系统符号二——正则表达式及三剑客之grep
一基础正则表达式
(一)^ 匹配以什么开头的信息
[root@centos71 ~]# grep "^root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@centos71 ~]# grep "^r" /etc/passwd
root:x:0:0:root:/root:/bin/bash
注意红色显示的才是真正匹配的内容

(二)$——匹配以什么结尾的信息
[root@centos71 ~]# cat /etc/selinux/config # This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@centos71 ~]# grep "disabled$" /etc/selinux/config
SELINUX=disabled
[root@centos71 ~]# grep "ed$" /etc/selinux/config
SELINUX=disabled
SELINUXTYPE=targeted

^$ 匹配空行信息
[root@centos71 ~]# grep "^$" /etc/selinux/config [root@centos71 ~]# grep "^$" /etc/selinux/config | wc
4 0 4
[root@centos71 ~]#
利用v进行取反,排除空行显示
[root@centos71 ~]# wc /etc/selinux/config
15 81 542 /etc/selinux/config
[root@centos71 ~]# grep -v "^$" /etc/selinux/config | wc
11 81
(三). 点——匹配任意一个字符且只有一个字符
[root@centos71 test]# cat test.txt
gd
god
good
goood
gooood
[root@centos71 test]# grep "g.d" test.txt
god
[root@centos71 test]# grep "g..d" test.txt
good
[root@centos71 test]# grep "g...d" test.txt
goood
[root@centos71 test]# grep "g....d" test.txt
gooood
[root@centos71 test]# grep "g.....d" test.txt
[root@centos71 test]# pwd
/test
[root@centos71 test]# grep "g.d" test.txt -o
god
[root@centos71 test]# grep "g..d" test.txt -o
good
[root@centos71 test]# grep "g...d" test.txt -o
goood
贪婪匹配,尽可能多的匹配
[root@centos71 test]# cat test.txt
gd
god
good
goood
gooood
