Hadoop架构及集群
Hadoop是一个由Apache基金会所开发的分布式基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算,特点是:高可靠性,高扩展性,高效性,高容错性。
Hadoop与Google三篇论文
- Google-File-System :http://blog.bizcloudsoft.com/wp-content/uploads/Google-File-System%E4%B8%AD%E6%96%87%E7%89%88_1.0.pdf
- Google-Mapreduce:http://blog.bizcloudsoft.com/wp-content/uploads/Google-MapReduce%E4%B8%AD%E6%96%87%E7%89%88_1.0.pdf
- Google-Bigtable:http://blog.bizcloudsoft.com/wp-content/uploads/Google-Bigtable%E4%B8%AD%E6%96%87%E7%89%88_1.0.pd
Hadoop架构
Hadoop1.x与Hadoop2.x的区别:

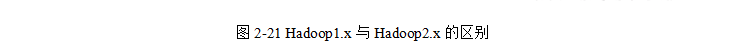
Hadoop整体框架来看:
Hadoop1.0由分布式存储系统HDFS和分布式计算框架MapReduce组成,其中HDFS由一个NameNode和多个DateNode组成,MapReduce由一个JobTracker和多个TaskTracker组成。
1.x与2.x区别
HDFS角度来看:
- Hadoop2.x新增了HDFS HA增加了standbynamenode进行热点备份,解决了1.x的单点故障
- Hadoop2.x新增了HDFS federation,解决了 HDFS的水平扩展能力。

Mapreduce角度来看:
2.x相比与1.x新增了YRAN框架,Mapreduce的运行环境发生了变化
在1.0中:由一个JobTracker和若干个TaskTracker两类服务组成,其中JobTracker负责资源管理和所有作业的控制,TaskTracker负责接收来自JobTracker的命令并执行它。所以MapReduce即是任务调度框架又是计算框架,1.0中会出现JobTracker大包大揽任务过重,而且存在单点故障问题,并且容易出现OOM问题,资源分配不合理等问题。
在2.0中:MASTER端由ResourceManager进行资源管理调度,有ApplicationMaster进行任务管理和任务监控。SLAVE端由NodeManager替代TaskTracker进行具体任务的执行,所以MapReduce2.0只是一个计算框架,具体资源调度全部交给Yarn框架。
2.X和3.X最主要区别:
|
对比 |
2.X特性 |
3.X特性 |
|
License |
Hadoop 2.x - Apache 2.0,开源 |
Hadoop 3.x - Apache 2.0,开源 |
|
支持的最低Java版本 |
java的最低支持版本是java 7 |
java的最低支持版本是java 8 |
|
容错 |
可以通过复制(浪费空间)来处理容错。 |
可以通过Erasure编码处理容错。 |
|
数据平衡 |
对于数据,平衡使用HDFS平衡器。 |
对于数据,平衡使用Intra-data节点平衡器,该平衡器通过HDFS磁盘平衡器CLI调用。 |
|
存储Scheme |
使用3X副本Scheme |
支持HDFS中的擦除编码。 |
|
存储开销 |
HDFS在存储空间中有200%的开销。 |
存储开销仅为50%。 |
|
存储开销示例 |
如果有6个块,那么由于副本方案(Scheme),将有18个块占用空间。 |
如果有6个块,那么将有9个块空间,6块block,3块用于奇偶校验。 |
|
YARN时间线服务 |
使用具有可伸缩性问题的旧时间轴服务。 |
改进时间线服务v2并提高时间线服务的可扩展性和可靠性。 |
|
默认端口范围 |
在Hadoop 2.0中,一些默认端口是Linux临时端口范围。所以在启动时,他们将无法绑定。 |
但是在Hadoop 3.0中,这些端口已经移出了短暂的范围。 |
|
工具 |
使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。 |
可以使用Hive,pig,Tez,Hama,Giraph和其他Hadoop工具。 |
|
兼容的文件系统 |
HDFS(默认FS),FTP文件系统:它将所有数据存储在可远程访问的FTP服务器上。 Amazon S3(简单存储服务)文件系统Windows Azure存储Blob(WASB)文件系统。 |
它支持所有前面以及Microsoft Azure Data Lake文件系统。 |
|
Datanode资源 |
Datanode资源不专用于MapReduce,我们可以将它用于其他应用程序。 |
此处数据节点资源也可用于其他应用程序。 |
|
MR API兼容性 |
与Hadoop 1.x程序兼容的MR API,可在Hadoop 2.X上执行 |
此处,MR API与运行Hadoop 1.x程序兼容,以便在Hadoop 3.X上执行 |
|
支持Microsoft Windows |
它可以部署在Windows上。 |
它也支持Microsoft Windows。 |
|
插槽/容器 |
Hadoop 1适用于插槽的概念,但Hadoop 2.X适用于容器的概念。通过容器,我们可以运行通用任务。 |
它也适用于容器的概念。 |
|
单点故障 |
具有SPOF的功能,因此只要Namenode失败,它就会自动恢复。 |
具有SPOF的功能,因此只要Namenode失败,它就会自动恢复,无需人工干预就可以克服它。 |
|
HDFS联盟 |
在Hadoop 1.0中,只有一个NameNode来管理所有Namespace,但在Hadoop 2.0中,多个NameNode用于多个Namespace。 |
Hadoop 3.x还有多个名称空间用于多个名称空间。 |
|
可扩展性 |
我们可以扩展到每个群集10,000个节点。 |
更好的可扩展性。 我们可以为每个群集扩展超过10,000个节点。 |
|
更快地访问数据 |
由于数据节点缓存,我们可以快速访问数据。 |
这里也通过Datanode缓存我们可以快速访问数据。 |
|
HDFS快照 |
Hadoop 2增加了对快照的支持。 它为用户错误提供灾难恢复和保护。 |
Hadoop 2也支持快照功能。 |
|
平台 |
可以作为各种数据分析的平台,可以运行事件处理,流媒体和实时操作。 |
这里也可以在YARN的顶部运行事件处理,流媒体和实时操作。 |
|
群集资源管理 |
对于群集资源管理,它使用YARN。 它提高了可扩展性,高可用性,多租户。 |
对于集群,资源管理使用具有所有功能的YARN。 |
