CVPR 2016 paper reading (6)
1. Neuroaesthetics in fashion: modeling the perception of fashionability, Edgar Simo-Serra, Sanja Fidler, Francesc Moreno-Noguer, Raquel Urtasun, in CVPR 2015.
Goal: learn and predict how fashionable a person looks on a photograph, and suggest subtle improvements that user could make to improve her/his appeal.
This paper proposes a Conditional Random Field model that jointly reasons about several fashionability factors such as the type of outfit (全套装备) and garments (衣服) the user is wearing, the type of the user, the photograph's setting (e.g., the scenery behind the user), and the fashionability score.
Importantly, the proposed model is able to give rich feed back to the user, conveying which garments or even scenery she/he should change in order to improve fashionability.

This paper collects a novel dataset that consists of 144,169 user posts from a clothing-oriented social website chictopia.com. In a post, a user publishes one to six photographs of her/himself wearing a new outfit. Generally each photograph shows a different angle of the user or zoons in on different garments. User sometimes also add a description of the outfit, and/or tags of the types and colors of the garments they are wearing.

Discovering fashion from weak data:
The energy of the CRF as a sum of energies encoding unaries for each variable as well as non-parametric pairwise pothentials which reflect the correlations between the different random variables:
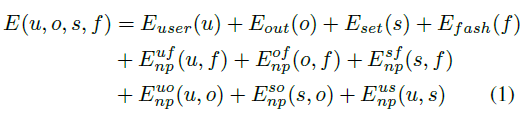
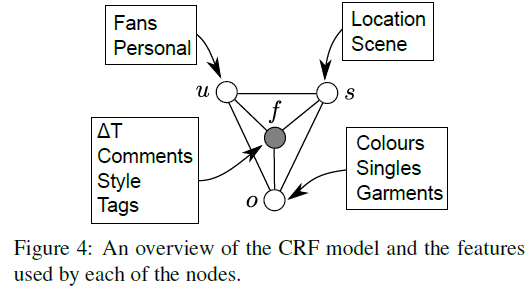
User specific features:
- the logarithm of the number of fans
- use rekognition to compute attributes of all the images of each post, keep the features for the image with the highest score.
Then compute the unary potentials as the output of a small neural network, produce an 8-D feature map.
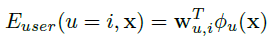
Outfit features:
bag-of-words approach on the "garments" and "colours" meta-data

