高级教程: 作出动态决策和 Bi-LSTM CRF 重点
动态 VS 静态深度学习工具集
Pytorch 是一个 动态 神经网络工具包. 另一个动态工具包的例子是 Dynet (我之所以提这个是因为使用 Pytorch 和 Dynet 是十分类似的. 如果你看过 Dynet 中的例子, 那么它将有可能对你在 Pytorch 下实现它有帮助). 与动态相反的是 静态 工具包, 包括了 Theano, Keras, TensorFlow 等等. 下面是这两者核心的一些区别:
- 在一个静态工具包中, 你一次性定义好一个计算图, 接着编译它, 然后把数据流输实例送进去.
- 在一个动态工具包中, 你 为每一个实例 定义一个计算图, 它完全不需要被编译并且是在运行中实时执行的.
若没有丰富的经验, 你很难体会出其中的差别. 举一个例子, 假设我们想要构建一个深度句法分析器. 那么我们的模型需要下列的一些步骤:
- 我们从下往上构建树
- 标注根节点(句子中的词语)
- 从那儿开始, 使用一个神经网络和词向量来找到组成句法的不同组合. 一旦当你形成了一个新的句法, 使用某种方式得到句法的嵌入表示 (embedding). 在这个例子里, 我们的网络架构将会 完全的依赖于输入的句子. 来看这个句子: “绿色猫抓了墙”, 在这个模型的某一节点, 我们想要把范围
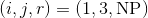 合并起来(即, 一个 NP 句法范围跨越词1到词3, 在这个例子中是”绿色猫”).
合并起来(即, 一个 NP 句法范围跨越词1到词3, 在这个例子中是”绿色猫”).
然而, 另一个句子可能是”某处, 那个大肥猫抓了墙.” 在这个句子中, 我们想要在某点形成句法 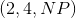 . 我们想要形成的句法将会依赖于这个实例. 如果仅仅编译这个计算图一次, 就像在静态工具包中那样, 那么我们给这个逻辑编程将会变得十分困难或者根本不可能. 然而, 在一个动态工具包中, 并不仅仅只有一个预定义的计算图. 对于每一个实例, 都能够有一个新的计算图, 所以上面的问题就不复存在了.
. 我们想要形成的句法将会依赖于这个实例. 如果仅仅编译这个计算图一次, 就像在静态工具包中那样, 那么我们给这个逻辑编程将会变得十分困难或者根本不可能. 然而, 在一个动态工具包中, 并不仅仅只有一个预定义的计算图. 对于每一个实例, 都能够有一个新的计算图, 所以上面的问题就不复存在了.
动态工具包也具有更容易调试和更接近所使用的编程语言的特点(我的意思是 Pytorch 和 Dynet 看上去 比 Keras 和 Theano 更像 Python).
Bi-LSTM CRF (条件随机场) 讨论
在这一部分, 我们将会看到一个完整且复杂的 Bi-LSTM CRF (条件随机场)用来命名实体识别 (NER) 的例子. 上面的 LSTM 标注工具通常情况下对词性标注已经足够用了, 但一个序列模型比如 CRF 对于在 NER 下取得 强劲的表现是至关重要的. 假设熟悉 CRF. 尽管这个名字听上去吓人, 但所有的模型只是一个由 LSTM 提供 特征的 CRF. 但这是一个高级的模型, 远比这个教程中的其它早期的模型更加复杂. 如果你要跳过这一部分, 没有关系. 想要确定你是否准备好, 那看看你是不是能够:
- 复现标签 k 的第 i 步维特比变量的算法.
- 修改上述循环来计算正向变量.
- 再一次修改上述复现来在对数空间中计算正向变量. (提示: 对数-求和-指数)
如果你能够完成以上三件事, 那么你就不难理解下面的代码了. 回想一下, CRF 计算的是一个条件概率. 让 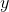 作为一个标注序列,
作为一个标注序列, 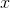 作为某个词的输入序列. 接下来我们计算:
作为某个词的输入序列. 接下来我们计算:
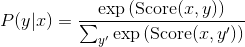
上面的分数 Score 是由定义一些对数势能 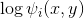 而决定的. 进而
而决定的. 进而
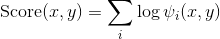
要使分割函数易于掌控, 势能必须只能集中于局部的特征.