3.x的新特性参考:https://www.cnblogs.com/smartloli/p/9028267.html ;https://www.cnblogs.com/smartloli/p/8827623.html
HDFS(Hadoop Distributed File System)架构概述
- NameNode(NN):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和所在的DataNode等。
- DataNode(DN):在本地文件系统存储的文件数据,以及块数据的校验和。
- Secondary NameNode(2NN):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
YARN架构概述
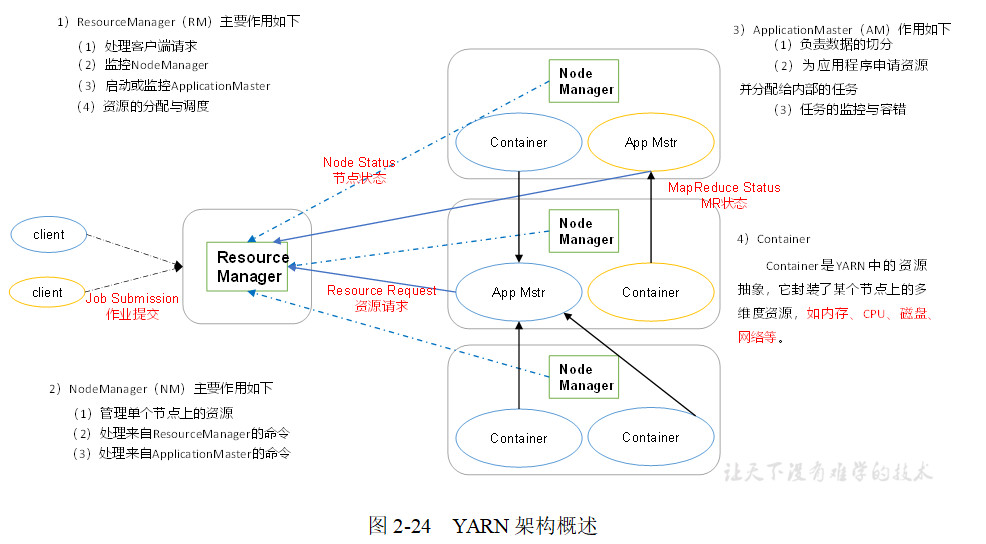
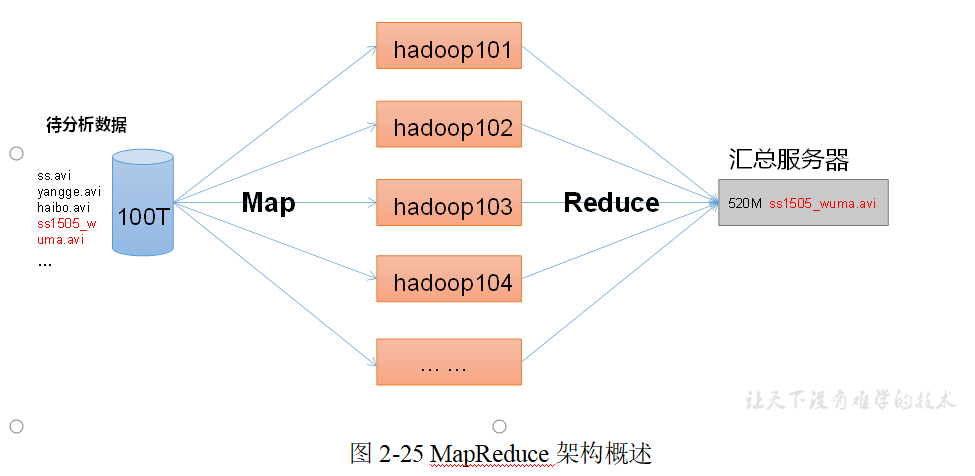
MapReduce将计算过程分为两个阶段:Map和Reduce,如图2-25所示
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
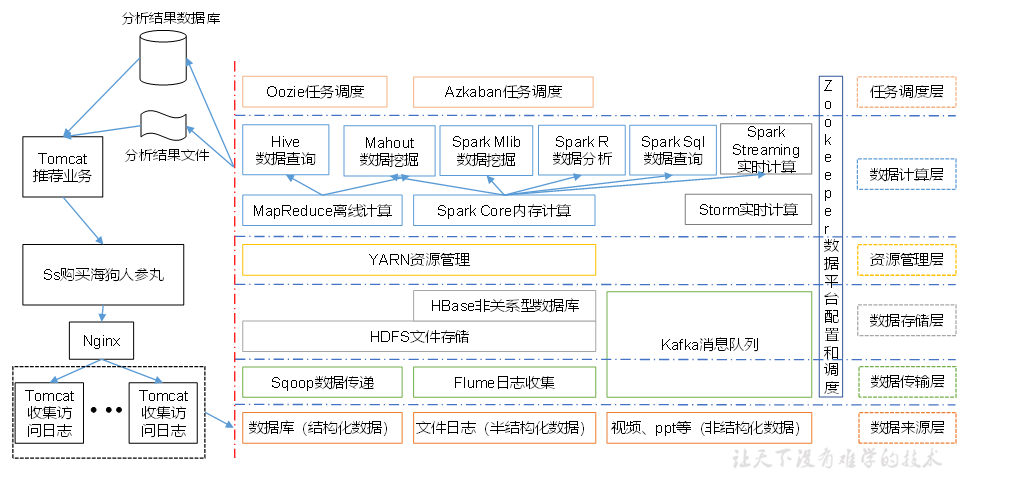
大数据技术生态体系

图中涉及的技术名词解释如下:
1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySql)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm用于“连续计算”,对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
推荐系统框架图
Hadoop集群搭建
虚拟机环境准备 -----/etc/hosts:
- 克隆虚拟机
- 修改克隆虚拟机的静态IP
- 修改主机名
- 关闭防火墙
- 创建用户gll
- 配置gll用户具有root权限
- 在/opt目录下创建文件夹
()在/opt目录下创建module、software文件夹 [atguigu@hadoop101 opt]$ sudo mkdir module
[atguigu@hadoop101 opt]$ sudo mkdir software ()修改module、software文件夹的所有者cd [atguigu@hadoop101 opt]$ sudo chown atguigu:atguigu module/ software/
[atguigu@hadoop101 opt]$ ll 总用量 8
drwxr-xr-x. atguigu atguigu 1月 : module
drwxr-xr-x. atguigu atguigu 1月 : software
安装JDK
卸载现有JDK
()查询是否安装Java软件:
[atguigu@hadoop101 opt]$ rpm -qa | grep java ()如果安装的版本低于1.,卸载该JDK:
[atguigu@hadoop101 opt]$ sudo rpm -e 软件包 ()查看JDK安装路径:
[atguigu@hadoop101 ~]$ which java
在Linux系统下的opt目录中查看软件包是否导入成功
[atguigu@hadoop101 opt]$ cd software/
[atguigu@hadoop101 software]$ ls
hadoop-2.7..tar.gz jdk-8u144-linux-x64.tar.gz
解压JDK到/opt/module目录下
[atguigu@hadoop101 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
配置JDK环境变量
()先获取JDK路径
[atguigu@hadoop101 jdk1..0_144]$ pwd
/opt/module/jdk1..0_144 ()打开/etc/profile文件
[atguigu@hadoop101 software]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1..0_144
export PATH=$PATH:$JAVA_HOME/bin ()保存后退出
:wq ()让修改后的文件生效
[atguigu@hadoop101 jdk1..0_144]$ source /etc/profile
测试JDK是否安装成功
atguigu@hadoop101 jdk1..0_144]# java -version
java version "1.8.0_144"
注意:重启(如果java -version可以用就不用重启)
[atguigu@hadoop101 jdk1..0_144]$ sync
[atguigu@hadoop101 jdk1..0_144]$ sudo reboot
安装Hadoop
.进入到Hadoop安装包路径下
[atguigu@hadoop101 ~]$ cd /opt/software/ .解压安装文件到/opt/module下面
atguigu@hadoop101 software]$ tar -zxvf hadoop-2.7..tar.gz -C /opt/module/ .查看是否解压成功
[atguigu@hadoop101 software]$ ls /opt/module/
hadoop-2.7. .将Hadoop添加到环境变量
()获取Hadoop安装路径
[atguigu@hadoop101 hadoop-2.7.]$ pwd
/opt/module/hadoop-2.7.
()打开/etc/profile文件
[atguigu@hadoop101 hadoop-2.7.]$ sudo vi /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
()保存后退出
:wq
()让修改后的文件生效
[atguigu@ hadoop101 hadoop-2.7.]$ source /etc/profile . 测试是否安装成功
[atguigu@hadoop101 hadoop-2.7.]$ hadoop version
Hadoop 2.7.
6. 重启(如果Hadoop命令不能用再重启)
[atguigu@ hadoop101 hadoop-2.7.2]$ sync
[atguigu@ hadoop101 hadoop-2.7.2]$ sudo reboot
查看Hadoop目录
[atguigu@hadoop101 hadoop-2.7.2]$ ll
总用量 52
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 bin
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 etc
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 include
