queue = result.method.queue
# 客户端订阅回调队列,当回调队列中有响应时,调用`on_response`方法对响应进行处理;
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
# 对回调队列中的响应进行处理的函数
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
# 发出RPC请求
def call(self, n):
# 初始化 response
self.response = None
# 生成correlation_id 关联标识
self.corr_id = str(uuid.uuid4())
# 发送RPC请求内容到RPC请求队列`rpc_queue`,同时发送的还有`reply_to`和`correlation_id`
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
# 建立客户端
fibonacci_rpc = FibonacciRpcClient()
# 发送RPC请求
print(" [x] Requesting sum(30)")
response = fibonacci_rpc.call(40)
print(" [.] Got %r" % response)
rpc_client.py
import pika
# 建立连接,服务器地址为localhost,可指定ip地址
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='123.206.16.61'))
# 建立会话
channel = connection.channel()
# 声明RPC请求队列
channel.queue_declare(queue='rpc_queue')
# 数据处理方法
def sum(n):
n+=100
return n
# 对RPC请求队列中的请求进行处理
def on_request(ch, method, props, body):
n = int(body)
print(" [.] sum(%s)" % n)
# 调用数据处理方法
response = sum(n)
# 将处理结果(响应)发送到回调队列
ch.basic_publish(exchange='',
# reply_to代表回复目标
routing_key=props.reply_to,
# correlation_id(关联标识):用来将RPC的响应和请求关联起来。
properties=pika.BasicProperties(correlation_id= \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag)
# 负载均衡,同一时刻发送给该服务器的请求不超过一个
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
消息队列rabbitmq/kafka的更多相关文章
- 消息队列--RabbitMQ(一)
1.消息队列概述 可以理解为保存消息的一个媒介/或者是个容器,与之相关有两个概念(即生产者(Publish)与消费者(Consumer)).所谓生产者,就是生产创造消息的一方,那么,消费者便是从队列中 ...
- (一)RabbitMQ消息队列-RabbitMQ的优劣势及产生背景
原文:(一)RabbitMQ消息队列-RabbitMQ的优劣势及产生背景 本篇并没有直接讲到技术,例如没有先写个Helloword.我想在选择了解或者学习一门技术之前先要明白为什么要现在这个技术而不是 ...
- nodejs操作消息队列RabbitMQ
一. 什么是消息队列 消息队列(Message Queue,简称MQ),从字面意思上看,本质是个队列,FIFO先入先出,只不过队列中存放的内容是message而已.其主要用途:不同进程Process/ ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- C#中使用消息队列RabbitMQ
在C#中使用消息队列RabbitMQ 2014-10-27 14:41 by qy1141, 745 阅读, 2 评论, 收藏, 编辑 1.什么是RabbitMQ.详见 http://www.rabb ...
- node使用消息队列RabbitMQ一
基础发布和订阅 消息队列RabbitMQ使用 1 安装RabbitMQ服务器 安装erlang服务 下载地址 http://www.erlang.org/downloads 安装RabbitMQ 下载 ...
- 消息队列与Kafka
2019-04-09 关键词: 消息队列.为什么使用消息队列.消息队列的好处.消息队列的意义.Kafka是什么 本篇文章系本人就当前所掌握的知识关于 消息队列 与 kafka 知识点的一些简要介绍,不 ...
- redis 的消息队列 VS kafka
redis push/pop VS pub/sub (1)push/pop每条消息只会有一个消费者消费,而pub/sub可以有多个 对于任务队列来说,push/pop足够,但真的在做分布式消息分发的时 ...
- 消息队列之 Kafka
转 https://www.jianshu.com/p/2c4caed49343 消息队列之 Kafka 预流 2018.01.15 16:27* 字数 3533 阅读 1114评论 0喜欢 12 K ...
随机推荐
- Codeforces 1194E. Count The Rectangles
传送门 看到 $n<=5000$,直接暴力枚举左右两条竖线 然后考虑怎么计算高度在某个范围内,左端点小于等于某个值,右端点大于等于某个值的横线数量 直接用权值树状数组维护当前高度在某个区间内的横 ...
- deepin 15.10.1 GTX1060 NVIDIA 驱动安装,双屏显示问题记录
有一段时间没有用Linux了.由于买了个4k的戴尔显示屏,在deepin系统上无法用,从昨晚到现在,总于解决了我的问题! 问题1:无法直接在深度的显卡驱动管理器哪里直接切换,网上看到很多人都有这个问题 ...
- 删库?半个DBA的跑路经验总结
0. 国内呆不下了,赶紧出国 首先,不要选动车,要选最近的一班飞机,尽快出国,能走高速走高速,不然选人少的路线. 没错,我们 DBA 都是常备护照的. 切记,注意看高德地图实时路况. 我们有个前辈就是 ...
- Linux之常用脚本
1) #检查php Money 队列脚本是否启动 php_count=`ps -ef | grep Money | grep -v "grep" | wc -l` ];then e ...
- python删除数组中元素
有数组a,要求去掉a所有为0的元素 a = [2,4,0,8,9,10,100,0,9,7] Filter a= filter(None, a) Lambada a = filter(lambda x ...
- Navicat连接Mysql11.1.13出现1251错误
打开Navicat软件,单击左上角[连接]按钮,选择mysql,弹出新建连接,输入相关信息,单击[连接测试],报1251的错误,如下图所示: 根因分析: mysql8 之前的版本中加密规则是mysql ...
- 配置Linux静态IP地址
- js 继承的简单理解
什么是继承 js中的继承就是获取存在对象已有属性和方法的一种方式. 继承一 属性拷贝 就是将对象的成员复制一份给需要继承的对象. // 创建父对象 var superObj = { name:'liy ...
- 月薪 30K Java 程序员,需要掌握哪些技术?
转载自:Java3y 1-5年的Java程序员,薪资区间大致是在15-25K左右,那有没有可能提前达到30K的薪资呢?有人说这只能是大企业或者互联网企业工程师才能拿到.也许是的,小公司或者非互联网企业 ...
- Jenkins+GitHub 项目环境搭建和发布脚本(二)
Jenkins+gitHub项目搭建配置 项目发布脚本 profilesScript.sh (支持不同环境配置文件) #!/bin/bash ACTIVE=$ JENKINS_PATH=/var/li ...