sklearn中回归器性能评估方法
- explained_variance_score()
- mean_absolute_error()
- mean_squared_error()
- r2_score()
以上四个函数的相同点:
- 这些函数都有一个参数“multioutput”,用来指定在多目标回归问题中,若干单个目标变量的损失或得分以什么样的方式被平均起来
- 它的默认值是“uniform_average”,他就是将所有预测目标值的损失以等权重的方式平均起来
- 如果你传入了一个shape为(n_oupputs,)的ndarray,那么数组内的数将被视为是对每个输出预测损失(或得分)的加权值,所以最终的损失就是按照你锁指定的加权方式来计算的
- 如果multioutput是“raw_values”,那么所有的回归目标的预测损失或预测得分都会被单独返回一个shape是(n_output)的数组中
explained_variance_score


#explained_variance_score
from sklearn.metrics import explained_variance_score
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(explained_variance_score(y_true,y_pred))
y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(explained_variance_score(y_true,y_pred,multioutput="raw_values"))
print(explained_variance_score(y_true,y_pred,multioutput=[0.3,0.7])) #结果
#0.957173447537
#[ 0.96774194 1. ]
#0.990322580645
mean_absolute_error

#mean_absolute_error
from sklearn.metrics import mean_absolute_error
y_true=[3,0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(mean_absolute_error(y_true,y_pred)) y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(mean_absolute_error(y_true,y_pred))
print(mean_absolute_error(y_true,y_pred,multioutput="raw_values"))
print(mean_absolute_error(y_true,y_pred,multioutput=[0.3,0.7])) #结果
#0.5
#0.75
#[ 0.5 1. ]
#0.85
mean_squared_error
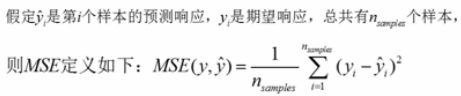
#mean_squared_error
from sklearn.metrics import mean_squared_error
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(mean_squared_error(y_true,y_pred))
y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(mean_squared_error(y_true,y_pred)) #结果
#0.375
#0.708333333333
median_absolute_error
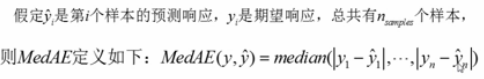
#median_absolute_error
from sklearn.metrics import median_absolute_error
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(median_absolute_error(y_true,y_pred)) #结果
#0.5
r2_score

#r2_score
from sklearn.metrics import r2_score
y_true=[3,-0.5,2,7]
y_pred=[2.5,0.0,2,8]
print(r2_score(y_true,y_pred)) y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(r2_score(y_true,y_pred,multioutput="variance_weighted")) y_true=[[0.5,1],[-1,1],[7,-6]]
y_pred=[[0,2],[-1,2],[8,-5]]
print(r2_score(y_true,y_pred,multioutput="uniform_average"))
print(r2_score(y_true,y_pred,multioutput="raw_values"))
print(r2_score(y_true,y_pred,multioutput=[0.3,0.7])) #结果
#0.948608137045
#0.938256658596
#0.936800526662
#[ 0.96543779 0.90816327]
#0.92534562212
sklearn中回归器性能评估方法的更多相关文章
- sklearn中的回归器性能评估方法(转)
explained_variance_score() mean_absolute_error() mean_squared_error() r2_score() 以上四个函数的相同点: 这些函数都有一 ...
- sklearn中的回归器性能评估方法
explained_variance_score() mean_absolute_error() mean_squared_error() r2_score() 以上四个函数的相同点: 这些函数都有一 ...
- sklearn中各种分类器回归器都适用于什么样的数据呢?
作者:匿名用户链接:https://www.zhihu.com/question/52992079/answer/156294774来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- Sklearn中的回归和分类算法
一.sklearn中自带的回归算法 1. 算法 来自:https://my.oschina.net/kilosnow/blog/1619605 另外,skilearn中自带保存模型的方法,可以把训练完 ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- 通俗地说逻辑回归【Logistic regression】算法(二)sklearn逻辑回归实战
前情提要: 通俗地说逻辑回归[Logistic regression]算法(一) 逻辑回归模型原理介绍 上一篇主要介绍了逻辑回归中,相对理论化的知识,这次主要是对上篇做一点点补充,以及介绍sklear ...
随机推荐
- 使用wordpress搭建的网站如何去掉域名中的wordpess
我们搭建好的网站当以文件夹的形式把wordpress程序放在空间的根目录时,访问的时候要加上文件夹名,访问地址就是:http://www.xxx.com/wordpress,直接用域名是无法访问,解决 ...
- 红黑数之原理分析及C语言实现
目录: 1.红黑树简介(概念,特征,用途) 2.红黑树的C语言实现(树形结构,添加,旋转) 3.部分面试题() 1.红黑树简介 1.1 红黑树概念 红黑树(Red-Black Tree,简称R-B T ...
- Linux 线程Demo
#include <stdio.h> #include <pthread.h> struct char_print_params { char character; int c ...
- CSS:CSS 图片廊
ylbtech-CSS:CSS 图片廊 1.返回顶部 1. CSS 图片廊 以下是使用CSS创建图片廊: 图片廊 以下是使用 CSS 创建图片廊: 实例 <div class="res ...
- 在jeecg中如何配置多对一和多对多的关系
多对多: mappedBy指的是当前的类对应的表, cascade属性的可能值有 all: 所有情况下均进行关联操作,即save-update和delete. none: 所有情况下均不进行关联操作. ...
- 3、Cookie与Session之间有哪些区别或者是优缺点?
Cookie与Session之间有哪些区别或者是优缺点? 知道了Cookie与Session,我们来做一些简单的总结: 1.Cookie可以存储在浏览器或者本地,session只能存在服务器 ...
- Android高级架构进阶之数据传输与序列化
更多Android高级架构进阶视频学习请点击:https://space.bilibili.com/474380680本篇文章将从以下几个内容来阐述数据传输与序列化: [Serializable原理] ...
- <python基础>python继承机制
子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找. 根据父类定义中的顺序,以深度优先的方式逐一查找父类! class D: def show(self) ...
- Mybatis Generator 安装(idea+maven)
1.在Intellij IDEA创建maven项目(本过程比较简单,略) 2. 在maven项目的pom.xml 添加mybatis-generator-maven-plugin 插件 <bui ...
- Linux初学习之 rm 命令
现在我们来仔细的学习一下linux的rm命令,这个命令顾名思义(我猜的,嘻嘻,是remove) 命令格式: rm [OPTION]... FILE... Remove (unlink) the FIL ...