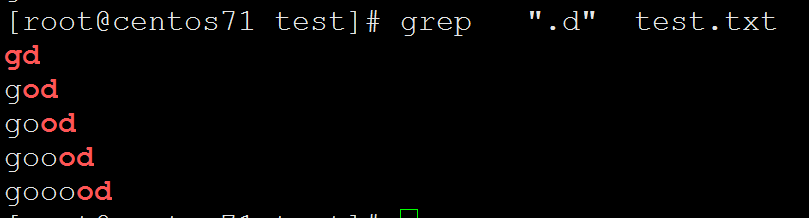
[root@centos71 test]# grep ".d" test.txt
gd
god
good
goood
gooood
(四)* 匹配符号前面一个字符连续出现0次或者多次
[root@centos71 test]# cat test.txt
gd
god
good
goood
gooood
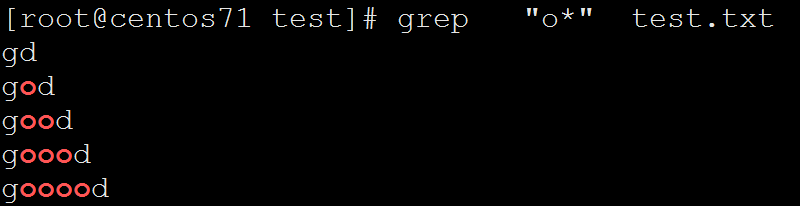
[root@centos71 test]# grep "o*" test.txt
gd
god
good
goood
gooood
匹配任意一个字符连续出现多次,空格也是字符
[root@centos71 ~]# cat /etc/passwd | grep "^n.*n$"
nobody:x:99:99:Nobody:/:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
nginx:x:997:995:Nginx web server:/var/lib/nginx:/sbin/nologin
(五) .* ——匹配任意所有字符信息
[root@centos71 ~]# cat /etc/passwd | grep "^n.*n$"
nobody:x:99:99:Nobody:/:/sbin/nologin
ntp:x:38:38::/etc/ntp:/sbin/nologin
nginx:x:997:995:Nginx web server:/var/lib/nginx:/sbin/nologin
[root@centos71 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@centos71 ~]# cat /etc/hosts | grep "^[0-9].*[0-9]$"
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
(六)\撬棍——转义(将意思进行转变)符号
1) 将有意义信息变得没有意义
2) 将没意义信息变得有意义
表示任意一个字符结尾
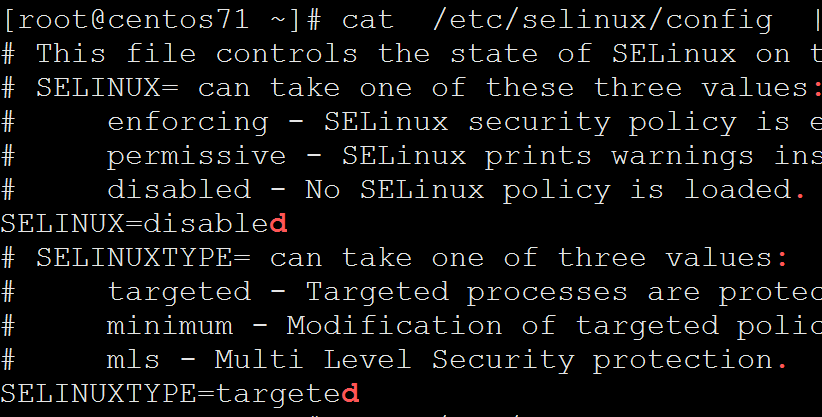
[root@centos71 ~]# cat /etc/selinux/config | grep ".$"
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
变成普通的点
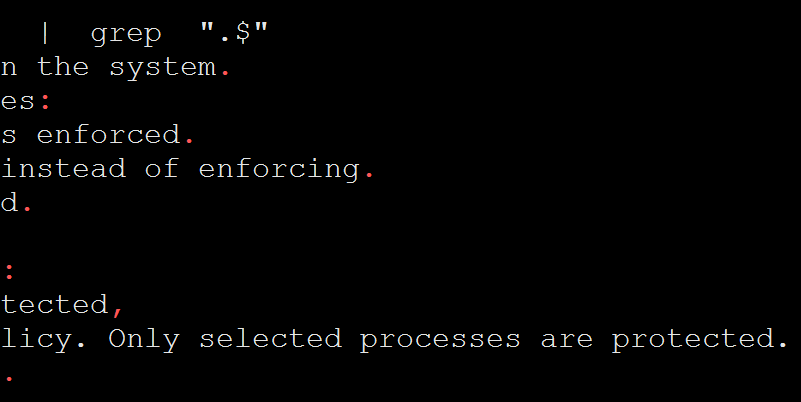
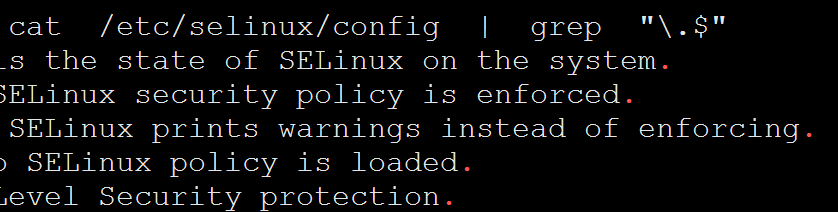
[root@centos71 ~]# cat /etc/selinux/config | grep "\.$"
# This file controls the state of SELinux on the system.
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# mls - Multi Level Security protection.
