基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume、log4j、Kafka进行规范的日志采集。

Flume 基本概念
Flume是一个完善、强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说明不再详细赘述。
Flume包含Source、Channel、Sink三个最基本的概念:

Source——日志来源,其中包括:Avro Source、Thrift Source、Exec Source、JMS Source、Spooling Directory Source、Kafka Source、NetCat Source、Sequence Generator Source、Syslog Source、HTTP Source、Stress Source、Legacy Source、Custom Source、Scribe Source以及Twitter 1% firehose Source。
Channel——日志管道,所有从Source过来的日志数据都会以队列的形式存放在里面,它包括:Memory Channel、JDBC Channel、Kafka Channel、File Channel、Spillable Memory Channel、Pseudo Transaction Channel、Custom Channel。
Sink——日志出口,日志将通过Sink向外发射,它包括:HDFS Sink、Hive Sink、Logger Sink、Avro Sink、Thrift Sink、IRC Sink、File Roll Sink、Null Sink、HBase Sink、Async HBase Sink、Morphline Solr Sink、Elastic Search Sink、Kite Dataset Sink、Kafka Sink、Custom Sink。
基于Flume的日志采集是灵活的,我们可以看到既有Avro Sink也有Avro Source,既有Thrift Sink也有Thrift Source,这意味着我们可以将多个管道处理串联起来,如下图所示:

串联的意义在于,我们可以将多个管道合并到一个管道中最终输出到同一个Sink中去,如下图:
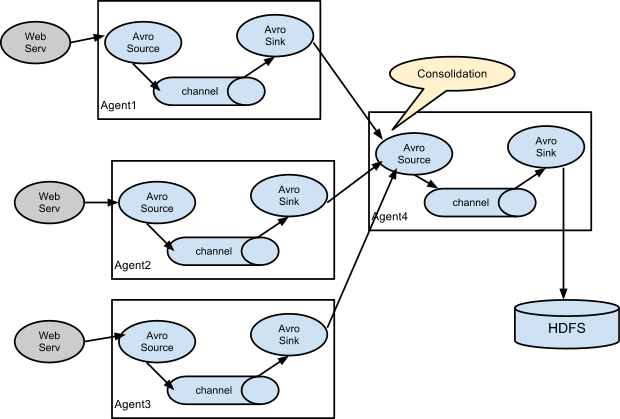
上面讲述了Source和Sink的作用,而Channel的作用在于处理不同的Sink,假设我们一个Source要对应多个Sink,则只需要为一个Source建立多个Channel即可,如下所示:
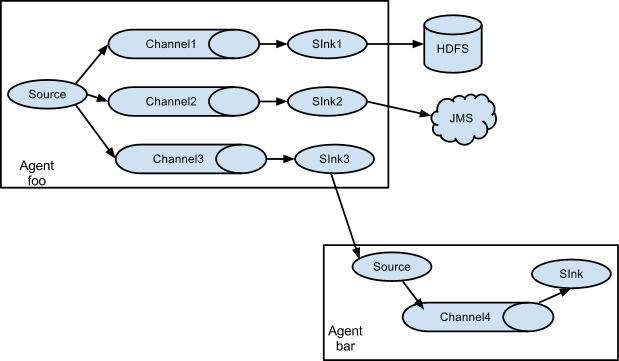
一个Source如果想要输出到多个Sink中去,就需要建立多个Channel进行介入并最终输出,通过上面这几张图,我们可以很好的理解Flume的运行机制,我们在这里也就点到为止,详细的配置可以在官网或者在网上搜索到、查看到。
一般情况下,我们使用 Exec Source对log文件进行监控,这样做确实是比较简单,但是并不方便,我们需要在每一台要监控的服务器上部署Flume,对运维来讲万一目标日志文件发生IO异常(例如格式改变、文件名改变、文件被锁),也是很痛苦的,因此我们最好能让日志直接通过Socket发送出去,而不是存放在本地,这样一来,不仅降低了目标服务器的磁盘占用,还能够有效的防止文件IO异常,而Kafka就是一个比较好的解决方案,具体的架构如下图所示:
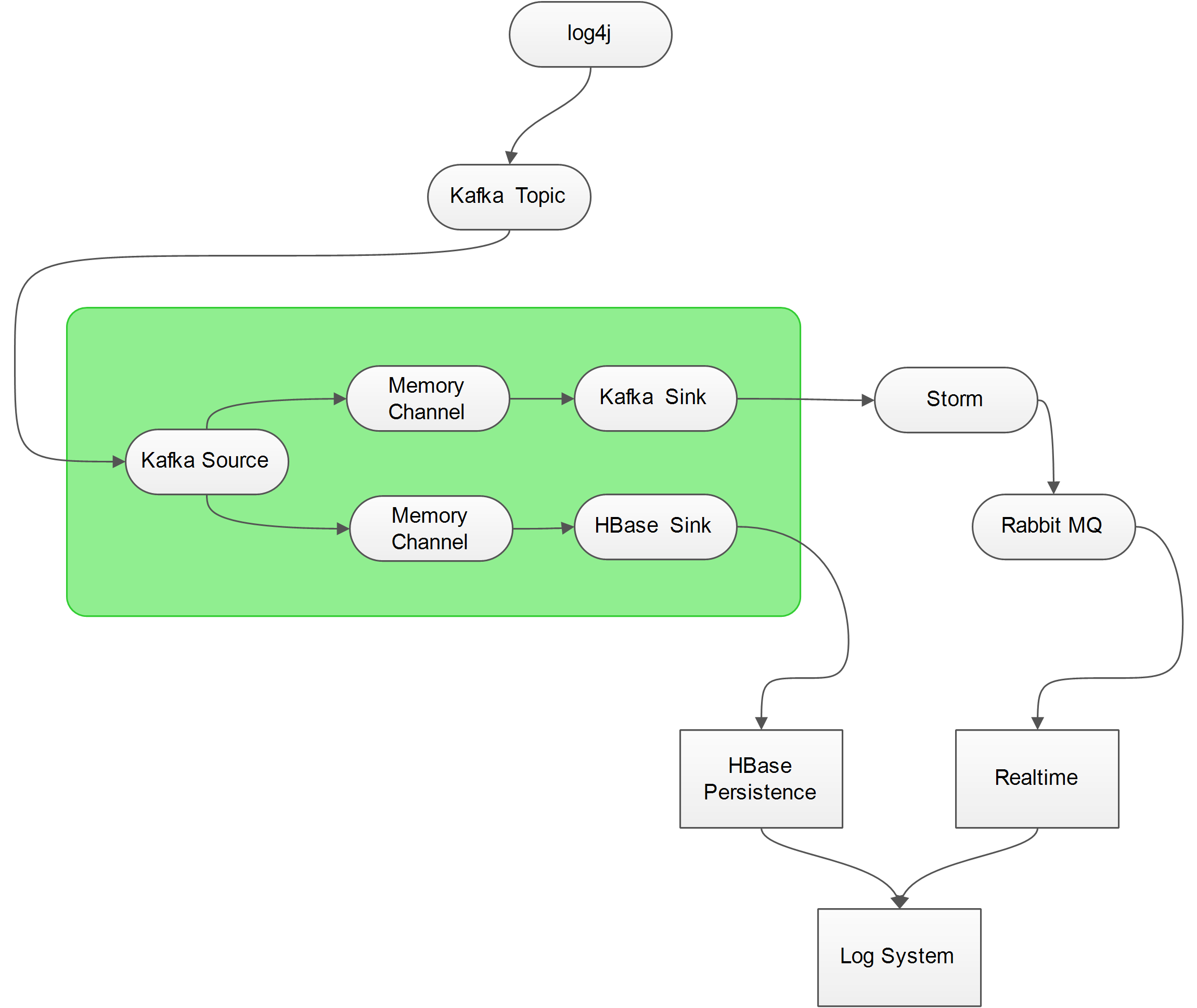
由上图可以看到,日志最终流向了两个地方:HBase Persistence和Realtime Processor,而至于为什么不用Kafka直接与Storm进行通信的原因是为了将Sotrm逻辑和日志源通过Flume进行隔离,在Storm中对日志进行简单的分析后,将结果扔进 Rabbit MQ 中供 WEB APP消费。
