python提取图片内容并转换成对应表格的markdown代码
本节我们将介绍使用python识别一张图片中的内容,并试着得到一张表格,当然并不是类似于Excel的表格,而是该表格的markdown代码。
注:原创内容,转载请标明出处!
相关工具的安装
本次实验环境:win10,Pycharm2019.3。
安装相关库既可以使用命令行,也可以使用Pycharm自带的工具。
打开cmd命令行或者powershell。
首先安装PIL:
pip install Pillow

这是已经安装好PIL的示意图。
之后,安装pytesseract:
pip install pytesseract

这是已经安装好pytesseract的示意图。
接下来,安装Tesseract-OCR,注意对应系统。
环境配置,输入
tesseract
tesseract -v
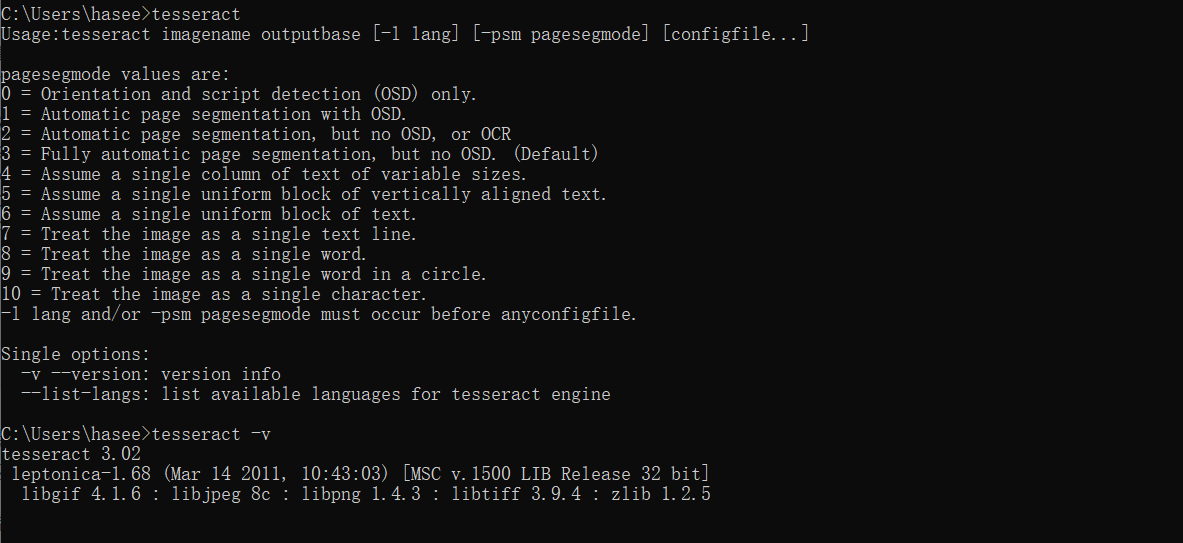
如果正常输出,表示配置成功了(我在实际操作时,安装完成后自动配置了系统变量),如果没有,找到之前安装的路径:
例如:
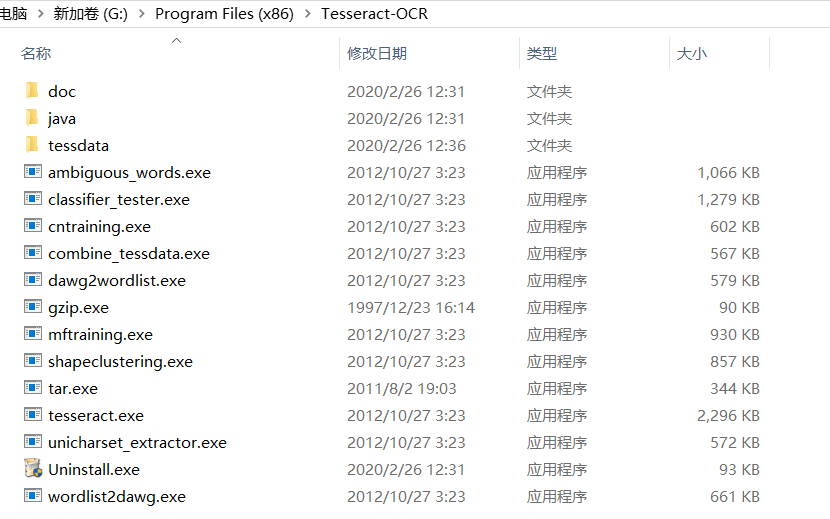
G:\Program Files (x86)\Tesseract-OCR
将该路径添加到系统变量中
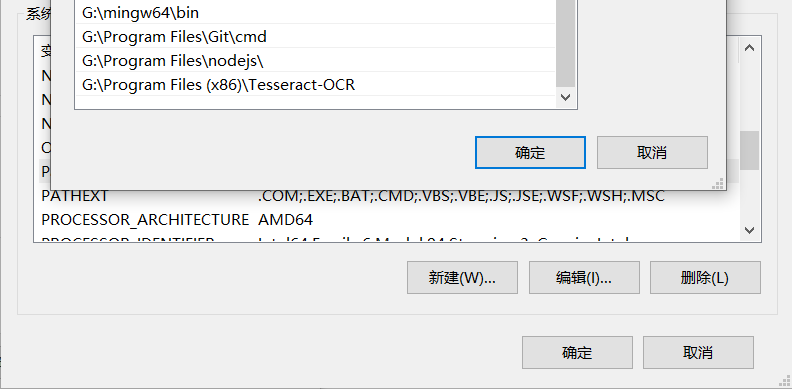
