莫烦PyTorch学习笔记(五)——分类
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# make fake data
n_data = torch.ones(, )
x0 = torch.normal(*n_data, ) #每个元素(x,y)是从 均值=*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y0 = torch.zeros() # 给每个元素一个0标签
x1 = torch.normal(-*n_data, ) # 每个元素(x,y)是从 均值=-*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y1 = torch.ones() # 给每个元素一个1标签
x = torch.cat((x0, x1), ).type(torch.FloatTensor) # shape (, ) FloatTensor = -bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (,) LongTensor = -bit integer
# torch can only train on Variable, so convert them to Variable
x, y = Variable(x), Variable(y) # draw the data
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=y.data.numpy())#c是一个颜色序列 #plt.show()
#神经网络模块
class Net(torch.nn.Module):#继承神经网络模块
def __init__(self,n_features,n_hidden,n_output):#初始化神经网络的超参数
super(Net,self).__init__()#调用父类神经网络模块的初始化方法,上面三行固定步骤,不用深究
self.hidden = torch.nn.Linear(n_features,n_hidden)#指定隐藏层有多少输入,多少输出
self.predict = torch.nn.Linear(n_hidden, n_output)#指定预测层有多少输入,多少输出
def forward(self,x):#搭建神经网络
x = F.relu(self.hidden(x))#积极函数激活加工经过隐藏层的x
x = self.predict(x)#隐藏层的数据经过预测层得到预测结果
return x
net = Net(,,)#声明一个类对象
print(net) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图
plt.show()
#神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。
optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率
loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range():
out = net(x)
loss = loss_func(out,y)#计算损失
optimizer.zero_grad()#梯度置零
loss.backward()#反向传播
optimizer.step()#计算结点梯度并优化,
if t % == :
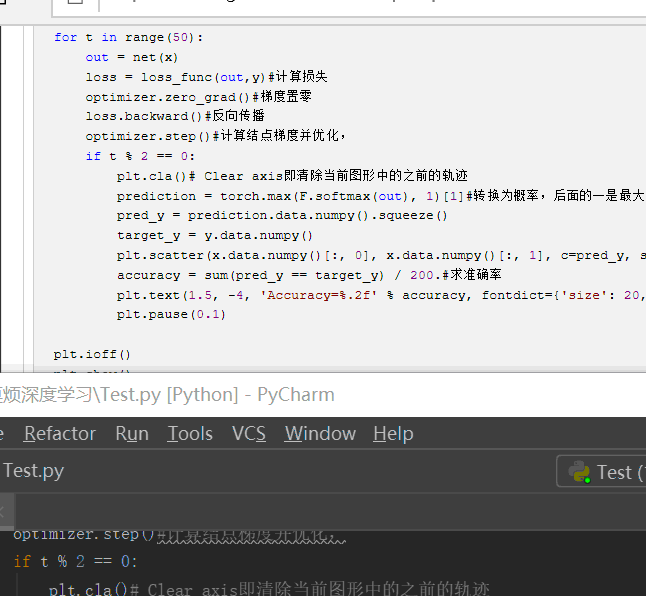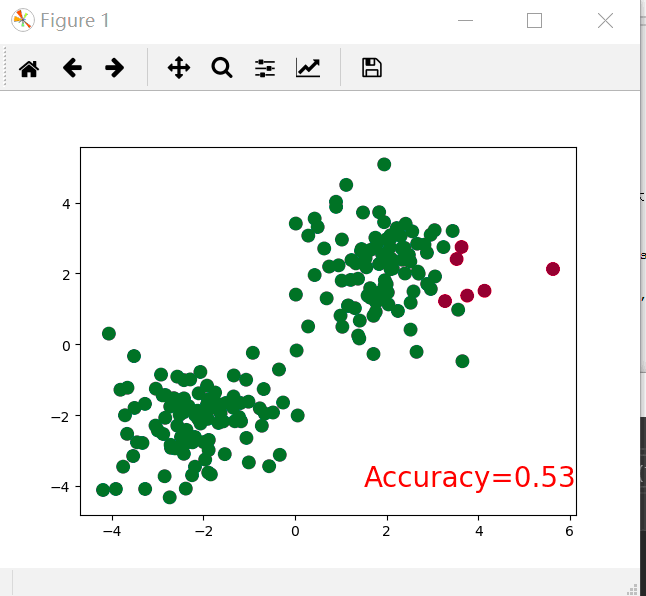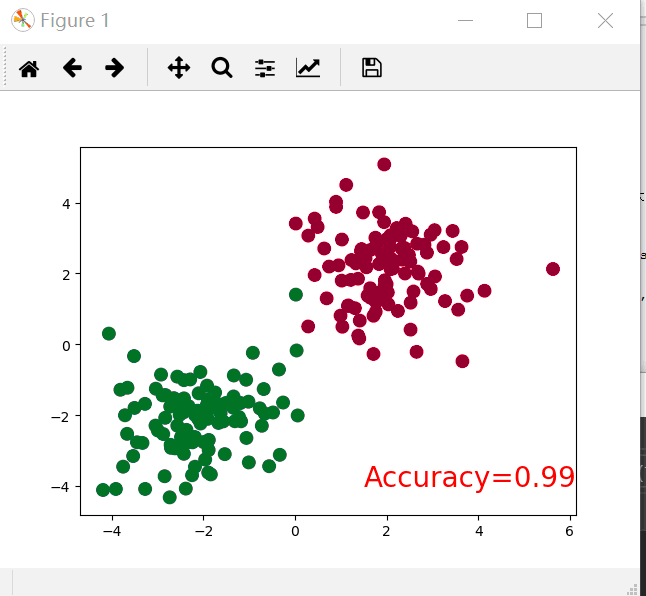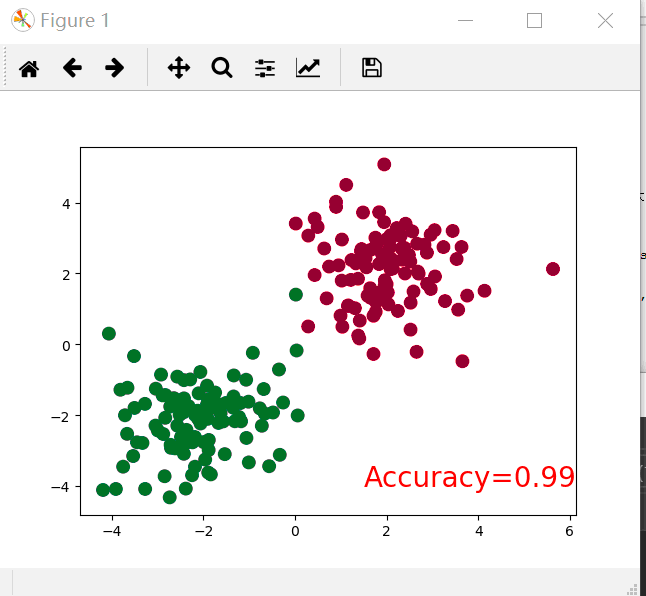
plt.cla()# Clear axis即清除当前图形中的之前的轨迹
prediction = torch.max(F.softmax(out), )[]#转换为概率,后面的一是最大值索引,如果为0则返回最大值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=pred_y, s=, lw=, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / .#求准确率