[root@centos71 ~]#
转义符号将没意义信息变得有意义
\t --- 制表符号
\n --- 换行符号
\r --- 换行符号
换行符对于echo来说是高级符号,要加参数e来识别,和颜色一样
[root@centos71 test]# echo wuwuwuwuhahahaha
wuwuwuwuhahahaha
[root@centos71 test]# echo wuwuwuwu\nhahahaha
wuwuwuwunhahahaha
[root@centos71 test]# echo -e wuwuwuwu\nhahahaha
wuwuwuwunhahahaha
[root@centos71 test]# echo "wuwuwuwu\nhahahaha"
wuwuwuwu\nhahahaha
[root@centos71 test]# echo -e "wuwuwuwu\nhahahaha"
wuwuwuwu
hahahaha
制表符可以保持word文本间距等齐
(七)[ ]——匹配多个字符信息
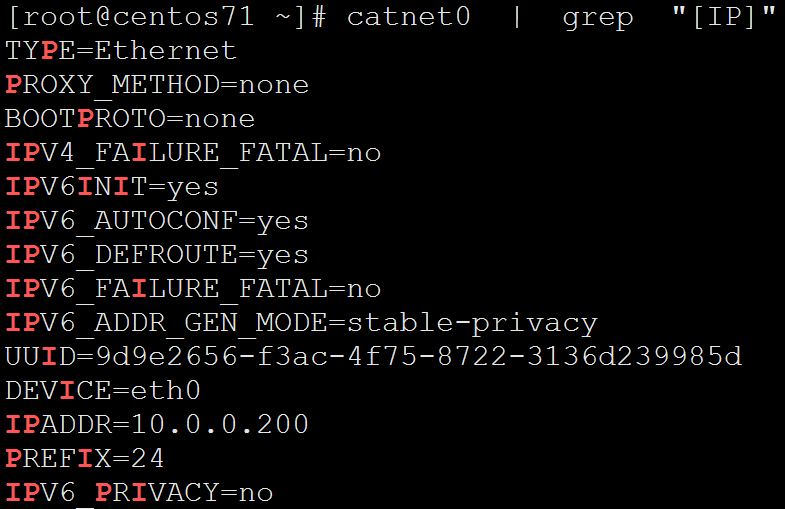
[root@centos71 ~]# catnet0 | grep "[IP]"
TYPE=Ethernet
PROXY_METHOD=none
BOOTPROTO=none
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
UUID=9d9e2656-f3ac-4f75--3136d239985d
DEVICE=eth0
IPADDR=10.0.0.200
PREFIX=
IPV6_PRIVACY=no
[root@centos71 ~]# catnet0 | grep "[IP]" -o
P
P
P
I
P
I
I
P
I
I
I
P
I
P
I
P
I
I
P
I
I
I
P
P
I
I
P
P
I
注意中括号里面不加^,而是加其他字符就会被解释为普通字符
[root@centos71 ~]# grep -E "[=]" /etc/selinux/config
# SELINUX= can take one of these three values:
SELINUX=enforcing
# SELINUXTYPE= can take one of three values:
SELINUXTYPE=targeted
[root@centos71 ~]# grep -E "[=]" /etc/selinux/config -o
=
=
=
=
但是这样的话直接过滤就可以了
[root@centos71 test]# grep "=" /etc/selinux/config
# SELINUX= can take one of these three values:
SELINUX=enforcing
# SELINUXTYPE= can take one of three values:
SELINUXTYPE=targeted
[root@centos71 test]# grep "=" /etc/selinux/config -o
=
=
=
=
(八)[ ^ ]——匹配多个字符信息进行取反排除
[root@centos71 ~]# cat /etc/issue
\S
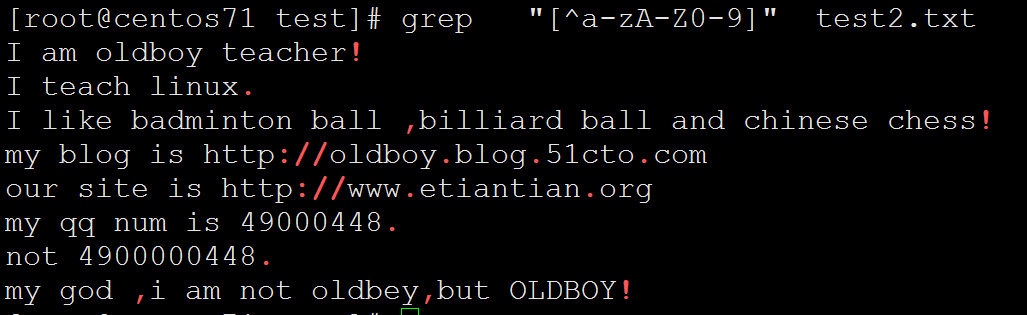
Kernel \r on an \m [root@centos71 ~]# cat /etc/issue | grep "[^a-z]"
\S
Kernel \r on an \m
[root@centos71 ~]# cat /etc/issue | grep "[^a-z]" -o
\
S
K \ \
二扩展正则表达式
(一)+——匹配符号前面一个字符连续出现1次或者多次
[root@centos71 test]# cat test.txt
gd
god
good
goood
gooood
[root@centos71 test]# grep -E "o+" test.txt
god
good
goood
gooood
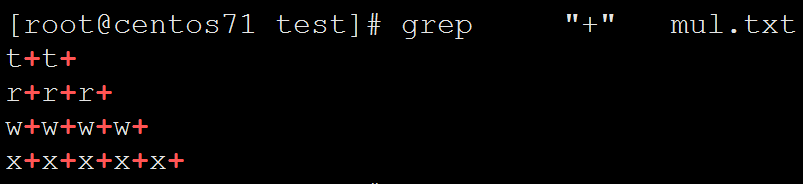
注意使用撬棍可以使+进行转义,变成单纯的+
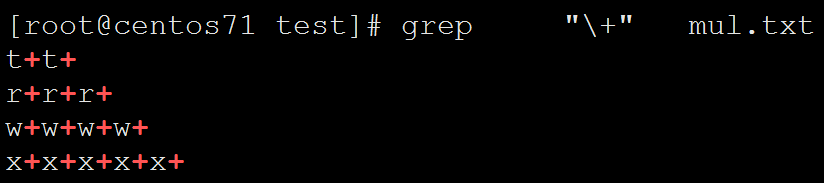
[root@centos71 test]# cat mul.txt
t+t+
r+r+r+
w+w+w+w+