Setting features:
- the output of a pre-trained scene classifier (multi-layer perceptron, whose input is CNN feature)
- user-provided location: look up the latitude and longitude of the user-provided location, project all the values on the unit sphere, and add some small Guassian noise. Then perform unsupervised clustering using the geodesic distances, and use the geodesic distance from each cluster center as a feature.
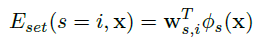
Fashion:
- delta time: the time between the creation of the post and when the post was crawled as a feature
- bag-of-words on the "tag"
- comments: parse the comments with the sentiment-analysis model, which can predict how positive a review is on a 1- 5 scale, sum the scores for each post.
- style: style classifier pretrained on Flickr80K.
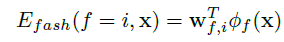
Correlations:
use a non-parametric function for each pairwise and let the CRF learn the correlations:
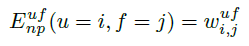
Similarly for the other pairwise potentials.
Learn and Inference:
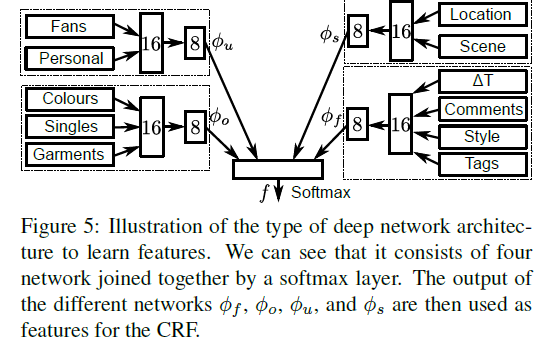
First jointly train the deep networks that are used for feature extraction to predict fashionablity, and estimate the initial latent states using clustering.
Then learn the CRF model using the primal-dual method.
CVPR 2016 paper reading (6)的更多相关文章
- CVPR 2016 paper reading (2)
1. Sketch me that shoe, Qian Yu, Feng Liu, Yi-Zhe Song, Tao Xiang, Timothy M. Hospedales, Cheng Chan ...
- CVPR 2016 paper reading (3)
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations, Ziwei Liu, Pin ...
- 浅析"Sublabel-Accurate Relaxation of Nonconvex Energies" CVPR 2016 Best Paper Honorable Mention
今天作了一个paper reading,感觉论文不错,马克一下~ CVPR 2016 Best Paper Honorable Mention "Sublabel-Accurate Rela ...
- (转)CVPR 2016 Visual Tracking Paper Review
CVPR 2016 Visual Tracking Paper Review 本文摘自:http://blog.csdn.net/ben_ben_niao/article/details/52072 ...
- Paper Reading: In Defense of the Triplet Loss for Person Re-Identification
In Defense of the Triplet Loss for Person Re-Identification 2017-07-02 14:04:20 This blog comes ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- 深度视觉盛宴——CVPR 2016
小编按: 计算机视觉和模式识别领域顶级会议CVPR 2016于六月末在拉斯维加斯举行.微软亚洲研究院在此次大会上共有多达15篇论文入选,这背后也少不了微软亚洲研究院的实习生的贡献.大会结束之后,小编第 ...
- Paper Reading - Deep Visual-Semantic Alignments for Generating Image Descriptions ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1412.2306 Main Points: An Alignment Model: Convolutional Ne ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
随机推荐
- C# 页面抽奖实例 asp.net
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head runat=&qu ...
- document.getElementsByTagName
var elems = document.forms[form_name].getElementsByTagName("INPUT"); getElementsByTagName( ...
- No.4一步步学习vuejs之表单输入绑定
基础用法 你可以用 v-model 指令在表单控件元素上创建双向数据绑定.它会根据控件类型自动选取正确的方法来更新元素.尽管有些神奇,但 v-model 本质上不过是语法糖,它负责监听用户的输入事件以 ...
- DataTables获取指定元素的行数据
法1: 用jquey获取,var row = $('.edit').parent().parent(); 缺点:只能获取dom上的东西,不能获取没有渲染的数据 法2: 首先绑定行号到元素上 $('#e ...
- zookeeper学习实践1-实现分布式锁
引言 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提 ...
- Java从入门到精通——数据库篇Mongo DB 导出,导入,备份
一.概述 本篇博客为大家讲述一下Mongo DB是如何导入导出数据,还有就是备份数据的. 在下面操作的时候需要把Mongo DB的服务端打开才能操作. 二.导出. MongoDB的导 ...
- .NET开源工作流RoadFlow-流程运行-任务收回
如果一个任务则发送,又觉得还要想修改可以立即收回刚刚发送的任务. 任务收回条件:任务发送后下一步处理人还没有打开该任务,则在已办事项中会看到 收回 按钮,否则不能收回. 点击收回按钮再确认即可收回刚刚 ...
- 二进制中 1 的个数(C++ 和 Python 实现)
(说明:本博客中的题目.题目详细说明及参考代码均摘自 “何海涛<剑指Offer:名企面试官精讲典型编程题>2012年”) 题目 请实现一个函数,输入一个整数,输出该数二进制表示中 1 的个 ...
- jquery mobile开发中常见的问题(转载)
1页面缩放显示问题 问题描述: 页面似乎被缩小了,屏幕太宽了. 处理方法: 在head标签内加入: <meta name="viewport" content="w ...
- idea基础操作
idea 类和方法注释模板生成 设置教程:https://blog.csdn.net/xiaoliulang0324/article/details/79030752