plt.text(1.5, -, 'Accuracy=%.2f' % accuracy, fontdict={'size': , 'color': 'red'})
plt.pause(0.1) plt.ioff()
plt.show()
下面的是一个比较快搭建神经网络的代码,在上面的代码进行修改,代码如下
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# make fake data
n_data = torch.ones(, )
x0 = torch.normal(*n_data, ) #每个元素(x,y)是从 均值=*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y0 = torch.zeros() # 给每个元素一个0标签
x1 = torch.normal(-*n_data, ) # 每个元素(x,y)是从 均值=-*n_data中对应位置的取值,标准差为1的正态分布中随机生成的
y1 = torch.ones() # 给每个元素一个1标签
x = torch.cat((x0, x1), ).type(torch.FloatTensor) # shape (, ) FloatTensor = -bit floating
y = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (,) LongTensor = -bit integer
# torch can only train on Variable, so convert them to Variable
x, y = Variable(x), Variable(y) # draw the data
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=y.data.numpy())#c是一个颜色序列 #plt.show()
#神经网络模块
net2 = torch.nn.Sequential(
torch.nn.Linear(,),
torch.nn.ReLU(),
torch.nn.Linear(,)
) plt.ion()#在Plt.ion和plt.ioff之间的代码,交互绘图
plt.show()
#神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间。
optimizer = torch.optim.SGD(net.parameters(),lr = 0.01)#其实就是神经网络的反向传播,第一个参数是更新权重等参数,第二个对应的是学习率
loss_func = torch.nn.CrossEntropyLoss()#标签误差代价函数 for t in range():
out = net(x)
loss = loss_func(out,y)#计算损失
optimizer.zero_grad()#梯度置零
loss.backward()#反向传播
optimizer.step()#计算结点梯度并优化,
if t % == :
plt.cla()# Clear axis即清除当前图形中的之前的轨迹
prediction = torch.max(F.softmax(out), )[]#转换为概率,后面的一是最大值索引,如果为0则返回最大值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, ], x.data.numpy()[:, ], c=pred_y, s=, lw=, cmap='RdYlGn')
accuracy = sum(pred_y == target_y) / .#求准确率
plt.text(1.5, -, 'Accuracy=%.2f' % accuracy, fontdict={'size': , 'color': 'red'})
plt.pause(0.1) plt.ioff()
plt.show()
莫烦PyTorch学习笔记(五)——分类的更多相关文章
- 莫烦PyTorch学习笔记(五)——模型的存取
import torch from torch.autograd import Variable import matplotlib.pyplot as plt torch.manual_seed() ...