在 Bi-LSTM CRF 中, 我们定义两种势能 (potential): 释放 (emission) 和过渡 (transition). 索引 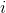 处字的释放势能来自于 时间处的 Bi-LSTM 的隐藏状态. 过渡势能的分数储存在
处字的释放势能来自于 时间处的 Bi-LSTM 的隐藏状态. 过渡势能的分数储存在 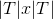 矩阵
矩阵 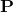 , 其中
, 其中 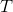 是标注集合. 在我的实现中,
是标注集合. 在我的实现中, 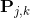 是从标注
是从标注 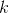 过渡到 标注
过渡到 标注 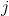 的得分. 因此:
的得分. 因此:
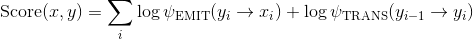
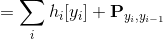
在上面第二个表达式中, 我们认为标签被分配了独一无二的非负索引.
如果上面的讨论太简短了, 你还可以看看 这个 由 Michael Collins 写的关于 CRFs 的文章.
具体实现笔记
下面的例子实现了在对数空间中的前向算法来计算出分割函数和维特比算法来进行译码. 反向传播将会为我们自动计算出梯度. 我们不需要手动去实现这个.
这个代码中的实现并没有优化过. 如果你理解下面的过程, 也许你会觉得下面的代码中, 前向算法中 的迭代下一次标注可以在一次大的运算中完成. 虽然有简化的余地, 但我想的是让代码可读性更好. 如果你想进行相关的修改, 也许你可以在一些真实的任务中使用这个标注器.
# 作者: Robert Guthrie
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
一些帮助函数, 使代码可读性更好
def to_scalar(var):
# 返回 python 浮点数 (float)
return var.view(-1).data.tolist()[0]
def argmax(vec):
# 以 python 整数的形式返回 argmax
_, idx = torch.max(vec, 1)
return to_scalar(idx)
def prepare_sequence(seq, to_ix):
idxs = [to_ix[w] for w in seq]
tensor = torch.LongTensor(idxs)
return autograd.Variable(tensor)
# 使用数值上稳定的方法为前向算法计算指数和的对数
def log_sum_exp(vec):
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
创建模型
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 将LSTM的输出映射到标记空间
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 过渡参数矩阵. 条目 i,j 是
# *从* j *到* i 的过渡的分数
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
# 这两句声明强制约束了我们不能
# 向开始标记标注传递和从结束标注传递
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
return (autograd.Variable(torch.randn(2, 1, self.hidden_dim // 2)),
autograd.Variable(torch.randn(2, 1, self.hidden_dim // 2)))
def _forward_alg(self, feats):
# 执行前向算法来计算分割函数
init_alphas = torch.Tensor(1, self.tagset_size).fill_(-10000.)
# START_TAG 包含所有的分数
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# 将其包在一个变量类型中继而得到自动的反向传播
forward_var = autograd.Variable(init_alphas)
# 在句子中迭代
for feat in feats:
alphas_t = [] # 在这个时间步的前向变量
for next_tag in range(self.tagset_size):
# 对 emission 得分执行广播机制: 它总是相同的,
# 不论前一个标注如何
emit_score = feat[next_tag].view(
1, -1).expand(1, self.tagset_size)
# trans_score 第 i 个条目是
# 从i过渡到 next_tag 的分数
trans_score = self.transitions[next_tag].view(1, -1)
# next_tag_var 第 i 个条目是在我们执行 对数-求和-指数 前
# 边缘的值 (i -> next_tag)
next_tag_var = forward_var + trans_score + emit_score
# 这个标注的前向变量是
# 对所有的分数执行 对数-求和-指数
alphas_t.append(log_sum_exp(next_tag_var))
forward_var = torch.cat(alphas_t).view(1, -1)
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
# 给出标记序列的分数
score = autograd.Variable(torch.Tensor([0]))
tags = torch.cat([torch.LongTensor([self.tag_to_ix[START_TAG]]), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
