小白学 Python 爬虫(31):自己构建一个简单的代理池

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
引言
前面的代理如果有同学动手实践过,就会发现一个问题,现在网上的免费代理简直太坑啦!!!
经常一屏幕好多的代理试下来,没有几个能用的。
当然,免费的代理嘛,连通率低、延迟高是正常的,人家毕竟是免费的。
但是这件事儿有没有解决方案呢?
这么天资聪颖的小编肯定是想到了办法了呀。
先来屡屡这件事儿,其实我们要的不是连通率高,而是我们在使用的时候,能每次都用到能用的代理。
这件事儿要么我们每次在用的时候自己手动去试,要么~~~
我们可以写程序让程序自己去寻找合适的代理嘛~~~
其实这一步就是把需要我们手动做的事情变成了程序自动去完成。
代理池
先想一下这个代理池最少需要有哪些功能:
- 自动获取代理
- 定时清除不能用的代理
这两个是我们的核心诉求,最少要有这两个功能,不然这个代理池也没有存在的价值了。
根据上面两个功能,我们来拆解程序的模块,小编这里定义了三个模块,获取模块(获取代理)、存储模块(数据库存储代理)、检测模块(定时检查代理的可用性)。
那么它们三者的关系就是这样的:
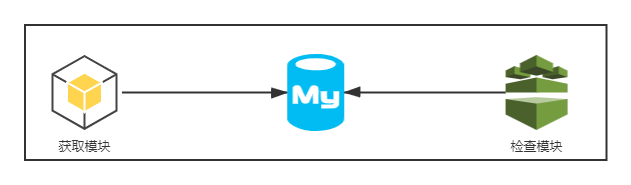
这里的存储模块我们使用 Mysql ,这与存储模块为什么选 Mysql ,因为 Mysql 有表结构,给各位同学展示起来比较清晰,如果需要用于生产环境的话,建议是用 Redis ,提高效率。
数据库
首先还是贴一下数据库的表结构,之前有同学留言问过小编表结构的事情,是小编偷懒没有贴。

本次设计使用的还是单表模式,一张表走天下就是小编本人了。
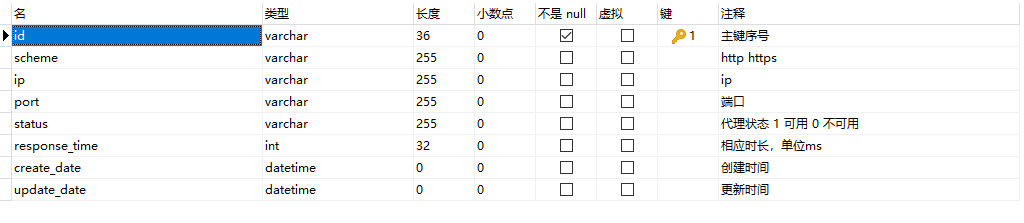
至于字段的含义小编就不介绍了,后面的注释已经写得比较清楚了。
存储模块
对于存储模块来讲,主要的功能是要将我们获取到的代理保存起来,上面的 Mysql 数据库是存储模块的一部分。
基于 OOP 的思想,我们本次写一个类 MysqlClient 将所有对于 Mysql 的操作封装起来,其他模块需要和数据库产生交互的时候只需要调用我们在 MysqlClient 中封装好的方法即可。
示例代码如下:
MYSQL_HOST = 'localhost'
MYSQL_PORT = 3306
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'password'
MYSQL_DB ='test'
MYSQL_CHARSET = 'utf8mb4'
import pymysql
import uuid
class MysqlClient(object):
def __init__(self, host=MYSQL_HOST, port=MYSQL_PORT, user=MYSQL_USER, password=MYSQL_PASSWORD, database=MYSQL_DB, charset=MYSQL_CHARSET):
"""
初始化 mysql 连接
:param host: mysql 地址
:param port: mysql 端口
:param user: mysql 用户
:param password: mysql 密码
:param database: mysql scheme
:param charset: 使用的字符集
"""
self.conn = pymysql.connect(
host = host,
port = port,
user = user,
password = password,
database = database,
charset = charset
)
def add_proxy(self, proxy):
"""
新增代理
:param proxy: 代理字典
:return:
"""
sql = 'INSERT INTO `proxy_pool` VALUES (%(id)s, %(scheme)s, %(ip)s, %(port)s, %(status)s, %(response_time)s, now(), null )'
data = {
"id": str(uuid.uuid1()),
"scheme": proxy['scheme'],
"ip": proxy['ip'],
"port": proxy['port'],
"status": proxy['status'],
"response_time": proxy['response_time'],
}
self.conn.cursor().execute(sql, data)
self.conn.commit()
def find_all(self):
"""
获取所有可用代理
:return:
"""
sql = 'SELECT * FROM proxy_pool WHERE status = "1" ORDER BY update_date ASC '
cursor = self.conn.cursor()
cursor.execute(sql)
res = cursor.fetchall()
cursor.close()
self.conn.commit()
return res
def update_proxy(self, proxy):
"""
更新代理信息
:param proxy: 需要更新的代理
:return:
"""
sql = 'UPDATE proxy_pool SET scheme = %(scheme)s, ip = %(ip)s, port = %(port)s, status = %(status)s, response_time = %(response_time)s, update_date = now() WHERE id = %(id)s '