如果你想做英文之外的识别,Tesseract-OCR是没有带其他语言包的,你可以去下载其他语言包。
这里我添加了简体中文的语言包,但是使用的是自带的英文语言包。
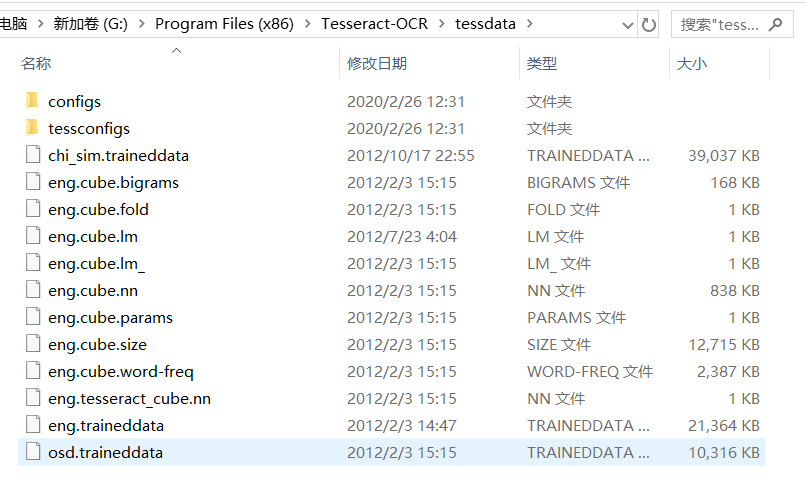
同时,我们还需要一项配置,找到python安装路径下的pytesseract.py,我这里的路径是
G:\Python37\Lib\site-packages\pytesseract
打开该路径下的pytesseract.py文件。
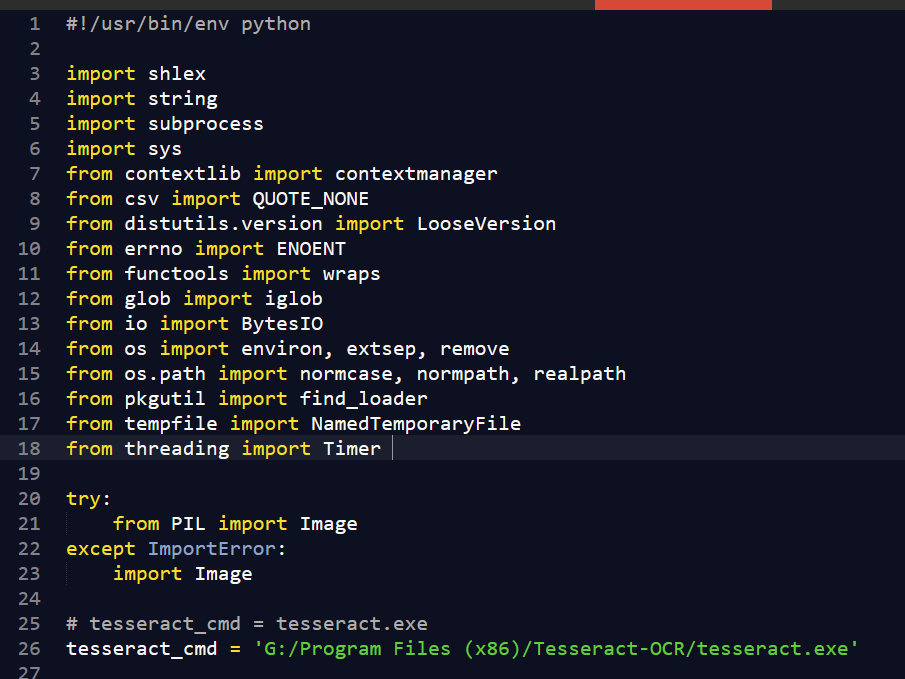
将其中的
tesseract_cmd = tesseract.exe
替换为你之前安装Tesseract-OCR的路径。
tesseract_cmd = 'G:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
简单测试
这是一张图:
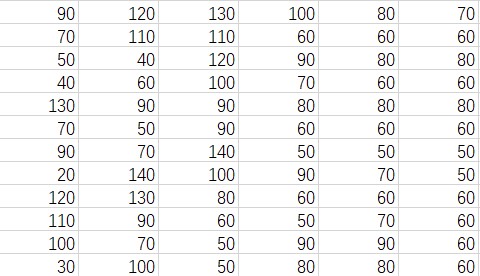
先简单演示一下:
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
# 注意图片路径和名称
path = "3.jpg"
# lang参数指定了语言包,你可以下载相应的语言包,这里使用自带的英文包
content = pytesseract.image_to_string(Image.open(path), lang="eng")