drwxr-xr-x. 3 atguigu atguigu 4096 5月 22 2017 lib
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 libexec
-rw-r--r--. 1 atguigu atguigu 15429 5月 22 2017 LICENSE.txt
-rw-r--r--. 1 atguigu atguigu 101 5月 22 2017 NOTICE.txt
-rw-r--r--. 1 atguigu atguigu 1366 5月 22 2017 README.txt
drwxr-xr-x. 2 atguigu atguigu 4096 5月 22 2017 sbin
drwxr-xr-x. 4 atguigu atguigu 4096 5月 22 2017 share
2、重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
集群搭建-Hadoop运行环境搭建
内存4G,硬盘50G
1. 安装好linux
/boot 200M
/swap 2g
/ 剩余
2. *安装VMTools
3. 关闭防火墙
sudo service iptables stop
sudo chkconfig iptables off
4. 设置静态IP,改主机名
改ip: 编辑vim /etc/sysconfig/network-scripts/ifcfg-eth0
改成
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="eth0"
IPADDR=192.168.1.101
PREFIX=24
GATEWAY=192.168.1.2
DNS1=192.168.1.2
改用户名:
编辑vim /etc/sysconfig/network
改HOSTNAME=那一行
NETWORKING=yes
HOSTNAME=hadoop101
5. 配置/etc/hosts
vim /etc/hosts
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
192.168.1.109 hadoop109
6. 创建一个一般用户gll,给他配置密码
useradd gll
passwd gll
7. 配置这个用户为sudoers
vim /etc/sudoers
在root ALL=(ALL) ALL
添加gll ALL=(ALL) NOPASSWD:ALL
保存时wq!强制保存
8. *在/opt目录下创建两个文件夹module和software,并把所有权赋给gll
mkdir /opt/module /opt/software
chown gll:gll /opt/module /opt/software
9. 关机,快照,克隆
从这里开始要以一般用户登陆
10. 克隆的虚拟机;改物理地址
[root@hadoop101 桌面]# vim /etc/udev/rules.d/70-persistent-net.rules
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="00:0c:29:5f:8e:d9", ATTR{type}=="1", KERNEL=="eth*",
NAME="eth0"
11. 搞一个分发脚本 cd ~ vim xsync 内容如下:
#!/bin/bash
#xxx /opt/module
if (($#<1))
then
echo '参数不足'
exit
fi
fl=$(basename $1)
pdir=$(cd -P $(dirname $1); pwd)
for host in hadoop102 hadoop103
do
rsync -av $pdir/$fl $host:$pdir
done
修改文件权限,复制移动到/home/gll/bin目录下
chmod +x xsync
12. 配置免密登陆
. 生成密钥对
[gll@hadoop101 ~]$ cd .ssh
[gll@hadoop101 .ssh]$ ssh-keygen -t rsa
ssh-keygen -t rsa 三次回车
. 发送公钥到本机
ssh-copy-id hadoop101 输入一次密码
. 分别ssh登陆一下所有虚拟机
ssh hadoop102
exit
ssh hadoop103
exit
. 把/home/gll/.ssh 文件夹发送到集群所有服务器
xsync /home/gll/.ssh ##发送.ssh/是不会成功的;不要加最后的/
13. 在一台机器上安装Java和Hadoop,并配置环境变量,并分发到集群其他机器
拷贝文件到/opt/software,两个tar包 sudo vim /etc/profile
配置环境变量; 在文件末尾添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1..0_144
export PATH=$PATH:$JAVA_HOME/bin #HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存
. source /etc/profile
. 将配置文件分发到其他集群中:
[gll@hadoop101 module]$ sudo xsync /etc/profile
sudo:xsync:找不到命令
[gll@hadoop101 module]$ sudo scp /etc/profile root@hadoop102:/etc/profile
[gll@hadoop101 module]$ sudo scp /etc/profile root@hadoop103:/etc/profile
在hadoop102/hadoop103各执行 source/etc/profile
. 在其他机器分别执行source /etc/profile
所有配置文件都在$HADOOP_HOME/etc/hadoop
14. 首先配置hadoop-env.sh,yarn-env.sh,mapred-env.sh文件,配置Java_HOME
在每个文件第二行添加 export JAVA_HOME=/opt/module/jdk1.8.0_144
15. 配置Core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
16. 配置hdfs-site.xml
<!-- 数据的副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
17. 配置yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