x+x+x+x+x+
[root@centos71 test]# grep "\+" mul.txt
t+t+
r+r+r+
w+w+w+w+
x+x+x+x+x+
[root@centos71 test]# grep "\+" mul.txt -o
+
+
+
+
+
+
+
+
+
+
+
+
+
+
直接过滤更方便
[root@centos71 test]# grep "+" mul.txt
t+t+
r+r+r+
w+w+w+w+
x+x+x+x+x+
[root@centos71 test]# grep "+" mul.txt -o
+
+
+
+
+
+
+
+
+
+
+
+
+
+
.+匹配任意一个字符一次以上
[root@centos71 test]# grep -E ".+" /etc/issue
\S
Kernel \r on an \m
[root@centos71 test]# grep -E ".+" /etc/issue -o
\S
Kernel \r on an \m
(二)?——匹配符号前面一个字符连续出现0次或1次
易错点:2,3,4个o包含了1个o
[root@centos71 test]# grep -E "o?" test.txt
gd
god
good
goood
gooood
查看过程很明显
[root@centos71 test]# grep -E "o?" test.txt -o
o
o
o
o
o
o
o
o
o
o
(三){ }——匹配符号前面一个字符连续出现指定次数
匹配o为2-3次
[root@centos71 test]# grep -E "o{2,3}" test.txt
good
goood
gooood
过滤的过程
[root@centos71 test]# grep -E "o{2,3}" test.txt -o
oo
ooo
ooo
匹配o在2次以上
[root@centos71 test]# cat test.txt
gd
god
good
goood
gooood
[root@centos71 test]# grep -E "o{2,}" test.txt
good
goood
gooood
[root@centos71 test]# grep -E "o{2,}" test.txt -o
oo
ooo
oooo
注意最后一行是3+1,看过程
[root@centos71 test]# grep -E "o{,3}" test.txt
gd
god
good
goood
gooood
[root@centos71 test]# grep -E "o{,3}" test.txt -o
o
oo
ooo
ooo
o
-w按照单词进行过滤
注意此单词非彼单词,是以空格作为分割符
[root@centos71 test]# cat identify.txt
linda 110109190006078765
merry 105110120110028123
suhadu 12482749277297292731829371
[root@centos71 test]# cat identify.txt | grep -Ew "[0-9]{18}"
linda 110109190006078765
merry
[root@centos71 test]# cat identif.txt | grep -Ew "([0-9]|X$){18}" -o
110109197706078765
105110111100281236
10511011110028123X
(四)|——匹配多个字符串信息
[root@centos71 ~]# grep -E "~#|^$|#" /etc/selinux/config # This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection. [root@centos71 ~]# grep -vE "~#|^$|#" /etc/selinux/config
SELINUX=disabled
SELINUXTYPE=targeted
匹配以#开头或者以.结尾的行
[root@centos71 ~]# grep -E "^#|\.$" /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
[root@centos71 ~]# grep -E "^#|\.$" /etc/selinux/config -o
#
.
#
#
.
#
.
#
.
#
#
#
#
.