print(content)
由于数据有些多,我只列出一部分。
90
70
50
40
130
70
90
20
120
110
100
30
...
70
60
80
60
80
60
50
50
60
60
60
60
这里呢,我们的工作就完成了大部分了,接下来我们试着将它转换一个对应表格的markdown代码。
转换
我们得到的结果是一个字符串,离我们实际的表格内容还有一段距离,也不难,做些数据处理就可以了。
markdown表格的语法:
| 左对齐 | 居中对齐 | 右对齐 |
| :-----| :----: | ----: |
| 内容 | 内容 | 内容 |
| 内容 | 内容 | 内容 |
这里直接上程序了:
# -*- coding: utf-8 -*-
from PIL import Image
import pytesseract
path = "3.jpg"
text = pytesseract.image_to_string(Image.open(path), lang="eng")
text_list = text.split()
rows = 12
lists = 6
md_text = []
list_name = ["语文", "数学", "英语", "物理", "化学", "生物"]
md_text.append(["|"])
for name in list_name:
md_text[0].append(str(name) + "|")
md_text[0] = "".join(md_text[0])
direction = ["中", "中", "中", "中", "中", "中"]
md_text.append(["|"])
for d in direction:
if str(d) == "左":
md_text[1].append(":----|")
if str(d) == "中":
md_text[1].append(":----:|")
if str(d) == "右":
md_text[1].append("----:|")
md_text[1] = "".join(md_text[1])
for r in range(rows):
res = "|"
for l in range(lists):
res += (text_list[r + l * rows] + "|")
md_text.append(res)
file = open("3.txt", "w")
for m in md_text:
file.write(m + "\n")
file.close()
print(md_text)
结果:
['|语文|数学|英语|物理|化学|生物|', '|:----:|:----:|:----:|:----:|:----:|:----:|', '|90|120|130|100|80|70|', '|70|110|110|60|60|60|', '