HBase Persistence就是将原始的日志记录在HBase中以便回档查询,而Realtime Processor则包含了实时的日志统计以及错误异常邮件提醒等功能。
为了能够准确的捕获到异常数据,我们还需要对程序进行一些规范化的改造,例如提供统一的异常处理句柄等等。
日志输出格式
既然打算要对日志进行统一处理,一个统一、规范的日志格式就是非常重要的,而我们以往使用的 PatternLayout 对于最终字段的切分非常的不方便,如下所示:
2016-05-08 19:32:55,572 [INFO ] [main] - [com.banksteel.log.demo.log4j.Demo.main(Demo.java:13)] 输出信息……
2016-05-08 19:32:55,766 [DEBUG] [main] - [com.banksteel.log.demo.log4j.Demo.main(Demo.java:15)] 调试信息……
2016-05-08 19:32:55,775 [WARN ] [main] - [com.banksteel.log.demo.log4j.Demo.main(Demo.java:16)] 警告信息……
2016-05-08 19:32:55,783 [ERROR] [main] - [com.banksteel.log.demo.log4j.Demo.main(Demo.java:20)] 处理业务逻辑的时候发生一个错误……
java.lang.Exception: 错误消息啊
at com.banksteel.log.demo.log4j.Demo.main(Demo.java:18)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:144)
如何去解析这个日志,是个非常头疼的地方,万一某个系统的开发人员输出的日志不符合既定规范的 PatternLayout 就会引发异常。
为了能够一劳永逸的解决格式问题,我们采用 JsonLayout 就能很好的规范日志输出,例如LOG4J 2.X 版本中提供的 JsonLayout 输出的格式如下所示:
{
"timeMillis" : 1462712870612,
"thread" : "main",
"level" : "FATAL",
"loggerName" : "com.banksteel.log.demo.log4j2.Demo",
"message" : "发生了一个可能会影响程序继续运行下去的异常!",
"thrown" : {
"commonElementCount" : 0,
"localizedMessage" : "错误消息啊",
"message" : "错误消息啊",
"name" : "java.lang.Exception",
"extendedStackTrace" : [ {
"class" : "com.banksteel.log.demo.log4j2.Demo",
"method" : "main",
"file" : "Demo.java",
"line" : 20,
"exact" : true,
"location" : "classes/",
"version" : "?"
}, {
"class" : "sun.reflect.NativeMethodAccessorImpl",
"method" : "invoke0",
"file" : "NativeMethodAccessorImpl.java",
"line" : -2,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "sun.reflect.NativeMethodAccessorImpl",