(五)()——将多个字符信息汇总成一个整体
过滤出含有disabled的行
[root@centos71 ~]# grep -E "(disabled)" /etc/selinux/config
# disabled - No SELinux policy is loaded.
SELINUX=disabled
[root@centos71 ~]# grep -E "(disabled)" /etc/selinux/config -o
disabled
disabled
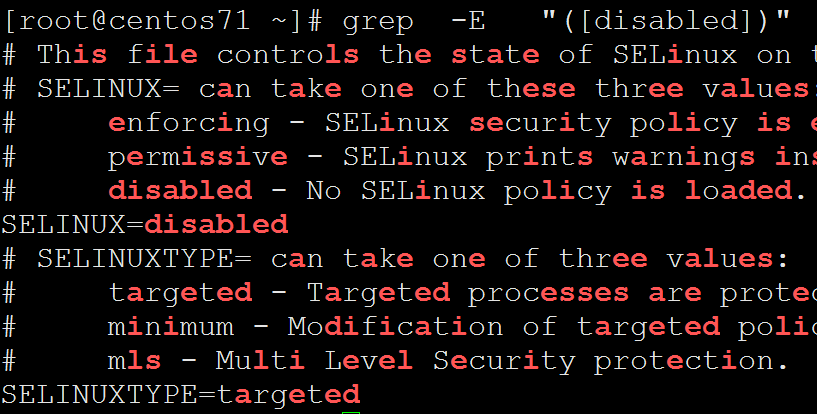
下面情况是分开的,disabled中的任意一个字符出现即可
[root@centos71 ~]# grep -E "([disabled])" /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
匹配多次出现的单词
注意下面()和[ ]的区别
[root@centos71 test]# cat hahaha.txt
hahahahahahahahaha
wuwuwuwuwuwuwuwuwu
xixixixixixixixixi
aiaiaiaiaiaiaiaiai
heiheiheiheiheihei
hehehehehehehehehe
bababababababababa
mamamamamamamamama
表示匹配3次x或者i
[root@centos71 test]# cat hahaha.txt | grep -E "[xi]{3}"
xixixixixixixixixi
[root@centos71 test]# cat hahaha.txt | grep -E "[xi]{3}" -o
xix
ixi
xix
ixi
xix
ixi
匹配3次xi,并且是贪婪匹配
[root@centos71 test]# cat hahaha.txt | grep -E "(xi){3}"
xixixixixixixixixi
[root@centos71 test]# cat hahaha.txt | grep -E "(xi){3}" -o
xixixi
xixixi
xixixi
利用sed进行替换时, 实现后向引用前项
[root@centos71 ~]# echo 123456 | sed 's#123456#<123456>#g'
<123456>
[root@centos71 ~]# echo 654321 | sed 's#123456#<123456>#g'
()表示把字符都保护起来,.*表示前面的任意字符
[root@centos71 ~]# echo 654321 | sed -r 's#(.*)#<\1>#g'
<654321>
拆分,每2个一组,<>是装饰,\2表示前面第2部分
3000=1040多看
[root@centos71 ~]# echo 12345678787878787878 | sed -r 's#(..)(..)(..)(..)(..)(..)(..)(..)(..)(..)#<\1><\2><\3><\4><\5><\6><\7><\8><\9><\10>#g'
<12><34><56><78><78><78><78><78><78><120>
正确显示,匹配偶数个
[root@centos71 ~]# echo 12345678787878787878 | sed -r 's#(.{2})#<\1>#g'
<12><34><56><78><78><78><78><78><78><78>
匹配奇数个
[root@centos71 ~]# echo 123456787878787878789 | sed -r 's#(.{1,2})#<\1>#g'
<12><34><56><78><78><78><78><78><78><78><9>
[root@centos71 ~]# echo 123456787878787878789 | sed -r 's#(.{1,2})#{\1}#g'
{12}{34}{56}{78}{78}{78}{78}{78}{78}{78}{9}
[root@centos71 ~]# echo 123456787878787878789 | sed -r 's#(.{1,2})#{\2}#g'
sed: -e expression #1, char 17: invalid reference \2 on `s' command's RHS
[root@centos71 ~]# echo 123456787878787878789 | sed -r 's#(.{1,2})#{\3}#g'
sed: -e expression #1, char 17: invalid reference \3 on `s' command's RHS
练习一——取出特定文件的权限
先定位,并且要选择独特的关键字
[root@centos71 test]# stat /etc/hosts
File: ‘/etc/hosts’
Size: 158 Blocks: 8 IO Block: 4096 regular file
Device: 803h/2051d Inode: 35530425 Links: 1
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-12-18 11:50:37.597173908 +0800
Modify: 2019-12-16 11:42:41.175934855 +0800
Change: 2019-12-18 11:09:06.359382129 +0800
Birth: -
[root@centos71 test]# stat /etc/hosts | grep Uid
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)
[root@centos71 test]# stat /etc/hosts | grep Uid | grep -E "[0-7]{4}"
Access: (0640/-rw-r-----) Uid: ( 0/ root) Gid: ( 0/ root)

[root@centos71 ~]# stat /etc/hosts | grep Uid | grep -E "[0-7]{4}" -o
练习二——取出IP地址信息
注意如果centos7修改为传统网卡,那么下面方法也适用于centos6
[0-9]表示IP地址的数字
{1,3}表示最少1位,最多3位
后面匹配的是点,而不是任意字符,所以要加上\
方法一
显示指定的网卡信息
[root@centos71 ~]# ip a s eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:ea:b8:14 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::951a:d6ce:9fbd:c7b7/64 scope link noprefixroute