18. 配置mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop103:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop103:19888</value>
</property>
启动历史服务器:mr-jobhistory-daemon.sh start historyserver
19. 配置slaves;配置时多一个空格/空行都不可以;
hadoop101
hadoop102
hadoop103
20. 分发配置文件
xsync /opt/module/hadoop-2.7.2/etc
21. 格式化Namenode 在hadoop102
在hadoop101上启动 hdfs namenode -format
22. 启动hdfs
在hadoop101上启动 start-dfs.sh
23. 在配置了Resourcemanager机器上执行
在Hadoop102上启动start-yarn.sh
24 关 stop-dfs.sh stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
Hadoop运行模式:
Hadoop运行模式:本地模式,伪分布式模式,完全分布式模式。
本地模式:
- 可运行的程序只有Mapreduce程序,而yarn(cpu,内存),HDFS(磁盘)均为了Mapreduce提供运行的环境。
- 本地运行存储不是HDFS,而是本地的磁盘,调度系统也是本地的操作系统。
- 主要用于开发和调试。
伪分布式模式:
即在一台服务器上搭建集群,HDFS分3个组建NameNode、DataNode、Secondary NameNode; yarn是分4个组建,实际只搭2个ResourceManage和NodeManager,
既是NameNode也是DataNode;既是ResourceManager也是NodeManager,这些进程都跑在一台机器上。
###所有配置文件都在$HADOOP_HOME/etc/hadoop
hadoop-env.sh、mapred-env.sh、yarn-env.sh三个文件中配置:JAVA_HOME
在每个文件第二行添加 export JAVA_HOME=/opt/module/jdk1.8.0_144 core-site.xml 指定HDFS中NameNode的地址;指定Hadoop运行时产生文件的存储目录
hdfs-site.xml 指定HDFS数据的副本数量 为3,就3台机器; 这些副本肯定分布在不同的服务器上;指定hadoop辅助名称节点(secondaryNameNode)主机配置;
mapred-site.xml 指定历史服务器地址;历史服务器web端地址,指定MR运行在YARN上;
yarn-site.xml Reducer获取数据的方式;指定YARN的ResourceManager的地址(服务器);日志的配置 hdfs namenode -format 格式化HDFS,在hadoop101上; 首次启动格式化
hadoop-daemon.sh start namenode 单独启动NameNode
hadoop-daemon.sh start datanode 单独启动DataNode
start-dfs.sh 启动hdfs
start-yarn.sh 启动yarn 启动前必须保证NameNode和DataNode已经启动
启动ResourceManager; 启动NodeManager
hadoop fs -put wcinput/ / 往集群的跟目录中上传一个wcinput文件
158 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /output
分发脚本配置和ssh配置过程
[gll@hadoop100 hadoop-2.7.2]$ dirname /opt/module/hadoop-2.7.2/
/opt/module
[gll@hadoop100 hadoop-2.7.2]$ dirname hadoop-2.7.2
.
[gll@hadoop100 hadoop-2.7.2]$ cd -P .
[gll@hadoop100 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2 遍历所有的主机名
##########集群分发脚本
#!/bin/bash
#xxx /opt/module
if (($#<))
then
echo '参数不足'
exit
fi
fl=$(basename $1) #文件名 basename /opt/module/hadoop-2.7.2/-->>hadoop-2.7.2
pdir=$(cd -P $(dirname $1); pwd) 父目录 dirname /opt/module/hadoop-2.7.2/ --->> /opt/module
for host in hadoop102 hadoop103 hadoop104
do
rsync -av $pdir/$fl $host:$pdir
done
scp安全拷贝、rsync远程同步工具
scp拷贝:可以实现服务器与服务器之间的数据拷贝
rsync拷贝:主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。
[atguigu@hadoop101 /]$ scp -r /opt/module root@hadoop102:/opt/module //-r是递归; 要拷贝的-->目的地
[atguigu@hadoop103 opt]$ scp -r atguigu@hadoop101:/opt/module root@hadoop104:/opt/module //可在不同服务之间传输;
[atguigu@hadoop101 opt]$ rsync -av /opt/software/ hadoop102:/opt/software //rsync只能从本机到其他 ;-a归档拷贝、-v显示复制过程
用scp发送
scp -r hadoop100:/opt/module/jdk1.8.0_144 hadoop102:/opt/module/
用rsync发送
[gll@hadoop100 module]$ rsync -av hadoop-2.7.2/ hadoop102:/opt/module/ 把当前目录下的全发过去了;-a归档拷贝、-v显示复制过程;
[gll@hadoop102 module]$ ls
bin include jdk1.8.0_144 libexec NOTICE.txt README.txt share
etc input lib LICENSE.txt output sbin wcinput
[gll@hadoop102 module]$ ls | grep -v jdk
过滤删除只剩jdk的
[gll@hadoop102 module]$ ls | grep -v jdk | xargs rm -rf