"method" : "invoke",
"file" : "NativeMethodAccessorImpl.java",
"line" : 57,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "sun.reflect.DelegatingMethodAccessorImpl",
"method" : "invoke",
"file" : "DelegatingMethodAccessorImpl.java",
"line" : 43,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "java.lang.reflect.Method",
"method" : "invoke",
"file" : "Method.java",
"line" : 606,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "com.intellij.rt.execution.application.AppMain",
"method" : "main",
"file" : "AppMain.java",
"line" : 144,
"exact" : true,
"location" : "idea_rt.jar",
"version" : "?"
} ]
},
"endOfBatch" : false,
"loggerFqcn" : "org.apache.logging.log4j.spi.AbstractLogger",
"source" : {
"class" : "com.banksteel.log.demo.log4j2.Demo",
"method" : "main",
"file" : "Demo.java",
"line" : 23
}
}
我们看到,这种格式,无论用什么语言都能轻松解析了。
日志框架的Kafka集成
我们这里只用log4j 1.x 和 log4j 2.x 进行示例。
log4j 1.x 与 Kafka 集成
首先POM.xml的内容如下:
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.8.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.8.2.1</version>
</dependency>
</dependencies>
注意,我们这里使用的Kafka版本号是0.8.2.1,但是对应0.9.0.1是可以使用的并且0.9.0.1也只能用0.8.2.1才不会发生异常(具体异常可以自己尝试一下)。
而log4j 1.x 本身是没有 JsonLayout 可用的,因此我们需要自己实现一个类,如下所示:
package com.banksteel.log.demo.log4j; import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.log4j.Layout;
import org.apache.log4j.spi.LoggingEvent; import java.util.LinkedHashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map; /**
* 扩展Log4j 1.x,使其支持 JsonLayout,与 log4j2.x 一样是基于Jackson进行解析,其格式也是完全参考 Log4J 2.x实现的。
*
* @author 热血BUG男
* @version 1.0.0
* @since Created by gebug on 2016/5/8.