backpointers = []
# 在对数空间中初始化维特比变量
init_vvars = torch.Tensor(1, self.tagset_size).fill_(-10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# 在第 i 步的 forward_var 存放第 i-1 步的维特比变量
forward_var = autograd.Variable(init_vvars)
for feat in feats:
bptrs_t = [] # 存放这一步的后指针
viterbivars_t = [] # 存放这一步的维特比变量
for next_tag in range(self.tagset_size):
# next_tag_var[i] 存放先前一步标注i的
# 维特比变量, 加上了从标注 i 到 next_tag 的过渡
# 的分数
# 我们在这里并没有将 emission 分数包含进来, 因为
# 最大值并不依赖于它们(我们在下面对它们进行的是相加)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id])
# 现在将所有 emission 得分相加, 将 forward_var
# 赋值到我们刚刚计算出来的维特比变量集合
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# 过渡到 STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# 跟着后指针去解码最佳路径
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# 弹出开始的标签 (我们并不希望把这个返回到调用函数)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # 健全性检查
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
def forward(self, sentence): # 不要把这和上面的 _forward_alg 混淆
# 得到 BiLSTM 输出分数
lstm_feats = self._get_lstm_features(sentence)
# 给定特征, 找到最好的路径
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
运行训练
START_TAG = "<START>"
STOP_TAG = "<STOP>"
EMBEDDING_DIM = 5
HIDDEN_DIM = 4
# 制造一些训练数据
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word_to_ix = {}
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# 在训练之前检查预测结果
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
precheck_tags = torch.LongTensor([tag_to_ix[t] for t in training_data[0][1]])
print(model(precheck_sent))
# 确认从之前的 LSTM 部分的 prepare_sequence 被加载了
for epoch in range(
300): # 又一次, 正常情况下你不会训练300个 epoch, 这只是示例数据
for sentence, tags in training_data:
# 第一步: 需要记住的是Pytorch会累积梯度
# 我们需要在每次实例之前把它们清除
model.zero_grad()
# 第二步: 为我们的网络准备好输入, 即
# 把它们转变成单词索引变量 (Variables)
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.LongTensor([tag_to_ix[t] for t in tags])
# 第三步: 运行前向传递.
neg_log_likelihood = model.neg_log_likelihood(sentence_in, targets)
# 第四步: 计算损失, 梯度以及
# 使用 optimizer.step() 来更新参数
neg_log_likelihood.backward()
optimizer.step()
# 在训练之后检查预测结果
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print(model(precheck_sent))
# 我们完成了!
练习: 为区别性标注定义一个新的损失函数
在解码的时候, 我们不一定需要创建一个计算图, 因为我们并不从维特比路径分数中做反向传播. 不管怎样, 既然我们有了它, 尝试训练这个标注器, 使其损失函数是维特比路径分数和黄金标准分数之差. 需要弄清楚的是, 这个函数在预测标注序列是正确的时候应当大于等于0. 这本质上是 结构化感知机 .
这个改动应当是很简短的, 因为 Viterbi 和 scoresentence 是已经实现好了的. 这是 依赖于训练实例的_ 计算图的形状的一个例子. 但我们并没有尝试过在一个静态工具包上实现过, 我想象中这是可行的但并不是很显而易见.
找一些真实数据做一下比较吧!
高级教程: 作出动态决策和 Bi-LSTM CRF 重点的更多相关文章
- [转帖]tar高级教程:增量备份、定时备份、网络备份
tar高级教程:增量备份.定时备份.网络备份 作者: lesca 分类: Tutorials, Ubuntu 发布时间: 2012-03-01 11:42 ė浏览 27,065 次 61条评论 一.概 ...
- JavaScript高级教程
JavaScript高级教程 基础总结深入 数据类型 分类 you are so nb! undefined :undefined string :任意字符串 sybmol: object:任意对象, ...
- ios cocopods 安装使用及高级教程
CocoaPods简介 每种语言发展到一个阶段,就会出现相应的依赖管理工具,例如Java语言的Maven,nodejs的npm.随着iOS开发者的增多,业界也出现了为iOS程序提供依赖管理的工具,它的 ...
