什么是 DQN
粉红色:不会。
黄色:重点。
1.为什么要使用神经网络
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 如果全用表格来存储它们, 恐怕我们的计算机有再大的内存都不够, 而且每次在这么大的表格中搜索对应的状态也是一件很耗时的事. 不过, 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络. 我们可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值. 还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作. 我们可以想象, 神经网络接受外部的信息, 相当于眼睛鼻子耳朵收集信息, 然后通过大脑加工输出每种动作的值, 最后通过强化学习的方式选择动作.
2.更新神经网络
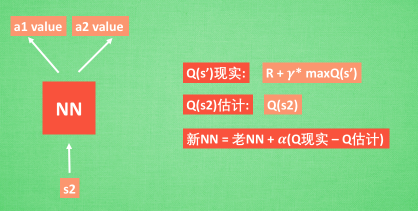
接下来我们基于第二种神经网络来分析, 我们知道, 神经网络是要被训练才能预测出准确的值. 那在强化学习中, 神经网络是如何被训练的呢? 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替. 同样我们还需要一个 Q 估计 来实现神经网络的更新. 所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距. 我们整理一下.

我们通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后我们选取 Q 估计中最大值的动作来换取环境中的奖励 reward. 而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s’ 的估计. 最后再通过刚刚所说的算法更新神经网络中的参数. 但是这并不是 DQN 会玩电动的根本原因. 还有两大因素支撑着 DQN 使得它变得无比强大. 这两大因素就是 Experience replay 和 Fixed Q-targets.
DQN 两大利器

简单来说, DQN 有一个记忆库用于学习之前的经历. 在之前的简介影片中提到过, Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率. Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的. 有了这两种提升手段, DQN 才能在一些游戏中超越人类.
什么是 DQN的更多相关文章
- (转)Let’s make a DQN 系列
Let's make a DQN 系列 Let's make a DQN: Theory September 27, 2016DQN This article is part of series Le ...
- DQN算法
DQN算法:基础入门看看 # -*- coding: utf-8 -*- import random import gym import numpy as np from collections im ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- 强化学习(十)Double DQN (DDQN)
在强化学习(九)Deep Q-Learning进阶之Nature DQN中,我们讨论了Nature DQN的算法流程,它通过使用两个相同的神经网络,以解决数据样本和网络训练之前的相关性.但是还是有其他 ...
- 强化学习(十一) Prioritized Replay DQN
在强化学习(十)Double DQN (DDQN)中,我们讲到了DDQN使用两个Q网络,用当前Q网络计算最大Q值对应的动作,用目标Q网络计算这个最大动作对应的目标Q值,进而消除贪婪法带来的偏差.今天我 ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
- 强化学习(四)—— DQN系列(DQN, Nature DQN, DDQN, Dueling DQN等)
1 概述 在之前介绍的几种方法,我们对值函数一直有一个很大的限制,那就是它们需要用表格的形式表示.虽说表格形式对于求解有很大的帮助,但它也有自己的缺点.如果问题的状态和行动的空间非常大,使用表格表示难 ...
- 【转】【强化学习】Deep Q Network(DQN)算法详解
原文地址:https://blog.csdn.net/qq_30615903/article/details/80744083 DQN(Deep Q-Learning)是将深度学习deeplearni ...
- 【转载】 强化学习(十一) Prioritized Replay DQN
原文地址: https://www.cnblogs.com/pinard/p/9797695.html ------------------------------------------------ ...
随机推荐
- UVA_458:The Decoder
Language:C++ 4.8.3 PS:ASCII值减去七 #include<stdio.h> #include<string.h> int main(void) { c ...
- Myeclipse jdk的安装
- Mysql 查询一天中每半小时记录的数量
SELECT HOUR(e.time)as Hour,FLOOR(MINUTE(e.time)/30) as M, COUNT(*) as Count FROM error_log e WHERE e ...
- 基于 springMVC 的 RESTful HTTP API 实践(服务端)
理解 REST REST(Representational State Transfer),中文翻译叫"表述性状态转移".是 Roy Thomas Fielding 在他2000年 ...
- c++中单引号和双引号的区别
在C++中单引号表示字符,双引号表示字符串. 例如 :在定义一个数组的时候string a [5]={"nihao","henhao","good&q ...
- 「BZOJ2510」弱题
「BZOJ2510」弱题 这题的dp式子应该挺好写的,我是不会告诉你我开始写错了的,设f[i][j]为操作前i次,取到j小球的期望个数(第一维这么大显然不可做),那么 f[i][j]=f[i-1][j ...
- [wikipedia] List of free and open-source software packages
List of free and open-source software packages From Wikipedia, the free encyclopedia This articl ...
- hdu 4430 Yukari's Birthday (简单数学 + 二分)
Problem - 4430 题意是,给出蜡烛的数量,要求求出r和k,r是蜡烛的层数,k是每一层蜡烛数目的底数. 开始的时候,没有看清题目,其实中间的那根蜡烛是可放可不放的.假设放置中间的那根蜡烛,就 ...
- Laravel 5.5 将会要求 PHP 7.0+
Laravel 5.5 都要用 PHP7 了呢!你还在用 PHP 5 吗? Laravel 一直是一个精 (sheng) 进 (ji) 不 (hen) 休 (kuai) 的框架.就在前几天,下图这位 ...
- js读取cookie 根据cookie名称获取值、赋值
借鉴:原作者https://blog.csdn.net/zouxuhang/article/details/80548417 //方法1 //存在问题:如果cookie中存在 aaaname= ...