*/
public class JsonLayout extends Layout { private final ObjectMapper mapper = new ObjectMapper(); public String format(LoggingEvent loggingEvent) {
String json;
Map<String, Object> map = new LinkedHashMap<String, Object>(0);
Map<String, Object> source = new LinkedHashMap<String, Object>(0);
source.put("method", loggingEvent.getLocationInformation().getMethodName());
source.put("class", loggingEvent.getLocationInformation().getClassName());
source.put("file", loggingEvent.getLocationInformation().getFileName());
source.put("line", safeParse(loggingEvent.getLocationInformation().getLineNumber())); map.put("timeMillis", loggingEvent.getTimeStamp());
map.put("thread", loggingEvent.getThreadName());
map.put("level", loggingEvent.getLevel().toString());
map.put("loggerName", loggingEvent.getLocationInformation().getClassName());
map.put("source", source);
map.put("endOfBatch", false);
map.put("loggerFqcn", loggingEvent.getFQNOfLoggerClass()); map.put("message", safeToString(loggingEvent.getMessage()));
map.put("thrown", formatThrowable(loggingEvent));
try {
json = mapper.writeValueAsString(map);
} catch (JsonProcessingException e) {
return e.getMessage();
}
return json;
} private List<Map<String, Object>> formatThrowable(LoggingEvent le) {
if (le.getThrowableInformation() == null ||
le.getThrowableInformation().getThrowable() == null)
return null;
List<Map<String, Object>> traces = new LinkedList<Map<String, Object>>();
Map<String, Object> throwableMap = new LinkedHashMap<String, Object>(0);
StackTraceElement[] stackTraceElements = le.getThrowableInformation().getThrowable().getStackTrace();
for (StackTraceElement stackTraceElement : stackTraceElements) {
throwableMap.put("class", stackTraceElement.getClassName());
throwableMap.put("file", stackTraceElement.getFileName());
throwableMap.put("line", stackTraceElement.getLineNumber());
throwableMap.put("method", stackTraceElement.getMethodName());
throwableMap.put("location", "?");
throwableMap.put("version", "?");
traces.add(throwableMap);
}
return traces;
} private static String safeToString(Object obj) {
if (obj == null) return null;
try {
return obj.toString();
} catch (Throwable t) {
return "Error getting message: " + t.getMessage();
}
} private static Integer safeParse(String obj) {
try {
return Integer.parseInt(obj.toString());
} catch (NumberFormatException t) {
return null;
}
} public boolean ignoresThrowable() {
return false;
} public void activateOptions() { }
}
其实并不复杂,注意其中有一些获取不到的信息,用?代替了,保留字段的目的在于与log4j 2.x 的日志格式完全一致,配置log4j.properties如下对接 Kafka:
log4j.rootLogger=INFO,console
log4j.logger.com.banksteel.log.demo.log4j=DEBUG,kafka
log4j.appender.kafka=kafka.producer.KafkaLog4jAppender
log4j.appender.kafka.topic=server_log
log4j.appender.kafka.brokerList=Kafka-01:9092,Kafka-02:9092,Kafka-03:9092
log4j.appender.kafka.compressionType=none
log4j.appender.kafka.syncSend=true
log4j.appender.kafka.layout=com.banksteel.log.demo.log4j.JsonLayout
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%t] - [%l] %m%n
通过打印日志我们可以看到其输出的最终格式如下:
{
"timeMillis": 1462713132695,
"thread": "main",
"level": "ERROR",
"loggerName": "com.banksteel.log.demo.log4j.Demo",
"source": {
"method": "main",
"class": "com.banksteel.log.demo.log4j.Demo",
"file": "Demo.java",
"line": 20
},
"endOfBatch": false,
"loggerFqcn": "org.slf4j.impl.Log4jLoggerAdapter",
"message": "处理业务逻辑的时候发生一个错误……",
"thrown": [
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
},
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
},
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
},
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
},
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
},
{
"class": "com.intellij.rt.execution.application.AppMain",
"file": "AppMain.java",
"line": 144,
"method": "main",
"location": "?",
"version": "?"
}
]
}
测试类:
package com.banksteel.log.demo.log4j; import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* @author 热血BUG男
* @version 1.0.0
* @since Created by gebug on 2016/5/8.