- 【读书笔记】.Net并行编程高级教程(二)-- 任务并行
前面一篇提到例子都是数据并行,但这并不是并行化的唯一形式,在.Net4之前,必须要创建多个线程或者线程池来利用多核技术.现在只需要使用新的Task实例就可以通过更简单的代码解决命令式任务并行问题. 1 ...
- 【读书笔记】.Net并行编程高级教程--Parallel
一直觉得自己对并发了解不够深入,特别是看了<代码整洁之道>觉得自己有必要好好学学并发编程,因为性能也是衡量代码整洁的一大标准.而且在<失控>这本书中也多次提到并发,不管是计算机 ...
- 分享25个新鲜出炉的 Photoshop 高级教程
网络上众多优秀的 Photoshop 实例教程是提高 Photoshop 技能的最佳学习途径.今天,我向大家分享25个新鲜出炉的 Photoshop 高级教程,提高你的设计技巧,制作时尚的图片效果.这 ...
- 展讯NAND Flash高级教程【转】
转自:http://wenku.baidu.com/view/d236e6727fd5360cba1adb9e.html 展讯NAND Flash高级教程
- Net并行编程高级教程--Parallel
Net并行编程高级教程--Parallel 一直觉得自己对并发了解不够深入,特别是看了<代码整洁之道>觉得自己有必要好好学学并发编程,因为性能也是衡量代码整洁的一大标准.而且在<失控 ...
- Siki_Unity_2-9_C#高级教程(未完)
Unity 2-9 C#高级教程 任务1:字符串和正则表达式任务1-1&1-2:字符串类string System.String类(string为别名) 注:string创建的字符串是不可变的 ...
随机推荐
- 从0开始学习 GitHub 系列之「03.Git 速成」
前面的 GitHub 系列文章介绍过,GitHub 是基于 Git 的,所以也就意味着 Git 是基础,如果你不会 Git ,那么接下来你完全继续不下去,所以今天的教程就来说说 Git ,当然关于 G ...
- Lichee ( 四 ) 打包IMAGE
在<Lichee(三) Android4.0的目标产品文件夹与Lichee的纽带---extract-bsp>中我们分析了extract-bsp的作用和意义.到这里,我们能够開始编译And ...
- php怎么自动加载
在 PHP 代码的顶部你是不是经常看到这样的代码. require 'lionis.php'; require 'is.php'; require 'cool.php'; 如果只是引入几个 PHP 脚 ...
- MaxCompute推出面向开发者的专属版本,普惠大数据开发者
3月20号,阿里云正式对外宣布推出MaxCompute产品的新规格-开发者版.MaxCompute开发者版是阿里云大数据计算服务发布的开发者专属版本.区别于原有的按量付费.按CU预付费规格,开发者版是 ...
- 【怪物】KMP畸形变种——扩展KMP
问题 参考51nod1304这道题: 很显然我们要求的是S的每个后缀与S的最长公共前缀的长度之和. 暴力 假设我们把next[i]表示为第i个后缀与S的最长公共前缀的长度. 现在我们想了:这个next ...
- JasperStudio study..
https://blog.csdn.net/shiyun123zw/article/details/79166448
- Directx11教程(20) 一个简单的水面
原文:Directx11教程(20) 一个简单的水面 nnd,以前发的这篇教程怎么没有了?是我自己误删除了,还是被系统删除了? 找不到存稿了,没有心情再写一遍了. 简单说一下,本篇教程就是实 ...
- SSM框架用JSON进行前后端数据传输
一个根据用户id查找用户信息的简单功能,使用JSON进行数据的传输 前端代码 这里用bootstrap做简单的样式美化,中间留了个div用来异步的显示查询结果,ajax进行前端的数据传输(class内 ...
- Leetcode821.Shortest Distance to a Character字符的最短距离
给定一个字符串 S 和一个字符 C.返回一个代表字符串 S 中每个字符到字符串 S 中的字符 C 的最短距离的数组. 示例 1: 输入: S = "loveleetcode", C ...
- JavaScript--时间日期格式化封装
这是一个正常的封装: 其他非正常的请按照以下语句自由搭配 <!DOCTYPE html> <html lang="en"> <head> < ...