|50|40|120|90|80|80|', '|40|60|100|70|60|60|', '|130|90|90|80|80|80|', '|70|50|90|60|60|60|', '|90|70|140|50|50|50|', '|20|140|100|90|70|50|', '|120|130|80|60|60|60|', '|110|90|60|50|70|60|', '|100|70|50|90|90|60|', '|30|100|50|80|80|60|']
看看文件内容。
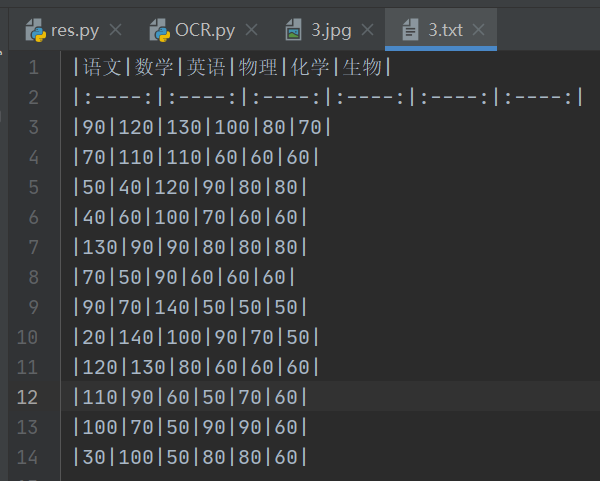
看看渲染结果:
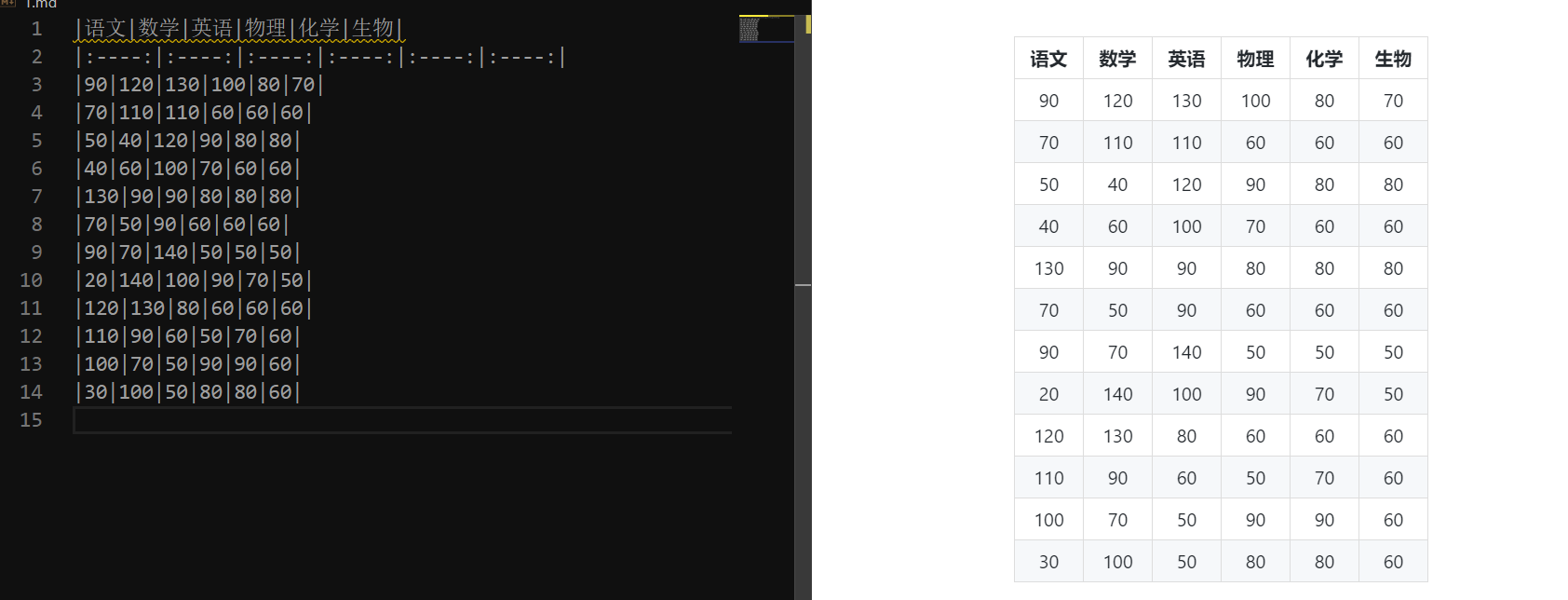
结果还不错,当然我们并没有训练样本,所以对于稍微复杂一点的图片,可能识别结果就不好了。
之后我以这个为基础,写一个带GUI的程序,界面如下:
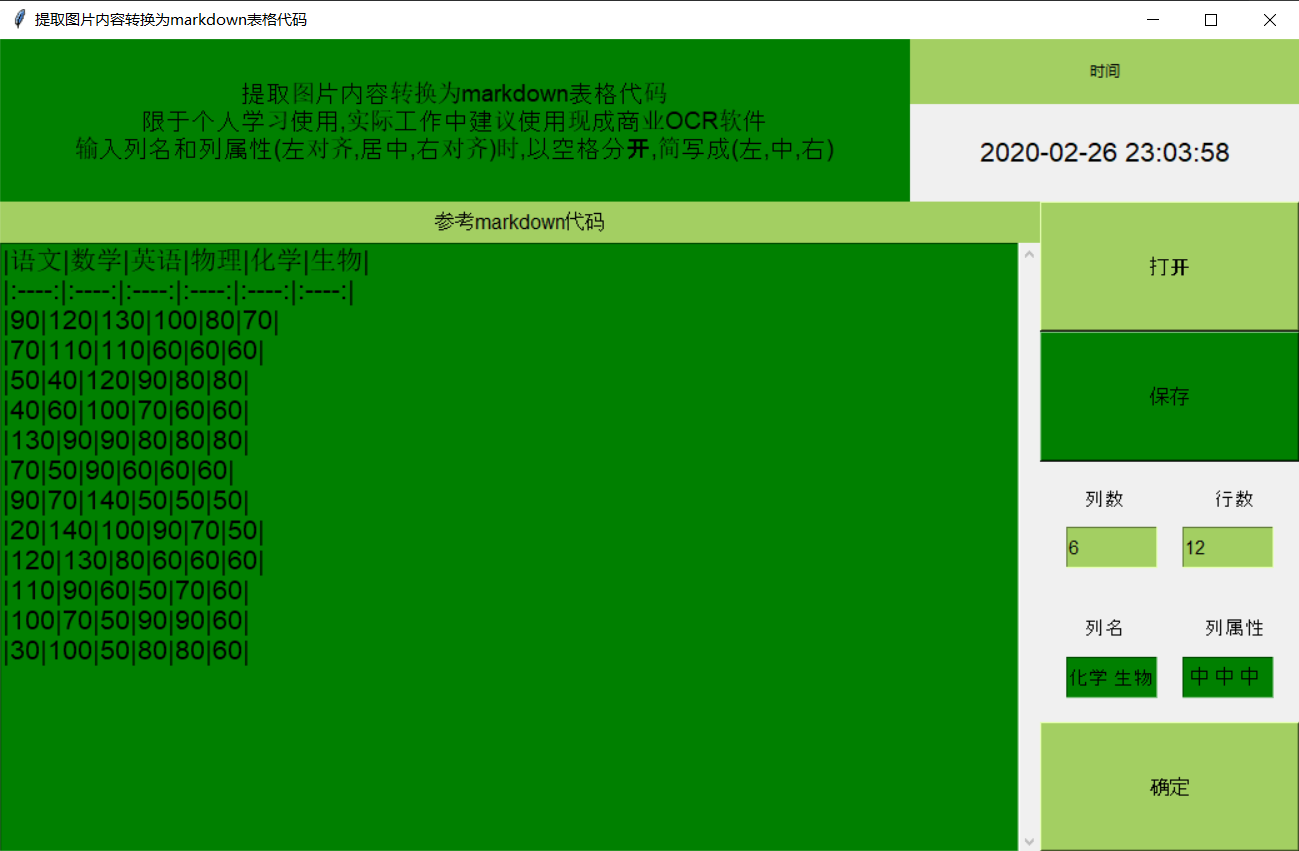
完整带GUI程序的github仓库地址。
python提取图片内容并转换成对应表格的markdown代码的更多相关文章
- 如何将WORD表格转换成EXCEL表格
WORD和EXCEL都可以制作表格,但WORD表格与EXCEL表格之间有着很明显的差距,所以在办公中经常会需要将WORD转换成EXCEL,今天小编就教大家一招将WORD表格转换成EXCEL表格. 操作 ...