valid_lft forever preferred_lft forever
注意关键字后面是有空格的,这样和inet6那么区分开
[root@centos71 ~]# ip a s eth0|grep "inet "
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
匹配到了IP地址的网络位,也就是xxx.xxx.xxx.格式
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "(([0-9]{1,3}\.){3}[0-9]{1,3})"
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "(([0-9]{1,3}\.){3}[0-9]{1,3})" -o
10.0.0.200
10.0.0.255

已经完全匹配了IP地址,但是要把广播地址过滤掉
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "(([0-9]{1,3}\.){3}[0-9]{1,3})"
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
[root@centos71 ~]#
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "(([0-9]{1,3}\.){3}[0-9]{1,3})" -o
10.0.0.200
10.0.0.255
通过特征过滤掉另外一个地址
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "(([0-9]{1,3}\.){3}[0-9]{1,3})" -o | head -1
10.0.0.200
方法二
.?组合符号,表示匹配.(点)的次数为0-1次
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9]{1,3}\.?){4}"
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9]{1,3}\.?){4}" -o
10.0.0.200
10.0.0.255
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9]{1,3}\.?){4}" -o | head -1
10.0.0.200
方法三
把数字和点组合起来,要么是数字要么是点,点为固定数3个
最少是3个点+4个数字,此时数字为一位数;最多是3个点+12个数字,此时数字为三位数
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})"
inet 10.0.0.200/24 brd 10.0.0.255 scope global noprefixroute eth0
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})" -o
10.0.0.200
10.0.0.255
[root@centos71 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})" -o | head -1
10.0.0.200
注意IPV6的地址有8组
xxxx:xxxx:xxxx:0000:0000:0000::xxxx:xxxx
centos6
[root@centos61 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:bc:ff:d7 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.61/24 brd 10.0.0.255 scope global eth0
inet6 fe80::20c:29ff:febc:ffd7/64 scope link
valid_lft forever preferred_lft forever
[root@centos61 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})"
inet 10.0.0.61/24 brd 10.0.0.255 scope global eth0
[root@centos61 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})" -o
10.0.0.61
10.0.0.255
[root@centos61 ~]# ip a s eth0|grep "inet "|grep -E "([0-9.]{7,15})" -o | head -1
10.0.0.61
练习三——磁盘使用率
[root@centos71 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 40G 3.0G 38G 8% /
devtmpfs 476M 0 476M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/sda1 197M 105M 93M 54% /boot
tmpfs 98M 0 98M 0% /run/user/0
[root@centos71 ~]# df -h | grep /dev/sda1|grep -E "[0-9]{1,3}%"
/dev/sda1 197M 105M 93M 54% /boot
[root@centos71 ~]# df -h | grep /dev/sda1|grep -E "[0-9]{1,3}%" -o
54%
一般两位数就可以了,%可以进行区分
说明:正则匹配一行信息时,默认有贪婪特性
[root@centos71 ~]# df -h | grep /dev/sda1|grep -E "[0-9]{1,2}%" -o
54%
三grep常用参数总结
grep -i --- 忽略大小写搜索信息
-i, --ignore-case
Ignore case distinctions in both the PATTERN and the input files. (-i is specified by
POSIX.)
grep -n --- 搜索信息后显示行号
-n, --line-number
Prefix each line of output with the 1-based line number within its input file. (-n is
specified by POSIX.)
grep -c --- 统计筛选出来的行数
-c, --count
Suppress normal output; instead print a count of matching lines for each input file.