[gll@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 gll gll 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 gll gll 4096 7月 22 2017 jdk1.8.0_144
-rw-rw-r--. 1 gll gll 223 1月 15 17:13 xsync
[gll@hadoop100 module]$ chmod +x xsync
[gll@hadoop100 module]$ ll
总用量 12
drwxr-xr-x. 12 gll gll 4096 1月 15 14:55 hadoop-2.7.2
drwxr-xr-x. 8 gll gll 4096 7月 22 2017 jdk1.8.0_144
-rwxrwxr-x. 1 gll gll 223 1月 15 17:13 xsync
[gll@hadoop100 module]$
[gll@hadoop100 module]$ ./xsync /opt/module/jdk1.8.0_144
注意:拷贝过来的/opt/module目录,别忘了在hadoop101、hadoop102、hadoop103上修改所有文件的,所有者和所有者组。sudo chown gll:gll -R /opt/module
拷贝过来的配置文件别忘了source一下/etc/profile
SSH免密登录配置:
无密钥配置:
免密登录原理:
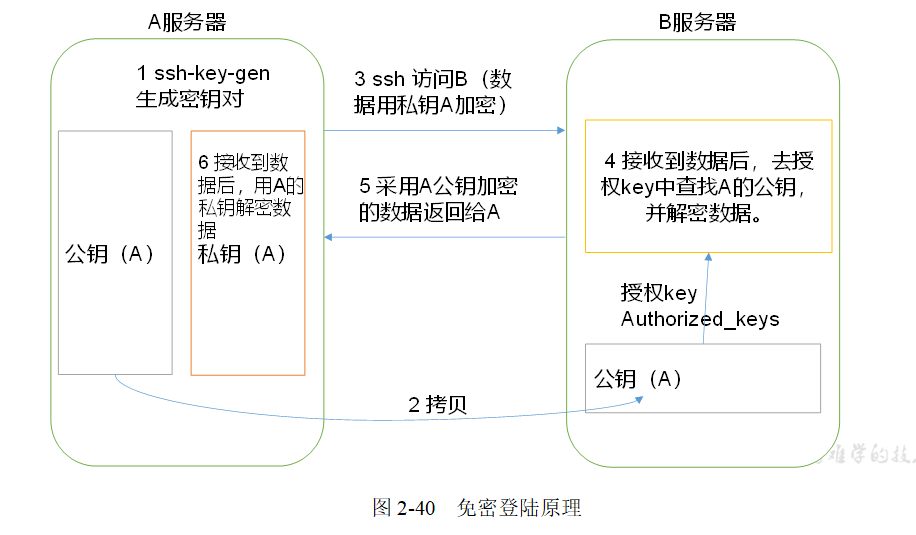
[gll@hadoop100 module]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/gll/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/gll/.ssh/id_rsa.
Your public key has been saved in /home/gll/.ssh/id_rsa.pub.
The key fingerprint is:
fd:15:a4:68:6e:88:c3:a1:f4:64:1b:aa:95:12:02:4a gll@hadoop100
The key's randomart image is:
+--[ RSA 2048]----+
|.E . |
|+ . o |
|o . . = o . . |
| . o O = = . |
| . = * S + . |
| + . . . . |
| . . |
| |
| |
+-----------------+
[gll@hadoop100 module]$ ssh-copy-id hadoop100 #给自己也发一份
[gll@hadoop100 module]$ ssh-copy-id hadoop101
[gll@hadoop100 module]$ ssh-copy-id hadoop102
[gll@hadoop100 module]$ ssh-copy-id hadoop103
[gll@hadoop100 module]$ ssh-copy-id hadoop104 100给100、101、102、103、104都赋权了;100<==>100双向通道已经建立,我能到自己了;可以把这个双向通道copy给其他的; [gll@hadoop100 .ssh]$ ll
总用量 16
-rw-------. 1 gll gll 396 1月 15 18:45 authorized_keys 把公钥放在已授权的keys里边,它跟公钥里边内容是一样的;
-rw-------. 1 gll gll 1675 1月 15 18:01 id_rsa 秘钥
-rw-r--r--. 1 gll gll 396 1月 15 18:01 id_rsa.pub 公钥
-rw-r--r--. 1 gll gll 2025 1月 15 17:37 known_hosts [gll@hadoop102 .ssh]$ ll
总用量 4
-rw-------. 1 gll gll 396 1月 15 18:04 authorized_keys [gll@hadoop100 module]$ ./xsync /home/gll/.ssh #给其他账户发送.ssh ;发送 .ssh/
sending incremental file list
.ssh/
.ssh/id_rsa
.ssh/id_rsa.pub
.ssh/known_hosts sent 4334 bytes received 73 bytes 8814.00 bytes/sec
total size is 4096 speedup is 0.93 sudo cp xsync /bin #copy到bin目录,就可全局使用;
[gll@hadoop100 module]$ xsync /opt/module/hadoop-2.7.2/
.ssh文件夹下(~/.ssh)的文件功能解释
表2-4
|
known_hosts |
记录ssh访问过计算机的公钥(public key) |
|
id_rsa |
生成的私钥 |
|
id_rsa.pub |
生成的公钥 |
|
authorized_keys |
存放授权过得无密登录服务器公钥 |
群起集群
1.配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves
[gll@hadoop102 hadoop]$ vi slaves
在该文件中增加如下内容:
hadoop102
hadoop103
hadoop104
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[gll@hadoop102 hadoop]$ xsync slaves
2.启动集群
(1)如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[gll@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -format
(2)启动HDFS
[gll@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[gll@hadoop102 hadoop-2.7.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode
[gll@hadoop103 hadoop-2.7.2]$ jps
3218 DataNode
3288 Jps
[gll@hadoop104 hadoop-2.7.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
(3)启动YARN
[gll@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