data = {
"id": proxy['id'],
"scheme": proxy['scheme'],
"ip": proxy['ip'],
"port": proxy['port'],
"status": proxy['status'],
"response_time": proxy['response_time'],
}
self.conn.cursor().execute(sql, data)
self.conn.commit()
在这个类中,我们首先定义了一些常量,都是和数据库连接有关的常量,如 MYSQL_HOST 数据库地址、 MYSQL_PORT 数据库端口、 MYSQL_USER 数据库用户名、 MYSQL_PASSWORD 数据库密码、 MYSQL_DB 数据库的 scheme 、 MYSQL_CHARSET 字符集。
接下来定义了一个 MysqlClient 类,定义了一些方法用以执行数据库的相关操作。
- init(): 初始化方法,在初始化 MysqlClient 这个类时,同时初始化了 Mysql 数据库的链接信息,获得了数据库连接 connection 。
- add_proxy():向数据库中添加代理,并添加相关信息,包括代理响应延时和健康状况。
- find_all():获取所有数据库可用代理,并根据更新时间正序排布,主要用于后续代理检查。
- update_proxy():更新代理信息,主要用户检查模块检查完代理后更新代理信息,根据取出当前代理的主键 id 进行更新。
获取模块
获取模块相对比较简单,主要功能就是从各个免费代理网站上将我们所需要的代理信息抓取下来。示例如下:
import requests
from pyquery import PyQuery
from MysqlClient import MysqlClient
from VerifyProxy import VerifyProxy
class CrawlProxy(object):
def __init__(self):
self.mysql = MysqlClient()
self.verify = VerifyProxy()
def get_page(self, url, charset):
response = requests.get(url)
response.encoding = charset
return response.text
def crawl_ip3366(self, page_num = 3):
"""
获取代理 ip3366
:param page_num:
:return:
"""
start_url = 'http://www.ip3366.net/?stype=1&page={}'
urls = [start_url.format(page) for page in range(1, page_num + 1)]
for url in urls:
print('crawl:', url)
html = self.get_page(url, 'gb2312')
if html:
d = PyQuery(html)
trs = d('.table-bordered tbody tr').items()
for tr in trs:
scheme = tr.find('td:nth-child(4)').text().lower()
ip = tr.find('td:nth-child(1)').text()
port = tr.find('td:nth-child(2)').text()
verify_result = self.verify.verify_proxy(scheme, ip, port)
if verify_result["status"] == '1':
proxy = {
"scheme": scheme,
"ip": ip,
"port": port,
"status": verify_result["status"],
"response_time": verify_result["response_time"],
}
# 存入数据库
self.mysql.add_proxy(proxy)
print('代理', ip, '连通测试已通过,已保存 Mysql')
else:
print('代理', ip, '连通测试未通过')
if __name__ == '__main__':
CrawlProxy().crawl_ip3366()
小编这里出于示例只演示了从 ip3366 上抓取免费代理,并且在抓取到代理后,调用检查模块的检查方法对当前的代理进行连通性检查,如果连通性测试未通过则不会写入数据库中。
检查模块
检查模块相对也会简单一些,功能是从数据库中取出所有可以用的代理,进行轮询检查,看看是不是有代理是连不通的,如果连不通则修改连通性标记位,将此代理标记为不可用。示例代码如下:
import requests
from MysqlClient import MysqlClient
class VerifyProxy(object):
def __init__(self):
self.mysql = MysqlClient()
def verify_proxy(self, scheme, ip, port):
"""
使用百度测试代理的连通性,并返回响应时长(单位:ms)
:param scheme:
:param ip:
:param port:
:return:
"""
proxies = {
scheme: scheme + '://' + ip + ':' + port + '/'
}
response_time = 0
status = '0'
try:
response = requests.get(scheme + '://www.baidu.com/get', proxies=proxies)
if response.ok:
response_time = round(response.elapsed.total_seconds() * 1000)
status = '1'
else:
response_time = 0
status = '0'
except:
pass
return {"response_time" : response_time, "status" : status}
def verify_all(self):
"""
验证住方法,从数据库中获取所有代理进行验证
:return:
"""
results = self.mysql.find_all()
for result in results:
res = self.verify_proxy(result[1], result[2], result[3])
proxy = {
"id": result[0],
"scheme": result[1],
"ip": result[2],
"port": result[3],
"status": res["status"],
"response_time": res["response_time"],
}
self.mysql.update_proxy(proxy)
print('代理验证成功')
if __name__ == '__main__':
VerifyProxy().verify_all()
小编这里使用的是度娘进行连通性测试,如果各位同学有特殊的需要,可以使用特定的网站进行连通性测试。
小结
本篇的内容到这里就结束了,不过有一点要说明,本篇的示例内容只能作为 DEMO 来进行测试使用,对于一个连接池来讲,还有很多不完善的地方。
例如检测模块应该是定时启动,自行检测,现在是靠人手动启动,不过这个可以使用各种系统上的定时任务来解决。
还有,现在要获取连接信息只能自己打开数据库从中 Copy ,这里其实还可以加一个 API 模块,写成一个接口,供其他有需要使用代理的系统进行调用。
获取模块现在小编也只是简单的有一个网站写一个方法,其实可以使用 Python 高级用法,获取到类中所有的方法名,然后调用所需要的方法。
总之,这个 DEMO 非常不完善,等小编下次有空的时候完善下,到时候还可以再来一个推送。

示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
小白学 Python 爬虫(31):自己构建一个简单的代理池的更多相关文章
- 小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(39): JavaScript 渲染服务 scrapy-splash 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 2019-6-23-WPF-获得当前输入法语言区域
title author date CreateTime categories WPF 获得当前输入法语言区域 lindexi 2019-06-23 11:51:21 +0800 2018-10-12 ...
- Java练习 SDUT-3106_小鑫数数儿
小鑫数数儿 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 某天小鑫忽然得到了许多的数字,他很好学,老师给他布置了一个任 ...
- ROS通过图形化界面控制和查看小乌龟参数
ROS图形化界面能够让我们快速开发ROS,也有利于我们观测数据. 下面介绍一下利用图形化界面控制小乌龟按照指令行进和查看小乌龟的行进参数. 首先我们需要做一些准备工作: 在Terminal中运行以下命 ...
- 永久设置anaconda的环境变量
安装anaconda后都显示install seccessful,可是输入anaconda 终端却显示“未找到命令” 原因是没有添加环境变量,按照如下方式将环境变量添加的安装路径下: emport P ...
- Python:pip 和pip3的区别
前言 装完python3后发现库里面既有pip也有pip3,不知道它们的区别,因此特意去了解了一下. 解释 先搜索了一下看到了如下的解释, 安装了python3之后,库里面既会有pip3也会有pip ...
- 洛谷P4018 Roy&October之取石子 题解 博弈论
题目链接:https://www.luogu.org/problem/P4018 首先碰到这道题目还是没有思路,于是寻思还是枚举找一找规律. 然后写了一下代码: #include <bits/s ...
- hdu 1754 I Hate It(线段树区间求最值)
I Hate It Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- PHP两个变量值互换(不用第三变量)
<?php /** * 双方变量为数字或者字符串时 * 使用list()和array()方法可以达到交换变量值得目的 */ $a = "This is A"; // a ...
- 2018-2-25-git-rebase-合并多个提交
title author date CreateTime categories git rebase 合并多个提交 lindexi 2018-02-25 11:41:26 +0800 2018-2-1 ...
- Acegi框架介绍
开发四年只会写业务代码,分布式高并发都不会还做程序员?->>> 概述 对于任何一个完整的应用系 统,完善的认证和授权机制是必不可少的.Acegi Securit ...