With the -v, --invert-match option (see below), count non-matching lines. (-c is
specified by POSIX.)
grep -v --- 将搜索信息进行取反
-v, --invert-match
Invert the sense of matching, to select non-matching lines. (-v is specified by
POSIX.)
grep -w --- 按照字符串进行匹配
-w, --word-regexp
Select only those lines containing matches that form whole words. The test is that the
matching substring must either be at the beginning of the line, or preceded by a non-
word constituent character. Similarly, it must be either at the end of the line or
followed by a non-word constituent character. Word-constituent characters are letters,
digits, and the underscore.
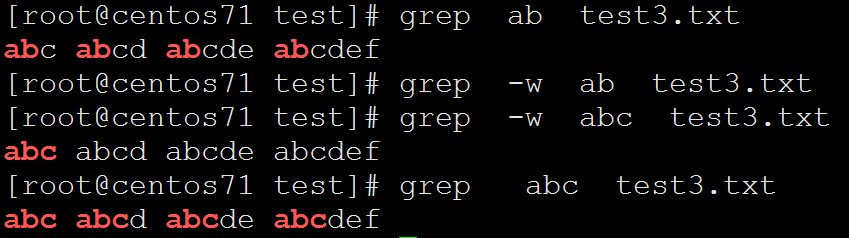
[root@centos71 test]# cat test3.txt
abc abcd abcde abcdef
grep -o --- 只输出显示匹配信息
-o, --only-matching
Print only the matched (non-empty) parts of a matching line, with each such part on a
separate output line.
grep -A --- 过滤指定内容之后的信息
-A NUM, --after-context=NUM
Print NUM lines of trailing context after matching lines. Places a line containing a
group separator (described under --group-separator) between contiguous groups of
matches. With the -o or --only-matching option, this has no effect and a warning is
given.
grep -B --- 过滤指定内容之前的信息
-B NUM, --before-context=NUM
Print NUM lines of leading context before matching lines. Places a line containing a
group separator (described under --group-separator) between contiguous groups of
matches. With the -o or --only-matching option, this has no effect and a warning is
given.
grep -C --- 过滤指定内容上下几行的信息
-C NUM, -NUM, --context=NUM
Print NUM lines of output context. Places a line containing a group separator
(described under --group-separator) between contiguous groups of matches. With the -o
or --only-matching option, this has no effect and a warning is given.
grep -E --- 识别扩展正则信息
-E, --extended-regexp
Interpret PATTERN as an extended regular expression (ERE, see below). (-E is specified
by POSIX.)
grep -r --- 递归搜索指定数据信息
-r, --recursive
Read all files under each directory, recursively, following symbolic links only if they
are on the command line. This is equivalent to the -d recurse option.
[root@centos71 test]# mkdir /test/test1/test2 -p
[root@centos71 test]# vim /test/test1/test2/test2.txt
hahahahaha
[root@centos71 test]# grep -r "hahaha"
hahaha.txt:hahahahahahahahaha
test1/test2/test2.txt:hahahahaha
[root@centos71 test]# tree
.
├── aaa.txt
├── aa.txt
├── aa.txt_hard_link
├── hahaha.txt
├── identif.txt
├── identify.txt
├── mail.txt
├── m.conf.tar.gz
├── m.tar.gz
├── qq_num.txt
├── test1
│ └── test2
│ └── test2.txt
├── test2.txt
├── test3.txt
└── test.txt 2 directories, 14 files
系统符号二——正则表达式及三剑客之grep的更多相关文章
- Linux文本处理三剑客之grep及正则表达式详解
Linux文本处理三剑客之grep及正则表达式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux文本处理三剑客概述 grep: 全称:"Global se ...