(4)Web端查看SecondaryNameNode
(a)浏览器中输入:http://hadoop104:50090/status.html
(b)查看SecondaryNameNode信息,如图2-41所示。
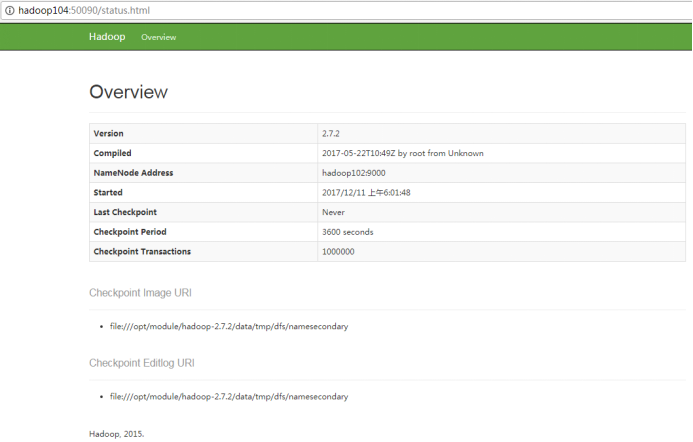
集群基础测试:
(1)上传文件到集群
上传小文件
[gll@hadoop102 hadoop-2.7.2]$ hdfs dfs -mkdir -p /user/gll/input
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfs -put wcinput/wc.input /user/atguigu/input
上传大文件
[gll@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -put
/opt/software/hadoop-2.7.2.tar.gz /user/gll/input
(2)上传文件后查看文件存放在什么位置
(a)查看HDFS文件存储路径
[gll@hadoop102 subdir0]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs/data/current/BP-938951106-192.168.10.107-1495462844069/current/finalized/subdir0/subdir0
(b)查看HDFS在磁盘存储文件内容
[gll@hadoop102 subdir0]$ cat blk_1073741825
hadoop yarn
hadoop mapreduce
gll
gll
(3)拼接
-rw-rw-r--. 1 gll gll 134217728 5月 23 16:01 blk_1073741836
-rw-rw-r--. 1 gll gll 1048583 5月 23 16:01 blk_1073741836_1012.meta
-rw-rw-r--. 1 gll gll 63439959 5月 23 16:01 blk_1073741837
-rw-rw-r--. 1 gll gll 495635 5月 23 16:01 blk_1073741837_1013.meta
[gll@hadoop102 subdir0]$ cat blk_1073741836>>tmp.file
[gll@hadoop102 subdir0]$ cat blk_1073741837>>tmp.file
[gll@hadoop102 subdir0]$ tar -zxvf tmp.file
(4)下载
[gll@hadoop102 hadoop-2.7.2]$ bin/hadoop fs -get
/user/gll/input/hadoop-2.7.2.tar.gz ./
集群时间同步:
配置集群是必须集群间时间同步得,所有得机器与这台集群时间进行定时得同步,比如,每隔十分钟,同步一次时间 。

配置时间同步具体实操:
1.时间服务器配置(必须root用户)
(1)检查ntp是否安装
[root@hadoop102 桌面]# rpm -qa|grep ntp
ntp-4.2.6p5-10.el6.centos.x86_64
fontpackages-filesystem-1.41-1.1.el6.noarch
ntpdate-4.2.6p5-10.el6.centos.x86_64
(2)修改ntp配置文件
[root@hadoop102 桌面]# vi /etc/ntp.conf
修改内容如下
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap为
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改/etc/sysconfig/ntpd 文件
[root@hadoop102 桌面]# vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[root@hadoop102 桌面]# service ntpd status
ntpd 已停
[root@hadoop102 桌面]# service ntpd start
正在启动 ntpd: [确定]
(5)设置ntpd服务开机启动
[root@hadoop102 桌面]# chkconfig ntpd on
2.其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[root@hadoop103桌面]# crontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[root@hadoop103桌面]# date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[root@hadoop103桌面]# date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。
自己配置得常用脚本
关闭所有机器:haltall.sh
for i in `cat /opt/module/hadoop-2.7.2/etc/hadoop/slaves`
do
ssh $i 'source /etc/profile&&sudo halt'
done
查看所有机器进程:jpsall:
#!/bin/bash
for((host=100;host<103;host++))
do
echo "==========szhzysdsjfx$host$i =========="
ssh ScflLinux$host$i 'source /etc/profile&&jps'
done
Windows中hosts的配置:
在windows系统中,HOST文件位于系统盘C:\Windows\System32\drivers\etc中
Hosts是一个没有扩展名的系统文件,其作用就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库”。
- hosts文件能加快域名解析,对于要经常访问的网站,我们可以通过在Hosts中配置域名和IP的映射关系,提高域名解析速度。
- hosts文件可以方便局域网用户在很多单位的局域网中,可以分别给这些服务器取个容易记住的名字,然后在Hosts中建立IP映射,这样以后访问的时候,只要输入这个服务器的名字就行了。
- hosts文件可以屏蔽一些网站,对于自己想屏蔽的一些网站我们可以利用Hosts把该网站的域名映射到一个错误的IP或本地计算机的IP,这样就不用访问了。
- 根据这个HOSTS文件的作用看的出来 ,如果是别有用心的病毒把你的HOSTS文件修改了!(例如把一个正规的网站改成一个有病毒的网站的IP)。那么你就会打开一个带有病毒的网站,你可想而知你的后果了吧!