*/
public class Demo {
private static final Logger logger = LoggerFactory.getLogger(Demo.class); public static void main(String[] args) {
logger.info("输出信息……");
logger.trace("随意打印……");
logger.debug("调试信息……");
logger.warn("警告信息……");
try {
throw new Exception("错误消息啊");
} catch (Exception e) {
logger.error("处理业务逻辑的时候发生一个错误……", e);
}
}
}
log4j 2.x 与 Kafka 集成
log4j 2.x 天生支持 JsonLayout,并且与 Kafka 集成方便,我们只需要按部就班的配置一下就好了,POM.xml如下:
<dependencies>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.1</version>
</dependency>
</dependencies>
log4j2.xml配置文件如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Log4j2 的配置文件 -->
<Configuration status="DEBUG" strict="true" name="LOG4J2_DEMO" packages="com.banksteel.log.demo.log4j2">
<properties>
<property name="logPath">log</property>
</properties> <Appenders>
<!--配置控制台输出样式-->
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%highlight{%d{yyyy-MM-dd HH:mm:ss} %d{UNIX_MILLIS} [%t] %-5p %C{1.}:%L - %msg%n}"/>
</Console>
<!-- 配置Kafka日志主动采集,Storm会将日志解析成字段存放在HBase中。 -->
<Kafka name="Kafka" topic="server_log">
<!--使用JSON传输日志文件-->
<JsonLayout complete="true" locationInfo="true"/>
<!--Kafka集群配置,需要在本机配置Hosts文件,或者通过Nginx配置-->
<Property name="bootstrap.servers">Kafka-01:9092,Kafka-02:9092,Kafka-03:9092</Property>
</Kafka>
</Appenders>
<Loggers>
<Root level="DEBUG">
<!--启用控制台输出日志-->
<AppenderRef ref="Console"/>
<!--启用Kafka采集日志-->
<AppenderRef ref="Kafka"/>
</Root>
</Loggers>
</Configuration>
这样就Okay了,我们可以在Kafka中看到完整的输出:
{
"timeMillis" : 1462712870591,
"thread" : "main",
"level" : "ERROR",
"loggerName" : "com.banksteel.log.demo.log4j2.Demo",
"message" : "处理业务逻辑的时候发生一个错误……",
"thrown" : {
"commonElementCount" : 0,
"localizedMessage" : "错误消息啊",
"message" : "错误消息啊",
"name" : "java.lang.Exception",
"extendedStackTrace" : [ {
"class" : "com.banksteel.log.demo.log4j2.Demo",
"method" : "main",
"file" : "Demo.java",
"line" : 20,
"exact" : true,
"location" : "classes/",
"version" : "?"
}, {
"class" : "sun.reflect.NativeMethodAccessorImpl",
"method" : "invoke0",
"file" : "NativeMethodAccessorImpl.java",
"line" : -2,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "sun.reflect.NativeMethodAccessorImpl",
"method" : "invoke",
"file" : "NativeMethodAccessorImpl.java",
"line" : 57,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "sun.reflect.DelegatingMethodAccessorImpl",
"method" : "invoke",
"file" : "DelegatingMethodAccessorImpl.java",
"line" : 43,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "java.lang.reflect.Method",
"method" : "invoke",
"file" : "Method.java",
"line" : 606,
"exact" : false,
"location" : "?",
"version" : "1.7.0_80"
}, {
"class" : "com.intellij.rt.execution.application.AppMain",
"method" : "main",
"file" : "AppMain.java",
"line" : 144,
"exact" : true,
"location" : "idea_rt.jar",
"version" : "?"
} ]
},
"endOfBatch" : false,
"loggerFqcn" : "org.apache.logging.log4j.spi.AbstractLogger",
"source" : {
"class" : "com.banksteel.log.demo.log4j2.Demo",
"method" : "main",
"file" : "Demo.java",
"line" : 22
}
}
为了减少日志对空间的占用,我们通常还会设置JSONLayout的compact属性为true,这样在kafka中获得的日志将会排除掉空格和换行符。
最后
由于在实际开发中,我们会引入多个第三方依赖,这些依赖往往也会依赖无数的log日志框架,为了保证测试通过,请认清本文例子中的包名以及版本号,log4j 1.x 的 Json 输出是为了完全模拟 2.x 的字段,因此部分字段用?代替,如果想要完美,请自行解决。
随便解释一下日志级别,以便建立规范:
log.error 错误信息,通常写在 catch 中,可以使用 log.error("发生了一个错误",e) 来记录详细的异常堆栈
log.fatal 严重错误,该级别的错误用来记录会导致程序异常退出的错误日志。
log.warn 警告
log.info 信息
log.trace 简单输出文字
log.debug 调试信息
基于Flume+LOG4J+Kafka的日志采集架构方案的更多相关文章
- Flume+LOG4J+Kafka
基于Flume+LOG4J+Kafka的日志采集架构方案 本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具, ...