- linux三剑客之grep
linux基础三剑客之grep 1.grep命令 基本介绍 grep命令是文本本过滤工具,是基于一个模式匹配文件的每一行,grep分类:egrep个fgrep. grep英文名:Global sea ...
- Linux之特殊符号与正则表达式
Linux中常用的特殊符号 '' 所见即所得,吃啥吐啥 "" 特殊符号会被解析运行 `` ==== $() 先运行里面的命令 把结果留下 > 重定向符号 先清空文件的内容 然 ...
- (转)不看绝对后悔的Linux三剑客之grep实战精讲
不看绝对后悔的Linux三剑客之grep实战精讲 原文:http://blog.51cto.com/hujiangtao/1923675 https://www.cnblogs.com/peida/a ...
- 文本三剑客之grep的用法
第1章 正则表达式 1.1 正则表达式的介绍 正则是用来过滤文件内容 为处理大量文本|字符串而定义的一套规则和方法. ...
- 文本处理三剑客之 grep
grep简介 grep(Global search REgular expression and Print out the line)是Linux上的文本处理三剑客之一,另外两个是sed和awk. ...
- Linux中find命令与三剑客之grep和正则
昨日内容回顾 1.每个月的3号.5号和15号,且这天时周六时 执行 00 00 3,5,15 * 6 2.每天的3点到15点,每隔3分钟执行一次 */3 3-15 * * * 3.每周六早上2点半执行 ...
- Linux文件处理三剑客(grep、sed、awk)
下面所说的是Linux中最重要的三个命令在业界被称为"三剑客",它们是grep.sed.awk. 我们现在知道Linux下一切皆文件,对Linux的操作就是对文件的处理,那么怎么能 ...
- Linux文本处理三剑客之grep
简介 grep命令,用于在一个文本文件中或者从STDIN中,根据用户给出的模式(pattern)过滤出所需要的信息. grep以及三剑客中的另外两个工具sed和awk都是基于行处理的,它们会一行行读入 ...
随机推荐
- 函数传参和firture传参数request
前言 为了提高代码的复用性,我们在写用例的时候,会用到函数,然后不同的用例去调用这个函数.比如登录操作,大部分的用例都会先登录,那就需要把登录单独抽出来写个函数,其它用例全部的调用这个登陆函数就行.但 ...
- vue树状结构(tree)
<!DOCTYPE html> <html> <head> <title></title> <style> body { fon ...
- Vue 渲染函数
Vue 推荐在绝大多数情况下使用模板来创建你的 HTML.然而在一些场景中,你真的需要 JavaScript 的完全编程的能力.这时你可以用渲染函数,它比模板更接近编译器. 一 项目结构 二 App组 ...
- 【MM系列】MB1A MB1B MB1C MB11 MIGO的区别解析
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]MB1A MB1B MB1C MB1 ...
- LeetCode.868-二进制距离(Binary Gap)
这是悦乐书的第333次更新,第357篇原创 01看题和准备 今天介绍的是LeetCode算法题中Easy级别的第203题(顺位题号是868).给定正整数N,找到并返回N的二进制表示中两个连续1之间的最 ...
- Ubuntu新建用户以及安装pytorch
环境:Ubuntu18,Python3.6 首先登录服务器 ssh username@xx.xx.xx.xxx #登录一个已有的username 新建用户 sudo adduser username ...
- 使用cython库对python代码进行动态编译达到加速效果及python第三方包的制作安装
1.测试代码:新建 fib.pyx # coding:utf-8 import matplotlib.pyplot as plt import numpy as np from sklearn.cl ...
- Js AJAX Event
;(function () { if ( typeof window.CustomEvent === "function" ) return false; function Cus ...
- CentOS7 策略路由配置
环境说明:Cloud1中的GE0/0/1.GE0/0/3.GE0/0/5接口,分别与Centos7中的eth1.eth2.eth3接口桥接到同一虚拟网卡,R1,R2,R3均配置一条静态默认路由指向Ce ...
- E - 盒子游戏
有两个相同的盒子,其中一个装了n个球,另一个装了一个球.Alice和Bob发明了一个游戏,规则如下:Alice和Bob轮流操作,Alice先操作每次操作时,游戏者先看看哪个盒子里的球的数目比较少,然后 ...