- 莫烦pytorch学习笔记(八)——卷积神经网络(手写数字识别实现)
莫烦视频网址 这个代码实现了预测和可视化 import os # third-party library import torch import torch.nn as nn import torch ...
- 莫烦pytorch学习笔记(七)——Optimizer优化器
各种优化器的比较 莫烦的对各种优化通俗理解的视频 import torch import torch.utils.data as Data import torch.nn.functional as ...
- 莫烦PyTorch学习笔记(六)——批处理
1.要点 Torch 中提供了一种帮你整理你的数据结构的好东西, 叫做 DataLoader, 我们能用它来包装自己的数据, 进行批训练. 而且批训练可以有很多种途径. 2.DataLoader Da ...
- 莫烦pytorch学习笔记(二)——variable
.简介 torch.autograd.Variable是Autograd的核心类,它封装了Tensor,并整合了反向传播的相关实现 Variable和tensor的区别和联系 Variable是篮子, ...
- 莫烦PyTorch学习笔记(三)——激励函数
1. sigmod函数 函数公式和图表如下图 在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率.sigmod函数 ...
- 莫烦 - Pytorch学习笔记 [ 二 ] CNN ( 1 )
CNN原理和结构 观点提出 关于照片的三种观点引出了CNN的作用. 局部性:某一特征只出现在一张image的局部位置中. 相同性: 同一特征重复出现.例如鸟的羽毛. 不变性:subsampling下图 ...
- 莫烦 - Pytorch学习笔记 [ 一 ]
1. Numpy VS Torch #相互转换 np_data = torch_data.numpy() torch_data = torch.from_numpy(np_data) #abs dat ...
- 莫烦PyTorch学习笔记(四)——回归
下面的代码说明个整个神经网络模拟回归的过程,代码含有详细注释,直接贴下来了 import torch from torch.autograd import Variable import torch. ...
随机推荐
- ECMAScript1.4 对象 | 简单数据类型与复杂数据类型 | 内置对象 | 基本包装类型 | String
对象 函数和对象的区别: 函数:封装代码 对象:封装属性和方法 创建对象的方法: 1,对象字面量{} // 模拟创建一只dog var dog = { // 属性 name: 'puppy', age ...
- MVC 传递数据 从前台到后台,包括单个对象,多个对象,集合
MVC 传递数据 从前台到后台,包括单个对象,多个对象,集合 1.基本数据类型 我们常见有传递 int, string, bool, double, decimal 等类型. 需要注意的是前台传递的参 ...
- std::unorder_set你插入元素的顺序不一定就是元素在里面的元素
去看了下cppreference,里面写了 根据哈希值排序了
- more指令和less指令使用的区别
more和less都是可以一页一页的翻动 more翻页的时候,显示有百分比在最下一行 less没有 more可以用来查询 空白键 (space):代表向下翻一页:Enter :代表向下翻『一行』:/字 ...
- VGDB提示
由于之前地址的版本在未安装.Net 4.0的电脑上安装会出现插件使用装载失败的问题,已更新,新地址为:http://pan.baidu.com/s/1xdnuD,此版本需要.Net 2.0.
- 【JZOJ4616】二进制的世界
description analysis \(DP\),这是\(Claris\)神仙的题-? 既然是\(2^{16}\)可以拆成两个\(2^8\)的位运算 照着打就行了 code #include&l ...
- QQ空间批量删除说说
按下F12,贴下如下代码 var delay = 1000; function del() { if (document.querySelector(".app_canvas_frame&q ...
- Manager 进程间数据共享
#_author:来童星#date:2019/12/11#Managersfrom multiprocessing import Process, Managerdef f(d, l,n): d[n] ...
- DelphiHookApi(经典)
论坛里有关于HOOK API的贴子, 但其实现在方式显示得麻烦, 其实现在拦截API一般不用那种方式, 大都采用inline Hook API方式.其实也就是直接修改了要拦截的API源码的头部,让它无 ...
- JAVA POI XSSFWorkbook导出扩展名为xlsx的Excel,附带weblogic 项目导出Excel文件错误的解决方案
现在很多系统都有导出excel的功能,总结一下自己之前写的,希望能帮到其他人,这里我用的是XSSFWorkbook,我们项目在winsang 用的Tomcat,LInux上用的weblogic服务器, ...