- kafka和flume进行整合的日志采集的confi文件编写
配置flume.conf 为我们的source channel sink起名 a1.sources = r1 a1.channels = c1 a1.sinks = k1 指定我们的source收集到 ...
- Spring cloud微服务安全实战-7-10ELK日志采集架构优化
ELK搭建起来.采集日志,展示.但是这个架构还有一些问题. 可用性的问题,springboot的应用,随着业务的增长会越来越多.logstash压力就会越来越大.大到一定的程度可能就会吧logstas ...
- 基于logstash+elasticsearch+kibana的日志收集分析方案(Windows)
一 方案背景 通常,日志被分散的储存不同的设备上.如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志.这样是不是感觉很繁琐和效率低下.开源实时日志分析ELK平台能够完美的 ...
- Openresty+Lua+Kafka实现日志实时采集
简介 在很多数据采集场景下,Flume作为一个高性能采集日志的工具,相信大家都知道它.许多人想起Flume这个组件能联想到的大多数都是Flume跟Kafka相结合进行日志的采集,这种方案有很多他的优点 ...
- flink---实时项目--day02-----1. 解析参数工具类 2. Flink工具类封装 3. 日志采集架构图 4. 测流输出 5. 将kafka中数据写入HDFS 6 KafkaProducer的使用 7 练习
1. 解析参数工具类(ParameterTool) 该类提供了从不同数据源读取和解析程序参数的简单实用方法,其解析args时,只能支持单只参数. 用来解析main方法传入参数的工具类 public c ...
- MySQL金融应用场景下跨数据中心的MGR架构方案(2)
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 如何在多个数据中心部署多套MGR集群,并实现故障快速切换. 上篇文章介绍了如何在多数据中心部署多套MGR集群,并构建集群间 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- setTimeout与取号机之间的关系
说到setTimeout写过javascript的伙伴们一定不会陌生,去银行办过存取款业务的伙伴一定对取号机不会陌生.今天群里有个好伙伴在问setTimeout的问题,大伙你一言我一语,讲了很多,可是 ...
- 韩国"被申遗" (转自果壳)
"被申遗"不是指"没申遗",而是全都经过了中国人重新包装. 近日,有报道称韩国计划将火炕申报世界遗产,联系近年来韩国多起"申遗事件",国内网 ...
- 使用PL/SQL工具比对表结构,同步表结构
需求:Oracle数据库,B库和C库,某些表的表结构不一致,现在要求以C库为标准,同步更新B库表结构PL/SQL 连接到C库, Tools --> Compare User Objects .. ...
- 【Python实战】Pandas:让你像写SQL一样做数据分析(一)
1. 引言 Pandas是一个开源的Python数据分析库.Pandas把结构化数据分为了三类: Series,1维序列,可视作为没有column名的.只有一个column的DataFrame: Da ...
- ASP.NET Core中的ActionFilter与DI
一.简介 前几篇文章都是讲ASP.NET Core MVC中的依赖注入(DI)与扩展点的,也许大家都发现在ASP.NET CORE中所有的组件都是通过依赖注入来扩展的,而且面向一组功能就会有一组接口或 ...
- CoCreateInstance调用返回代码0x80040154的一种解决方法
引言 前面的一篇博文中总结了开发Windows Thumbnail Handler的一些经验.在公司实际项目中,需要同时针对图片和视频实现缩略图.同时还要在图片和视频文件的顶部加上LOGO.像如下这样 ...
- 转: IntelliJ IDEA 2016.2.2注册码
43B4A73YYJ-eyJsaWNlbnNlSWQiOiI0M0I0QTczWVlKIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiI ...
- ASP.NET MVC HtmlHelper之Html.ActionLink
前言 ActionLink用于生成超链接,方法用于指向Controller的Action. 扩展方法与参数说明 ActionLink扩展方法如下: public static MvcHtmlStrin ...
- EF Core1.0 CodeFirst为Modell设置默认值!
当我们使用CodeFirst时,有时候需要设置默认值! 如下 ; public string AdminName {get; set;} = "admin"; public boo ...
- java反编译获取源码
最近在研究反射,想做一个东西,把运行的java程序饭编译(Decompile)成.java文件.现思路如下: 1.写出程序反编译一个类 2.将所有类反编译 3.java代码注入一个正在运行的java程 ...