查看Windows IP 配置
C:\Users\Administrator>ipconfig /displaydns
修改hosts后生效的方法:Windows 开始 -> 运行 -> 输入cmd -> 在CMD窗口输入 ipconfig /flushdns
Linux 终端输入: sudo rcnscd restart
host中的配置没有被识别到,那么是否是因为字符或者换行等原因呢?于是:
查看了host文件的字符:


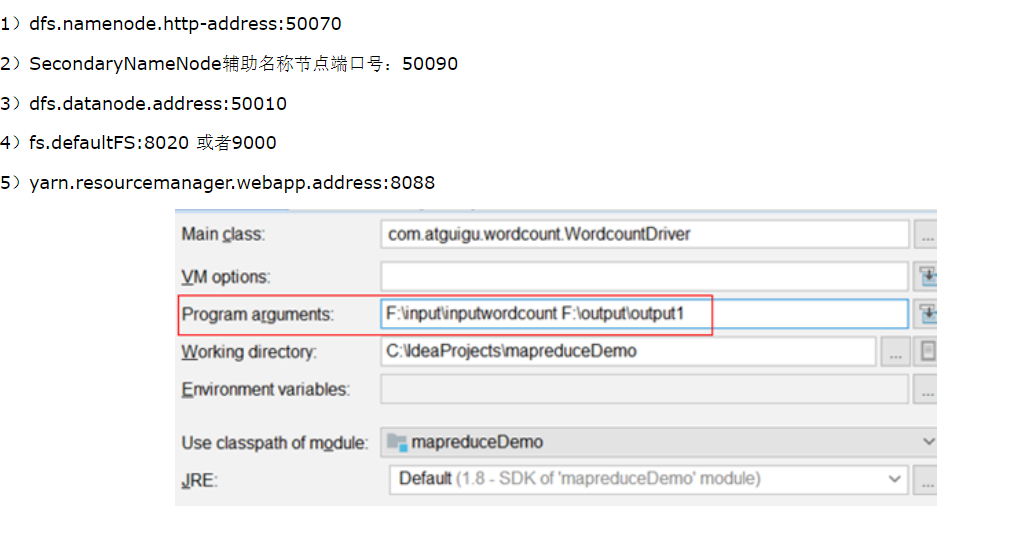
Hadoop默认端口及含义:
常见错误和解决问题
1)防火墙没关闭、或者没有启动YARN
INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
2)主机名称配置错误
3)IP地址配置错误
4)ssh没有配置好
5)root用户和atguigu两个用户启动集群不统一
6)配置文件修改不细心
7)未编译源码
Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/05/22 15:38:58 INFO client.RMProxy: Connecting to ResourceManager at hadoop108/192.168.10.108:8032
8)不识别主机名称
java.net.UnknownHostException: hadoop102: hadoop102
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
解决办法:
(1)在/etc/hosts文件中添加192.168.1.102 hadoop102
(2)主机名称不要起hadoop hadoop000等特殊名称
9)DataNode和NameNode进程同时只能工作一个。
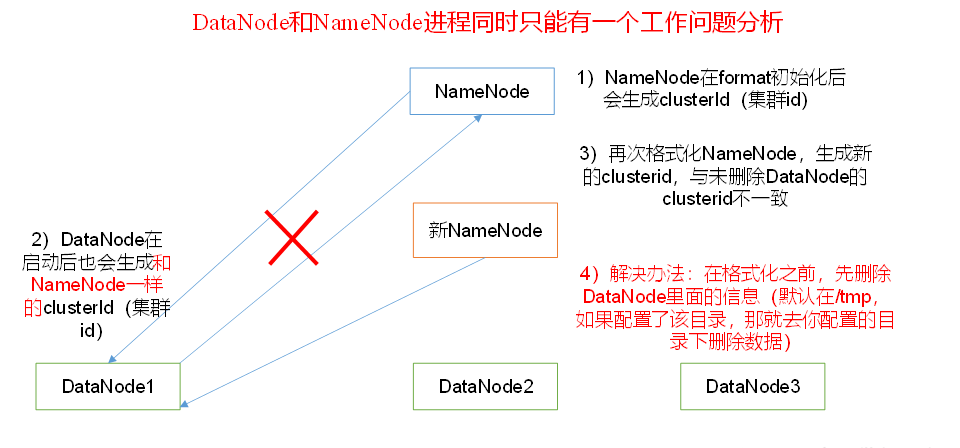
10)执行命令不生效,粘贴word中命令时,遇到-和长–没区分开。导致命令失效
解决办法:尽量不要粘贴word中代码。
11)jps发现进程已经没有,但是重新启动集群,提示进程已经开启。原因是在linux的根目录下/tmp目录中存在启动的进程临时文件,将集群相关进程删除掉,再重新启动集群。
12)jps不生效。
原因:全局变量hadoop java没有生效。解决办法:需要source /etc/profile文件。
13)8088端口连接不上
[atguigu@hadoop102 桌面]$ cat /etc/hosts
注释掉如下代码
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 hadoop102
集群安装过程错误及解决方法:
1)发现有些进程没有启动起来:
解决:
* 先尝试单点启动进程。
* 如果单点启动失败:先关闭所有进程;删除hadoop下得data,logs;再重新格式化namenode;再重启所有进程。
* 如果还是失败,查看那个进程没有起来,看对应的配置文件是否配置成功,更改后,记得分发给其他机器。
2)jdk版本问题:
解决:
在安装时记得查看是否有旧版本,并删除,安装后配置/etc/profile,记得source /etc/profile文件才能成功,每个机器都要做此操作。 3)格式化HDFS 到达hadoop的bin目录下 执行
$hadoop namenode -format
报了这个错(namenode 无法启动)
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /export/home/dfs/name/current
解决:原因是 没有设置 /opt/hadoop 的权限没有设置, 将之改为:
$ chown –R gll:gll /opt/hadoop
$ sudo chmod -R a+w /opt/hadoop 4)启动Hadoop,执行 start-all.sh 当前用户对hadoop安装目录无足够权限
hm@hm-ubuntu:/usr/hadoop-1.1.2/bin$ start-all.sh
mkdir: cannot create directory /usr/hadoop-1.1.2/libexec/../logs': Permission denied
chown: cannot access/usr/hadoop-1.1.2/libexec/../logs’: No such file or directory
starting namenode, logging to /usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out
/usr/hadoop-1.1.2/bin/hadoop-daemon.sh: line 136: /usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out: No such file or directory
head: cannot open `/usr/hadoop-1.1.2/libexec/../logs/hadoop-hm-namenode-hm-ubuntu.out’ for reading: No such file or directory
hm@localhost’s password:
解决:
执行 chown 命令为当前用户赋予对目录可写的权限
sudo chown -hR Eddie(当前用户名) hadoop-xxx(当前版本)
5)hadoop执行stop-all.sh的时候总是出现 “no namenode to stop”
解决:
这个原因其实是因为在执行stop-all.sh时,找不到pid文件了。
在 HADOOP_HOME/conf/ hadoop-env.sh 里面,修改配置如下:
export HADOOP_PID_DIR=/home/hadoop/pids
pid文件默认在/tmp目录下,而/tmp是会被系统定期清理的,所以Pid文件被删除后就no namenode to stop”
6)当在格式化namenode时出现cannot create directory /usr/local/hadoop/hdfs/name/current的时候
解决:
请将hadoop的目录权限设为当前用户可写sudo chmod -R a+w /usr/local/hadoop,授予hadoop目录的写权限
7)当碰到 chown:changing ownership of 'usr/local/hadoop ../logs':operation not permitted时
解决:
可用sudo chown -R gll /usr/local/hadoop来解决,即将hadoop主目录授权给当前grid用户
8)如果slaves机上通过jps只有TaskTracker进程,没有datanode进程
解决:
请查看日志,是不是有“could only be replicated to 0 nodes,instedas of 1”有这样的提示错误,如果有,可能就是没有关闭防火墙所致,服务器和客户机都关闭(sudo ufw disable)后,所有进程启动正常,浏览器查看状态也正常了(ub untu防火墙关闭)
9)要在服务器机上把masters和slavs机的IP地址加到/etc/hosts:当然这个不影响start-all.sh启动,只是浏览器jobtacker上找不到节slaves节点