- 用Python将word文件转换成html(转)
用Python将word文件转换成html 序 最近公司一个客户大大购买了一堆医疗健康方面的科普文章,希望能放到我们正在开发的健康档案管理软件上.客户大大说,要智能推送!要掌握节奏!要深度学习!要 ...
- 怎样将PDF文件转换成Excel表格
PDF文件怎样转换成Excel表格呢?因为很多的数据信息现在都是通过PDF文件进行传输的,所以很多时候,信息的接受者都需要将这些PDF文件所传输的数据信息转换成Excel表格来进行整理,但是我们应该怎 ...
- PDF文件转换成Excel表格的操作技巧
我们都知道2007以上版本的Office文档,是可以直接将文档转存为PDF格式文档的.那么反过来,PDF文档可以转换成其他格式的文档吗?这是大家都比较好奇的话题.如果可以以其他格式进行保存,就可以极大 ...
- 使用python将ppm格式转换成jpg【转】
转自:http://blog.csdn.net/hitbeauty/article/details/48465017 最近有个很火的文章,叫 有没有一段代码,让你觉得人类的智慧也可以璀璨无比? 自己试 ...
- python入门:UTF-8转换成GBK编码
#!/usr/bin/env python # -*- coding:utf-8 -*- #UTF-8转换成GBK编码 #temp(临时雇员,译音:泰坡) #decode(编码,译音:迪口德) #en ...
- ExcelToHtmlTable转换算法:将Excel转换成Html表格并展示(项目源码+详细注释+项目截图)
功能概述 Excel2HtmlTable的主要功能就是把Excel的内容以表格的方式,展现在页面中.Excel的多个Sheet对应页面的多个Tab选项卡.转换算法的难点在于,如何处理行列合并,将Exc ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- SnowNLP:•中文分词•词性标准•提取文本摘要,•提取文本关键词,•转换成拼音•繁体转简体的 处理中文文本的Python3 类库
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和Te ...
随机推荐
- git使用的常见命令汇总
git的简单介绍 git是分布式版本控制工具 git 的基本操作指令 git init 初始化git仓库 git add 文件名 git add . 把文件 添加到 git 暂存区中 git stat ...
- WEB Node-JS 服务器搭建
一.创建express 1.创建一个单独文件 2.打开命令面板,进入该文件 3.npm config set registry = https://registry.npm.taobao.org(设置 ...
- flask插件全家桶集成学习---持续更新ing
不得不说flask的设计要比django要小巧精妙的多了,没有那么臃肿,只保留核心功能,其他的都需要自己引入,即各种各样的插件来满足我们的需求,我这里记录一下自己学习项目中用的插件使用方法和一些技巧总 ...
- DISCUZ 如何为主题帖列表页添加头像,显示发帖者头像
只显示名字的代码 ```php<em style=" font-size:14px;"> <!--{if $thread['authorid'] &&am ...
- Arduino系列之pwm控制LED灯(呼吸灯)
下面我将写出最简单控制呼吸灯的方法 void setup() // { pinMode(12,OUTPUT); ...
- 使用nginx构建一个具备缓存功能的反向代理服务器
上游服务一般不提供公网访问. upstream模块,名字叫local 这个时候访问,都是由反向代理服务处理返回的. 有了反向代理服务后,拿变量和值会出错,tcp是有对端地址的,反向代理与客户端是一个t ...
- qt QSplitter分割窗口
#include <QApplication> #include <QFont> #include <QTextEdit> #include <QSplitt ...
- python笔记18(复习)
今日内容 复习 内容详细 1.Python入门 1.1 环境的搭建 mac系统上搭建python环境. 环境变量的作用:方便在命令行(终端)执行可执行程序,将可执行程序所在的目录添加到环境变量,那么以 ...
- caffe 指定GPU
caffe默认使用编号为0的gpu, 若它的内存不够或正忙, 即使有其余gpu空闲, caffe也不会使用. 要用哪个gpu, 就要明确指定哪个. 不指定则使用默认. 命令行 ./build/tool ...
- Codeforces 1060C Maximum Subrectangle(子矩阵+预处理)
题意:给出数组a,b,组成矩阵c,其中$c_{ij}=a_i*b_j$,找出最的大子矩阵,使得矩阵元素和<=x,求这个矩阵的size n,m<=2000 思路:对于子矩阵(l1...r1) ...