10).ssh免密码登陆时,注意文件authorized_keys和.ssh目录权限,如果从masters机上scp authorized_keys到slaves机上出现拒绝问题
解决:
那就在salves机上也ssh-keygen,这样目录和文件就不会有权限问题了,就可以实现ssh免密码登陆了,或直接将.ssh目录拷过去,在slaves机上新建.ssh目录权限好像和masters机的目录权限不一样
运行正常后,可以用wordcount例子来做一下测试:
bin/hadoop dfs –put /home/test-in input //将本地文件系统上的 /home/test-in 目录拷到 HDFS 的根目录上,目录名改为 input
bin/hadoop jar hadoop-examples-0.20.203.0.jar wordcount input output
#查看执行结果:
# 将文件从 HDFS 拷到本地文件系统中再查看:
$ bin/hadoop dfs -get output output
$ cat output/*
# 也可以直接查看
$ bin/hadoop dfs -cat output/*
11)如果在reduce过程中出现"Shuffle Error:Exceeded,MAX_FAILED_UNIQUE_FETCHES;bailing-out"错误
解决:
原因有可能是/etc/hosts中没有将IP映射加进去,还有可能是关于打开文件数限制的问题,需要改vi /etc/security/limits.conf
12)error:call to failed on local exception:java.io.EOFException
解决:
原因如下:eclipse-plugin和Hadoop版本对不上(因为刚开始不想换hadoop版本,就直接把那个插件(hadoop-plugin-0.20.3-snapshot.jar)拷到0.20.203版本里跑了一下,结果报上面的错,后来将hadoop版本换成hadoop0.20.2就好了)
参考资料:
http://lucene.472066.n3.nabble.com/Call-to-namenode-fails-with-java-io-EOFException-td2933149.html ;
Hadoop架构及集群的更多相关文章
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- [推荐]Hadoop+HBase+Zookeeper集群的配置
[推荐]Hadoop+HBase+Zookeeper集群的配置 Hadoop+HBase+Zookeeper集群的配置 http://wenku.baidu.com/view/991258e881c ...
- Hadoop的HA集群启动和停止流程
假设我们有3台虚拟机,主机名分别是hadoop01.hadoop02和hadoop03. 这3台虚拟机的Hadoop的HA集群部署计划如下: 3台虚拟机的Hadoop的HA集群部署计划 hadoop0 ...
- hadoop 2.3 集群总结
用了近两个礼拜的摸索终于搭建好了hadoop集群,测试性能也符合预期. centos6.4下hadoop2.3集群总结如下: 关于环境的设置: 1.关闭selinux (反复折腾了好多次) vi /e ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Hadoop(三)手把手教你搭建Hadoop全分布式集群
前言 上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的.接下来我将给大家分享一下全分布式集群的搭建! 其实搭建最基本的全分布式集群和伪分布式集群 ...
- Hadoop 2.8集群安装及配置记录
第一部分:环境配置(含操作系统.防火墙.SSH.JAVA安装等) Hadoop 2.8集群安装模拟环境为: 主机:Hostname:Hadoop-host,IP:10.10.11.225 节点1:Ho ...
- Hadoop基础-HDFS集群中大数据开发常用的命令总结
Hadoop基础-HDFS集群中大数据开发常用的命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本盘博客仅仅列出了我们在实际生成环境中常用的hdfs命令,如果想要了解更多, ...
随机推荐
- 嗯 想写个demo 苦于没数据
step 1: 来点数据: 各种数据 随你便了. step 2: 来个 服务端 step 3 : 客户端 调用
- BZOJ 3513 idiots
题目传送门 分析: FFT一手统计两根棍子相加的方案 然后一个值2S可能会被同一根S自己乘自己得到 然后要减去 其次,A+B和B+A会被算成两种方案,所以还要除以2 然后不太好算合法的方案数,但是非法 ...
- jmeter使用—远程分布式
今天要说的是在远程服务器上使用多台服务器进行noGUI分布式使用jmeter压测. 1.首先准备几台服务器,服务器上都需要安装同一个版本的jmeter. 2.在服务器上启动jmeter的方式是在jme ...
- Informatica9.5.1配置域名错误(ICMD_10033,INFASETUP_10002,RSVCSHARED_00021)
错误信息: OutPut : [ICMD_10033] Command [defineDomain] failed with error [[INFASETUP_10002] Cannot creat ...
- Spring Boot 2.x基础教程:默认数据源Hikari的配置详解
通过上一节的学习,我们已经学会如何应用Spring中的JdbcTemplate来完成对MySQL的数据库读写操作.接下来通过本篇文章,重点说说在访问数据库过程中的一个重要概念:数据源(Data Sou ...
- FFMPEG学习----遍历所支持的封装格式
#include <stdio.h> extern "C" { #include "libavformat/avformat.h" }; int m ...
- rep stos 指令(Intel汇编)
今天读代码时,忽然跳出如下一条指令==>> 汇编代码: rep stos dword ptr es:[edi] 在网上查了相关资料显示: /************************ ...
- Tarjan算法——强连通、双连通、割点、桥
Tarjan算法 概念区分 有向图 强连通:在有向图\(G\)中,如果两个顶点\(u, v\ (u \neq v)\)间有一条从\(u\)到\(v\)的有向路径,同时还有一条从\(v\)到\(u\)的 ...
- PTA 7-10 树的遍历(二叉树基础、层序遍历、STL初体验之queue)
7-10 树的遍历(25 分) 给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列.这里假设键值都是互不相等的正整数. 输入格式: 输入第一行给出一个正整数N(≤30),是二叉树中结点的个数 ...
- YUM源部署和使用
1.前言 为什么需要内部yum源呢,有可能是业务内部的服务器对外是不通了,居于一些安全方面的考虑.内部yum源又有什么好处呢,第一,速度快:第二,内网可控,外网有问题也不影响内网包的下载和安装等. 2 ...